VLMO: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts 논문 리뷰
논문 링크
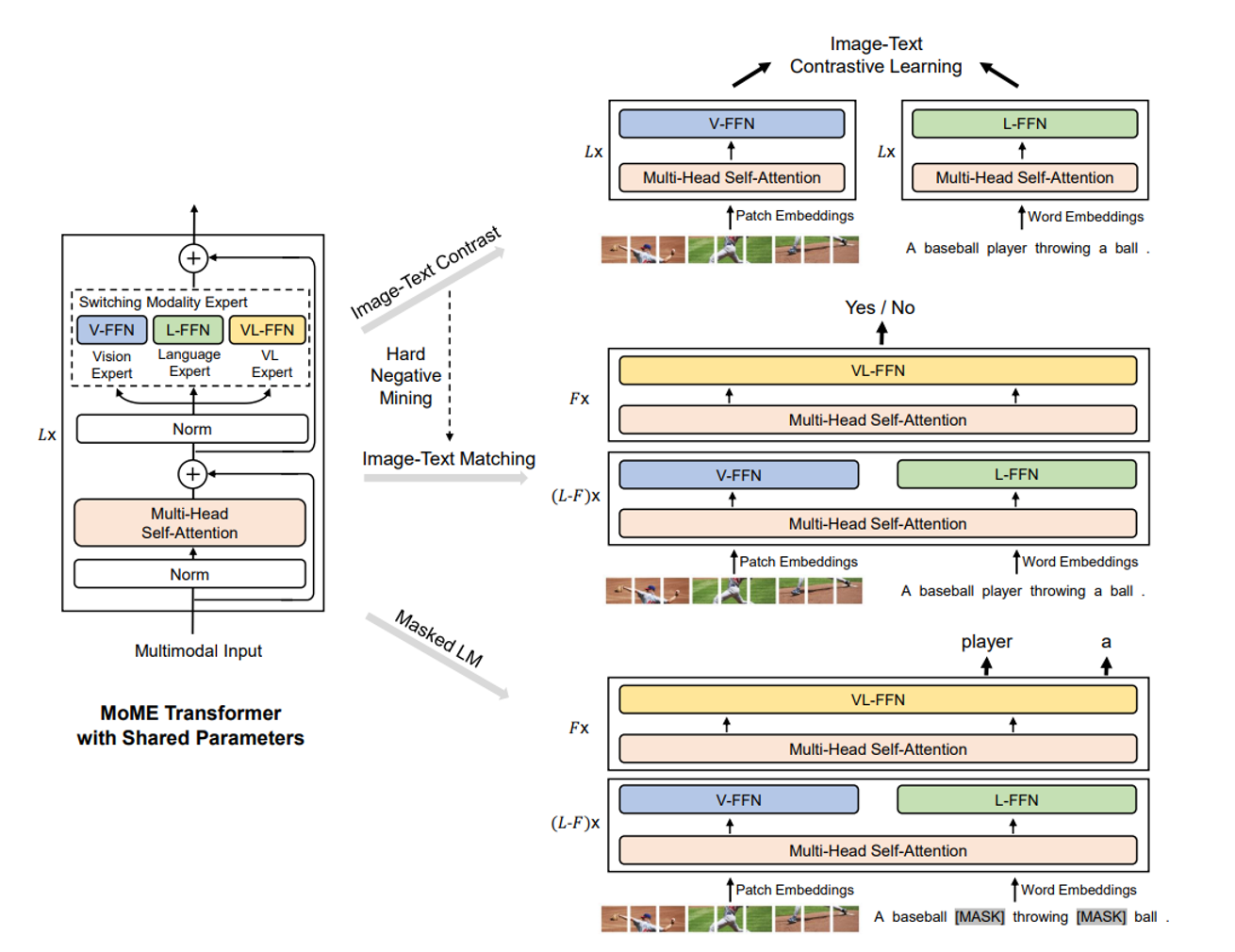
해당 리뷰에서는 VLMO에서 어떤 방식으로 어떻게 학습을 했는지를 리뷰
Backbone
Visual: BEiT
Language: BERT
2가지 방식 모두 Masked Data Modeling방식을 이용한 학습을 진행
아래에 BEiT-3 논문 리뷰 링크
https://velog.io/@guts4/BEiT-3-%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0
Stepwise Pre-training
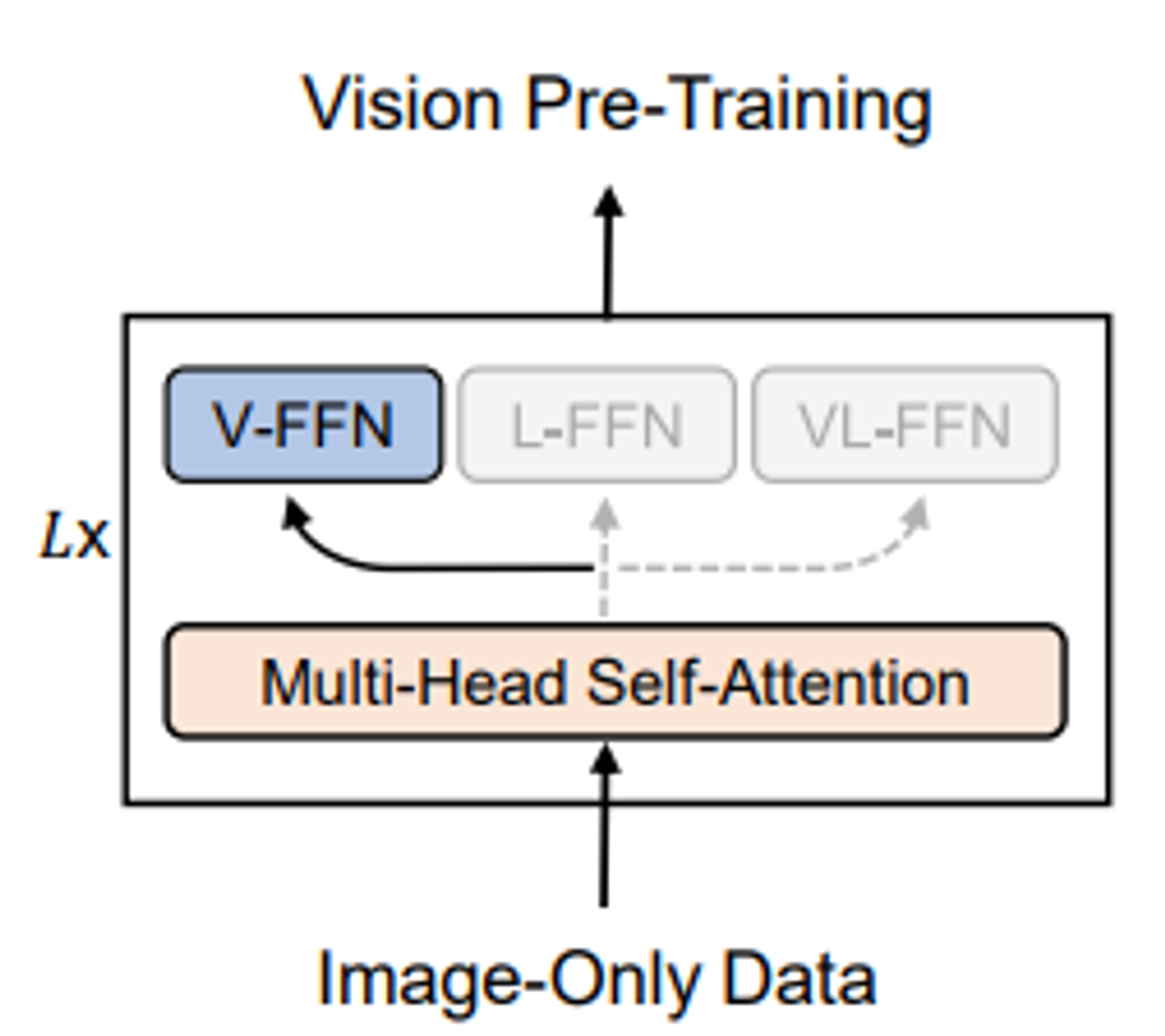
Stage1: BEiT + Self-Att + V-FFN 학습
