
실시간 동시 편집
만약 Google Docs에서 [🔴Red] 와 [🔵Blue] 가 문서를 작성하려고 합니다.
두 명 다 똑같이 Hello! 를 보고 있습니다.
Hello![🔴Red] 는 Hello 와 ! 사이에 World 를 추가하고,
[🔵Blue] 는 ! 뒤에 :-) 이모티콘을 추가했다고 치면,
어떤 결과가 어떻게 나올까요?

아마 다들 당연히 Hello World ! :-) 가 나와야겠다고 생각하실 겁니다.
하지만 동시 편집은 인간의 눈엔 직관적이지만, 구현상에서는 분산된 환경에서의 동시성은 복잡한 문제를 가지고 있습니다. 그런 모호함을 해결하기 위한 여러 기술 중 대표적인 2가지 기술이 있습니다.
[OT 알고리즘] 과 [CRDT 알고리즘] 입니다.
OT vs CRDT
우선 OT(Operational Transformation) 알고리즘은 과거에서부터 2006년 정도까지 사용되었던 기술이며, 대표적인 서비스가 Google Docs와 MS Office Online 입니다.
그리고 CRDT(Conflict-Free-Replicatied Data Types) 알고리즘은 2006년 이후 현재까지 사용되는 기술로, 대표적으로 Figma나 Redis 등 많은 서비스들이 사용하고 있습니다.
OT (Operational Transformation)
OT 의 작동원리
다시 Google Docs에서 🟢Green 과 🟣Purple 가 문서를 작성하려고 합니다.
두 사용자 모두 다 똑같이 Helo 를 보고 있습니다.
🟢Green 와 🟣Purple 가 동시에 편집한다고 가정했을 때,
0123
Helo🟢Green 은 INDEX 2번(l)과 INDEX 3번(o) 사이에 l을 추가 하고,
🟣Purple 은 INDEX 3번(o) 뒤에 !를 추가한다고 했을 때,
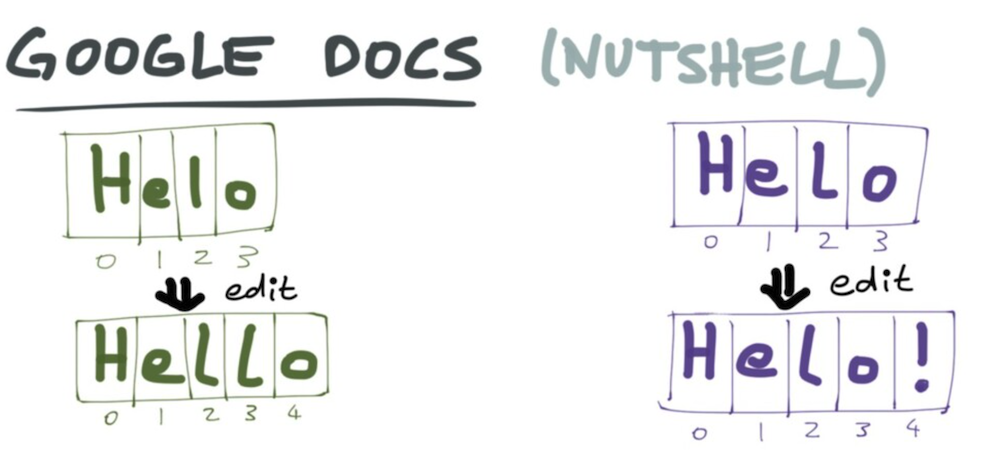
이 때, 아래 그림과 같이
🟢Green 에서는 INDEX 위치를 이용해서 l을 INDEX 3번에 삽입하는 명령어,
🟣Purple 에서는 !를 INDEX 4번에 넣는 명령어가 동시에 발생하게 됩니다.
이 두 명령어를 중앙 서버(Server)가 받아서 문서를 통합합니다.

만약,
🟢Green 의 명령어(l 을 INDEX 3에 삽입하기)가 먼저 실행 될 경우,
🟣Purple 의 명령어로 인해 !가 INDEX 4에 들어가야하는데,
이미 l이 INDEX 3에 들어가서 INDEX 위치가 바뀌어 버렸습니다.
