논문링크
Introduction
기존과 다른 Pre-training
현재의 vision-Language 기반 모델들은 여러 사전 학습 목표를 동시에 사용(Ex. VLMO는 3가지 학습). 하지만 논문에서는 이러한 방식은 비효율적이라고 언급
→ ‘마스크 데이터 모델링’이라는 방법만을 사용
BEiT-3
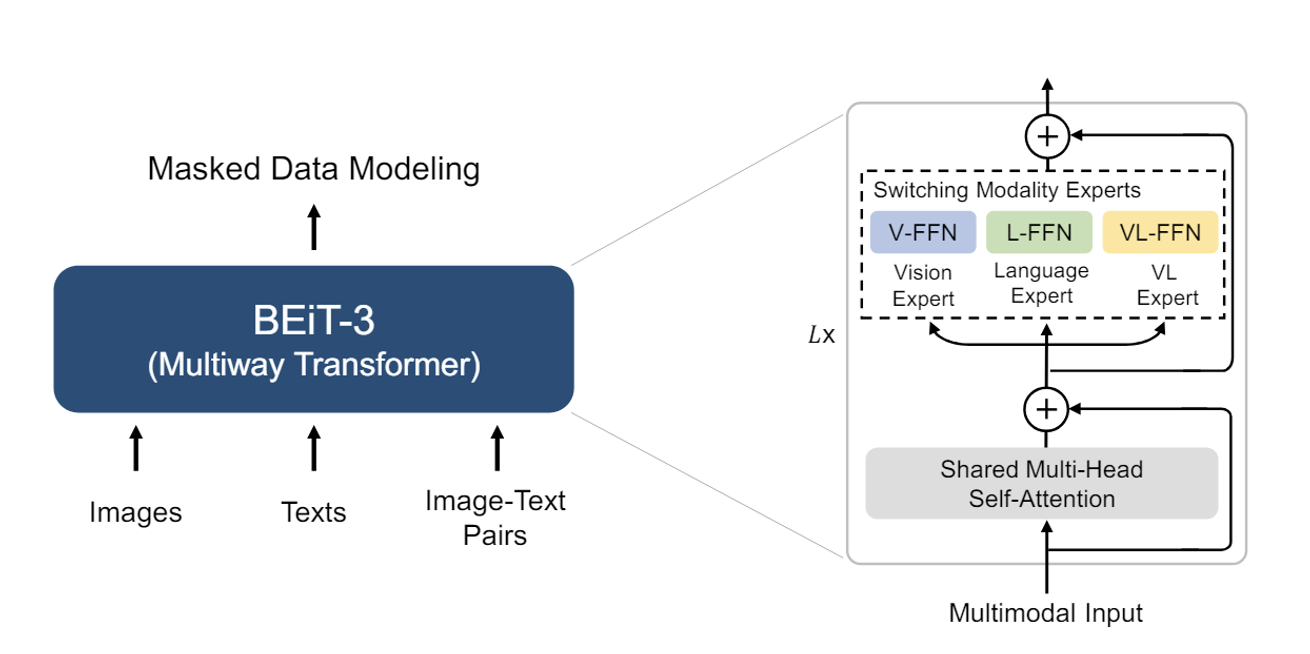
Multiway Transformers
- 하나의 공유된 self-attention module을 이용
- 각 block에는 모달리티별 전문가(feed-forward network)가 존재
- 마지막 3개의 Layer만 VL-FFN을 사용(fusion encoders)
Q.왜 모달리티가 달라져도 동일한 self-attention module을 사용하나요?
A. self-attention을 공유함으로써 서로다른 모달리티의 alignment(정렬 or 관계)를 학습 할 수 있고, deep fusion이 가능하다!
결론적으로 BEiT-3는 다양한 Task에 적용할 수 있어!