BEiT방식을 이용해서 Image-only 데이터로 V-FFN(Visual Expert)와 Self-attention학습
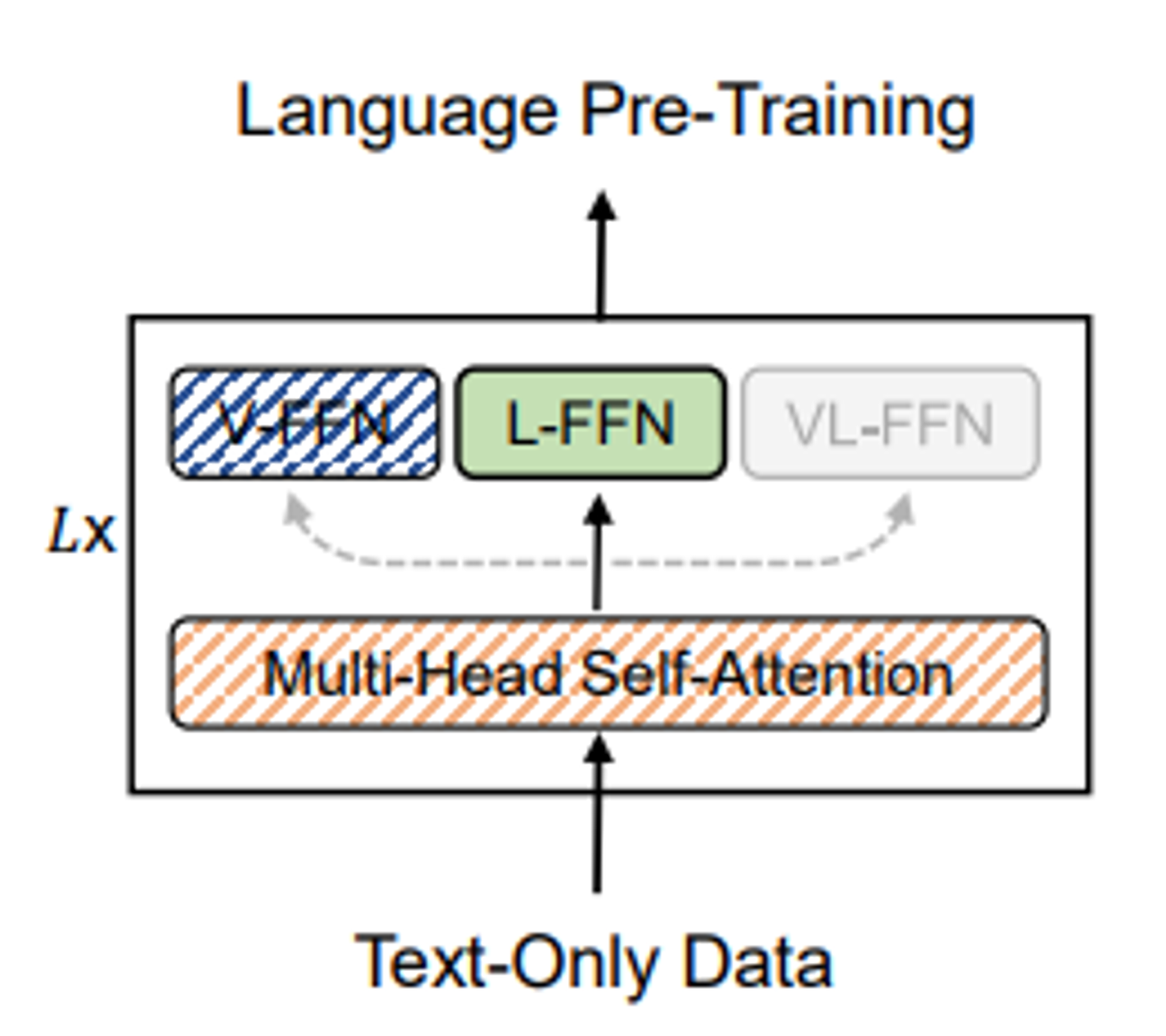
Stage2: BERT + L-FFN 학습
Text-only데이터로 L-FFN(Language Expert)학습
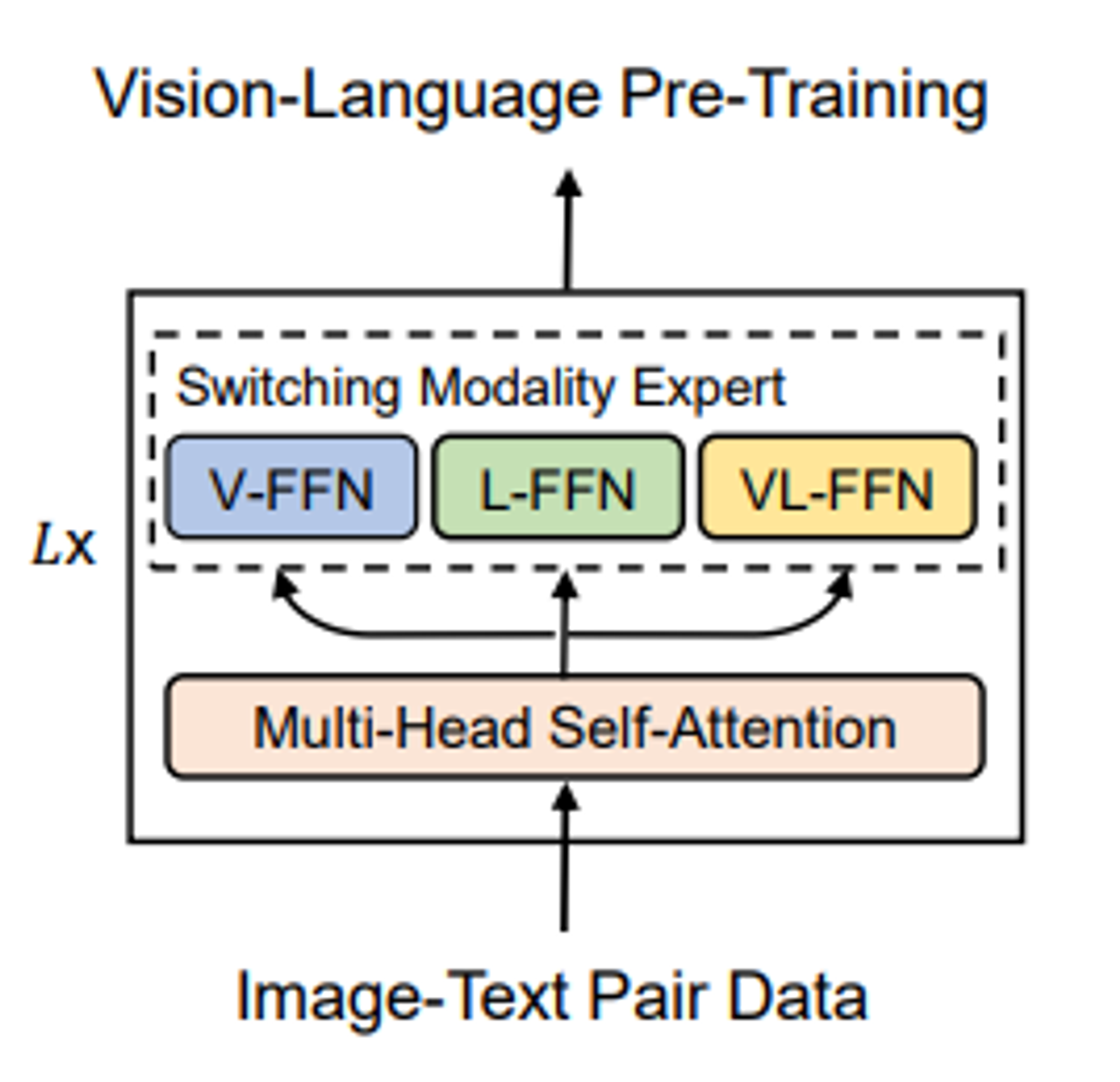
Stage3: BERT + BEiT + Self-Att + V-FFN + L-FFN + VL-FFN학습
image-text pair 데이터로 전체 model학습
각 모달리티별 Representation
Image Representation
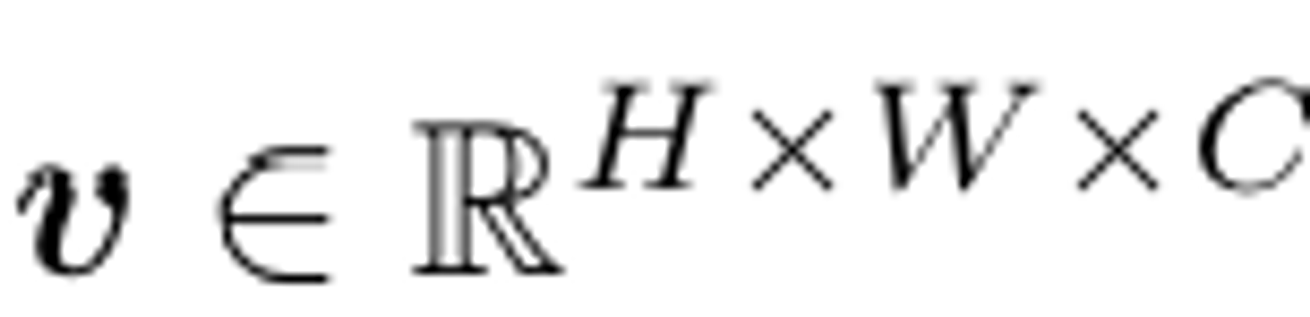
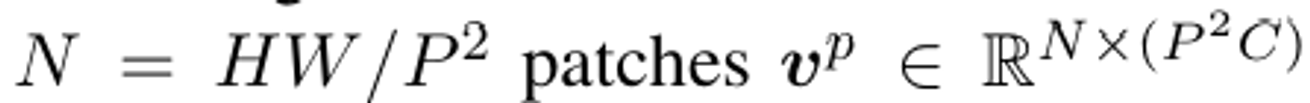
