네 가지 IPC 시스템을 살펴본다.
1. 공유 메모리를 위한 POSIX API
2. Mach(마크) 운영체제에서 메시지 전달 논의
3. 특정 유형의 메시지 전달을 제공하는 메커니즘으로 공유 메모리는 사용하는 Windows IPC
4. UNIX 시스템에서 가장 초기의 IPC 메커니즘 중 하나인 pipes
3.7.1 POSIX Shared Memory
POSIX 시스템에서는 공유 메모리와 메시지 전달을 포함한 여러 IPC 메커니즘을 사용할 수 있다. 여기서는 공유 메모리를 위한 PISIX API를 살펴본다.
POSIX 공유 메모리는 메모리 매핑 파일을 사용하여 구성되며, 이는 공유 메모리 영역을 파일과 연결한다. 프로세스는 먼저 다음과 같이 shm_open() 시스템 콜을 사용하여 공유 메모리 객체를 생성해야 한다.
fd = shm_open(name, O_CREAT : O_RDWR, 0666);첫 번째 매개변수는 공유 메모리 객체의 이름을 지정한다. 이 공유 메모리에 접근하려는 프로세스는 이 이름으로 객체를 참조해야 한다. 다음 매개변수는 공유 메모리 객체가 아직 존재하지 않는 경우 생성되는 것(OCREATE)과 객체가 읽기 및 쓰기를 위해 열려있음(O_RDWR)을 명시한다. 마지막 매개변수는 공유 메모리 객체의 파일 접근 권한을 설정한다. _shm_open() 에 대한 성공적인 호출은 공유 메모리 객체에 대한 정수 파일 디스크립터(서술자)를 반환한다.
객체가 설립되면, ftruncate() 함수를 사용하여 객체의 크기를 바이트 단위로 설정한다. 호출
ftruncate(fd, 4096);은 객체의 크기를 4096byte로 설정한다.
마지막으로 mmap() 함수는 공유 메모리 객체를 포함하는 메모리 매핑 파일을 설정한다. 또한 공유 메모리 객체에 접근하는데 사용되는 메모리 매핑 파일에 대한 포인터를 반환한다.
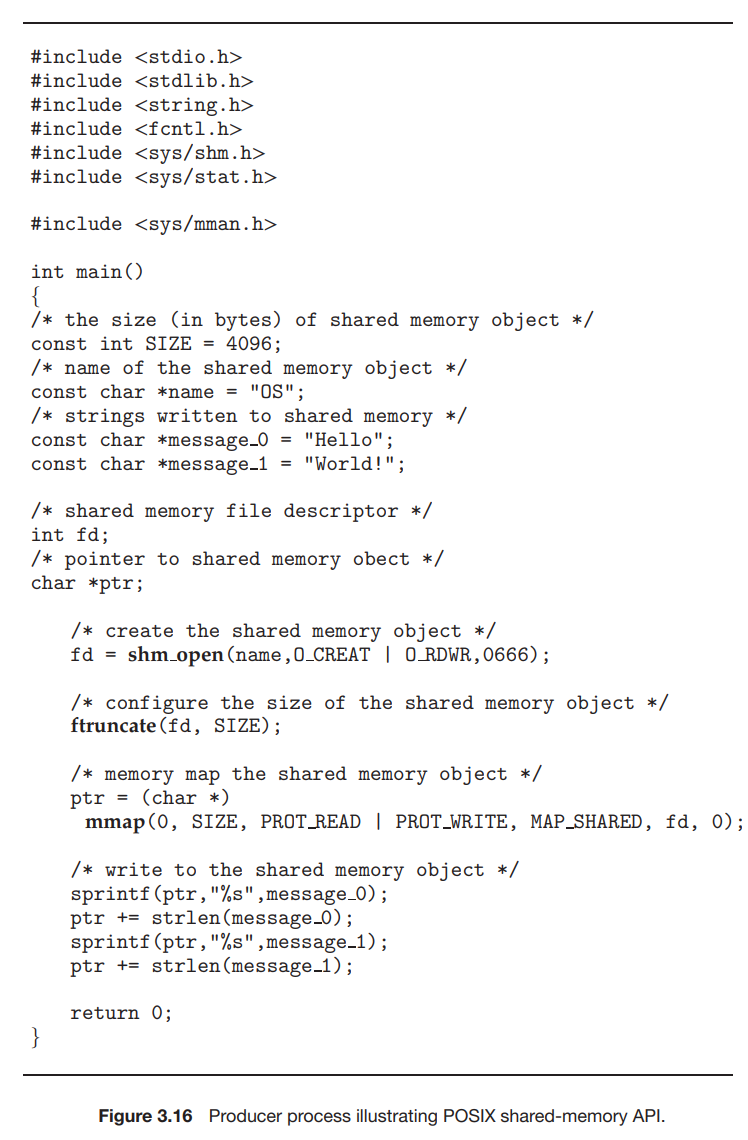
그림 3.16과 그림 3.17에 나타낸 프로그램은 공유 메모리를 구현하는 데 생산자-소비자 모델을 사용한다. 생산자는 공유 메모리 객체를 설정하고 공유 메모리에 쓰고, 소비자는 공유 메모리에서 읽는다.
