Method
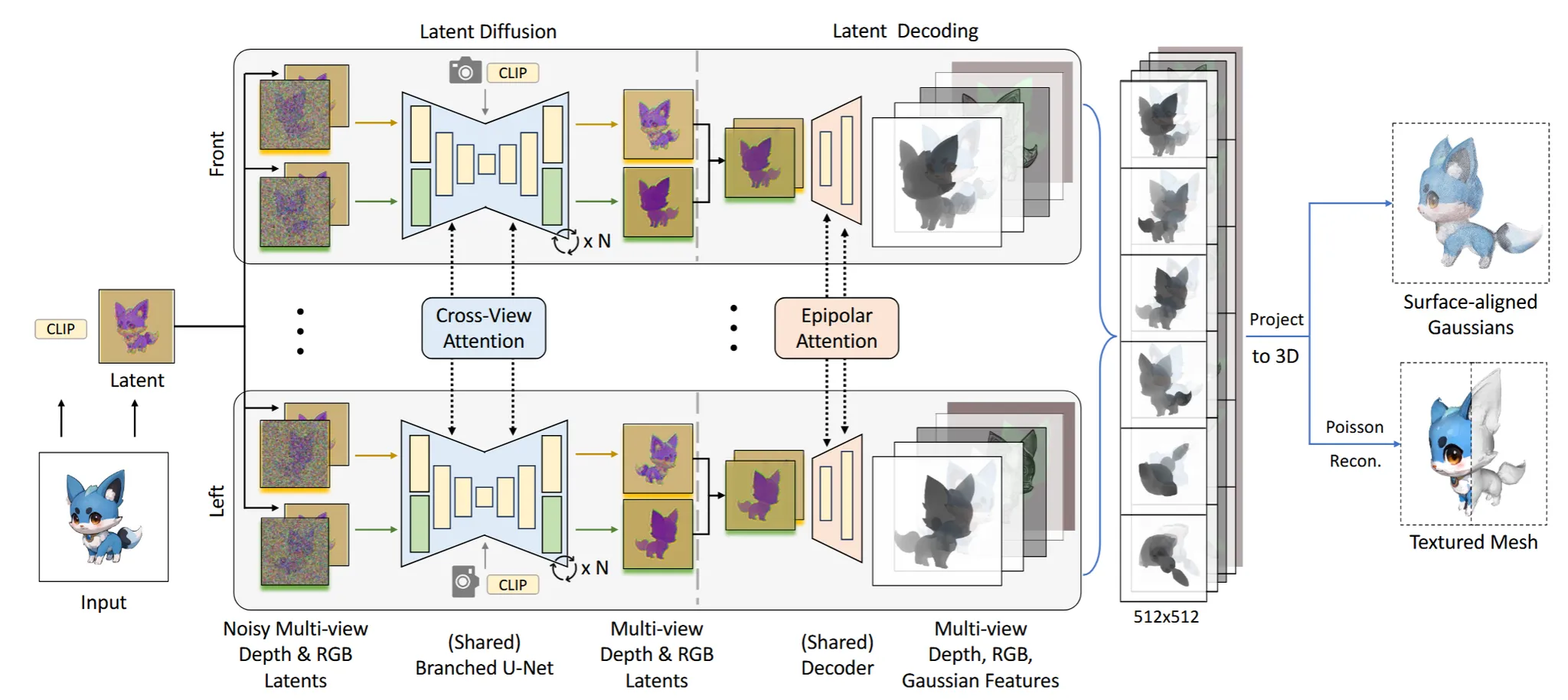
Multi-view Generation in Latent Space
3D를 생성할 때 1개의 이미지로부터 생성하게 되면 부적절한 결과가 나오는 경우가 많습니다. 따라서 Stable diffusion을 활용해서 2D 상에서 여러 시점의 이미지를 얻고 이를 기반으로 3D Reconstruction 하는 경우가 많고, 해당 논문에서도 여러 시점의 이미지를 얻는 과정을 진행했습니다.
이때 “Text-Guided Texturing by Synchronized Multi-View Diffusion” 논문에서 사용했던 것처럼 U-Net 모델의 Self-Attention layer를 다른 뷰에 대해서 Cross-Attnetion을 하도록 수정했습니다. 위의 Attention U-Net의 intermediate layer에서 Self-Attention이 수행되는데, 해당 부분의 입력값을 다른 뷰의 이미지로 넣어서 Cross-Attention을 하는 방법입니다. 이렇게 될 경우 View 끼리의 consistency를 일치시킬 수 있습니다.
