1. 해시 테이블
해시 테이블은 (Key, Value)로 데이터를 저장하는 자료구조입니다.
해시 테이블이 빠른 검색속도를 제공하는 이유는 내부적으로 배열(버킷)을 사용하여 데이터를 저장하고 있습니다. 해시 테이블은 각각의 Key값에 해시함수를 적용해 배열의 고유한 index를 생성하고, 이 index를 활용해 값을 저장하거나 검색합니다. 여기서 실제 값이 저장되는 장소를 버킷 또는 슬롯이라고 합니다.
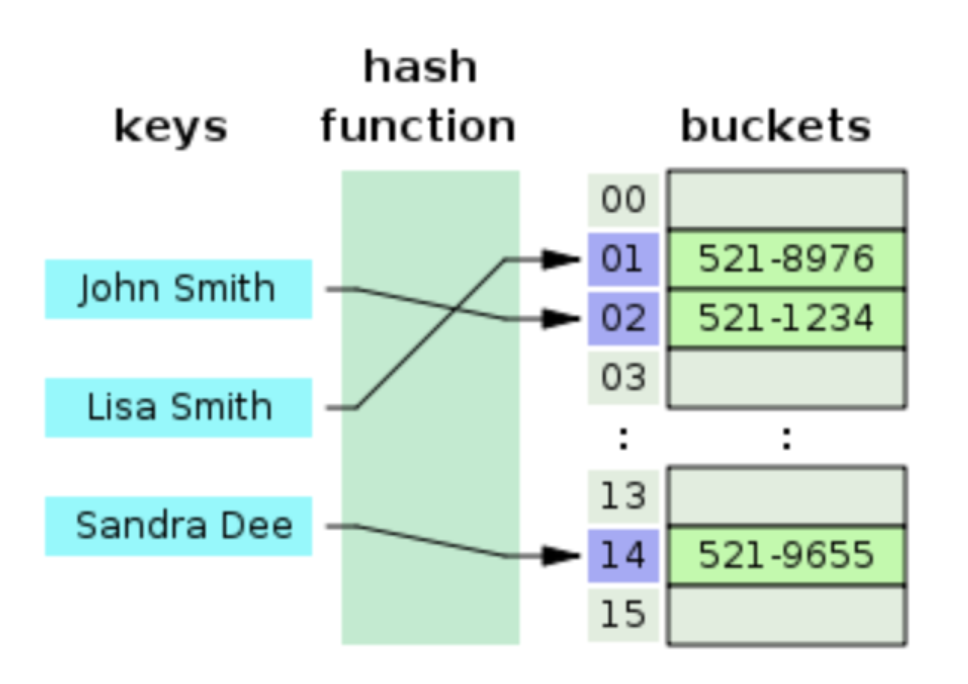
Python에서는 Dictionary로 제공을 하고 있고
Java에서는 HashMap과 HashTable로 제공하고 있습니다.
저는 Java에서 Key-Value가 필요할 땐 Map을 사용했었던것 같은데,
그렇다면 Key-Value로 동작하는 자료구조에서 Map과 HashMap의 차이가 무엇인지 궁금해졌습니다.
[JAVA] 2. Map과 Hash
Java에서는 Map의 종류가 다양합니다.
- HashMap: 기본적인 맵 구현체로, 키와 값을 쌍으로 저장합니다. 키의 해시코드를 사용하여 빠르게 검색할 수 있습니다. 순서가 보장되지 않으며, null 키와 null 값이 허용됩니다.
- LinkedHashMap:
HashMap을 기반으로 하며, 추가된 순서 또는 접근된 순서에 따라 요소를 정렬합니다. 순서가 유지되며 성능은HashMap에 비해 약간 느린 편입니다.- TreeMap: 레드-블랙 트리를 기반으로 하는 정렬된 맵 구현체입니다. 키에 대해 자동 정렬되며, 키에 대한 비교를 제공하는
Comparator를 사용하여 정렬 방식을 지정할 수 있습니다. 순서가 유지되며 성능은HashMap에 비해 느린 편입니다.- ConcurrentHashMap: 멀티스레드 환경에 최적화된
HashMap의 변형입니다. 동시성에 대한 지원을 제공하며 높은 성능을 유지합니다. 단, 순서가 보장되지 않습니다.- Hashtable: 자바 초기부터 사용된 맵 구현체로, 키와 값을 쌍으로 저장합니다.