 |  |
|---|
그림 3.16에 나타낸 생산자는 OS 라는 공유 메모리 객체를 생성하고 악명 높은 문자열 "Hello Word!" 를 공유 메모리에 작성한다. 이 프로그램은 지정된 크기의 공유 메모리 객체를 메모리 매핑하고 객체에 작성할 수 있도록 한다. 플래그 MAP_SHARED 는 공유 메모리 객체에 대한 변경 사항이 객체를 공휴나는 모든 프로세스에 표시됨을 지정한다. sprintf() 함수를 호출하고 포맷된 문자열을 포인터 ptr 에 써서 공유 메모리 객체에 작성한다는 점을 유의해라. 각 작성 후, 포인터를 작성된 바이트 수만큼 증가시켜야 한다.
그림 3.17에 나타낸 소비자 프로제스는, 공유 메모리의 내용을 읽고 출력한다. 소비자는 또한 소비자가 접근한 후 공유 메모리 부분을 제거하는 shm_unlink() 함수를 호출한다. 메모리 매핑에 대한 자세한 내용은 13.5장에서 제공한다.
3.7.2 Mach Message Passing
메시지 전달의 한 예로, Mach 운영체제를 고려해보겠다. Mach는 분산 시스템을 위해 특별히 설계되었지만, 2장에서 논의한 것처럼 macOS와 iOS 운영체제에 포함된 것을 보면, 데스크톱과 모바일 시스템에도 적합한 것으로 나타났다.
Mach 커널은 프로세스와 비슷하지만 제어 스레드가 여러 개이고 연관된 리소스가 적은 여러 작업의 생성 및 파괴를 지원한다. Mach에서 대부분의 통신(모든 작업 간의 통신 포함)은 메시지를 통해 수행된다. 메시지는 Mach에서 포트라고 하는 메일박스로 전송되고, 메일박스에서 수신된다. 포트는 크기가 한정되어 있고 단방향이다. 양방향의 통신의 경우 메시지는 한 포트로 전송되고 응답은 별도의 reply(응답) 포트로 전송된다. 각 포트에서 여러 발신자가 있을 수 있지만, 수신자는 하나만 있다. Mach는 작업, 스레드, 메모리, 프로세서와 같은 리소스를 나타내는 데 포트를 사용하는 반면, 메시지 전달은 이러한 시스템 리소스 및 서비스와 상호 작용하기 위한 객체 지향 접근 방식을 제공한다. 메시지 전달은 동일한 호스트의 두 포트간 접근이나 분산 시스템의 별도 호스트에서 발생할 수 있다.
각 포트와 연관된 것은 포트와 상호 작용하는 작업에 필요한 기능을 식별하는 포트 권한의 컬렉션이다. 예를 들어, 작업이 포트에서 메시지를 수신하려면 해당 포트에 대한 MACH_PORT_RIGHT_RECEIVE 기능이 있어야 한다. 포트를 만드는 작업은 해당 포트의 소유자이고, 소유자는 해당 포트에서 메시지를 수신할 수 있는 유일한 작업이다. 포트 소유자는 포트의 기능을 조작할 수도 있다. 이것은 가장 일반적으로 응답 포트를 설정할 때 수행된다. 예를 들어, 작업 T1이 포트 P1을 소유하고, 작업 T2가 소유한 포트 P2로 메시지를 보낸다고 가정하자. T1이 T2로부터 응답을 받을 것으로 예상하는 경우 포트 P1에 대한 MACH_PORT_RIGHT_SEND 권한을 T2에 부여해야 한다. 포트 권한의 소유권은 작업 레벨에 있으며, 동일한 작업에 속하는 모든 스레드가 동일한 포트 권한을 공유한다는 것을 의미한다. 따라서 동일한 작업에 속하는 두 스레드는 각 스레드와 연관된 스레드별 포트를 통해 메시지를 교환하여 쉽게 통신할 수 있다.