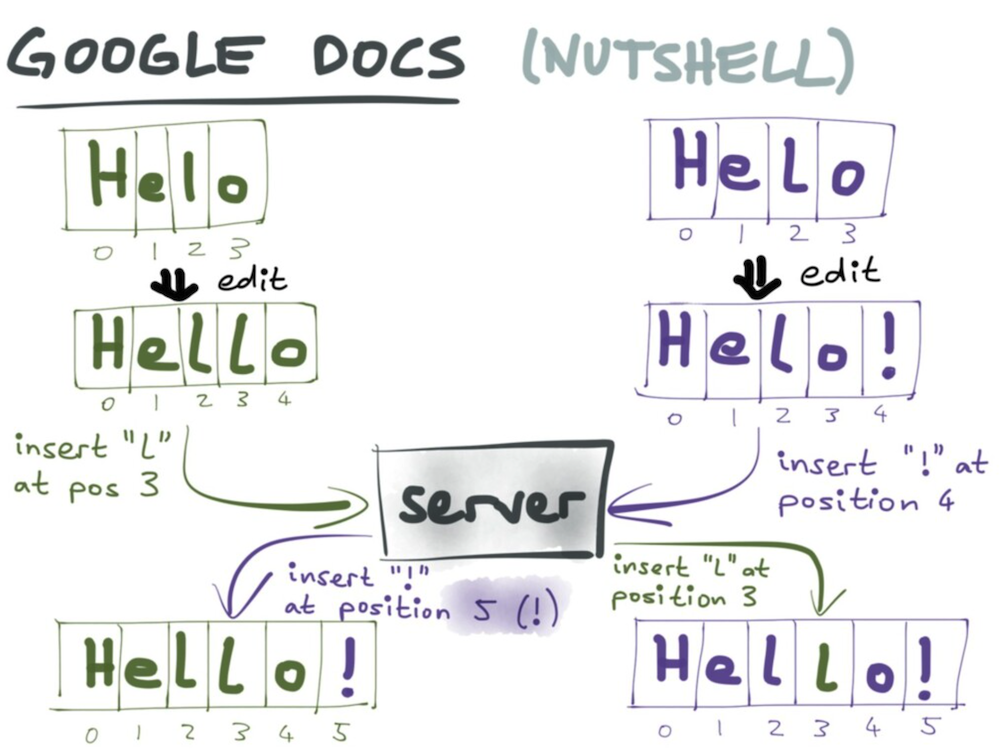
따라서, INDEX 위치가 바뀌어 🟣Purple의 명령어인 !를 INDEX 4가 아닌 INDEX 5의 위치로 변경되게 됩니다.
이렇게 명령어가 이전에 동작되었던 명령어에 의해 바뀌어 다음 동작을 transform(변환) 시켜줘야 하는데,
이것을 바로 operational transformation OT 알고리즘입니다.
OT 방식의 문제점

이러한 OT 방식에 단점이 있습니다.
사용자가 서버(Server)에 수정사항을 던지게 되면 다른 유저들과 직접적으로 연동할 방법 없습니다. transformation(변환)을 하는 주체인 서버가 있어야 합니다.
따라서, OT의 문제는 중앙 집중식 서버/DB가 필요합니다. 이런 구조에서는 사람이 몰릴 때 과부화가 올 수 있습니다.
CRDT (Conflict-Free-Replicatied Data Types)
CRDT 의 작동 원리
CRDT(Conflict-Free-Replicated Data Types)는 어떤 변경사항을 받으면, 순서와 상관없이 변경사항만 같으면 같은 상태 입니다.
즉, OT는 순서가 중요하고, CRDT는 순서가 상관 없고 operation만 같으면 어긋나더라도 같은 상태가 됩니다.
OT 알고리즘은 INDEX가 변하게 되어 문제가 발생하지만,
CRDT는 이 같은 문제를 피하기 위해 각 개체를 유니크한 값으로 봅니다. 그래서 텍스트가 추가될 때마다 새로운 유니크한 값을 생성해서 넣어주게 됩니다.
위와 동일한 조건으로 CRDT 의 예를 들어보겠습니다.
두 사용자 모두 다 똑같이 Helo 를 보고 있습니다.