HashMap과 유사하지만 동기화되어 있어 멀티스레드 환경에서 안전하게 사용할 수 있습니다. 그러나 성능이 떨어지며 현대적인 Java에서는ConcurrentHashMap을 사용하는 것이 권장됩니다.
다양한 Map의 종류들은 Map Interface를 상속 받아 구현되었습니다. 공식문서
사실 Map은 인터페이스이기 때문에 직접 인스턴스를 생성할 수 없습니다.
❌ Map<String, Object> map = new Map<String, Object>();
그래서 제가 작성한 코드들을 살펴보았습니다.
이런식으로 Map은 인스턴스를 생성할 수 없기 때문에, HashMap으로 인스턴스를 생성하고 있었습니다!
HashMap<String, Object> map = new HashMap<String, Object>();또한 Map 인터페이스 자료형으로 선언할 수도 있는데, 이렇게 하면 다른 Map 함수와도 유연성이 높아지기 때문에 Map 인터페이스 자료형으로도 많이 선언한다고 합니다.
Map<String, Object> map = new HashMap<String, Object>();2. 시간 복잡도
코테를 Python으로 볼 것이기 때문에, Dictionary의 시간 복잡도를 살펴본다면, 다음과 같습니다.
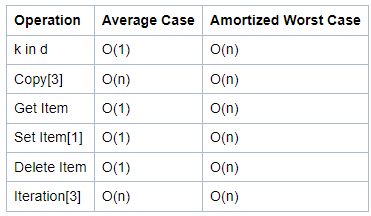
요소를 찾고, 요소를 설정하고, 삭제하는 모든 작업이 O(1)로 굉장히 빨랐습니다.
이렇게 HashTable은 굉장히 빠른 알고리즘입니다.
📢 자바도 마찬가지로 O(1) 입니다!!
3. Dictionary 사용법
선언
- Key로는 Mutable한 객체는 사용할 수 없음! ❌
set / list / dict
newdict = dict(alice = 5, bob = 20, tony= 15, suzy = 30)
# 값 추가 (Key : hi / Value : 7)
newdict['hi'] = 7접근
newdict['alice'] # 5
newdict['bob'] # 20
'alice' in newdict # True
'korean' in newdict # False삭제
del newdict['alice']그 외에도 여러가지 메소드들이 존재합니다.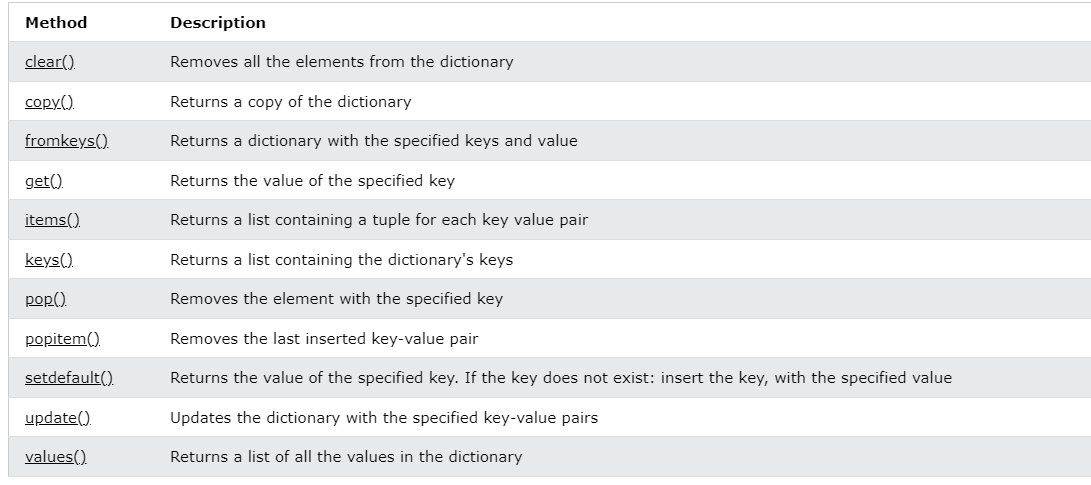
출처
- Map 종류 : https://statuscode.tistory.com/31
