딥러닝 주요모델
딥러닝 ? : 다층의 layer를 통해 복잡한 데이터의 학습이 가능토록 함 (Graphical representation learning)
알고리즘, GPU의 발전이 딥러닝의 부흥!을 일으킴
Neural Network
- 입력, 은닉, 출력 층으로 구성된 모형
- overfitting이 심하고, 학습시간이 매우 길다.
CNN (Convolutional Neural Network)
- 이미지의 지역별 feature를 뽑아서 neural network 학습
- 자세한건 나중에~~~
RNN, AutoEncoder 등 다양한 형태로 발전했다.
또 다양한 분야로 발전(object detection, image resolution, style transfer, colorization 등)하기도 했으며, 네트워크 구조를 발전시켜(ResNet, DenseNet 등) 더 좋은 성과를 얻어내기도 했다. 뒤에서 딥러닝은 따로 다룰 예정이므로 대~~충 겉핥기만 하고 넘어가자!
근데 아직 안끝났다.
GAN (Generative Adversarial Network)
- DATA를 만들어내는 Generator와, 만들어진 data를 평가하는 Discriminator가 서로 대립하여(Adversarial) 학습해가는 개념
-Discriminator를 학습시킬때는 진짜를 진짜로 판별하고, 가짜를 가짜로 판별할 수 있도록
-Generator를 학습시킬때는 discriminator가 구분못하도록 학습
강화학습 (Reinforcement Learning)
- Q-learning
-현재 상태에서부터 먼 미래까지 가장 큰 보상!을 얻을 수 있도록 행동을 학습
모델의 적합성 평가 및 실험설계
데이터 분할
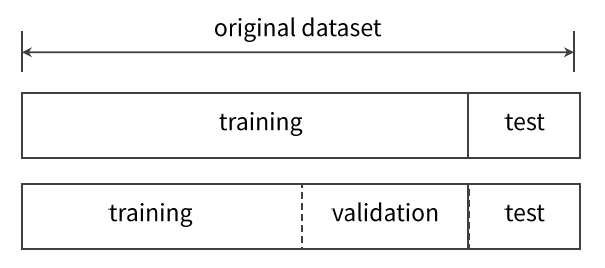
- 과적합을 방지하기 위해 데이터를 학습, 검증, 테스트로 나눈다.(보통 5:3:2 선호)
- 학습 데이터를 사용해 모델 학습
- 검증 데이터를 사용하여 각 모델의 성능을 비교하고 모델 선택
- 테스트 데이터를 사용하여 검증 데이터로 도출한 최종모델의 성능 지표를 계산
K-Fold 교차검증 (K-Fold Cross Validation)
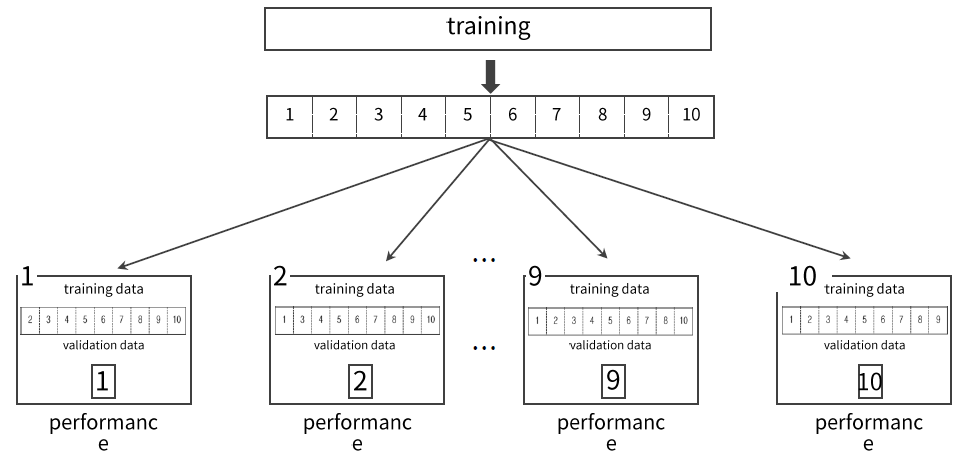
- 모형의 적합성을 보다 객관적으로 평가하기 위해!
- 데이터를 K개 부분으로 나눔, 그중 하나를 검증집합! 나머지를 학습집합! 으로 분류
- 위 과정을 K번 반복, K개의 성능지표를 평균하여 모델적합성 평가
데이터 분석 과정
겉핥기식 공부는 여기까지 !