작업이 생성되면, 두 개의 특수 포트(Tesk Self 포트와 Notify 포트)도 생성된다. 커널은 작업 자체 포트에 대한 수신 권한을 가지고 있어, 작업이 커널에 메시지를 보낼 수 있다. 커널은 작업의 Notify 포트(물론, 작업에 수신 권한이 있음)에 이벤트 발생 알림을 보낼 수 있다.
mach_port_allocate() 함수 호출은 새 포트를 생성하고 메시지 큐에 대한 공간을 할당한다. 또한 포트에 대한 권한을 식별한다. 각 포트 권한은 해당 포트의 이름을 나타내며, 포트는 권한을 통해서만 접근할 수 있다. 포트 이름은 간단한 정수 값이며 UNIX 파일 디스크립터와 매우 비슷하게 동작한다. 다음 예는 이 API를 사용하여 포트를 만드는 방법을 보여준다.
mach_port_t port; // the name of the port right
mach_port_allocate(
mach_task_self(), // a task referring to is self
MACH_PORT_RIGHT_RECEIVE, // the right for this port
&port); // the name of the port right각 작업은 부트스트랩 포트에 엑세스할 수 있으며, 이를 통해 작업은 자신이 만든 포트를 시스템 전체 부트스트랩 서버에 등록할 수 있다. 포트가 부트스트랩 서버에 등록되면 다른 작업은 이 레지스트리에서 포트를 조회하여 포트로 메시지를 보낼 권한을 얻을 수 있다.
각 포트에 연관된 대기열은 크기가 유한하며 처음에는 비어있다. 메시지가 포트로 전송되면 메시지가 큐에 복사된다. 모든 메시지는 안정적으로 전달되고 동일한 우선순위를 갖는다. Mach는 동일한 발신자의 여러 메시지가 선입선출(FIFO) 순서로 큐에 들어가도록 보장하지만 절대적인 순서를 보장하지는 않는다. 예를 들어 두 발신자의 메시지는 어떤 순서로든 큐에 들어갈 수 있다.
Mach 메시지에 다음 두 필드가 포함된다:
- 메시지 크기, 소스 및 대상 포트를 포함한 메시지에 대한 메타데이터가 포함된 고정 크기 메시지 헤더. 일반적으로 전송 스레드는 응답을 기대하므로 소스의 포트 이름이 수신 작업으로 전달되고, 수신 작업은 응답을 보낼 때 "return address"로 사용할 수 있다.
- 데이터를 포함하는 가변 크기의 본문
메시지는 간단하거나 복잡할 수 있다. 간단한 메시지에는 커널에서 해석되지 않는 일반적이고 구조화되지 않은 사용자 데이터가 포함된다. 복잡한 메시지에는 데이터가 포함된 메모리 위치(out-of-line data)에 대한 포인터가 포함될 수 있거나 다른 작업에 포트 권한을 전송하는 데 사용될 수도 있다. out-of-line 데이터 포인터는 메시지가 대량의 데이터 청크를 전달해야할 때 특히 유용하다. 간단한 메시지는 메시지에서 데이터를 복사하고 패키징해야 하지만, out-of-line 데이터 전송에는 데이터가 저장된 메모리 위치를 참조하는 포인터만 필요하다.
함수 mach_msg() 는 메시지를 보내고 받는 표준 API이다. 함수의 매개변수 중 하나인 MACH_SEND_MSG 또는 MACH_RCV_MSG 의 값은 전송 작업인지 수신 작업인지를 나타낸다. 이제 클라이언트 작업이 서버 작업에 간단한 메시지를 보낼 때 어떻게 사용되는지 보여주겠다. 클라이언트와 서버 작업에 각각 연결된 두 개의 포트(클라이언트와 서버)가 있다고 가정한다. 그림 3.18의 코드는 클라이언트 작업이 헤더를 구성하고 서버에 메시지를 보내는 것과 서버 작업이 클라이언트에서 보낸 메시지를 수신하는 것을 보여준다.