🟢Green 와 🟣Purple 가 동시에 편집한다고 가정했을 때,
Helo🟢Green 은 l과 o 사이에 l을 추가 하고,
🟣Purple 은 o 뒤에 !를 추가한다고 했을 때,
아래 그림과 같이 유니크한 값을 0과 1 사이의 숫자들로 가정한다면,
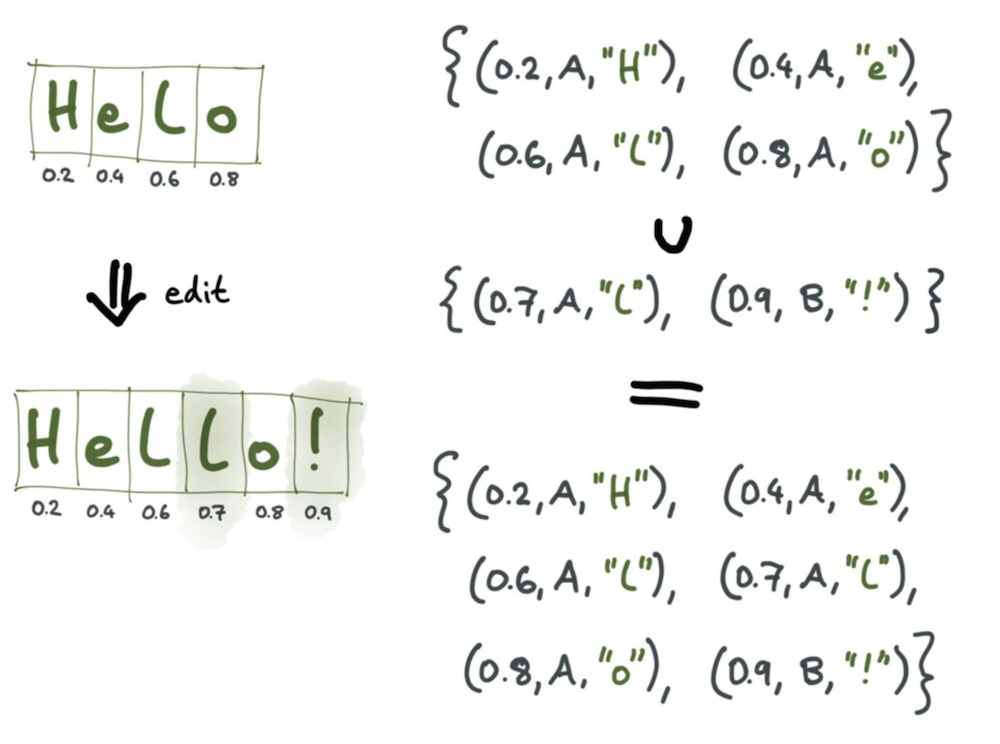
🟢Green 과 🟣Purple의 명령어로 동시에 l 과 !를 넣는다는 가정했을 때,
- 🟢Green의 명령어:
l은 0.6과 0.8사이에 0.7을 생성합니다. - 🟣Purple의 명령어:
!는 0.8과 1 사이에 0.9를 생성합니다.
이렇듯 동시 편집을 하더라도 합치는 과정에서 유니크한 값으로 판별하기 때문에 충돌이 일어나지 않게 됩니다. CRDT는 이러한 기술을 서버응답을 기다릴 필요 없이 편집이 가능한 것입니다.
통신은 서버에서 하거나 클라에서 직접 병합하거나 같은 결과를 만들기 때문에 네트워크의 영향을 직접적으로 받지 않을 수 있습니다.
그래서 CRDT는 중앙집중식 서버가 필요 하지 않습니다. 어떤 네트워크, 통신을 선택하든지 제한이 없습니다. 그래서 협업 애플리케이션 뿐 아니라, Redis Enterprise 같은 데이터 센터 간에 지역적으로 떨어져서 운영하는 DB 시스템에도 활용됩니다.
CRDT 방식의 문제점
하지만 CRDT에서도 완벽하지 않은 동작이 있습니다. 바로 아래와 같은 예시입니다.
🧑💻User 1과 👨🏽💻User 2가 Hello!를 보고 있고, 동시에 편집합니다.
🧑💻User 1이 Hello와 ! 사이에 Alice를 삽입합니다.
👨🏽💻User 2도 Hello와 ! 사이에 Charlie를 삽입합니다.