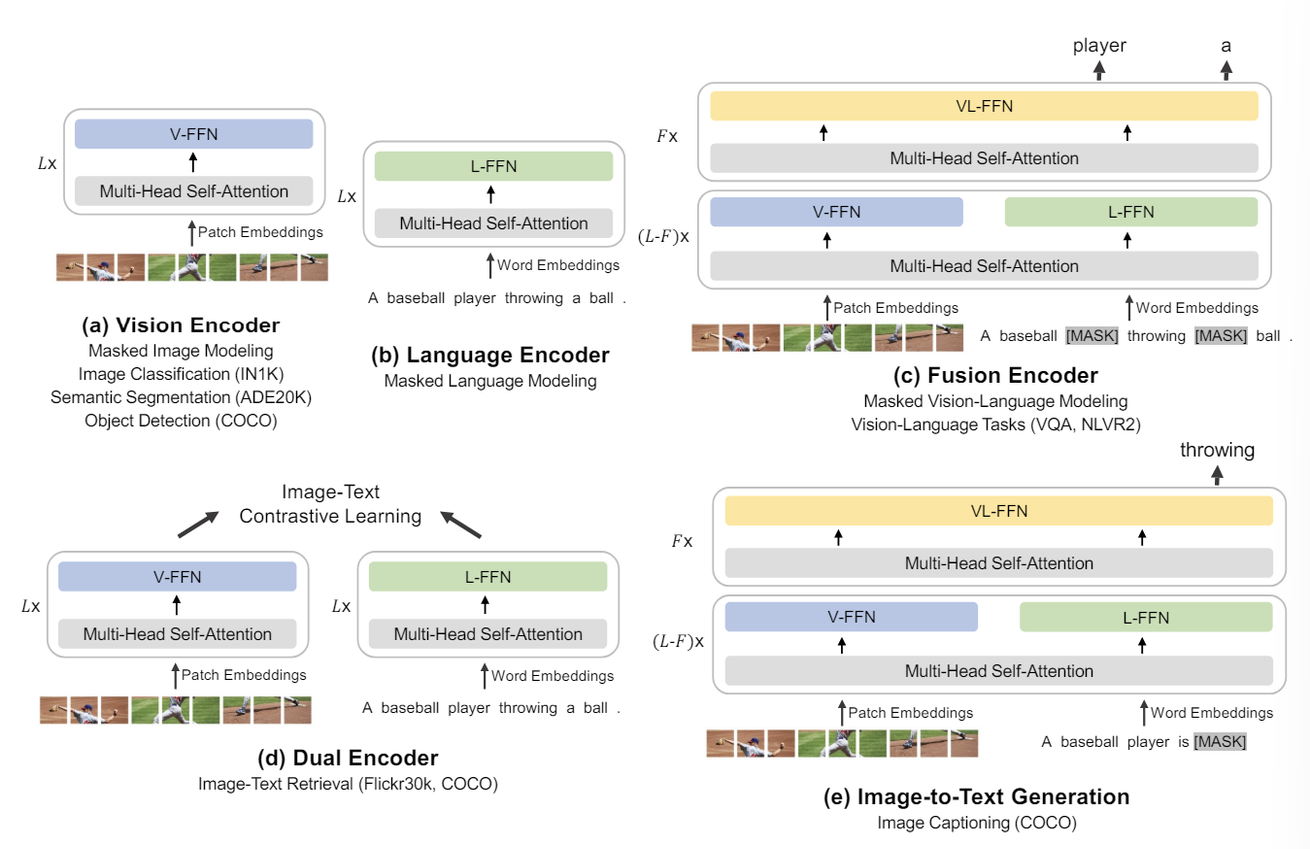
vision or language encoders: (a), (b)
fusion encoders: (c)
dual encoders for retrieval: (d)
seq-to-seq for image-to-text generation: (e)
Masked Data Modeling(마스크 데이터 모델링)
Masked Data Modeling 방법을 통해서 단일, 멀티 모달 데이터에대해서 사전학습을 진행
사전학습 방법: Random으로 token을 mask처리하고 해당 mask의 token을 찾는 방식으로 학습을 진행(BEiT,BERT 논문 참조)
→ representations, alignment of different modalities 학습
Text: SentencePiece tokenizer / Image: BEiT v2 tokenizer
Mask 비율: Text(15), image-text(50), image(40)