mach_msg() 함수 호출은 메시지 전달을 수행하기 위해 사용자 프로그램에서 호출된다. mach_msg() 는 그런 다음 Mach 커널에 대한 시스템 콜인 mach_msg_trap() 함수를 호출한다. 커널 내에서 mach_msg_trap() 은 다음으로 mach_msg_overwrite_trap() 함수를 호출하고, 이 함수는 메시지의 실제 전달을 처리한다.
전송 및 수신 작업 자체는 유연하다. 예를 들어, 메시지가 포트로 전송될 때 큐가 가득찰 수 있다. 큐가 가득 차지 않으면, 메시지가 큐에 복사되고 전송 작업이 계속된다. 포트의 큐가 가득 찬 경우, 발신자는 여러 옵션을 사용할 수 있다 (mach_msg() 매개변수를 통해 지정됨):
- 큐에 자리가 생길 때까지 무한정 기다린다.
- 최대 n 밀리초 동안 기다린다.
- 전혀 기다리지 말고 즉시 돌아온다.
- 메시지를 일시적으로 캐시한다. 여기서, 메시지는 해당 메시지가 전송되는 큐가 가득 차더라도 유지하기 위해 운영체제에 전달된다. 메시지를 큐에 넣을 수 있으면 알림 메시지가 발신자에게 다시 전송된다. 주어진 전송 스레드에 대해 전체 큐에 대한 메시지는 하나만 대기할 중일 수 있다.
마지막 옵션은 서버 작업을 위한 것이다. 요청을 완료한 후, 서버 작업은 서비스를 요청한 작업에 일회성 응답을 보내야 할 수도 있지만, 클라이언트의 응답 포트가 가득 차더라도 다른 서비스 요청도 계속 진행해야 한다.
메시지 시스템의 주요 문제는 일반적으로 발신자 포트에 수신자 포트로의 메시지 복사로 인한 성능 저하이다. Mach 메시지 시스템은 가상 메모리 관리 기법을 사용하여 복사 작업을 피하려고 시도한다(10장). 기본적으로 Mach는 발신자의 메시지가 포함된 주소 공간을 수신자의 주소 공간에 매핑한다. 따라서 발신자와 수신자 모두 동일한 메모리에 액세스하므로 메시지 자체는 실제로 복사되지 않는다. 이 메시지 관리 기술은 성능을 크게 향상시키자만 시스템 내 메시지에 대해서만 작동한다.
3.7.3 Windows
Windows 운영 체제는 모듈 방식을 채택하여 기능을 향상시키고 새로운 기능을 구현하는 데 필요한 시간을 단축하는 최신 설계의 예다. Windows는 여러 운영 환경 또는 하위 시스템을 지원한다. 응용 프로그램은 메시지 전달 메커니즘을 통해 하위 시스템과 통신한다. 따라서, 응용 프로그램은 하위 시스템 서버의 클라이언트로 간수할 수 있다.
Windows의 메시지 전달 기능은 고급 로컬 프로시저 호출(Advanced Local Procedure Call. ALPC) 기능이라고 한다. 이 기능은 동일한 컴퓨터의 두 프로세스 간의 통신에 사용된다. 이 기능은 널리 사용되는 표준 RPC(Remote Procedure Call) 메커니즘과 유사하지만, Windows에 최적화되어 있고, Windows에 특화되어 있다. Mach와 마찬가지로 Windows는 포트 개체를 사용하여 두 프로세스간 연결을 설정하고 유지한다. Windows는 connection 포트와 communication 포트의 두 가지 유형 포트를 사용한다.
서버 프로세스는 모든 프로세스가 볼 수 있는 연결 포트 개체를 게시한다. 클라이언트가 하위 시스템의 서비스를 원하면, 서버는 연결 포트 개체에 대한 핸들을 열고 해당 포트에 연결 요청을 보낸다. 그러면 서버는 채널을 만들고 클라이언트에 핸들을 반환한다. 채널은 한 쌍의 비공개 통신 포트로 구성되며, 하나는 클라이언트-서버 메시지용, 다른 하나는 서버-클라이언트 메시지용이다. 또한, 통신 채널은 클라이언트와 서버가 일반적으로 응답을 기대할 때 요청을 수락할 수 있는 콜백 메커니즘을 지원한다.
