출처[LECTURE09]
강의 영상 및 자료:
https://mhsung.github.io/kaist-cs492d-fall-2024/
해당 강의를 기반으로 추가적인 설명을 정리했습니다.
DDIM Inversion
처음에 DDIM의 Inversion이라는 내용이 있어서, Reverse process의 반대는 Forward process이고 해당 과정은 정해진 상수(스케줄러)를 이용해서 노이즈를 더하는 과정인데 학습할게 있나? 라는 의문이 들었습니다. 하지만 정해진 상수를 이용해서 노이즈를 더하더라도 해당 Forward process는 non-deterministic합니다.
코드에서 Forward process를 진행한다고 했을 때 seed 값을 고정하지 않으면 forward processs를 진행할 때 마다 의 값은 달라지게 될 것입니다. Image Generation에서는 의 과정이 non-deterministic 하다는 것이 문제 없지만, Image Editting에서는 문제가됩니다.
따라서 Forward Process과정을 determinisitic하게 학습해서, 의 값이 매번 동일하게 나오도록 한 뒤, Condition을 기반으로 이미지를 수정하도록 하는 방법이 DDIM Inversion이라고 생각하시면 됩니다.

위의 사진처럼 Inversion 과정을 적은 step만을 이용해서 진행할 경우 Inversion에 실패하게 됩니다.

Inversion을 성공하기 위해서 제시한 아이디어는 CFG를 사용하는 것입니다. DDIM Inversion 즉 forward process에서는 “original prompt”를 사용하고, rever process에서는 “new prompt”를 CFG에 사용함으로써 성능을 높일 수 있습니다.

이전에 CFG에서 알아봤던 것처럼 Scale Factor(w)의 값이 클수록 Output의 성능이 좋아지는 것을 알 수 있었습니다. 하지만 DDIM Inversion에서 w의 값을 키웠을 때 오히려 성능이 안 좋아지는 현상이 발생했습니다.
w가 증가했을 때 성능이 안좋아지는 이유를 자세히는 모르겠지만, DDIM Inversion 과정은 이미지를 생성하는 과정이 아니기 때문에 노이즈를 생성할 때 너무 특정 class에 집중하도록 학습이 진행되면 오히려 성능이 안 좋아질것으로 예상됩니다.
Null-Text Inversion
- w=1을 이용해서 구한 를 pivot(기준점)으로 설정합니다.
- w>>1을 이용해서 학습을 하는데, 이때 이전에 구한 pivot과 비슷하게 학습하도록 제약을 추가합니다.
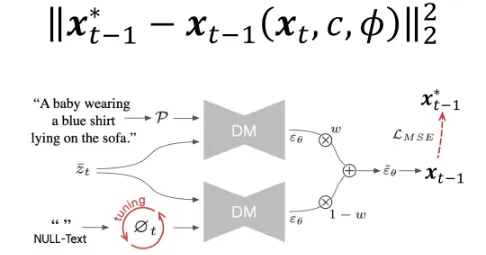
그러면 pivot과 비슷하게 학습되는 것은 어떤 것을까요? 바로 Null text prompt(ϕ) 입니다.
위의 DM(Diffusion Model)은 Condition(text prompt)를 학습하는 과정, 아래 DM은 Non-Conditional(Null-text)를 학습하는 과정입니다. w와 1-w로 설정한 이유는 CFG에서 w+1을 w로 w를 1-w로 변경한 것입니다.(extrapolation → interpolation)
이때 빨간색 동그라미 되어있는 부분인 Null-text prompt는 pivot과 비슷하게 학습되도록 tuning 되고 해당 과정이 존재하기 때문에 결론적으로 w를 큰값으로 증가시켜도 이전에 발생했던 성능이 떨어지는 현상이 나타나지 않습니다.


2개의 사진은 Null-Text Inversion의 결과로서 원본을 잘 유지하면서, Text prompt가 적용된 것을 알 수 있습니다.
Score Distillation
Diffusion Models for 3D
Diffusion 모델의 좋은 성능을 기반으로 많은 도메인에 해당 모델을 이용한 결과를 내고 있는 것을 위의 그림을 통해서 확인할 수 있습니다.
그중 3D 모델에 적용했을 때 매우 좋은 성능을 내고 있습니다. 위의 사진들이 3D에 Diffusion 모델을 적용한 결과들입니다.