2D image는 N개의 패치들로 나눠진다
C: 차원 , (H,W): 이미지 해상도, (P,P): 패치 해상도
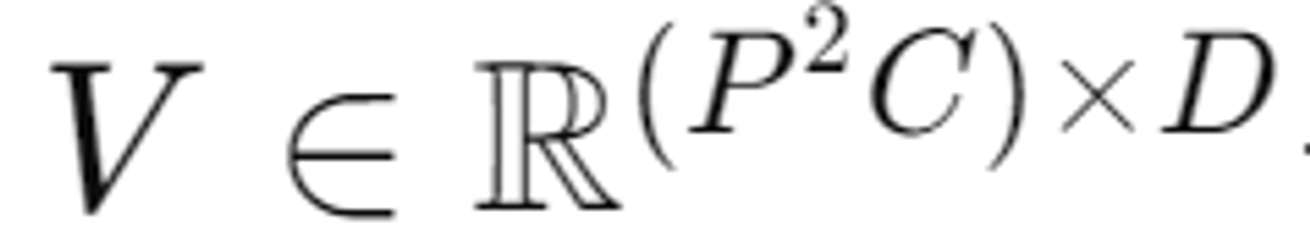
이후 이미 패치들은 벡터로 flatten되고 patch embedding 얻기 위해 project된다
I_CLS: 학습 가능한 특수 토큰 앞에 추가(sequence) → class
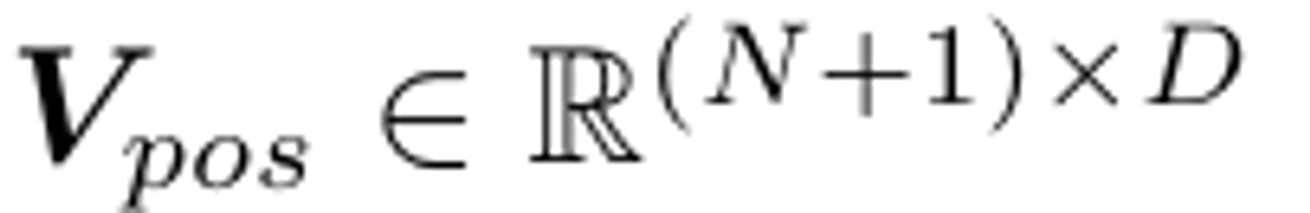
위치 임베딩 추가
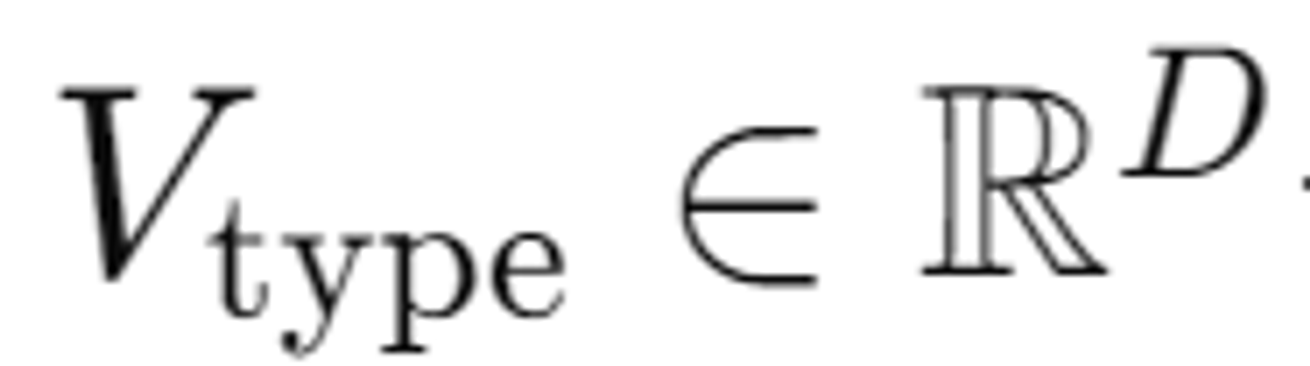
타입 임베딩 추가(입력의 타입 → 이미지)
최종
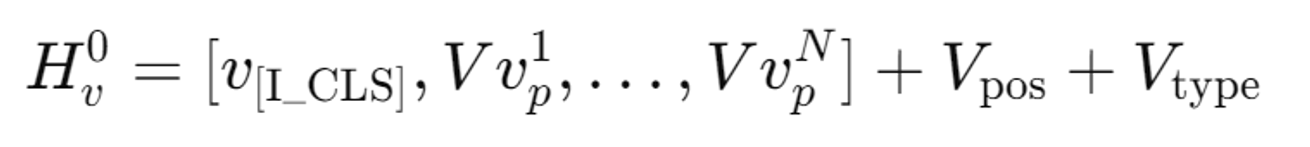
패치 임베딩 + 위치 임베딩 + 타입 임베딩(최종 차원은 모두 (N+1)*D)
Text Representatioin