ALPC 채널이 생성되면, 세 가지 메시지 전달 기술 중 하나가 선택된다:
- 작은 메시지(최대 256바이트)의 경우, 포트의 메시지 큐가 중간 저장소로 사용되고, 메시지는 한 프로세스에서 다른 프로세스로 복사된다.
- 더 큰 메시지는 채널과 연관된 공유 메모리 영역인 섹션 객체(section object)를 통해 전달되어야 한다.
- 데이터 양이 섹션 객체에 맞추기에는 너무 큰 경우, 서버 프로세스가 클라이언트의 주소 공간을 직접 읽고 쓸 수 있도록 해주는 API를 사용할 수 있다.
클라이언트는 채널을 설정할 때 큰 메시지를 보내야 할지 여부를 결정해야 한다. 클라이언트가 큰 메시지를 보내고 싶다고 결정하면, 섹션 객체를 만들 것을 요청한다. 마찬가지로 서버가 응답이 클 것이라고 결정하면 섹션 객체를 만든다. 섹션 객체를 사용할 수 있도록 섹션 객체에 대한 포인터와 크기 정보가 포함된 작은 메시지를 보낸다. 이 방법은 위에 나열된 첫 번째 방법보다 복잡하지만 데이터 복사를 피할 수 있다. Windows에서 ALPC 구조는 그림 3.19에 나와있다.

Windows의 ALPC 기능은 Windows API의 일부가 아니므로 애플리케이션 프로그래머에게 보이지 않는다는 점을 유의하는 것이 중요하다. 오히려 Windows API를 사용하는 애플리케이션은 표준 RPC를 호출한다. RPC가 동일한 프로세스에서 호출될 때, RPC는 ALPC 프로시저 호출을 통해 간접적으로 처리된다. 또한, 많은 커널 서비스는 ALPC를 사용하여 클라이언트 프로세스와 통신한다.
3.7.4 Pipes
파이프는 두 프로세스가 통신할 수 있도록하는 통로 역할을 한다. 파이프는 초기 UNIX 시스템에서 최초의 IPC 메커니즘 중 하나였다. 파이프는 일반적으로 프로세스가 서로 통신할 수 있는 가장 간단한 방법 중 하나를 제공하지만 몇 가지 제한 사항도 있었다. 파이프를 구현할 때는 다음 네 가지 문제를 고려해야 한다.
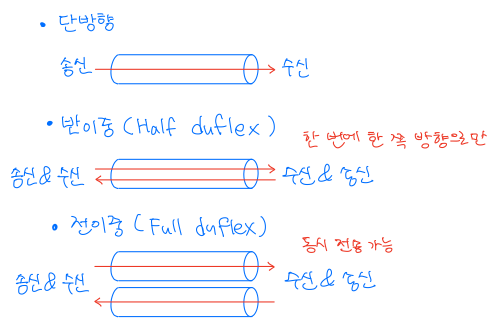
- 파이프는 양방향 통신을 허용하는가, 아니면 통신이 단방향인가?
- 양방향 통신이 허용된다면, 그것은 반이중(데이터를 한 번에 한 방향으로만 전송 가능)인가, 아니면 전이중(데이터를 동시에 양방향으로 전송 가능)인가?
- 통신하는 프로세스 간에 관계(예: 부모-자식)가 존재해야 하나?
- 파이프가 네트워크를 통신할 수 있나, 아니면 통신하는 프로세스가 동일한 시스템에 있어야 하나?
다음 섹션에서 UNIX와 Windows 시스템에서 모두 사용되는 두 가지 일반적인 파이프 유형 ordinary 파이프와 named 파이프에 대해 살펴보겠다.
3.7.4.1 Ordinary Pipes
일반 파이프는 두 프로세스가 표준 생산자-소비자 방식으로 통신할 수 있도록 한다. 생산자는 파이프의 한 쪽 끝(write end)에 쓰고 소비자는 다른 쪽 끝(read end)에서 읽는다. 결과적으로 일반 파이프는 단방향이어서 단방향 통신만 가능하다. 양방향 통신이 필요한 경우, 두 개의 파이프를 사용해야 하며, 각 파이프는 다른 방향으로 데이터를 전송해야 한다. 다음으로 UNIX와 Windows 시스템에서 일반 파이프를 구성하는 방법을 설명한다. 두 프로그램 예제에서, 한 프로세스는 파이프에 Greetings 메시지를 쓰고 다른 프로세스는 파이프에서 이 메시지를 읽는다.
