LDA란?
-
데이터 분포를 학습해 결정경계를 만들어 데이터를 분류하는 모델
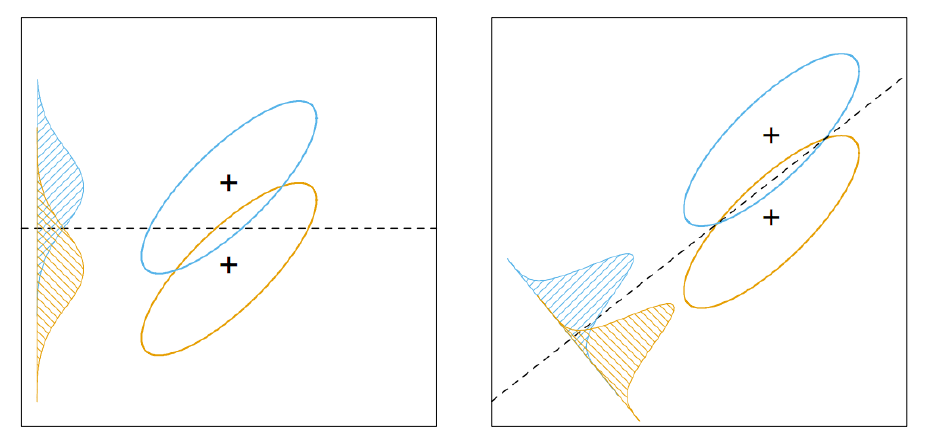 (어느 모델이 더 분류가 잘 되었다고 판단할 수 있을까?)
(어느 모델이 더 분류가 잘 되었다고 판단할 수 있을까?) -
두 범주의 중심(평균!)이 서로 멀수록 좋다!
-
두 범주의 분산이 작을수록 좋다!
이 두가지의 경우를 최대한! 충족시키며 중간지점을 찾아내는것이 LDA다!
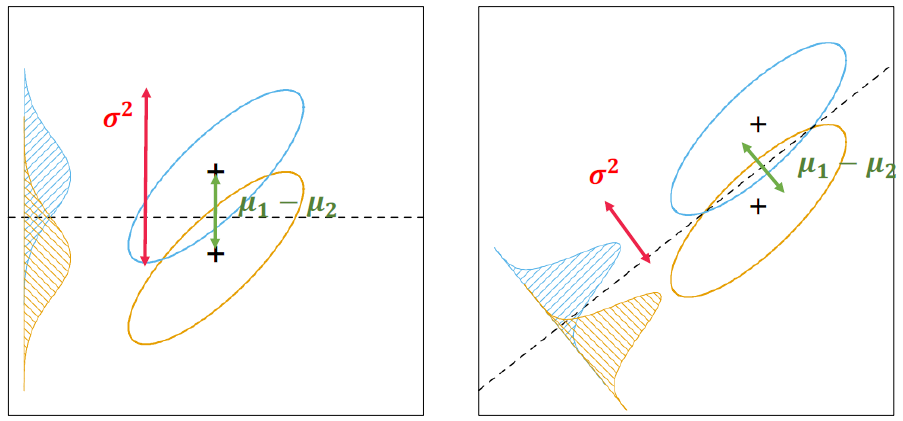 (왼쪽 그림은 평균은 극대화 되었으나, 분산이 너무 커요! 오른쪽은 반대상황이겠져?)
(왼쪽 그림은 평균은 극대화 되었으나, 분산이 너무 커요! 오른쪽은 반대상황이겠져?)
LDA decision boundary
- 분산대비 평균의 차이를 극대화 하는 boundary
가정
- 각 숫자 집단은 정규분포 형태의 확률분포를 가짐!
- 각 숫자 집단은 비슷한 형태의 공분산 구조를 가짐!
장점
- 나이브 베이즈 모델과 달리, 설명변수간의 공분산 구조를 반영
- 가정이 위반되더라도 비교적 robust
단점
- 가장 작은 그룹의 샘플 수가 설명변수의 개수보다는 많아야함
- 정규분포 가정에 크게 벗어나는 경우 잘 설명하지 못함
- y의 범주 사이에 공분산 구조가 다른 경우를 반영하지 못함 --> 이럴때? QDA~!
QDA 정의 및 이해
- k와 관계없는 공통 공분산 구조에 대한 가정을 버림!
- 서로 다른 공분산 구조를 가진 경우에 활용 가능!
LDA, QDA 비교
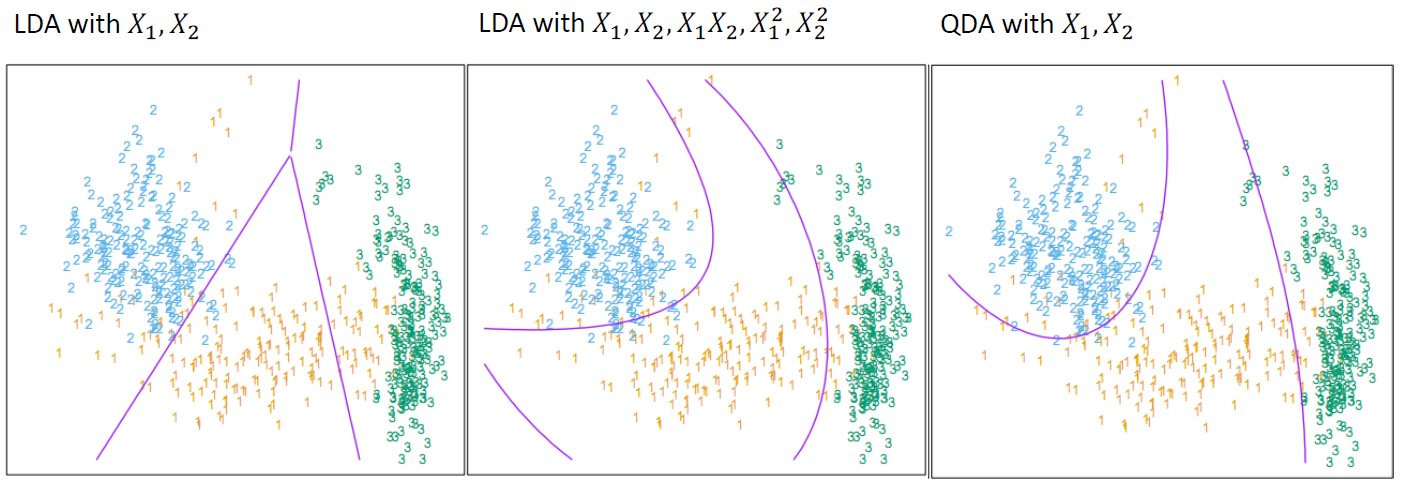 (꼭 QDA가 답은아냐!)
(꼭 QDA가 답은아냐!)
- QDA는 설명변수의 개수가 많을 경우, 추정해야 하는 모수가 많아짐! 즉 샘플이 많이필요하기때문에 위 그림에서 두번째 경우가 더 많은 장점을 가지기도 함

2개의 댓글

2023년 8월 7일
좋은 내용 감사합니다 멋지네요! 저도 개발 공부하는 중인데, https://quantpro.co.kr/ 해당 사이트 퀀트 내용 어떤지 의견주시면 감사하겠습니다!
답글 달기
옆에서 직접 말해주는 느낌이네요!!