3D 분야에서의 문제점은 데이터셋의 부족입니다. 2D 데이터의 경우 LAION이 5.8B의 데이터를 가지고 있는 것처럼 많은 양의 데이터가 존재하지만, 3D의 경우 가장 많은 데이터를 갖고있는 ObjaverseXL의 경우 10M개로 단위자체가 다를정도로 3D 분야에서는 데이터가 부족합니다.
이러한 데이터 문제를 극복하기 위해서 pretrained된 image diffusion 모델을 이용해서 Distillation을 진행하는 것입니다. Diffusion 모델은 많은 2D 데이터셋을 이용해서 학습했기 때문에 이를 이용해서 3D 모델을 생성할 수 있다면, 적은 수의 3D 데이터셋을 사용한다는 점을 극복할 수 있습니다.
3D Reconstruction
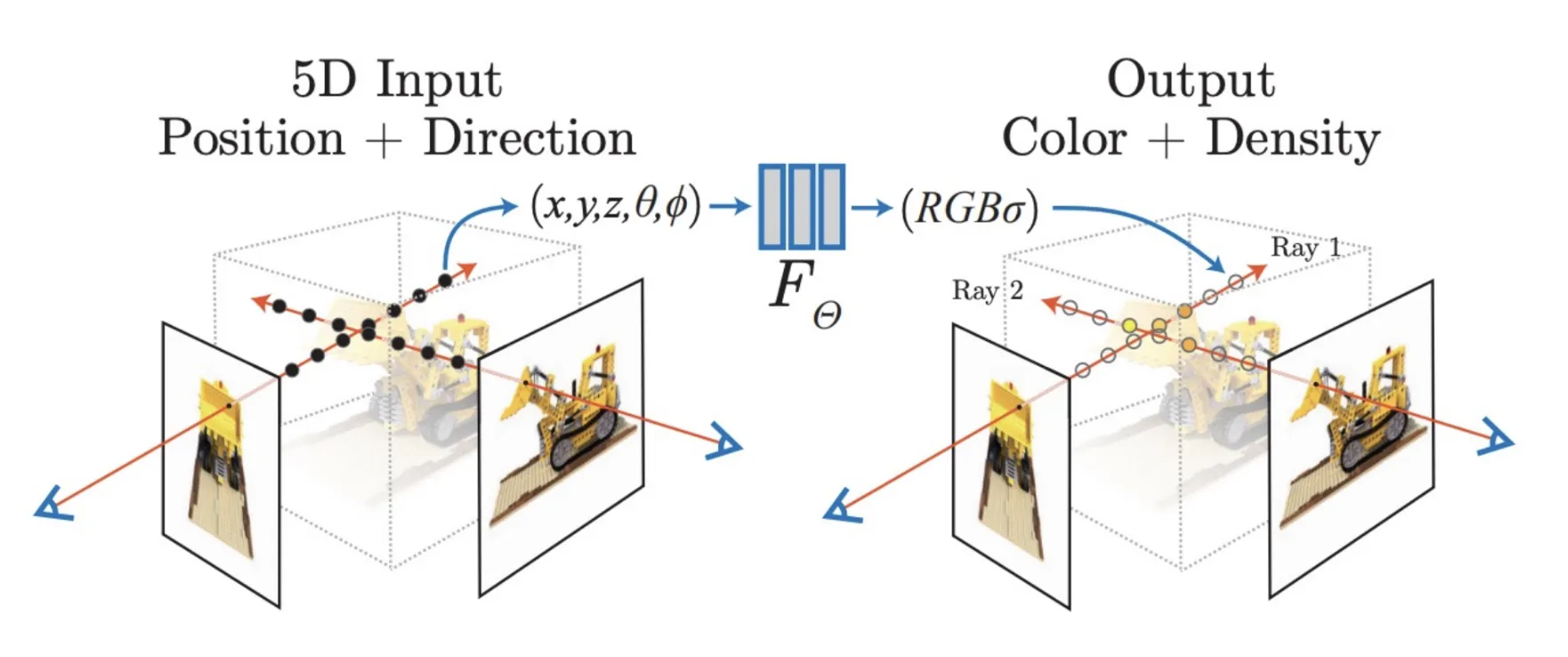
우선 3D Reconstrucion의 기초적인 부분부터 알아보도록 하겠습니다. 다양한 뷰의 이미지들을 이용해서 해당 시점에서 Ray를 쏴서 Color과 Density를 측정하는 대표적인 모델이 NeRF입니다.