UNIX 시스템에서, 일반 파이프는 다음 함수를 사용하여 구성된다.
pipe(int fd[])이 함수는 int fd[] 파일 디스크립터를 통해 엑세스되는 파이프를 생성한다. fd[0] 은 파이프의 읽기 끝이며, fd[1] 은 쓰기 끝이다. UNIX는 파이프를 특수한 유형의 파일로 취급한다. 따라서, 파이프는 일반적은 read() 및 write() 시스템 콜을 사용하여 엑세스할 수 있다.
일반 파이프는 파이프를 만든 프로세스 외부에서 엑세스할 수 없다. 일반적으로 부모 프로세스는 파이프를 만들고 fork() 를 통해 만든 자식 프로세스와 통신하는데 사용한다. 섹션 3.3.1에서 자식 프로세스는 부모로부터 오픈 파일을 상속한다는 것을 기억해라. 파이프는 특수한 유형의 파일이기 때문에 자식은 부모 프로세스로부터 파이프를 상속받는다. 그림 3.20은 fd 배열의 파일 디스크립터와 부모 및 자식 프로세스의 관계를 보여준다. 여기에서 알 수 있듯이, 부모가 파이프의 쓰기 끝인 fd[1] 에 쓴 모든내용은 자식 파이프의 읽기 끝은 fd[0] 에서 읽을 수 있다.
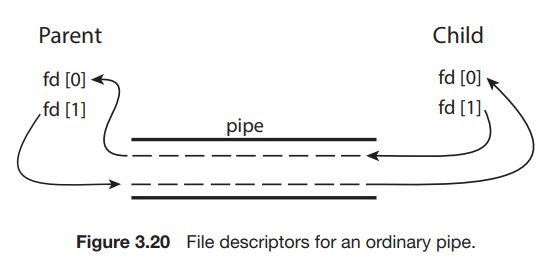
그림 3.21에 나와 있는 UNIX 프로그램에서 부모 프로세스는 파이프를 만든 다음 fork() 콜을 보내 자식 프로세스를 만든다. fork() 호출 후에 발생하는 일은 데이터가 파이프를 통해 어떻게 흐를지에 따라 달라진다. 이 경우, 부모는 파이프에서 쓰고 자식은 파이프에서 읽는다. 부모 프로세스와 자식 프로세스 모두 처음에 파이프의 사용되지 않는 끝을 닫는다는 점을 유의하는 것이 중요하다. 그림 3.21에 나와있는 프로그램은 이 작업이 필요하지 않지만, 작성자가 파이프 끝을 닫았을 때 파이프에서 읽는 프로세스가 파일 끝(read() 가 0을 반환)을 감지할 수 있도록 하는 중요한 단계이다.
 |  |
|---|
Windows 시스템에서 일반 파이프는 anonymous pipes(익명 파이프)라고 하며, UNIX 대응 파이프와 비슷하게 동작한다. 단방향이며 통신 프로세스 간에 부모-자식 관계를 사용한다. 또한 파이프에대한 읽기 및 쓰기는 일반 ReadFile() 및 WriteFile() 함수로 수행할 수 있다. 파이프를 만드는 Windows API는 CreatePIpe() 함수로, 4개의 매개변수가 전달된다. 매개변수는 (1) 파이프 읽기 및 (2) 파이프 쓰기에 대한 별도의 핸들과 (3) 자식 프로세스가 파이프 핸들을 상속하도록 지정하는 데 사용되는 STARUPINFO 구조의 인스턴스를 제공하고, (4) 파이프의 크기(byte)를 지정할 수 있다.