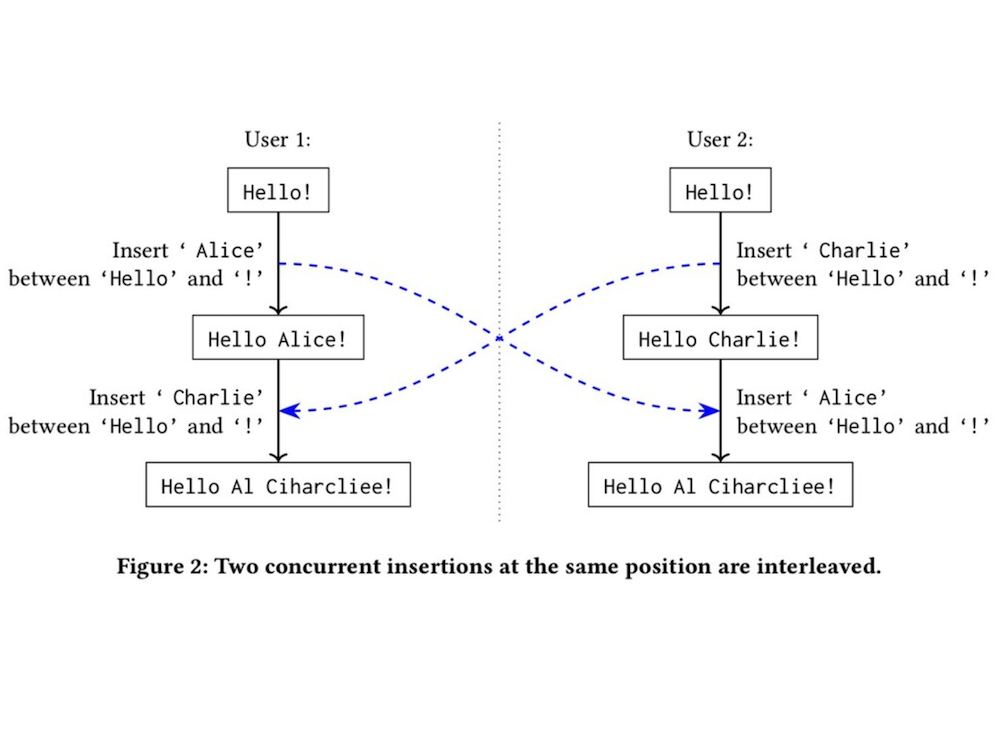
그래서 두 명령어를 아래와 같이 CRDT 방식으로 병합하게 되면,
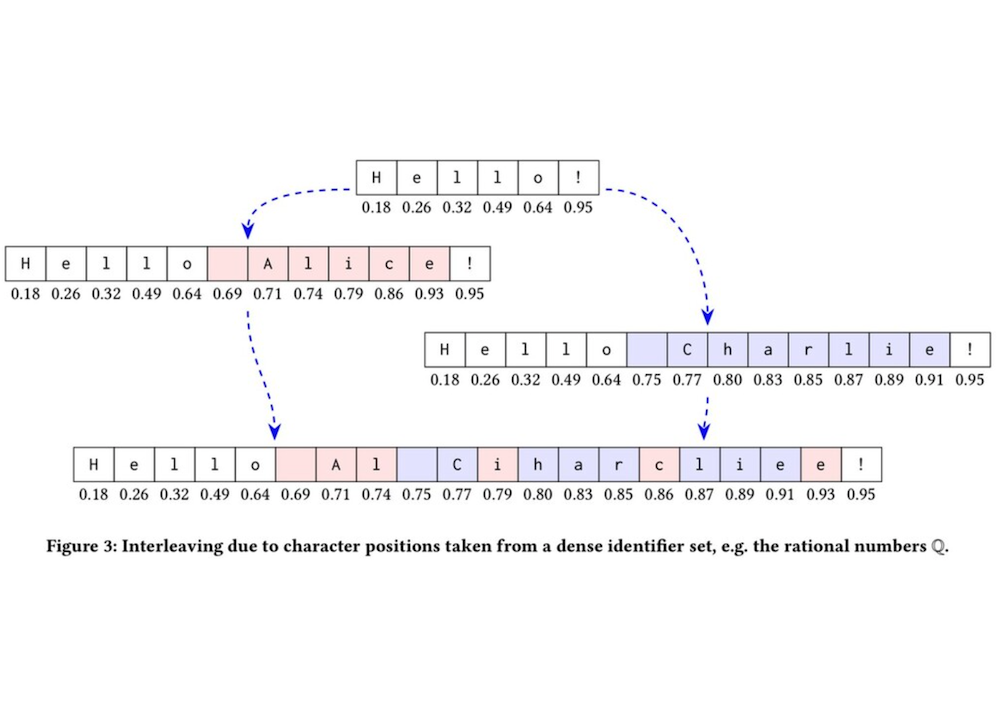
Hello Al Ciharcliee!위와 같은 결과처럼 이상한 결과를 가지게 됩니다.
앞에서 말했듯이 글자 하나에 모두 유니크한 (숫자)값을 가진다고 했을 때, 독립적으로 글자들이 랜덤화된 값에 의해 병합되게 됩니다. 그래서 불행하게도 alice와 charlie의 글자들을 CRTD 알고리즘 방식대로 정렬했을 때 이상한 결과값으로 나오게 되는 것입니다.
CRDT의 문제를 보완하는 알고리즘 기법들

이러한 문제점을 해결하는 다양한 알고리즘 기법들이 있습니다.
