
Optimization
-
용어 모음
-
Generalization
- 학습한 모델이 한번도 보지 않은 데이터에 대해 얼마나 잘 작동하는지에 대한 용어
-
Underfitting, Overfitting
-
Cross-validation(K-fold)
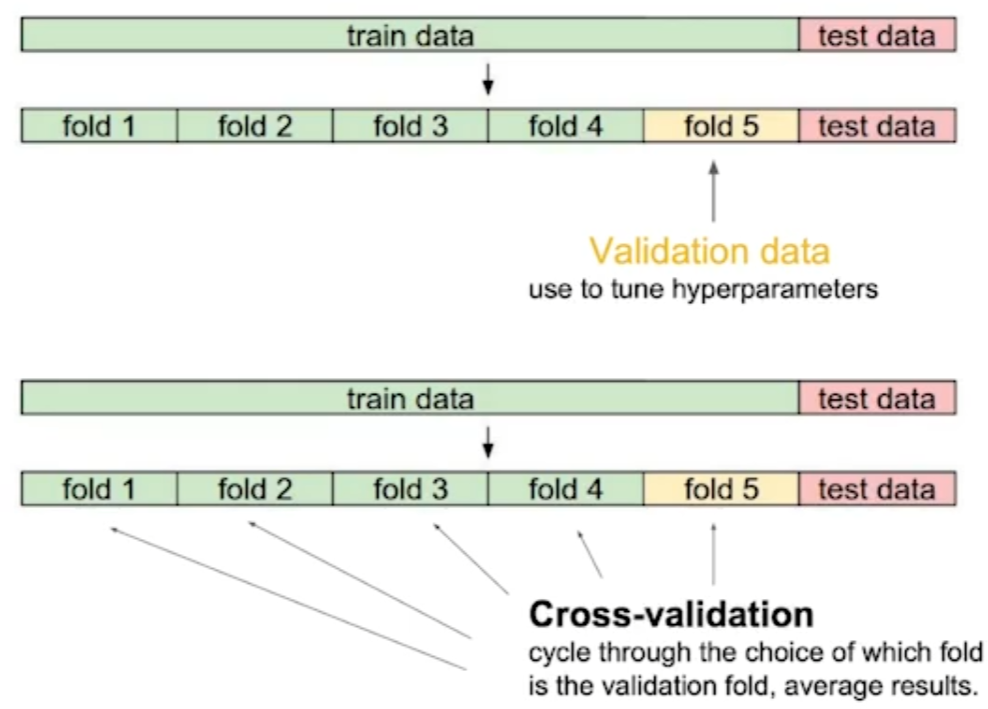
-
Bias/Variance
-
Bootstrapping
- 학습데이터 중 일부를 사용한 모델들을 사용하는 기법
-
Bagging
- Bootstrapping을 사용하여 학습한 여러 모델을 사용해서 예측값의 평균이나 최다투표값을 사용하는 기법
-
Boosting
- 잘 안되는 데이터에 대해서만 따로 모델을 만들어서 시퀀셜하게 붙여서 해결하는 기법
-
-
Batch-size
- 일반적으로 배치사이즈를 적게 사용하는 것이 좋음
- 그래서 Large-Batch를 사용할때 해결하는 trick에 대한 논문이 있음
- On Large-batch Training for Deep Learning: Generalization Gap and Sharp Minima, 2017
-
Gradient Descent Method
- Stochastic gradient descent
- Momentum
- Nesterov accelerated gradient
- Adagrad
- Adadelta
- RMSprop
- Adam
- Stochastic gradient descent
Regularization
-
Early Stopping
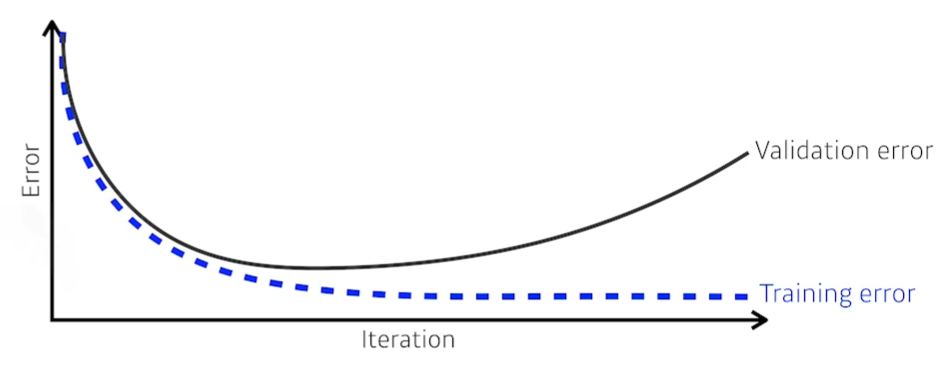
-
Parameter norm penalty(weight decay)

-
Data augmentation
- 데이터가 어느정도 커지게 되면 일반화 성능이 향상됨
- 최대한 가지고 있는 데이터를 이용해서 더 많은 데이터를 만들기 위해 사용
- 도메인 상황을 봐가면서 사용해야함
-
Noise robustness
-
학습단계에서 입력 데이터에 노이즈를 주거나 weight에 노이즈를 주면 실험적으로 학습이 잘됨
-
Label smoothing
- 학습단계에서 복수의 이미지를 합쳐 학습함
- Decision Boundary가 부드러워지는 효과가 있음
-
Dropout
- NeuralNet의 weight를 일시적으로 0으로 바꿔줌
- 수학적으로 증명된것은 아님
-
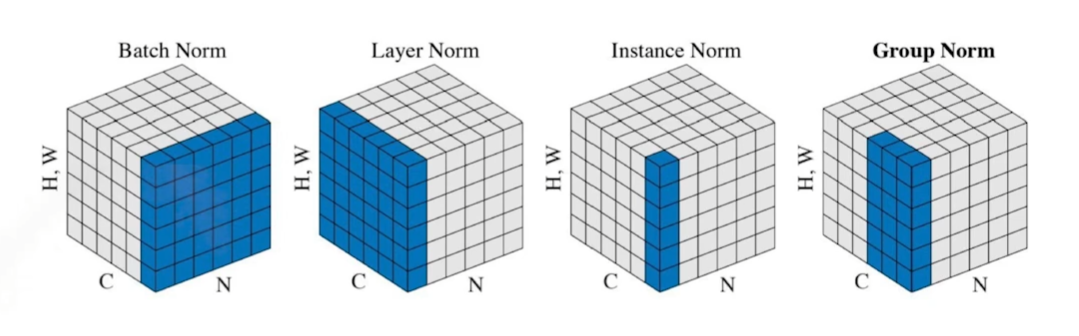
Batch normalization
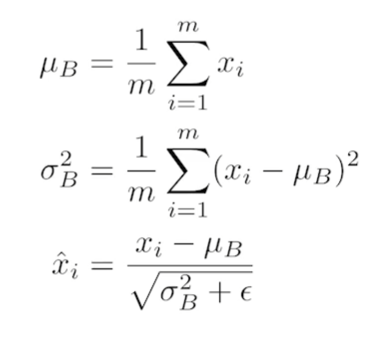
- internal covariate shift에 대한 논란이 많음
피어세션 정리
DL-Basic 완료
필수과제 완료
예정
Viz 강의 마저 듣기

아마추어 GAN잽이