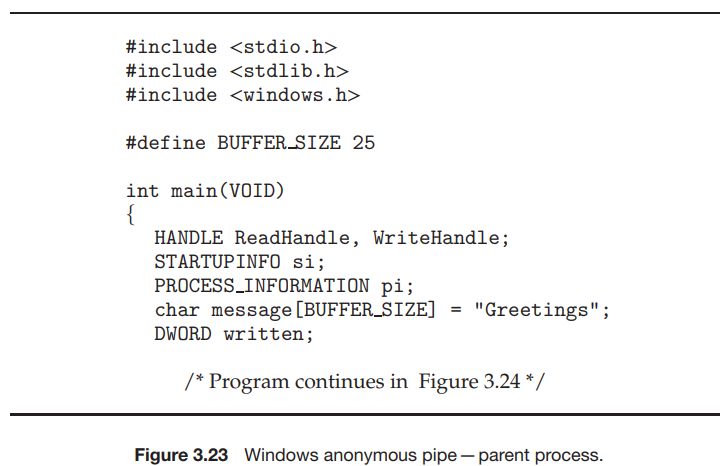
그림 3.23은 부모 프로세스가 자식 프로세스와 통신하기 위해 익명 파이프를 만드는 것을 보여준다. 자식 프로세스가 부모 프로세스가 만든 파이프를 자동으로 상속받는 UNIX 시스템과 달리 Windows에서는 프로그래머가 자식 프로세스가 상속받을 속성을 지정해야 한다. 이는 먼저 SECURITY_ATTRIBUTES 구조를 초기화하여 핸들을 상속할 수 있도록 한 다음 자식 프로세스의 표준 입출력 핸들을 파이프의 읽기 또는 쓰기 핸들로 리다이렉션하여 수행된다. 또한 파이프가 반이중이므로, 자식이 파이프의 쓰기 끝을 상속하는 것을 금지해야 한다.
 | 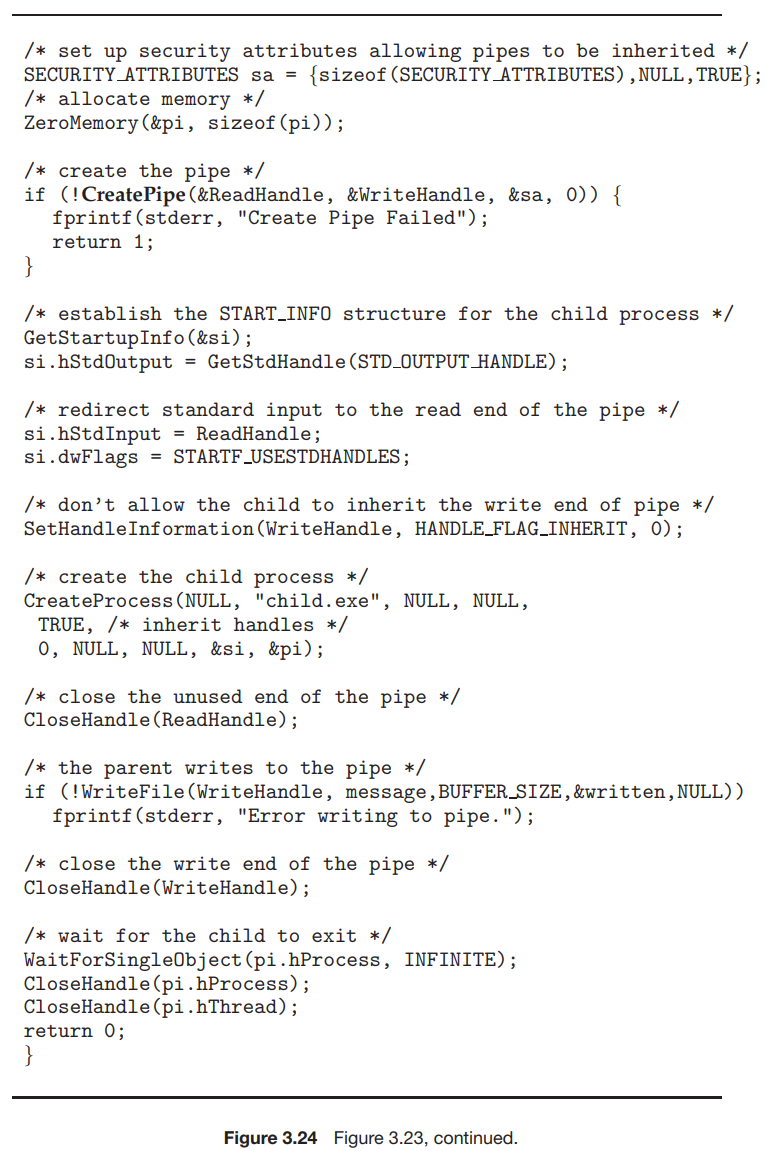 |
|---|
자식 프로세스를 만드는 프로그램은 그림 3.10의 프로그램과 비슷하지만, 다섯 번째 매개변수가 TRUE 로 설정되어 자식 프로세스가 부모로부터 지정된 핸들을 상속받게 된다. 파이프에 쓰기 전에 부모는 먼저 파이프의 사용되지 않는 읽기 끝을 닫는다. 파이프에서 읽는 자식 프로세스는 그림 3.25에 나와있다. 파이프에서 읽기 전에 이 프로그램은 GetStdHandel() 을 호출하여 파이프에 대한 읽기 핸들을 얻는다.