BERT와 같다
WordPice를 이용해 텍스트를 토큰화
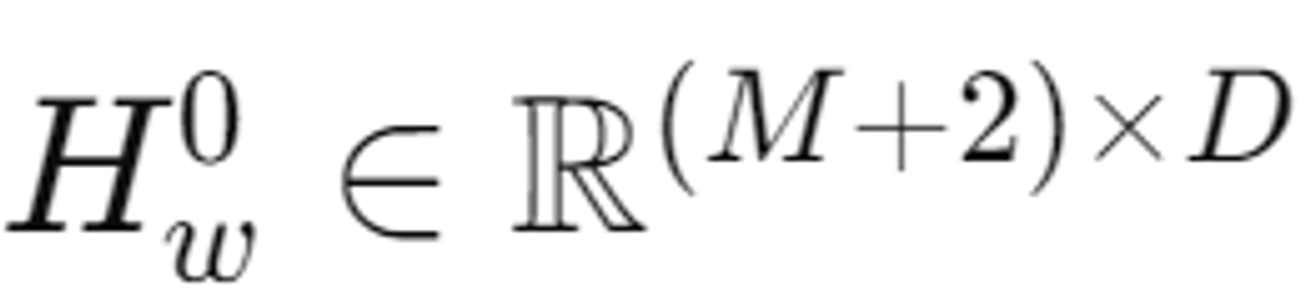
T_CLS(시작 토큰), T_SEP(특수 경계 토큰) 추가
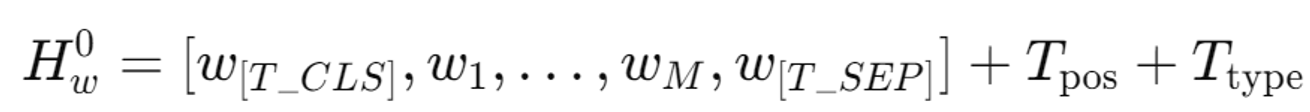
단어 임베딩 + 위치 임베딩 + 타입 임베딩(최종 차원은 모두 (M+2)*D)
Image-Text Representation
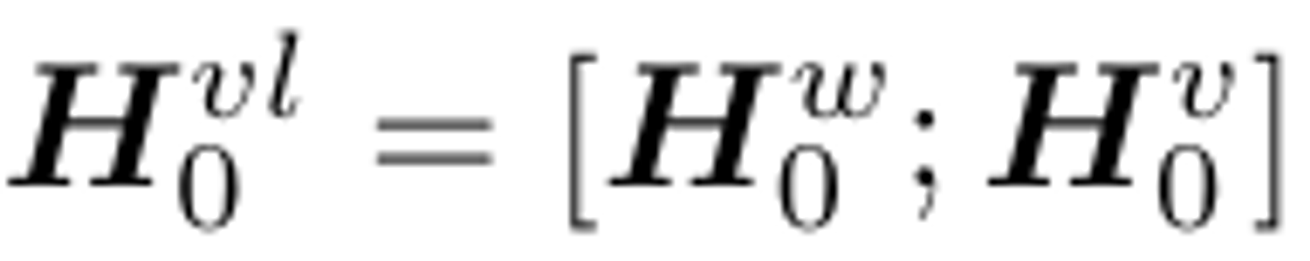
위에 2개를 concate한다
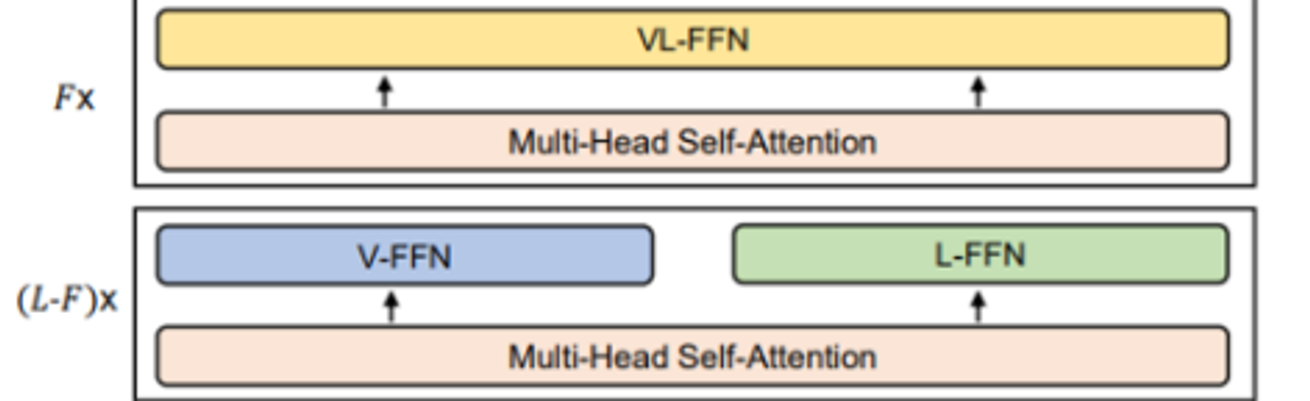
Mixture-of-Modality-Experts Transformer
기존 Transformer구조에서 FFN부분을 각 모달리티별 특화된 FFN인 MoME-FFN로 바꾼다