NeRF에 대해서 자세하게 알아보시고 싶은 분은 위의 정리한 사이트를 방문하시면 될거같습니다.
3D Reconstruction의 다른 대표적인 모델인 3D Gaussian Splatting은 NeRF가 성능은 좋지만 시간이 많이 걸린다는 단점을 극복한 모델입니다.
마찬가지로 3D GS에 대해서 자세하게 알아보시고 싶은 분은 위의 정리한 사이트를 방문하시면 될거같습니다.
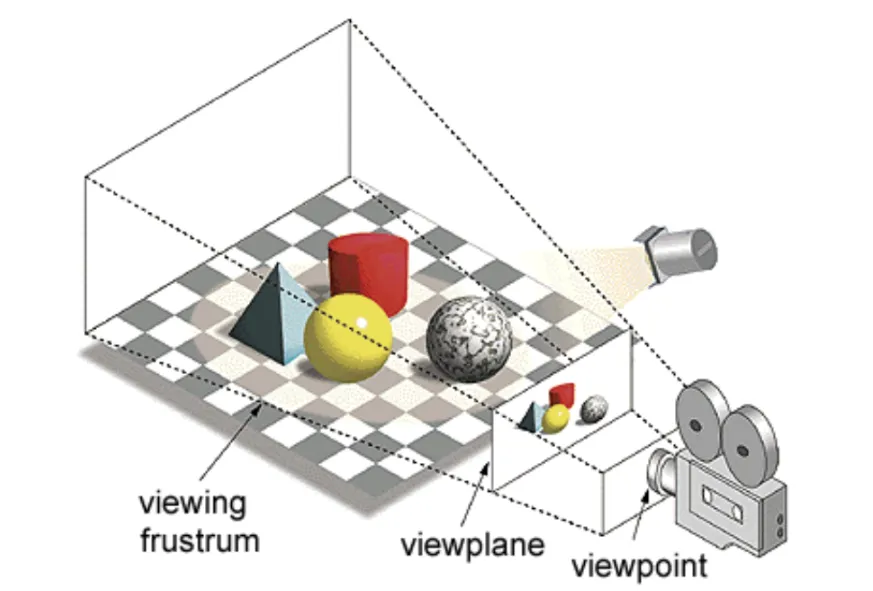
특정시점에서의 이미지를 얻기 위해 사용하는 방법은 Rendering입니다. Rendering은 특정 viewpoint에 대한 정보를 기반으로 해당 시점에서의 이미지를 Rendering 하는 것입니다. 3D Reconstruction은 Rednering을 기반으로 학습이 진행됩니다.
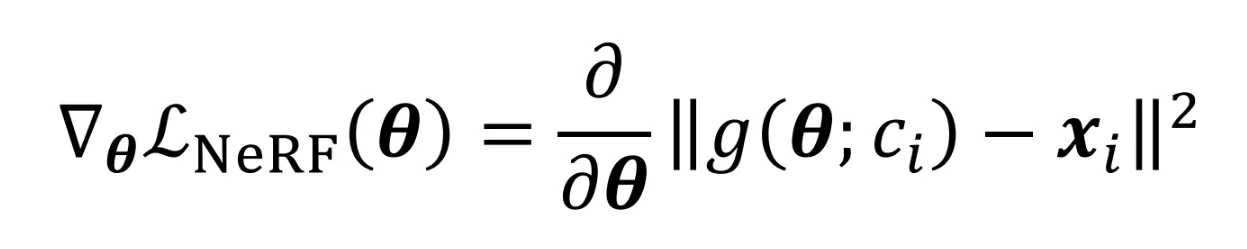
N개의 viewpoint와 해당 시점에 이미지가 주어졌을 때 모델이 렌더링한 이미지와 원본 이미지를 비교하면서 학습이 진행되게 됩니다. 학습식은 위와 같고 g의 함수가 렌더링함수 이고, 가 i시점에서의 이미지 입니다.
Using CLIP in 3D Reconstruction
그러면 얼마나 많은 이미지가 3D Reconstrucion을 하기 위해서 필요할까요? 3,5개처럼 적은 수의 이미지로도 가능할까요? 사실 데이터가 많으면 많을수록 성능이 더 좋아지는 것은 당연합니다. 그렇지만 실제로 많은 시점의 이미지를 구하기는 힘들기 때문에 적은 수의 이미지를 이용해서 3D Reconstruction을 할 수 있는 많은 연구들이 나왔습니다.