Scaling Up: BEiT-3 Pretrining
Backbone

- ViT-giant
- 13개의 V,L Expert & 3개의 V-L Expert
Pretraining Data

Pretraining Settings
- Batch: 6144(images:2048, texts:2048, image-text pairs:2048)
- 14x14 patch size / 224x224 resolution
- Augmentation: random resized cropping, horizontal flipping, color jittering
- SentencePiece tokenizer: 64k vocab size
- AdamW(β1 = 0.9, β2 = 0.98 and =1e-6 )
- cosine learning rate decay scheduler with a peak learning rate of 1e-3 and a linear warmup of 10k steps(decay=0.05)
- Stochastic depth with a rate of 0.1 is used
- BEiT initializationalgorithm4 is used to stabilize Transformer training
Experiments
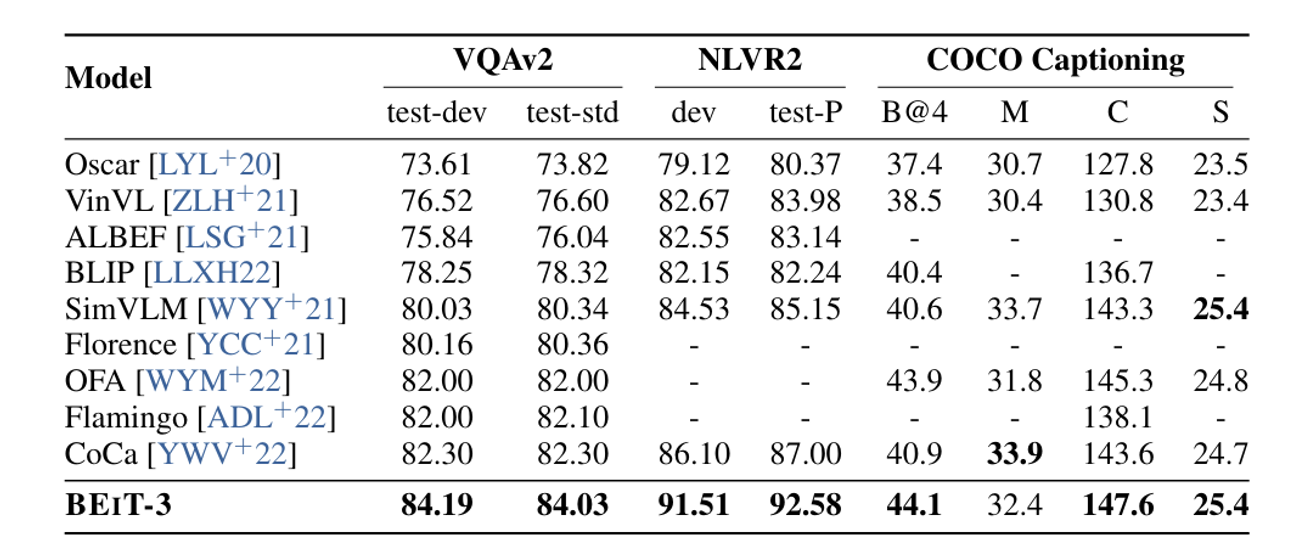
VQA(Visual Question Answering), NLVR2(Visual Reasoning), COCO Captioning(Image Captioning) 3가지 Task에서 SOTA달성
각 Task별 간단한 설명
- VQA: 이미지와 질문이 들어오면 3129개의 answer category중에서 1개를 선택하도록 한다
- Visual Reasoning: 주어진 텍스트 설명이 주어진 이미지 쌍에 대해 참인지 거짓인지를 판단
- Image Captioning: 주어진 이미지에 대해서 자연스러운 설명을 생성하도록 한다
Image-Text Retrieval
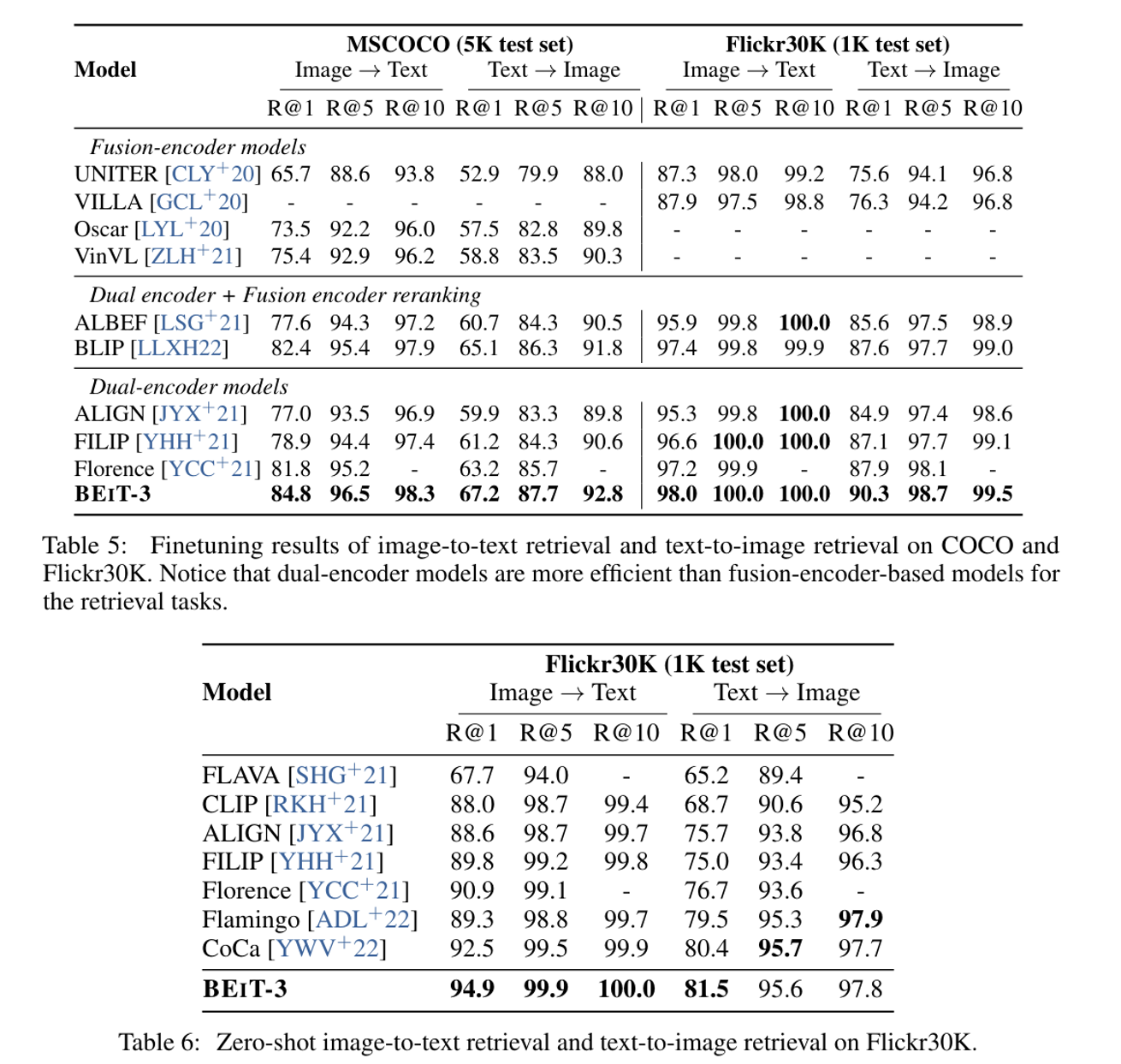