총 L개의 MOME가 존재하고 입력값은 이전 MOME의 출력값이 된다
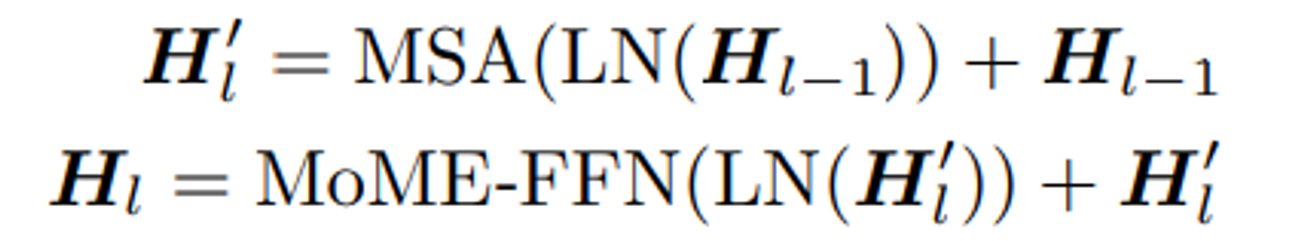
MSA: Multi-Head Self-Attention
MoME-FFN: vision expert (V-FFN), language expert (L-FFN) and vision-language expert (VL-FFN)
Vision-language expert: 모달리티간의 상관관계를 학습하기 위해 top layer로 설정한다
Pretraining Tasks
Image-Text Contrast
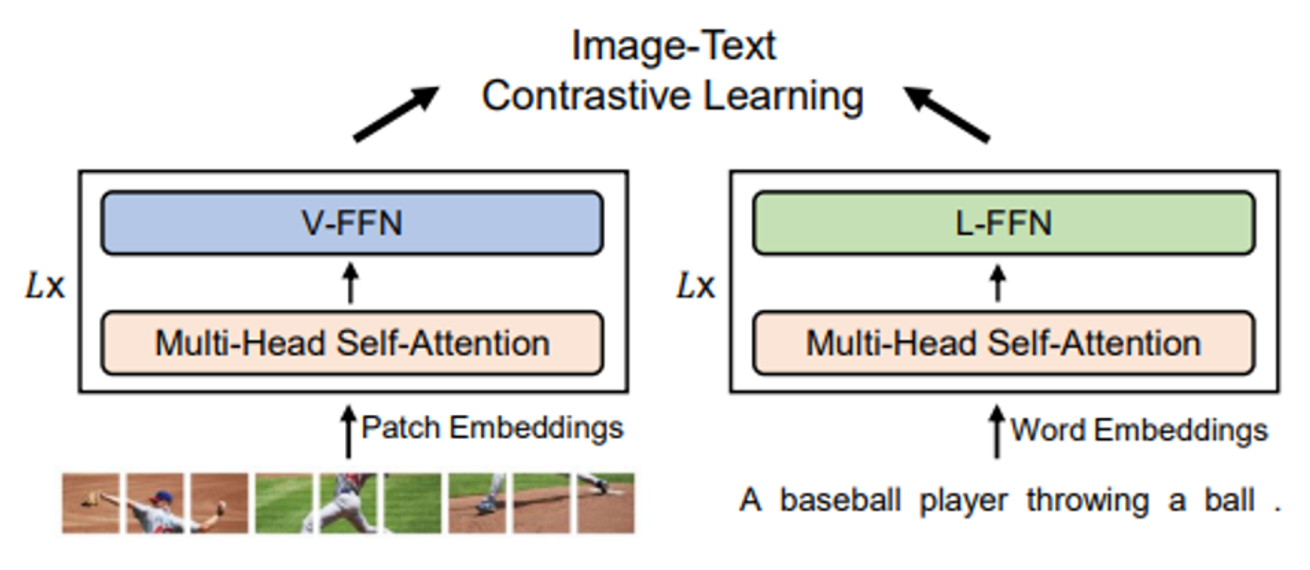
Output으로 나오는 I_CLS토큰과 T_CLS토큰을 이용해서 image와 text정보를 종합한다