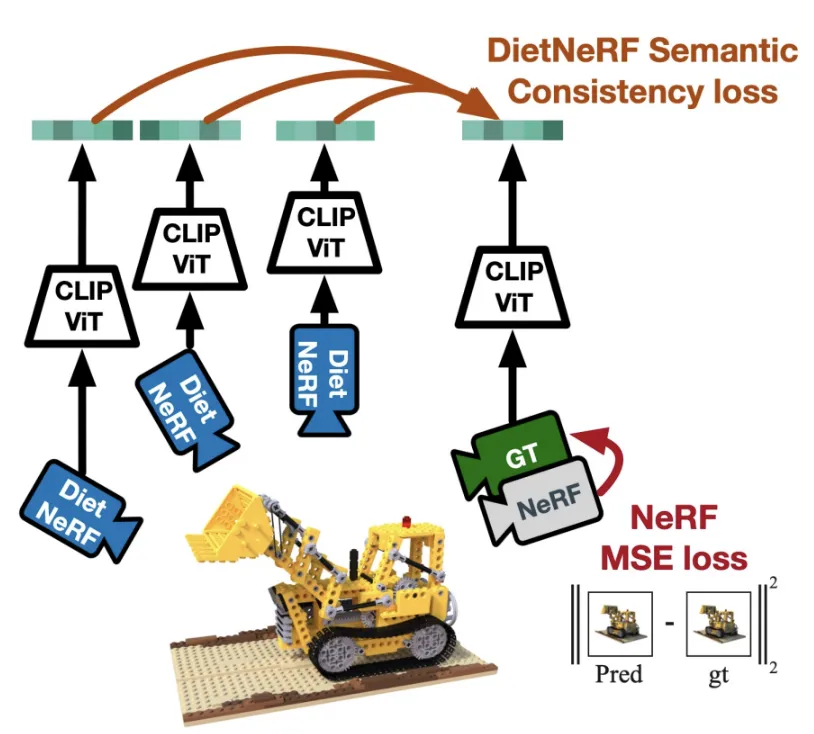
위의 모델은 NeRF에 대해서 적은 수의 이미지로 결과를 내기위해서 CLIP 모델을 사용한 방식입니다.

아이디어는 간단합니다. Text와 이미지가 얼마나 일치하는지 CLIP 모델을 통해서 알 수 있습니다. 예를들어서 위의 text prompt와 이미지를 같이 CLIP에 넣었을 때 이에대한 결과 70.7이 유사도를 나타냅니다.
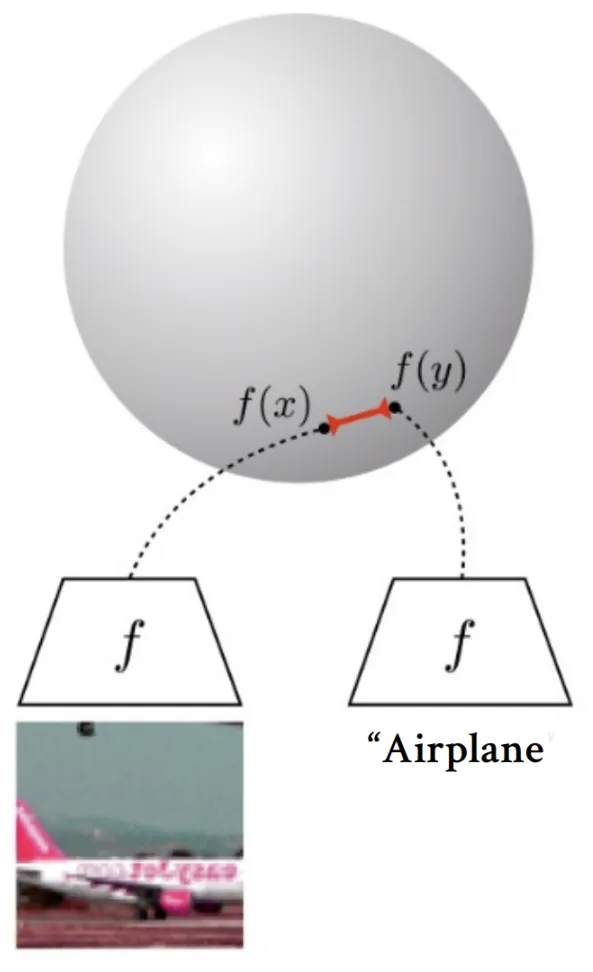
조금더 자세히 설명하면, 400million text-image 페어 데이터로 학습된 CLIP 모델에 이미지와 텍스트를 넣었을 때 임베딩 값을 얻을 수 있고, 2개의 임베딩값의 거리차이를 기반으로 2개의 값이 얼마나 비슷한지에 대해서도 나타낼 수 있습니다.