Enforcing Cross-view Depth Consistency with Epipolar Attention
이전에 Stable diffusion을 사용했기 때문에 사전학습된 VAE decoder를 이용해서 latent의 차원을 RGB 차원으로 변환해줍니다. Latent 차원에서 뷰끼리 Cross-Attention을 진행했기 때문에 consistency가 좋아졌을 것입니다.

우리가 각 시점의 depth map을 얻고싶을 때, 각 시점의 latent 정보를 존재하니까 VAE decoder를 학습시켜서 depth map을 생성하면 어떨까? 라는 아이디어로 진행해봤습니다. 하지만 위의 그림과 같이 결과는 좋지 않았습니다. 이에 대한 근거는 RGB보다 depth를 생성할 때 더 정확한 픽셀의 값을 필요로 하기 때문이라고 설명했습니다.
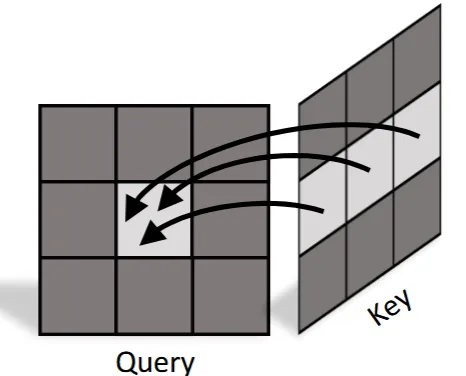
각 시점의 Depth map을 잘 생성하기 위해서 epipolar attention 방식을 사용했습니다. Epipolar attention은 cross-attention에 비해서 계산량도 더 적습니다. 계산 방식은 위와 같이 픽셀 값에 대응되는 epipolar line과만 attention을 진행합니다. 실제로 epipolar line은 기하학적 특징을 갖고 있기 때문에 기하학적인 영향을 나타내는 depth map을 생성할 때 적절하다고 설명했습니다.
논문에서 6개의 othogonal한 view(front, back, left, right, top, bottom)를 사용하기 때문에 실제로 epipolar attention은 row or column attention이 될 것입니다(위의 사진은 row attention, 정육면체에서 윗면과 옆면인 경우 column attention).
Efficient Cross-domain Denoising via Expert Branch
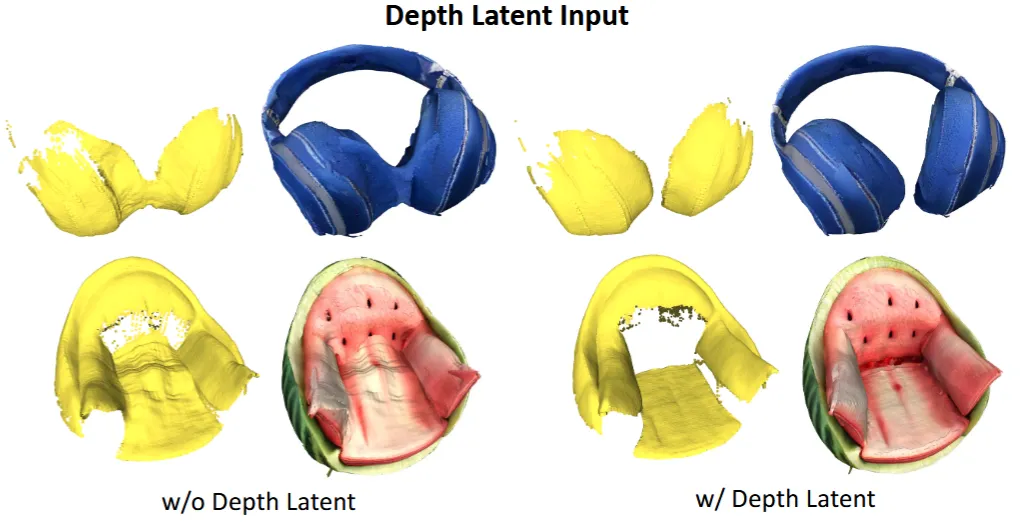
Epipolar attention을 이용해서 더 좋은 depth map을 생성하게 되긴 했지만 여전히 RGB latent를 기반으로 생성하기 때문에 좋지 않은 결과가 나옵니다. 따라서 U-Net의 결과로 depth latent도 생성하도록 수정했습니다. 위의 그림에서도 depth latent를 생성하도록 할 경우의 depth 결과가 더 잘 나오는 것을 확인할 수 있습니다.