N개의 positive pair와 N^2-N개의 negative pair에 대해서 positive pair의 유사도는 높이고 negative pair의 유사도는 낮춘다(자세한 내용은 CLIP 논문 참고)
Masked Language Modeling
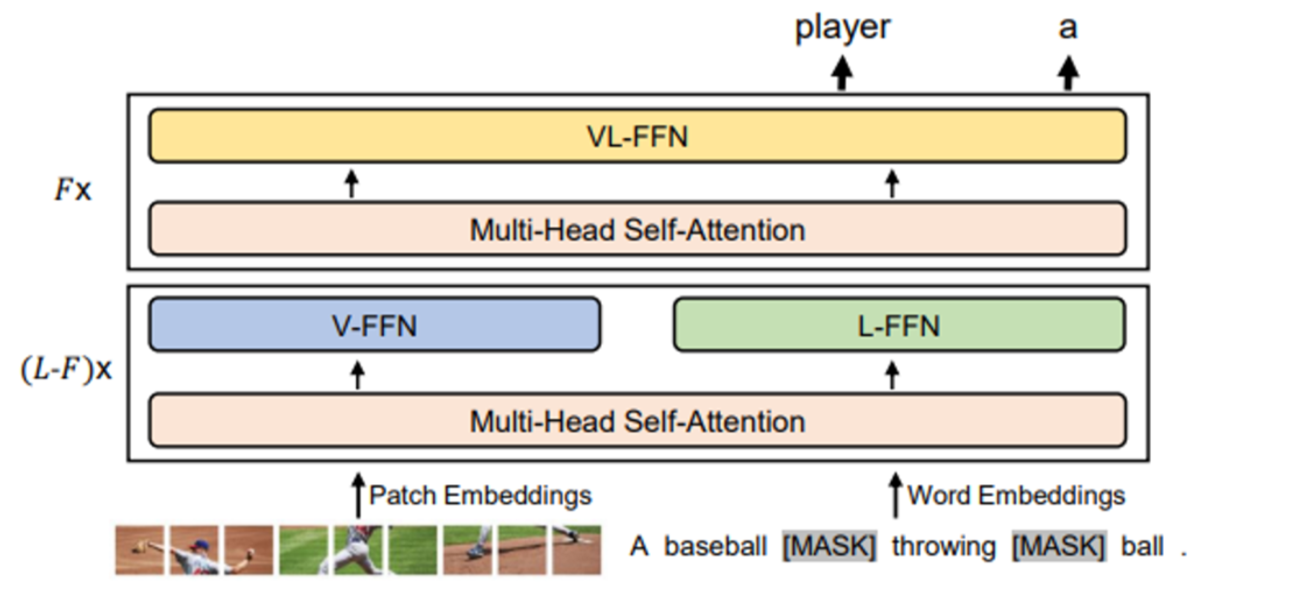
BERT 방식을 선택 → 15% masking한후 mask를 예측하는 방식으로 학습
→ The final output vectors of masked tokens are fed into a classifier over the whole text
vocabulary with cross-entropy loss
Image-Text Matching
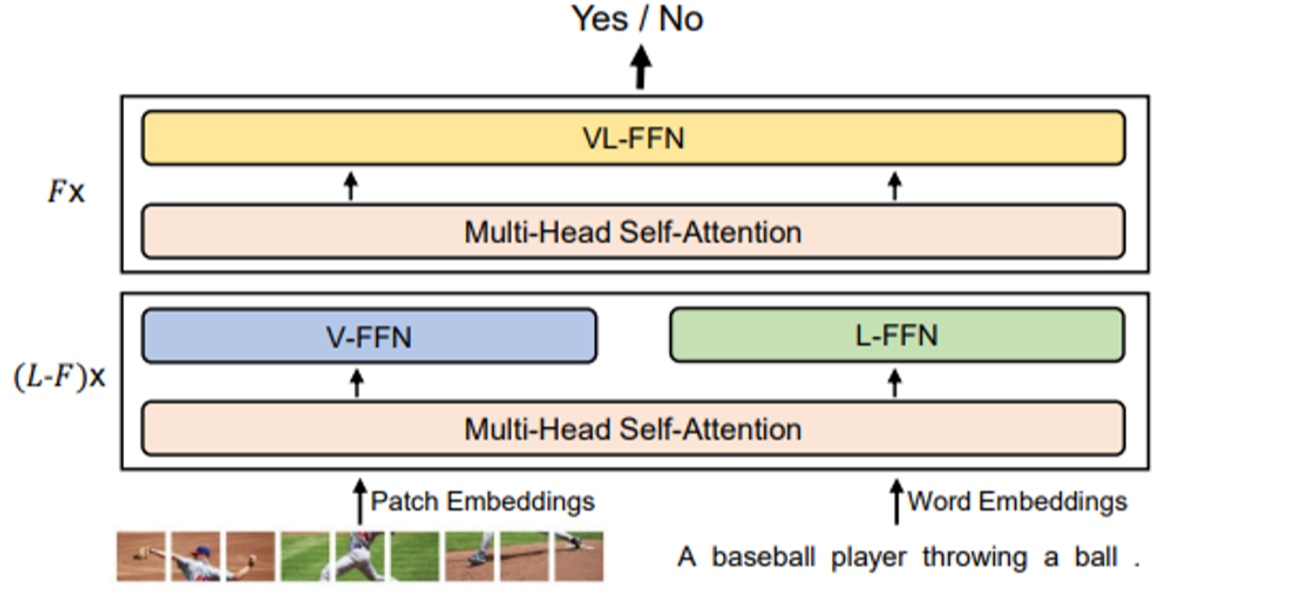
말그대로 image와 text가 매칭되는지 확인(Yes/No)
T_CLS token으로 마지막 값을 예측한다.