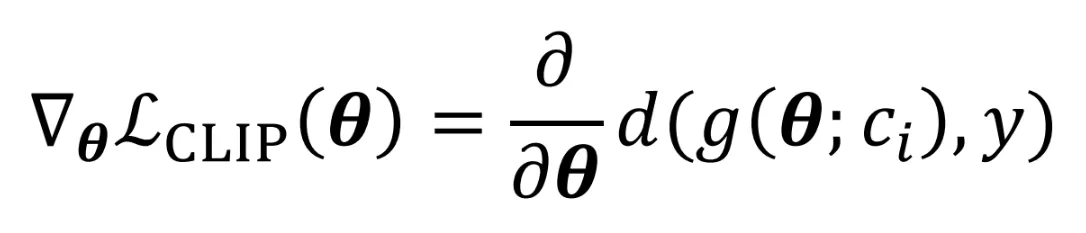
CLIP을 NeRF에 적용하는 방법은, 우리가 view point시점에 대해서 이미지 정보를 렌더링 할 수 있고 그 이미지와 text prompt의 유사한 정도를 CLIP을 통해서 얻을 수 있기 때문에 text prompt에 적절하게 렌더링된 이미지를 수정할 수 있습니다. CLIP을 사용한다면 또 좋은 장점이, 기존에는 많은 이미지를 입력하고, 그 이미지를 바탕으로 결과를 낼 수 있었는데 text라는 정보를 사용할 수 있기때문에 입력 이미지 없이도 text에 알맞은 결과를 낼 수 있습니다.
Score Distillation Sampling(SDS)
CLIP말고 Diffusion모델을 사용해서 3D Reconstruction을 진행하는 방법이 Score Distillation Sampling(SDS)입니다. 해당 과정은 DreamFusion에서 처음 제시했고 큰 아이디어는 이전에 설명한 CLIP과 크게 다르지 않습니다.
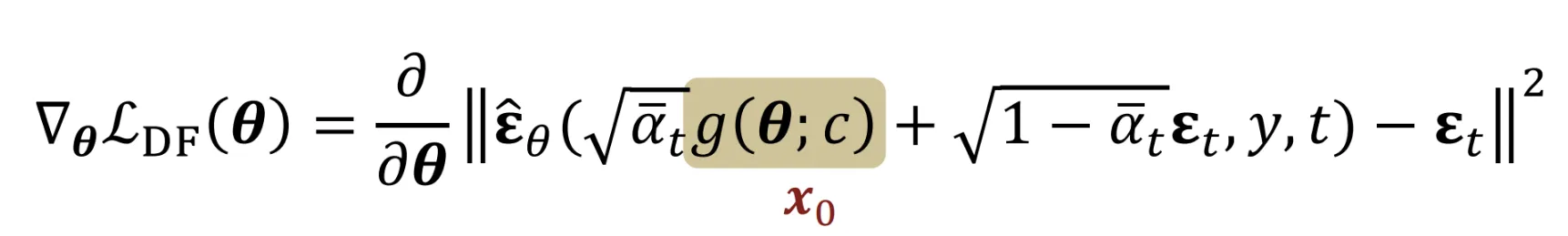
- 색칠된 부분에 나와있는 것처럼 viewpoint를 이용해서 렌더링된 이미지 를 얻습니다.