- Retrieval Task에서는 Fusion 방식보다 dual encoder 방식의 성능이 좋기때문에 기존 모델을 미세 조정
- 다른 모델들과 다르게 처음부터 contrastive learning을 하지 않았는데도 성능이 더 좋았다
- Fine-tuning전에 intermediate Finetuning단계에서 contrastive learning으로 성능 향상을 시켰다고 언급은했다
Vision Downstream Tasks
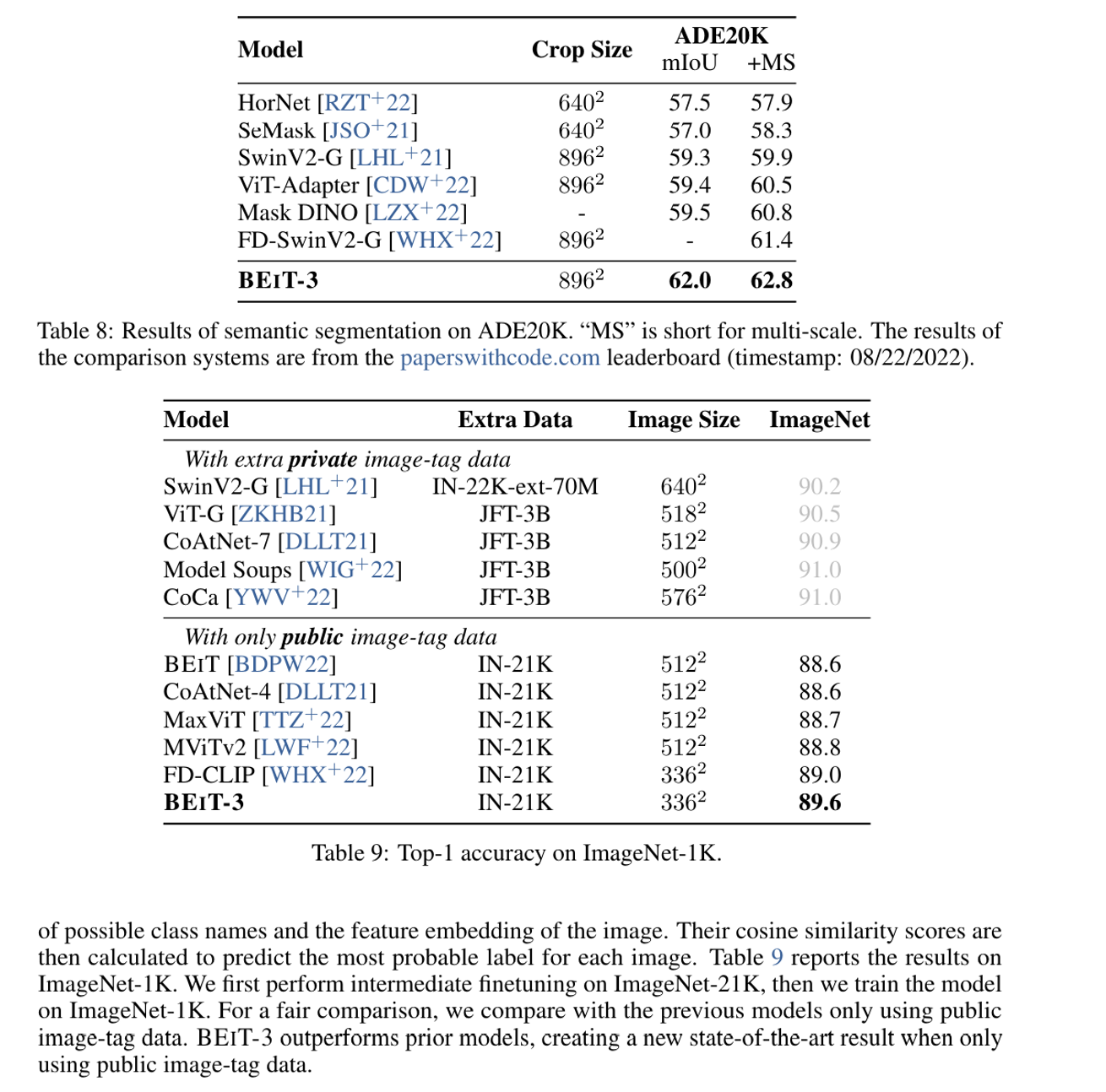
- Object Detection and Instance Segmentation
- Semantic Segmentation
- Image Classification
성능이 잘나왔다는 이야기를 중심으로하기때문에 자세한 내용은 논문을 참조하면 좋을 것 같다
Conclusion
모든 모달리티에 대해서 “통일된” 방식으로 학습을 진행했다. 그리고 이 방식은 성능이 잘 나왔다.