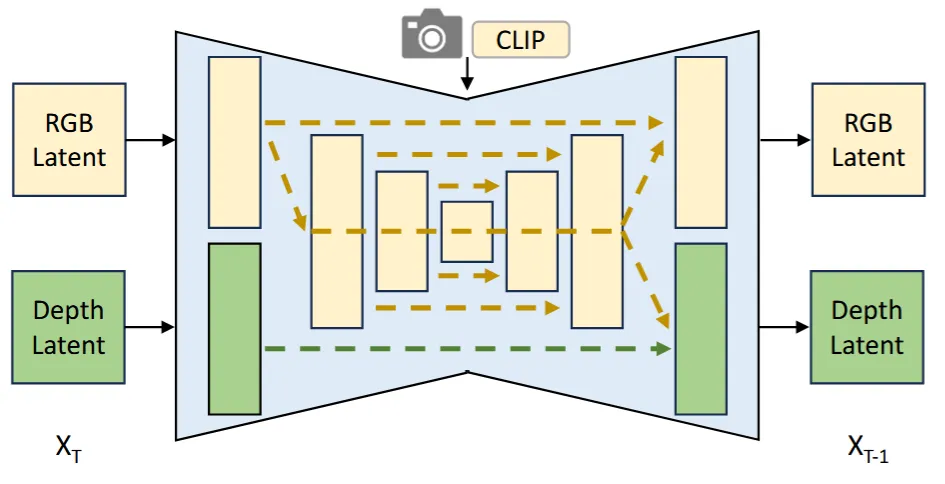
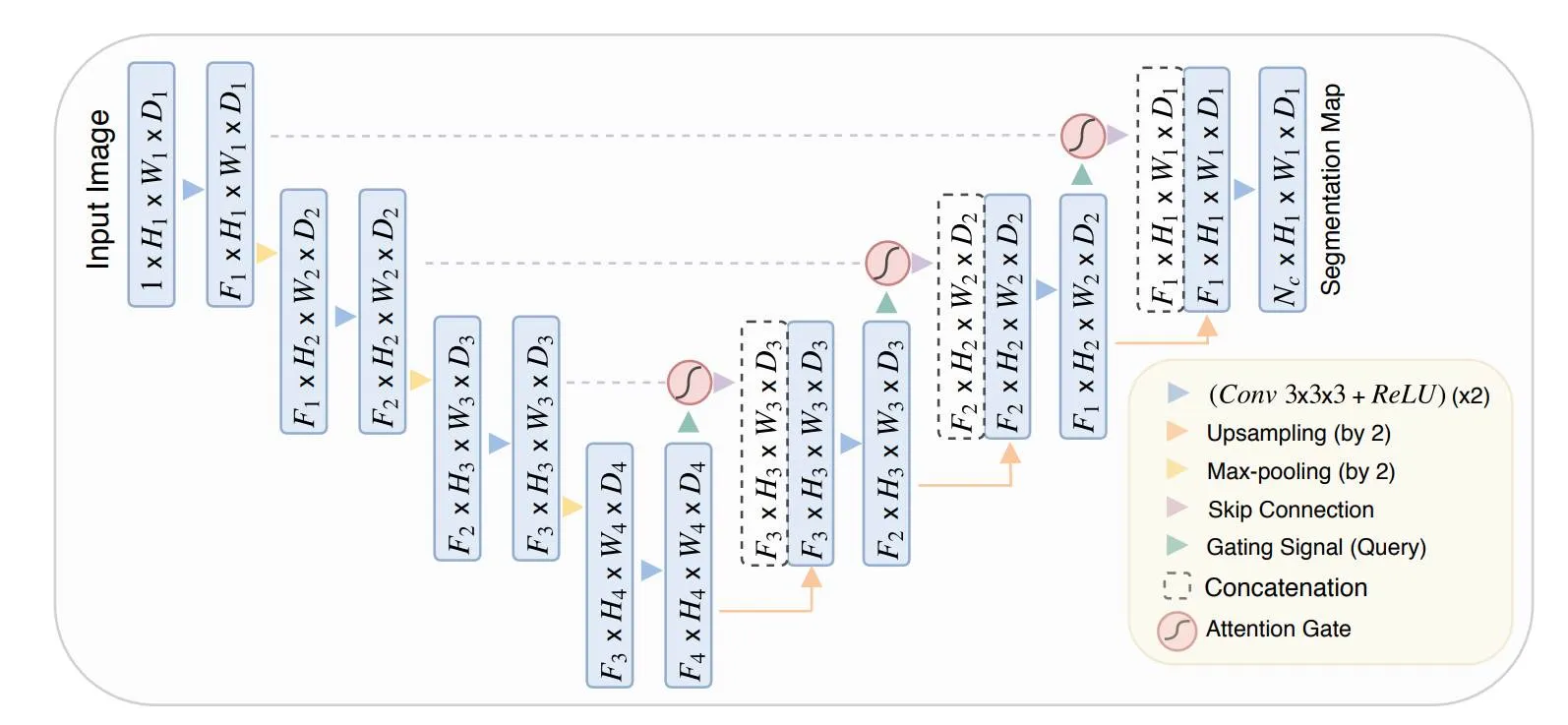
Wonder3D에서는 label(rgb, depth)을 이용하고, HyperHuman에서는 expert branch를 이용해서 rgb와 depth latent를 예측하도록 설계 됐습니다. 2가지 경우 모두 train과 inference시간이 매우 증가한다는 단점이 존재했습니다. 해당 논문에서는 위의 그림처럼 Upsampling의 처음 부분과 Downsampling의 마지막 부분의 layer를 복제해서 rgb와 depth 각각의 정보만 학습할 수 있도록 설계 했습니다. 이렇게 될 경우 각 정보를 해치지 않으면서 독립적이고 병렬적으로 학습이 가능하게 됩니다.
Epipolar attention을 Cross Attention 대신 사용?
해당 방식이 좋은건 알겠는데 Cross Attention을 대신해서 사용한건지 다른 자리에 추가적으로 들어간지에 대한 설명이 부족 했던거 같았습니다. 찾아보니까 논문의 8페이지 ablation study쪽에 epipolar attention은 depth decoder에 사용된다고 나와있었습니다.
Efficient Rendering with 3D Gaussian Splatting
3D Gaussian splatting: 3D Gaussian을 사용해서 3D를 표현하는 모델입니다. 각각의 가우시안들은 3차원에서 중심(x), 색깔(c), 불투명도(), scaling(s), rotation quaternion(q)를 사용해서 나타냅니다.
Pixel-aligned 3D gaussians : 방금 설명한 3D gaussian의 중심(x) 대신 depth pixel(t)를 사용해서 가우시안을 나타내는 방법입니다. 광선의 시작하는 지점()에서 광선이 향하는 방향()을 이용하면 가우시안의 중심 로 나타낼 수 있습니다.