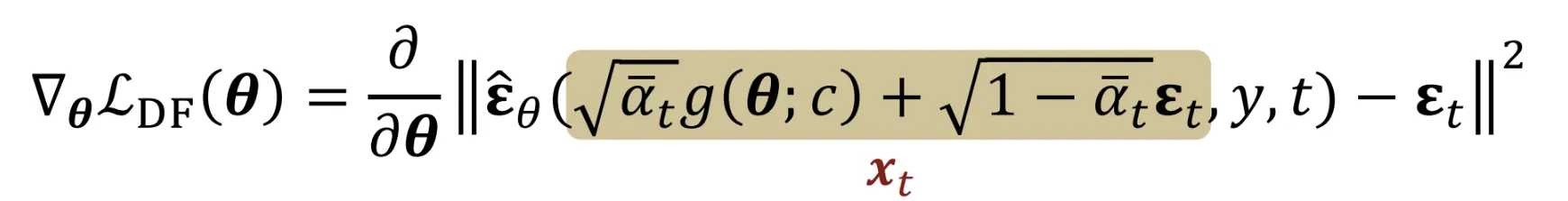
- 렌더링된 이미지 에 노이즈를 추가해서 time step t의 이미지 를 얻습니다.
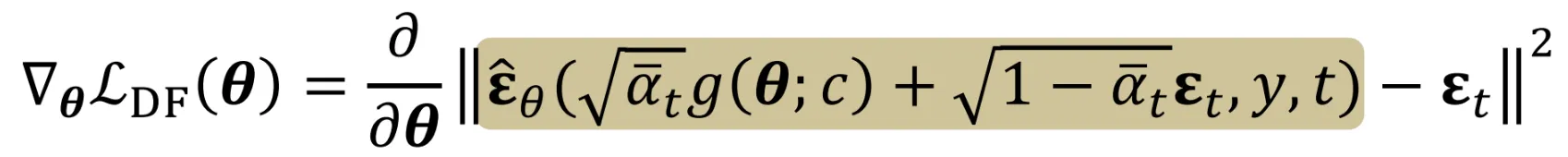
- t시점의 노이즈를 예측하고
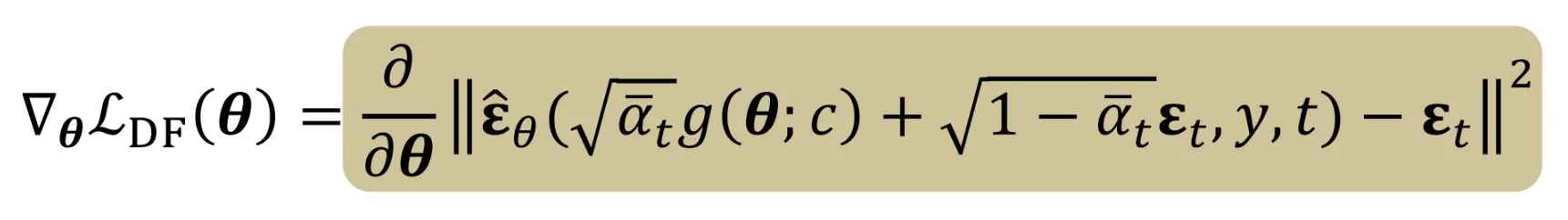
- 노이즈의 차이를 최소화하면서 학습을 진행합니다.
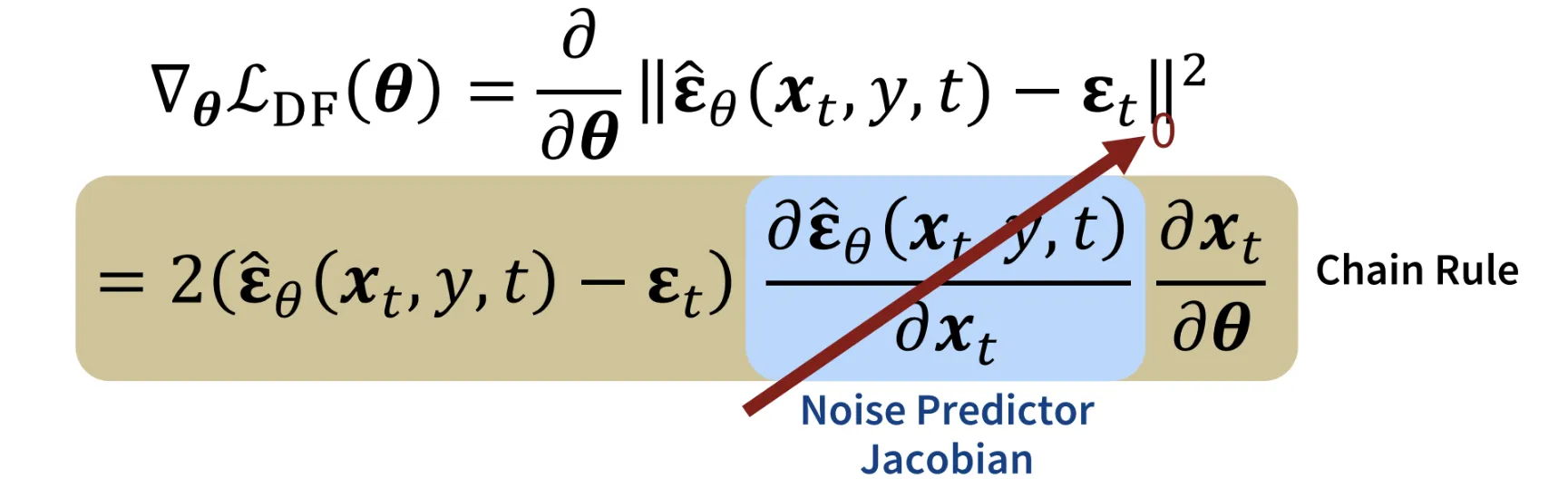
결과적으로 나온 SDS의 Loss가 첫번째 줄이고, 해당 Loss의 Gradient를 Chain Rule로 나타내면 2번째 줄이됩니다. 두번째줄에서 파란색 박스친 부분이 에 대한 노이즈 예측의 변화량을 나타내는 Noise predictor Jacobian 값입니다. 해당 값이 지나치게 크면 에 대해서 노이즈 예측의 변화량이 커지는 즉 학습이 불안정해지는 현상이 발생합니다. 따라서 해당 값을 0으로 수렴시켜서 에 따라 더 집중적으로 학습할 수 있도록 즉 안정적으로 학습할 수 있도록 수정합니다.
사실 결과만 보면 해당값을 0으로 보내냐, 0으로 보내지 않냐에 따라서 차이가 많지 않습니다. 하지만 VRAM의 사용량이 0으로 보냈을 때 반으로 줄기 때문에 기본적으로는 0으로 보내는 방식을 사용합니다.
SDS vs Reverse Diffusion