Appendix
Effects of Intermediate Finetuning for Retrieval
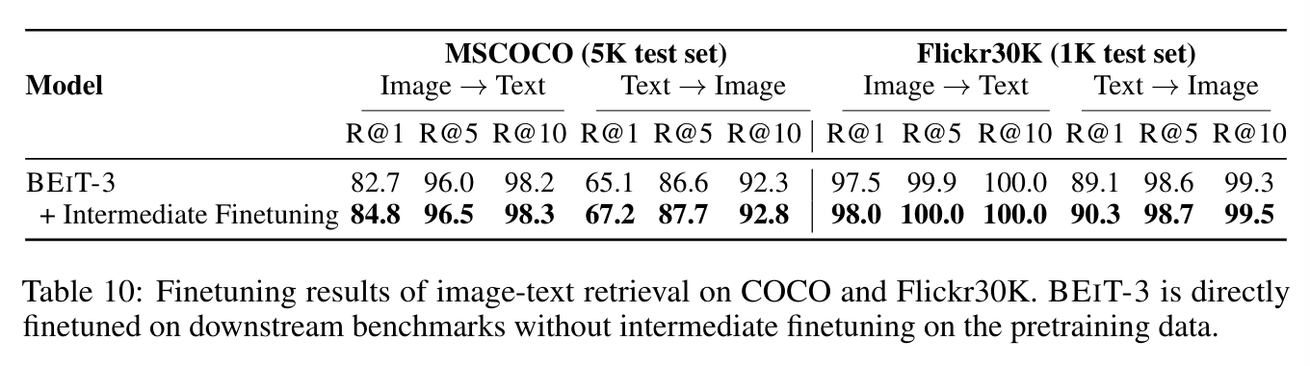
위의 설명에서 Retrieval Task를 수행하는 중 Intermediate Finetuning을 통해서 성능을 높였다고 한다. 이에 대한 설명이 Appendix에 더 자세히 나오는데 5 epoch, 16k batch size를 이용해서 학습을 진행했을 때 추가 성능이 개선된 것을 표로 확인할 수 있다
cf. 나머지 appendix는 하이퍼파라미터 설명들
개인적인 결론
해당 논문을 읽게 된 이유는 VLMO와 유사한 방식을 사용했기 때문에 비교를 위해서 읽어봤다. 하지만 결론적으로 말하자면 Masked Data Modeling 부분을 제외하고 다른 부분의 차이를 못느꼈다. 하지만 성능은 개선됐고 조금더 간단해졌다는 느낌을 받았다. 현재 VQA Task에 특화된 모델을 만들고 싶고 Baseline Model을 선정해야되는 입장에서 더 간단하고 성능 좋은 모델인 BEiT-3를 선택할거같다.
