공룡책(Operating System Concepts)
1.[운영체제] Chapter 1. Introduction

운영체제는 컴퓨터 하드웨어를 관리하는 소프트웨이다. application 프로그램들이 동작하는 환경을 제공하는interrupt들은 주요 방법이다. 하드웨어와 운영체제가 상호작용하는컴퓨터가 프로그램들을 실행하는 일을 하기 위해서, 프로그램들은 반드시 메인 메모리에 있어야
2.[운영체제] Chapter 2.5 Linkers and Loaders
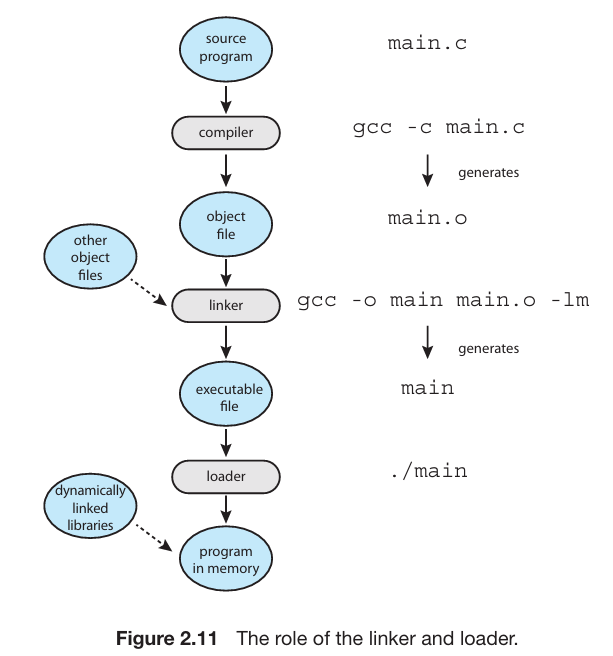
보통, 프로그램은 바이너리 실행 가능한 파일로 디스크에 존재한다. -예를 들어, a.out 또는 prog.exe -CPU가 동작하기 위해서, 프로그램은 반드시 메모리에서 가져오고 프로세스 맥락에 위치해야한다.이 섹션에서, 우리는 이 절차 단계를 설명한다, 프로그램 컴파
3.[운영체제] Chapter 2.10 Operating-System Debugging
대강 말해서, 디버깅은 하드웨어와 소프트웨어에서 시스템의 에러를 찾고 고치는 활동이다. 성능 문제도 버그로 여거져서, 디버깅은 또한 프로세싱의 병목현상을 제거하여 성능을 개선하는 성능 튜닝도 포함된다.사용자 레벨 프로세스 코드를 디버깅하는 것은 어려운 일이다. 운영체제
4.[운영체제] Chapter 2.7 Operating-System Design and Implementation
이 섹션에서, 우리는 운영체제를 설계하고 구현하는 데 직면한 문제를 논의한다. 물론, 이러한 문제에 완전한 해결책은 없지만, 성공적으로 증명된 접근방식이 있다. 2.7.1 Design Goals 시스템을 설계하는 것의 첫 번째 문제는 목표와 사양을 정의하는 것이다.
5.[운영체제] Chapter 3.3 Operations on Processes

대부분의 시스템의 프로세스들은 동시에 실행될 수 있고, 동적으로 생성되고 삭제될 수 있다. 따라서, 시스템은 프로세스 생성과 종료 메커니즘을 제공해야한다. 3.3.1 Process Creation 실행 과정에서, 프로세스는 여러 개의 새로운 프로세스를 생성할 수 있다
6.[운영체제] Chapter 3.7 Examples of IPC Systems
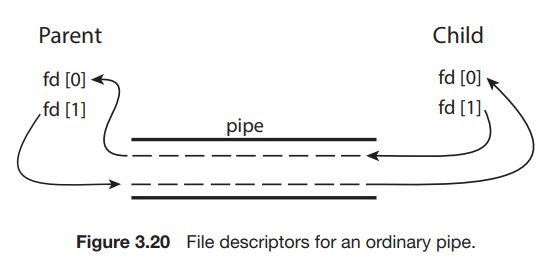
네 가지 IPC 시스템을 살펴본다. 공유 메모리를 위한 POSIX API Mach(마크) 운영체제에서 메시지 전달 논의 특정 유형의 메시지 전달을 제공하는 메커니즘으로 공유 메모리는 사용하는 Windows IPC UNIX 시스템에서 가장 초기의 IPC 메커니즘 중 하나
7.[운영체제] Chapter 4. Treads & Concurrency