→feed the vector into a classifier with cross-entropy loss for binary classification
ALBEF를 기반으로 hard negative 사용 → 기존의 hard negative mining(single GPU)에서 global hard negative mining(all GPUs) → 성능증가
Experiments
Dataset
4개의 image captioning datasets이용
- Conceptual Captions(CC)
- SBU Captions
- COCO
- Visual Genome(VG)
→ 4M images와 10M image-text 페어
Model종류
VLMO-Base: 12-layer Transformer, 768 hidden size, 12 attention heads → 마지막 2개 layer를 vision-language expert
VLMO-Large: 24-layer Transformer, 1024 hidden size, 16 attnetion layers → 마지막 3개 layer를 vision-language expert
imtermidate: base-size(3072), large-size(4096) hidden
Training on Larger-scale Datasets
VLMo-Large 10억개의 noisy web image-text pair로 학습
pretrain: 200k steps, 16k batch size
train: 100k steps, 32k batch size
VQA(Visual Question Answering)
dataset: VQA2.0, 3129 answers중 선택
T_CLS 토큰을 사용
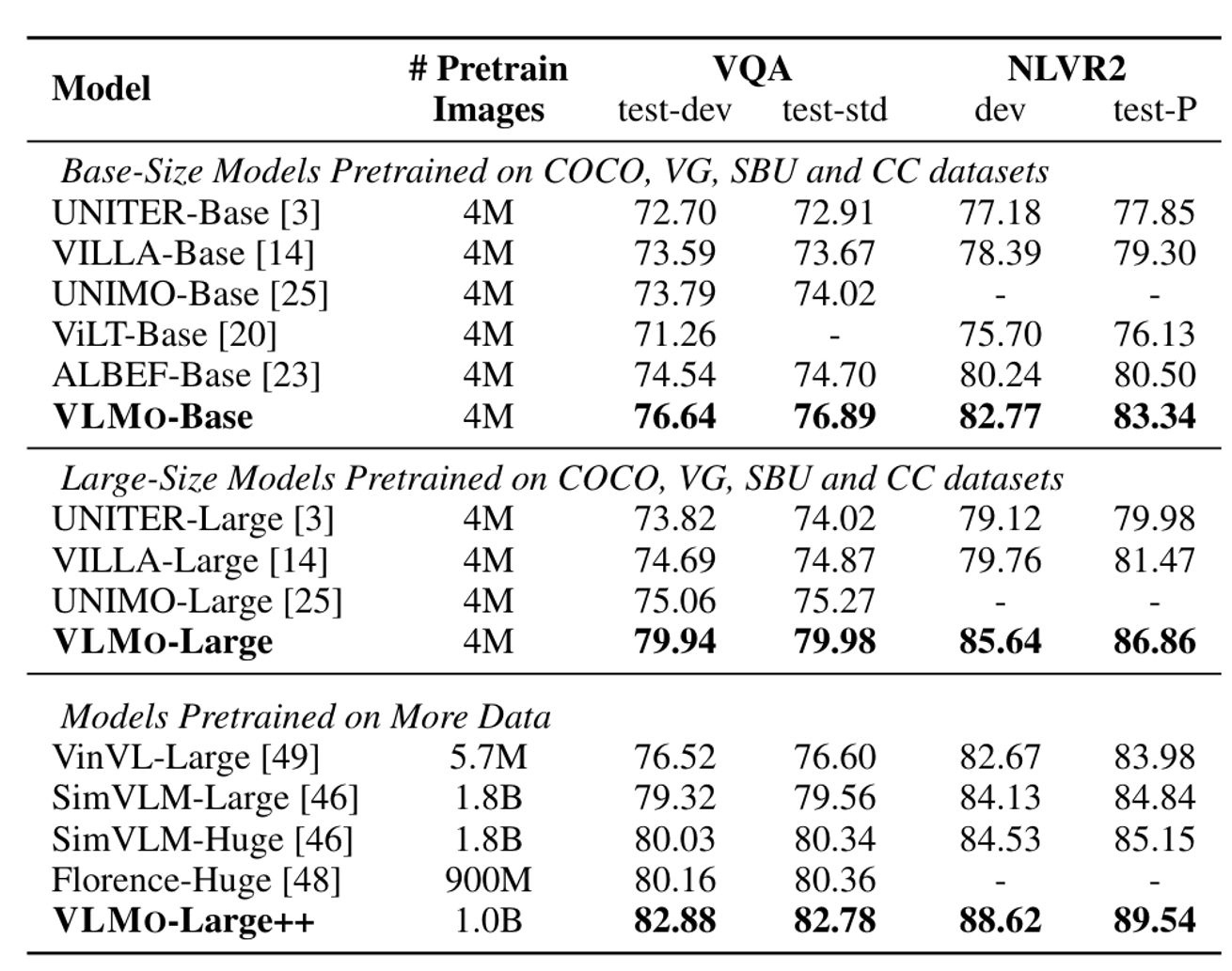
Base모델에서의 성능차이보다 Large모델에서의 성능차이가 더 크다
VLMO++가 위에 noisy데이터로 추가학습한 것
Ablation studies
Stagewise Pre-Training
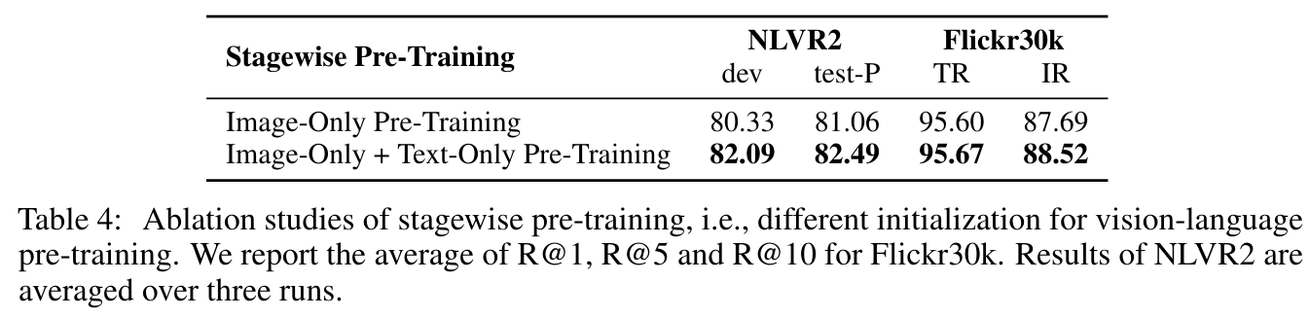
Vision:BEIT(ViT)
→ BEIT-Base의 파라미터를 사용하여 MOME transformer의 vision expert와 self-attention을 초기화
Language: BERT
Vision-Language: ViLT
pretrain값 사용시 Vision성능이 더 좋아 image-only data먼저 학습
MOME transformer
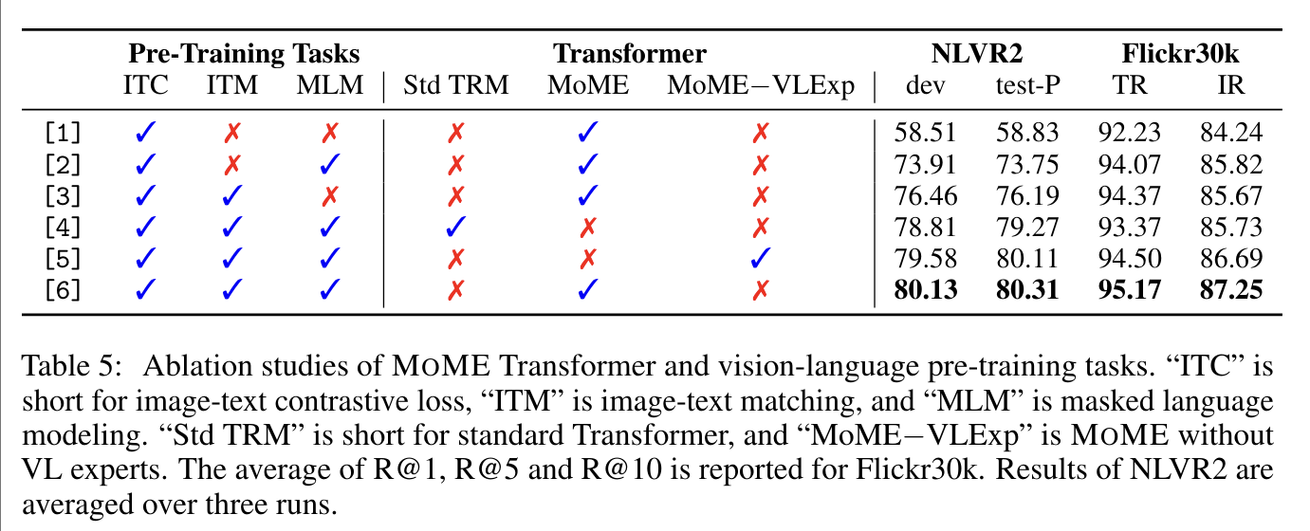
VL-Expert가 layer 2개 or 3개인데 정확도가 0.2정도 증가 → 좋은거같기도 아닌거같기도? (5 vs 6)
일반 transformer랑 MoME 비교 2%정도도 차이 안나느데 이게 다음에 설명하는 global hard negative mining차이면.. 사실 transformer랑 MoME는 차이가 없는건데..(4 vs 6)
Global Hard Negative Mining
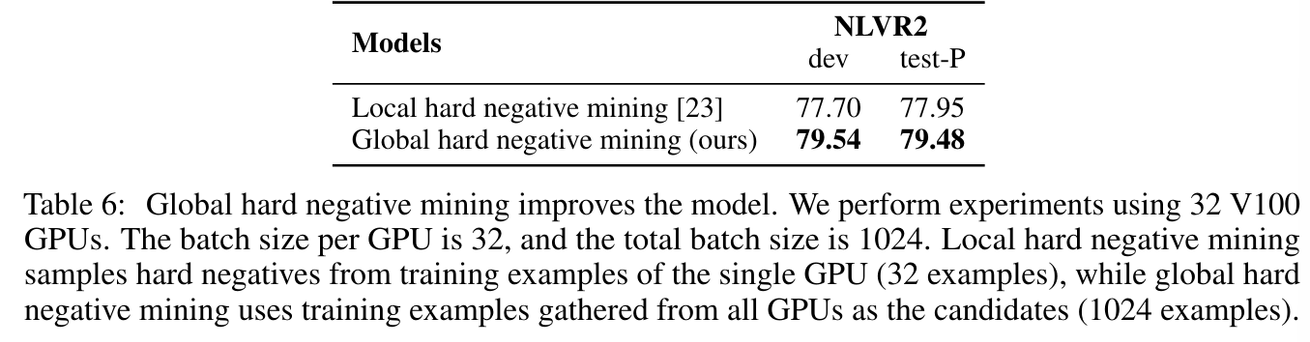
ALBEF에서 사용한 single GPU방식을 multi GPU방식으로 바꿈