이 논문에서는 위의 설명중 3D GS에 depth 정보를 활용한 Pixel-aligend 3D gaussian 방법을 사용합니다. 기존의 입력값은 RGB의 정보만을 사용했지만, depth 정보를 추가로 사용하게 됩니다. 또한 decoder에 추가적으로 8차원(1-opacity, 3-scale, 4-rotation)을 예측하도록 수정했습니다. 그리고 Gaussian의 값이 너무 크거나 작은 것을 방지 하기 위해서 수식을 통해서 1과 가까운 값을 갖도록 설정하고 마지막으로 novel view synthesis loss term을 추가했습니다(수식은 Details에서 설명).
Textured Mesh Extraction
이전까지 생성된 Gaussian feature의 RGB, depth, opacity를 이용해서 texture와 3D mesh를 생성합니다. 첫번째로 depth map을 이용해서 surface normals를 생성합니다. 이때 대응되는 투명도의 값이 0.1보다 작은 점들은 제외 했습니다.
Mesh를 얻기 위해서는 Poisson surface reconstruction 방식을 사용했습니다. 계단 현상과 같은 aliasing을 제거하기 위해서 Laplacian smoothing을 적용했습니다.
Texutre는 xatlas 라이브러리를 이용해서 생성했습니다.
기존에 3D GS를 pixel-perfect depth map으로 생성했기 때문에 추가적인 복잡한 과정 없이 간단하게 Texture와 Mesh를 생성할 수 있었습니다.
Implementation Details
Stable Diffusion: Image Variation(zero123의 fine-tuning에도 사용된 모델)
U-Net 학습: 256x256, 512 batch, 30K iter → 512x512, 96 batch, 100K iter
VAE decoder와 epipolar attention fine-tuning : 512x512, 8 batch, 90K iter
RGB image : Mean Square Error(MSE) loss + LPIPS loss
Depth image : L1 loss + gradient matching loss
Novel view synthesis loss : 10개의 랜덤 뷰를 랜더링해서 MSE loss와 LPIPS loss를 RGB에 대해서 계산하고, MSE loss를 alpha image에 대해서 계산합니다.