스레드는 CPU 활용의 기본 단위로, 스레드 ID, 프로그램 카운터(PC), 레지스터 세트, 스택으로 구성된다. 스레드는 동일한 프로세스에 속한 다른 스레드와 코드 섹션, 데이터 섹션, 열린 파일 및 신호와 같은 기타 운영 체제 리소스를 공유한다. 기존 프로세스에는 싱
8.[운영체제] Chapter 4.4 Thread Libraries

스레드 라이브러리(thread library)는 프로그래머에게 스레드를 만들고 관리하기 위한 API를 제공한다. 스레드 라이브러리를 구현하는 두 가지 주요한 방법이 있다.커널 지원 없이 사용자 공간에서 라이브러리를 완전히 제공하는 것. 라이브러리의 모든 코드와 데이터
9.[운영체제] Chapter 4.5 Implicit Threading
OpenMP는 컴파일러 지시문(지침) 세트이자 C, C++ 또는 FORTRAN으로 작성된 프로그램을 위한 API로, 공유 메모리 환경에서 병렬 프로그래밍을 지원한다. OpenMP는 병렬 영역을 병렬로 실행될 수 있는 코드 블록으로 식별한다. 애플리케이션 개발자는 병렬
10.[운영체제] Chapter5.1 Basic Concepts
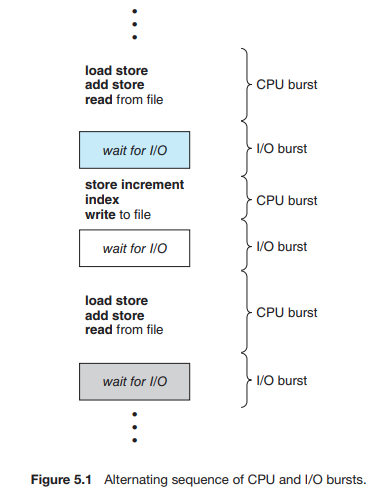
단일 CPU 코어가 있는 시스템에서는 한 번에 하나의 프로세스만 실행할 수 있다. 다른 프로세스는 CPU 코어가 비어서 다시 스케줄링될 수 있을 때까지 기다려야 한다. 멀티프로그래밍의 목적은 CPU 활용도를 극대화하기 위해 항상 일부 프로세스를 실행하는 것이다. 프로세
11.[운영체제] Chapter5.4 Thread Scheduling

사용자 수준 스레드와 커널 스레드의 한 가지 차이점은 스케줄링 방식에 있다. 다대일 및 다대다 모델을 구현하는 시스템에서 스레드 라이브러리는 사용자 수준 스레드가 사용 가능한 LWP(Light-weight process) 에서 실행되도록 스케줄링한다. 이 방식은 동일한
12.[운영체제] Chapter5.6 Real-Time CPU Scheduling
실시간 운영체제의 CPU 스케줄링은 특정 문제를 포함한다. 일반적으로, soft 실시간 시스템과 hard 실시간 시스템을 구분할 수 있다.Soft real-time system중요한 실시간 프로세스가 언제 스케줄링될지 보장하지 않고, 그 프로세스가 중요하지 않은 프로세
13.[운영체제] Chapter6 Synchronization Tools

copperating process 시스템에서 실행되는 다른 프로세스에 영향을 미치거나 받을 수 있는 프로세스 논리적인 주소 공간을 직접 공유하거나 공유 메모리 또는 메세지 전달을 통해서만 데이터를 공유하도록 허용될 수 있음. but, 공유 데이터에 동시 액세스는 데이
14.[운영체제] Chapter7.3 POSIX Synchronization
이전 섹션에서 논의한 동기화 방법은 커널 내의 동기화와 관련되므로 커널 개발자에게만 제공된다. 반면에, POSIX API는 사용자 레벨에서 프로그래머가 사용가능하고, 특정 운영 체제 커널의 일부가 아니다.이 섹션에서는, Pthreads와 POSIX API에서 사용할 수
15.[운영체제] Chapter8.2 Deadlock in Multithreaded Applications