그러면 이번시간에 처음배운 DDIM Inversion을 이용해서 3D Reconstruction을 하는게 아니라 SDS를 적용해서 진행할까요?
우선 비교를 하기전에 해당 비교는 diffusion 모델을 훈련할 때 사용된 방식과 다른 형태로 파라미터화된 경우입니다. 지금의 3D Reconstruction 같은 경우를 말하는 것입니다. Reverse Diffusion 같은 경우 학습했던 데이터 분포에서만 동작하기 때문에 새로운 데이터 표현 방식을 사용할 경우 사용하기 어렵습니다.
이와 달리 SDS는 Gradient descent를 이용해서 반복적으로 적용하여 목표 데이터를 생성하기 때문에 새로운 데이터 분포에 대해서도 잘 동작합니다.
SDS Applications
SDS는 3D Reconstruction분야 뿐만아니라 다양한 분야에서 사용됩니다.
Vector image를 생성할 때

4D(3D + animation)을 생성할 때

Mesh editing을 사용할 때
2D prior Model Limitation

위의 결과가 사진이라서 한눈에 결과를 확인할 수 없어 제가 이전에 돌렸던 Stable Zero123의 결과를 가져와보겠습니다.

보시면 강아지의 얼굴이 2개가 나오는 현상이 나타납니다. 해당 영상에서는 2개지만 초기 모델들의 결과는 더 많은 얼굴들이 나오는 결과가 나옵니다. 이러한 현상을 janus problem이라고 합니다.