일반적인 파이프는 UNIX와 Windows 시스템 모두에서 통신하는 프로세스 간에 부모-자식 관계가 필요하다. 이러한 파이프는 동일한 머신의 프로세스 간의 통신에서만 사용할 수 있음을 의미한다.
3.7.4.2 Named Pipes
일빈 파이프는 프로세스 쌍이 통신할 수 있도록 하는 간단한 메커니즘을 제공한다. 그러나 일반 파이프는 프로세스가 서로 통신하는 동안만 존재한다. UNIX와 Windows 시스템에서 프로세스가 통신을 마치고 종료되면 일반 파이프는 더 이상 존재하지 않는다.
네임드 파이프(명명된 파이프)는 훨씬 강력한 통신 툴을 제공한다. 통신은 양방향일 수 있으며, 부모-자식 관계는 필요하지 않다. 네임드 파이프가 설정되면 여러 프로세스가 통신에 사용할 수 있다. 사실, 일반적인 시나리오에서 네임드 파이프에는 여러 작성자가 있다. 또한, 네임드 파이프 통신 프로세스가 완료된 후에도 계속 존재한다. UNIX와 Windows 시스템은 모두 네임드 파이프를 지원하지만 구현 세부 사항은 크게 다르다. 다름으로, 이러한 각 시스템의 네임드 파이프를 살며본다.
네임드 파이프는 UNIX 시스템에서 FIFO라고 한다. 일단 만들어지면, 파일 시스템에서 일반적인 파일로 나타난다. FIFO는 mkfifo() 시스템 콜로 만들어지고 일반적인 open(), read(), writer(), close() 시스템 콜로 조작된다. 파일 시스템에서 명시적으로(명백하게) 삭제될 때 까지 계속 존재한다. FIFO는 양방향 통신을 허용하지만, 반이중 전송만 허용된다. 데이터가 양방향으로 이동해야 하는 경우 일반적으로 두 개의 FIFO가 사용된다. 또한, 통신 프로세스는 동일한 머신에 존재해야 한다. 머신 간 통신이 필요한 경우 소켓(섹션 3.8.1)을 사용해야 한다.
Windows 시스템의 네임드 파이프는 UNIX 대응품보다 더 풍부한 통신 메커니즘을 제공한다. 전이중 통신이 허용되며, 통신 프로세스는 동일하거나 다른 머신에 존재할 수 있다. 또한 UNIX FIFO를 통해 바이트 지향 데이터만 전송할 수 있는 반면, Windows 시스템은 바이트 또는 메시지 지향 데이터를 허용한다. 네임드 파이프는 CreateNamedPipe() 함수로 생성되고, 클라이언트는 ConnectNamedPipe() 를 사용하여 네임드 파이프에 연결할 수 있다. 네임드 파이프를 통한 통신은 ReadFile() 및 WriteFile() 함수를 사용하여 수행할 수 있다.
파일 서술자(file descriptor)
리눅스/유닉스 계열 시스템에서 프로세스가 파일을 다룰 때 사용하는 것으로, 운영체제가 특정 파일에 할당해주는 정수값, 윈도우와 C에서의 파일 핸들과 유사
프로시저(procedure)
하나의 프로지서는 특정 작업을 수행하기 위한 프로그램의 일부(명령어 모듬 또는 코드 블럭), 쉽게 말하면 함수
섹션 객체(section object)
공유할 수 있는 메모리의 섹션, 프로세스는 섹션 객체를 사용하여 메모리 주소 공간의 일부를 다른 프로세스와 공유할 수 있다.