deadlock 문제를 식별하고 관리하는 방법을 살펴보기 전에, 먼저 POSIX mutex lock를 사용하서 멀티스레드 Pthread 프로그램에서 deadlock이 발생하는 방법을 설명한다. pthread_mutex_init() 함수는 unlock된 mutex를 초기
16.[운영체제] Chapter8.5 Deadlock Prevention
8.3.1절에서 언급했든이 deadkock이 발생하려면 네 가지 필수 조선이 충족되어야 한다. 이러한 조건 중 적어도 하나가 충족될 수 없도록 보장함으로써, 데드락을 방지할 수 있다. 8.5.1 Mutual Exclution 상호 배제 조건은 hold되어야 한다. 즉
17.[운영체제] Chapter8.8 Recovery from Deadlock
detection 알고리즘이 deadlock이 존재한다고 판단하면, 여러 대안을 사용할 수 있다. 한 가지 가능성은 deadlock이 발생한 것을 운영자에게 알라고, 운영자가 데드락을 수동으로 처리하도록 하는 것이다. 다른 가능성은 시스템이 데드락에서 자동으로 reco
18.[운영체제] Chapter9 Main Memory
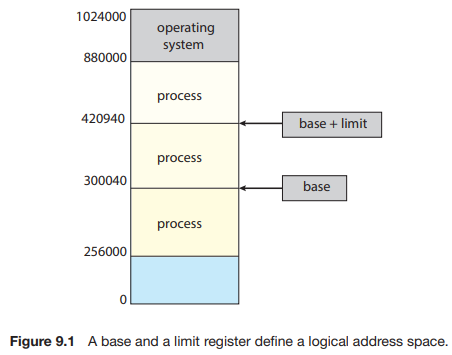
1장에서 본 것처럼, 메모리는 현대 컴퓨터 시스템의 작동에 핵심이다. 메모리는 각각 고유한 주소를 가진 많은 바이트 배열로 구성된다. CPU는 프로그램 카운터의 값에 따라 메모리에서 명령어를 가져온다. 이러한 명령어는 특정 메모리 주소에서 추가 로딩 및 저장을 유발할
19.[운영체제] Chapter9.4 Structure of the Page Table
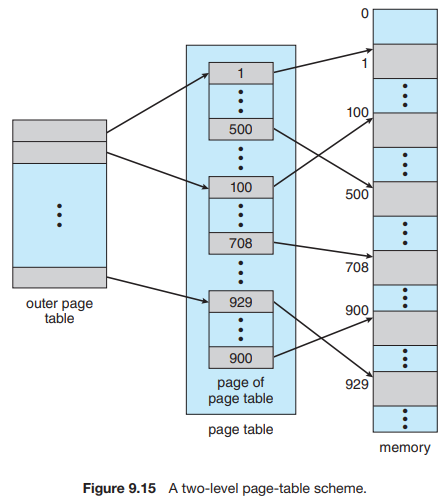
대부분의 최신 컴퓨터 시스템은 큰 논리적 주소 공간($2^{32}$ to $2^{64}$)을 지원한다. 이러한 환경에서, 페이지 테이블 자체가 지나치게 커진다. 예를 들어, 32bit 논리 주소 공간이 있는 시스템에서, 페이지의 크기가 4KB($2^{12}$)인 경우,
20.[운영체제] Chapter9.5 Swapping
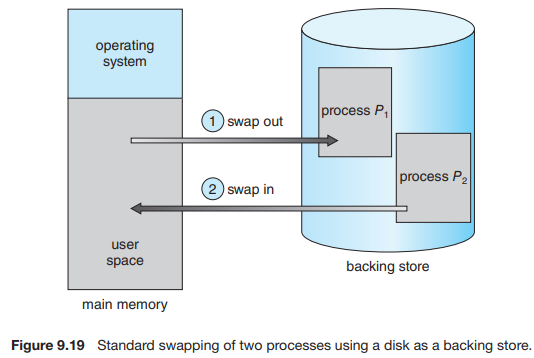
프로세스 명령어와 그 명령어가 작동하는 데이터는 실행되기 위해 메모리에 있어야 한다. 그러나, 피로세스의 일부는 일시적으로 메모리에서 backin store로 스왑된 다음 지속적인 실행을 위해 다시 메모리로 가져올 수 있다(그림 9.19). 스와핑은 모든 프로세스의 총
21.[운영체제] Chapter10.3 Copy-on-Write