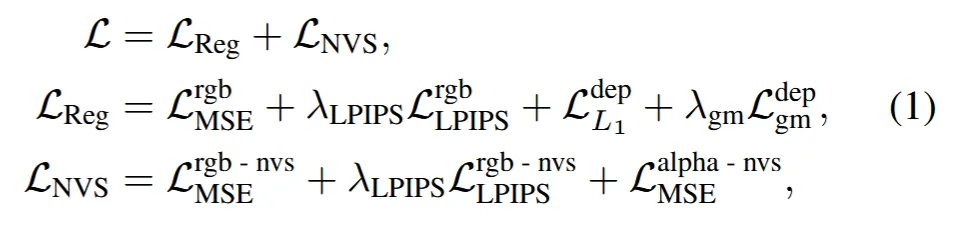
위의 3개의 loss를 한번에 수식으로 정리한 것입니다. loss는 Regression loss랑 Novel view synthesis(NVS) 2가지로 크게 분류할 수 있습니다.
Regression loss는 rgb에 영향을 미치는 MSE와 LPIPS, depth에 영향을 미치는 L1과 gradient matching 2가지로 총 4가지 term을 갖고 있습니다.
NVS loss는 rgb에대해서 MSE와 LPIPS loss, alpha image에 대해서 MSE를 진행해서 총 3가지 term을 갖고 있습니다.
Ablation Study
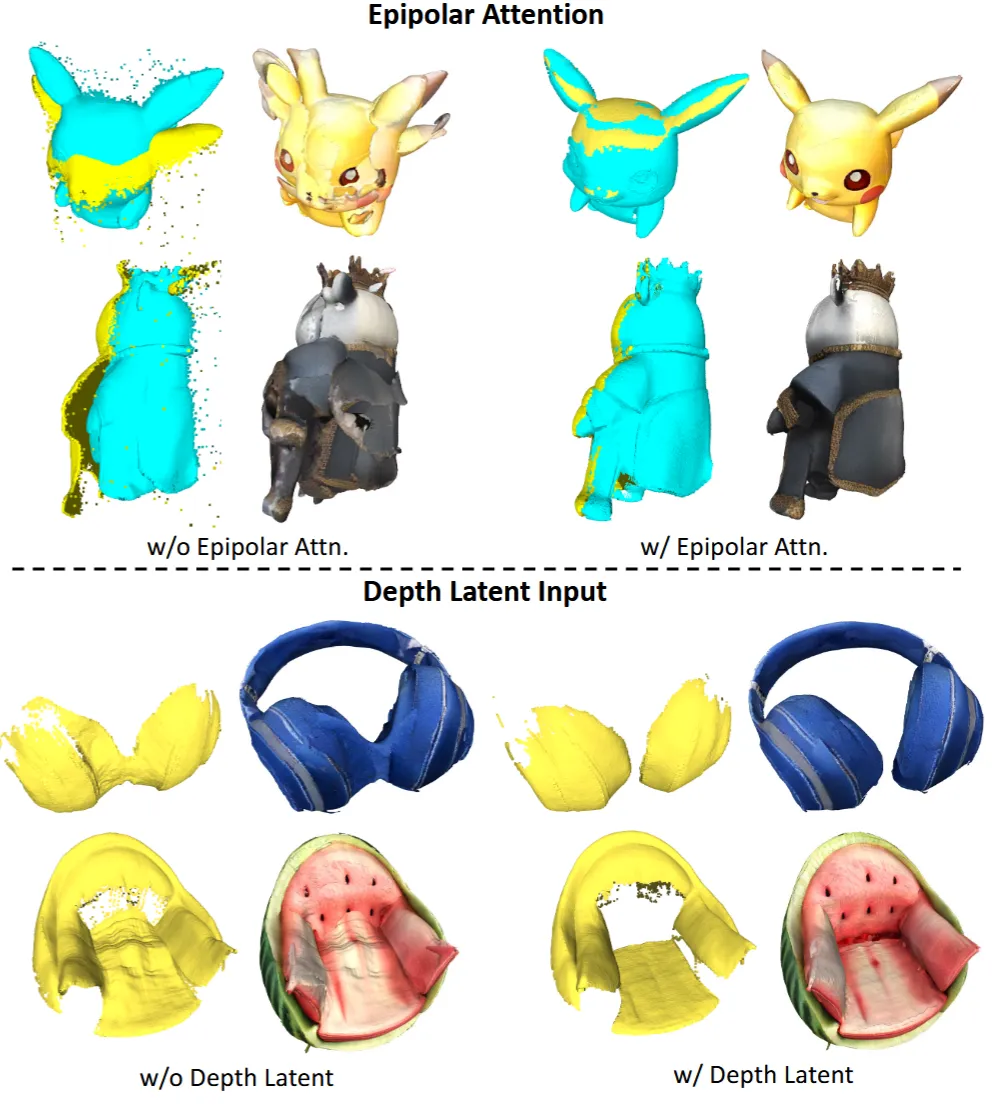
이전에 그림에서 보았던 epipolar attention의 유무에 따른 결과와, latent depth map의 유무에 따른 결과를 시각적으로 나타냈습니다.
