EXISTS
SELSECT 사용시 테이블에 데이터가 있는지 없는지 판별해서 해당 데이터의 존재 유무에 따라 실행하는 결과가 다르다
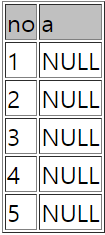
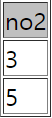
#551테이블의 a row값이
#552번 테이블에 a2 row에 존재하면
update sample551 set a = '있음'
where exists (select * from sample552 where no2 = no);
update sample551 set a = '없음'
where not exists (select * from sample552 where no2 = no);
#비교대상이 되는 column의 이름이 같을때는
#sample552 where sample551.no = sample552.no
#테이블명.column결과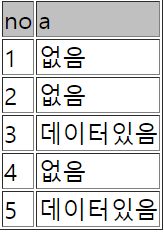
마지막 부분where no2 = no은 552번 테이블의 no2와 551번 테이블의 no을 비교하라는 =이 되는 것 같다
상관서브쿼리
update 명령은 (부모)가 되고 이하 서브쿼리 부분은 (자식)이된다 부모 명령은 551테이블을 갱신하는 역할을 하고 자식인 서브쿼리는 552테이블의 no2값이 부모의 no값과 일치하는 행을 검색.
->이와 같이 부모명령과 자식 서브쿼리가 특정관계를 맺는 것을 '상관 서브쿼리' 라고한다
IN
논리합 연산자 (OR)과 쓰임새는 비슷하다고 한다
그럼 그냥 OR을 다쓰면 되지않을까 생각해서 찾아보니
IN을 사용할 수 있는 경우라면 OR보다 IN을 사용하는 것이 좋습니다. IN은 경우에 따라서 서브쿼리를 이용하여 보다 유연한 확장이 가능합니다. IN은 반드시 하나의 컬럼이 비교되어야 하지만 OR는 여러 개의 컬럼이 올 수 있으므로 나중에 인덱스 구성에 대한 전략을 수립할 때도 IN이 유리합니다. 그리고 IN절의 경우에는 인덱스를 이용해서 조건을 검색할 수 있지만, OR은 인덱스를 이용하지 못 합니다. OR 연산자는 정말 다른 방법이 도저히 없는 경우를 제외하고는 사용하지 않는 것이 바람직합니다.
이렇다고 한다
select * from sample551 where no = 3 or no = 5;
select * from sample551 where no in(3,5);
#or과 in - 똑같은 sql문IN을 이용해서 두테이블간의 조건검색 서브쿼리를 사용해보자(서브쿼리 종류에서 2번)
select * from sample551 where no = (select no2 from sample552);
select * from sample551 where no IN (select no2 from sample552);여기서 서브쿼리의 종류가 또 2개로 갈라진다
- 단일행 서브쿼리는 결과값이 1개이고, 스칼라값일때
where no = (equals)를 사용- 다중행 서브쿼리는 결과값이 2개이상이고, 스칼라값이 아니어도 되며 where no IN 을 사용한다(IN, ANY, ALL)
그럼 다중행에서 사용하는 (IN, ANY, ALL)이 뭔지 보자
IN
- 조건절에서 사용하며 다수의 비교값과 비교하여 비교값 중 하나라도 같은 값이 있다면 true 이다.
ANY
- 다수의 비교값 중 한개라도 만족하면 true 이다.
- IN 과 다른점은 비교 연산자를 사용한다는 점이다.
ALL
- 전체 값을 비교하여 모두 만족해야만 true 이다. <--> ANY
- ALL은 나올 수 있는 모든 조건에 AND 연산을 수행한것과 동일한 결과를 얻는다.