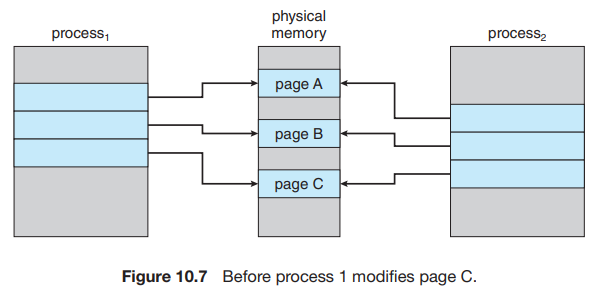
fork() 시스템 콜을 사용한 프로세스 생성은 페이지 공유와 유사한 기술을 사용하여, 처음에는 요구 페이징의 필요를 피할 수 있다. 이 기법은 빠른 프로세스 생성을 제공하고, 새로 생성된 프로세스에 할당해야 하는 새 페이지 수를 최소화 한다.fork() 시스템 콜은
22.[운영체제] Chapter10 Virtual Memory
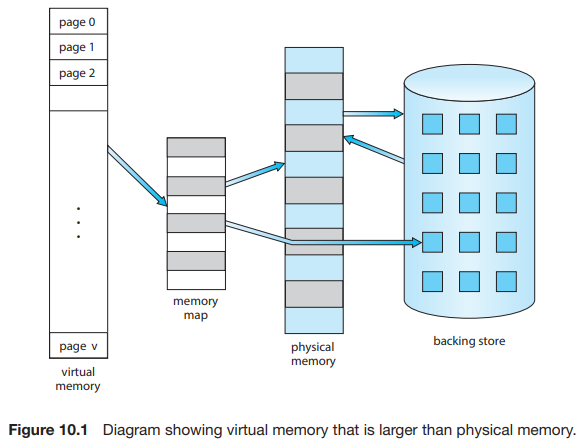
10.1 Background Chapter9에서 설명된 메모리 관리 알고리즘은 한 가지 기본 요구사항 때문에 필요하다: 실행되는 명령어는 물리 메모리에 있어야 한다. 이 요구사항을 충족하는 첫 번째 방법은, 전체 논리 주소 공간을 물리 메모리에 배치하는 것이다. Dyn
23.[운영체제] Chapter9.2 Contiguous Memory Allocation
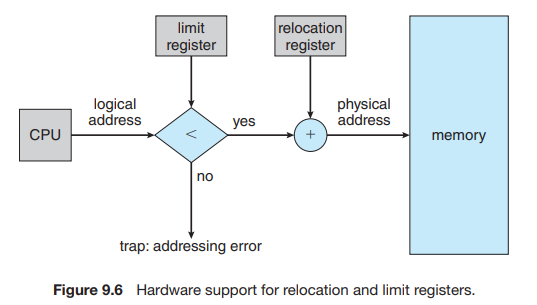
메인 메모리는 운영체제와 다양한 사용자 프로세스를 모두 수용해야 한다. 따라서 가능한 가장 효율적인 방식으로 메인 메모리를 할당해야 한다. 이 섹션에서는 초기 방법 중 하나인, 연속 메모리 할당에 대해 설명한다.메모리는 일반적으로 두 개의 파티션으로 나뉜다: 하나는 운
24.[운영체제] Chapter10.4 Page Replacement
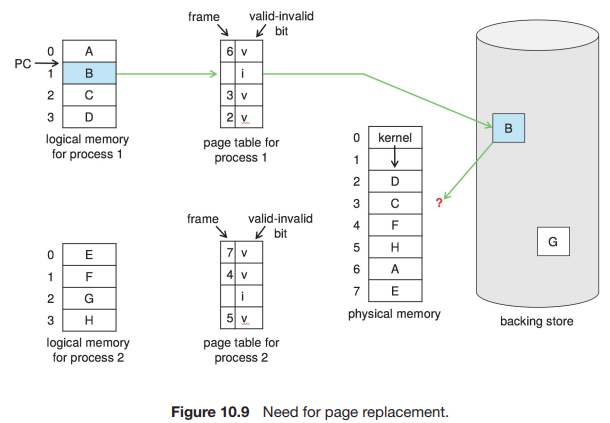
page-fault율에 대한 이전의 논의에서, 각 페이지는 처음 참조될 때, 최대 한 번 fault(폴트, 부재)된다고 가정했다. 하지만, 이 표현은 엄밀히 말하면 정확하지 않다. 10페이지짜리 프로세스가 실제로는 그 중 절반만 사용한다면, demand paging(요
25.[운영체제] Chapter10.6 Thrashing
프로세스에 "충분한" 프레임이 없는 경우, 즉 작업 집합의 페이지를 지원하는 데 필요한 최소 프레임 수가 없는 경우는 고려하면, 프로세스는 빠르게 페이지 폴트(page fault)를 발생시킨다. 이 시점에서 프로세스는 특정 페이지를 교체해야 한다. 그러나 모든 페이지가
26.[운영체제] Chapter10.9 Other Considerations
10.9.1 Prepaging 순수 요구 페이징의 명백한 특성 중 하나는 프로세스가 시작될 때 발생하는 페이지 폴트가 많다는 것이다. 이러한 상황은 초기 지역성을 메모리에 저장하려고 할 때 발생한다. prepaging은 이러한 높은 수준의 초기 페이징을 방지하기 위한