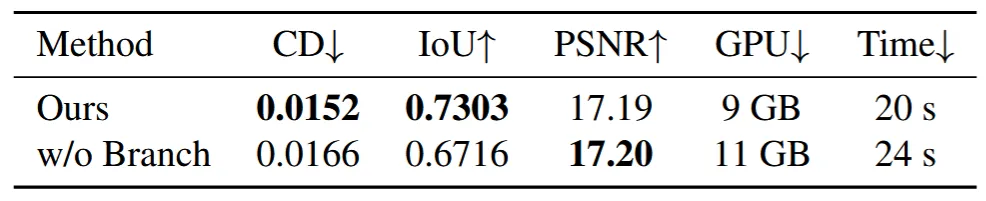
추가적으로 U-Net에 branch를 추가하는 해당 방식과 Wonder3D의 domain-switch 방식을 비교했을 때 시간도 더 적게 걸리고, GPU 사용량도 더 적은 것을 나타냅니다.
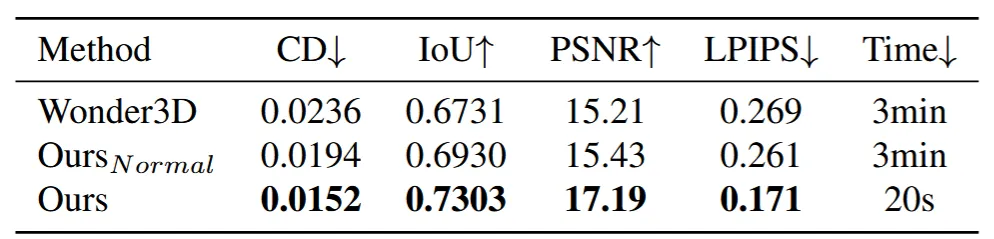
마지막으로 흥미로운 실험 결과였는데 depth map과 normal map의 결과를 비교해본 것입니다.

위의 사진은 Meta3D에서 가져온 것인데 (a)가 depth map이고, (b)position 그리고 (c)가 normal map입니다. depth map에 비해서 normal map의 정보가 뷰에 영향을 받지 않고 더 많은 정보를 담고 있다고 설명했는데 위의 ablation 결과를 보면 depth map이 normal map보다 좋은 것을 확인할 수 있습니다. 따라서 생성을 할 때는 depth map이, 시점에서의 정보를 표현할 때는 normal map이 더 좋다는 점을 확인할 수 있습니다.
Limitations
입력 이미지가 orthogonal하다는 가정이 들어갔기 때문에 원근법이 적용된 이미지가 들어가면 약간의 성능 저하를 야기합니다.
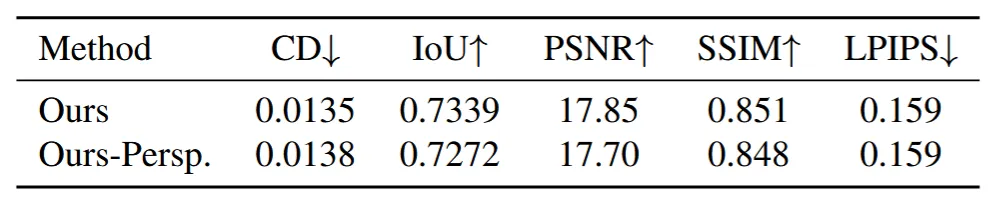
실제로 Perspective view에 대해서 고정된 focal length를 이용해서 학습한 결과가 위의 표입니다. Orthogonal한 view에 비해서 약간의 성능이 하락한 것을 알 수 있습니다.
이렇게 특정 카메라에 의존적인 결과를 나타낸다는 것을 논문의 한계점으로 갖고 있습니다.