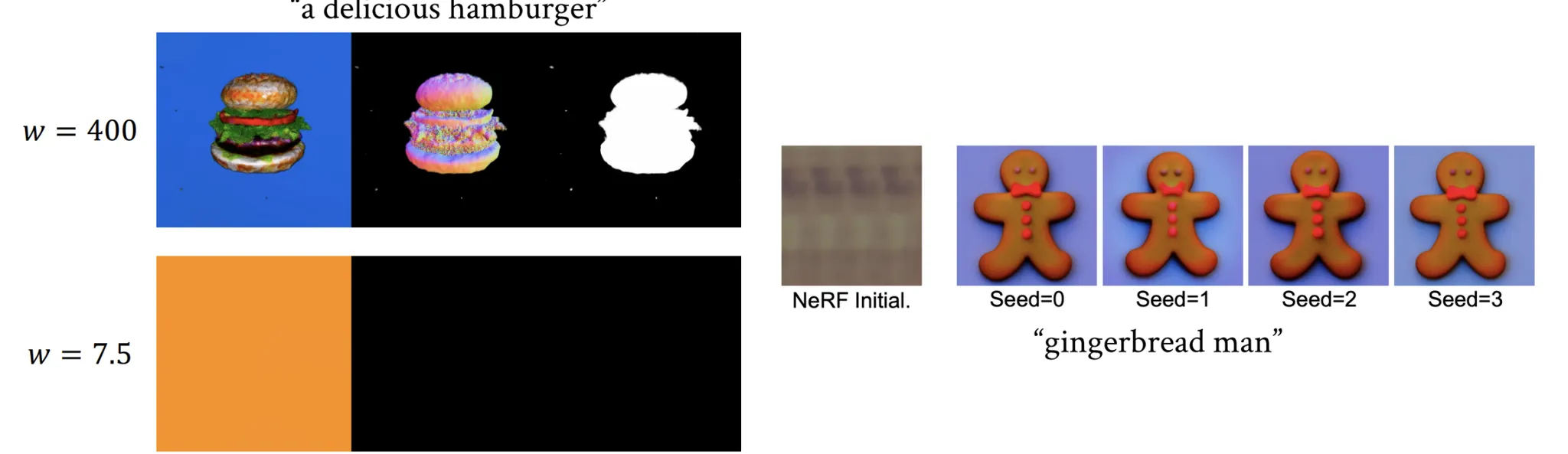
SDS의 또다른 문제는 CFG의 값이 낮으면 converge하지 않는다는 점입니다. CFG가 높으면 diversity가 떨어지기때문에 diversity가 한계점으로 나타나고 있습니다.
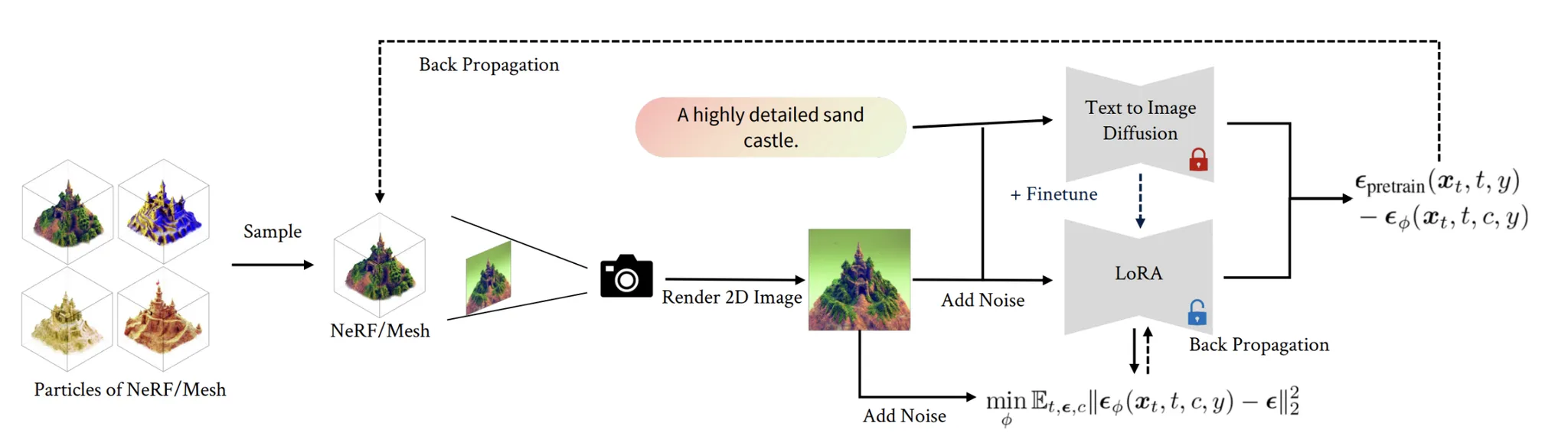
이러한 문제를 LoRA로 해결한 모델이 ProlificDreamer입니다. 자세한 내용은 논문을 참조하면 될거같습니다.
