
Depth 모델과 3D Gaussian 모델이 서로 학습하면서 서로의 학습을 도와주는 모델이 depthsplat입니다. 이에 따라 최종 결과인 3D Representation의 성능이 좋아졌다고 밝혔습니다. 어떻게 서로 보완적인 관계를 유지하면서 좋은 3D Representation을 나타냈는지 확인해보도록 하겠습니다.
DepthSplat
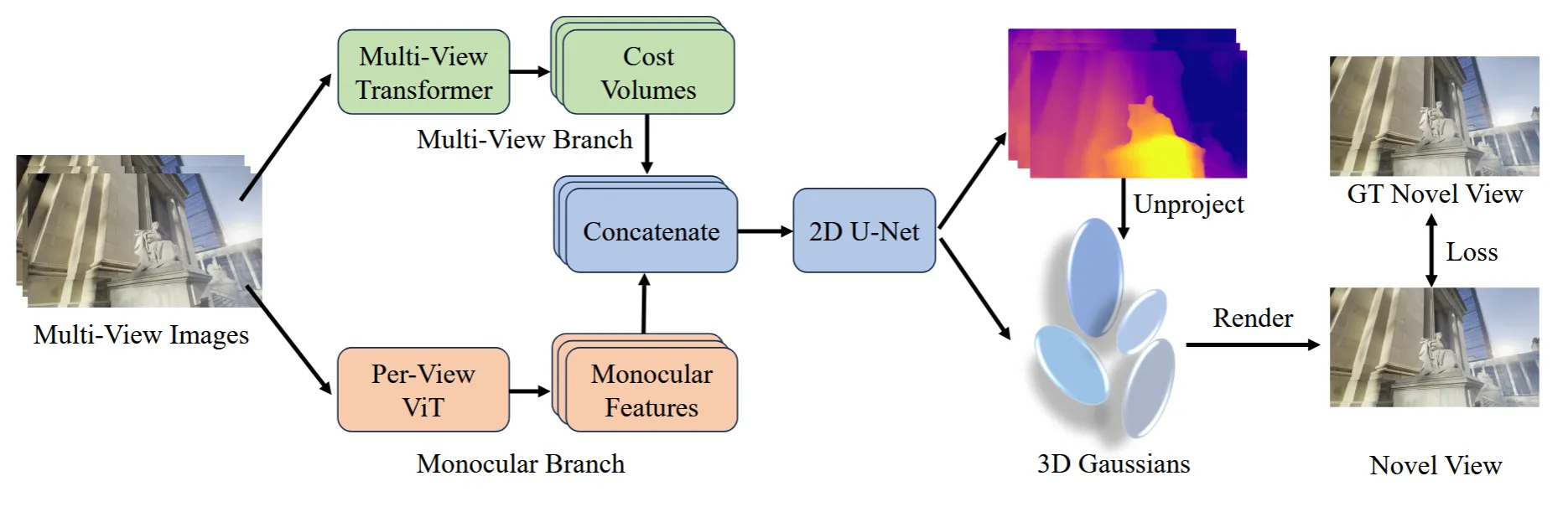
모델의 아키텍처는 위의 그림과 같습니다. N개의 이미지를 입력한 후 각 픽셀별로 depth()와 Gaussian parameters()를 예측하는 것을 목표로 합니다. Position을 나타내는 는 2D depth 정보를 3D로 unprojecting 시켜서 얻고, 나머지 Gaussian parameter들은 추가적인 lightweight head를 이용해서 얻습니다.
Depth model은 크게 Cost volume과 Monocular feature를 추출하는 모델로 나눠집니다. 2개의 정보를 Concate 돼서 2D U-Net의 depth regression에 사용됩니다.
Multi-View Feature Matching
Multi-View Feature Extraction
Cost Volumes를 어떻게 추출하는지 더 자세히 살펴보도록 하겠습니다. 처음에 파라미터를 공유하는 ResNet을 사용해서 각 시점에서의 feature를 얻도록 했습니다. 이렇게 될 경우 뷰끼리의 정보 교환은 없기때문에 inconsistency한 결과가 나옵니다. 따라서 ResNet를 통해서 얻은 feature에 대해서 Swin Transformer를 사용하도록 변경했습니다. Swin Transformer에 존재하는 Cross-attention의 경우 모든 뷰에 대해서 실행하면 너무 많은 연산량이 필요하기 때문에 카메라 거리가 가장 가까운 top-2 시점에 대해서만 진행합니다.
Feature Matching
Swin Transformer의 결과로 나온 feature들에 대해서 plane-sweep stereo approach를 통해서 뷰끼리의 depth 차이를 측정합니다. j시점에서의 feature에 대해서 여러가지 depth candidates 를 이용해서 i시점의 feature를 얻게 됩니다. 어떤 depth candidate를 사용했는지에 따라서 변환된 i시점의 feature는 다르게 생성될 것이고, 원본 i시점의 feature와 내적을 통해서 cost값을 얻게 됩니다. 이렇게 저장된 여러개의 cost정보가 cost volume일 것이고, 여기에는 두 시점간의 적절한 depth candidate 값을 얻게 될 것입니다. 여기서도 top-2시점에 대해서 depth candidate별로 correlation을 계산하고 2개의 값을 평균내어서 저장합니다.
Monocular Depth Feature Extraction
Cost Volume으로 얻은 결과는 시점별로 depth차이를 알기에는 좋지만, 해당 시점에서의 depth를 알 수 없습니다. 또한 texture가 없거나, 붕괴되거나, 반사가 많이 되는 부분에서는 상대적인 depth를 정확히 알지 못합니다. 따라서 사전학습된 monocular depth를 cost volume과 함께 사용해서 더 많은 정보를 사용할 수 있도록 합니다.
사전 학습된 모델은 Depth Anything V2 입니다. 해당 모델의 백본은 ViT이고 패치 사이즈가 14이기 때문에 Cost volume의 feature와 같은 차원을 얻기 위해서 bilinear interpolation을 실행합니다.
Feature Fusion and Depth Regression
그림에서 보이는 것처럼 이제 monocular feature와 cost volume을 channel 차원에 대해서 concatenation합니다. Concate된 값은 2D U-Net의 입력값으로 들어가서 병렬적으로 의 출력값을 생성합니다. 참고로 여기서 D는 이전에 말한 depth candidate입니다, 즉 픽셀별로 D개의 depth 후보들을 갖게 됩니다. 이렇게 후보들에 대해서 softmax값을 취한 후 weighted average를 취해서 학습을 하게 됩니다.
Hierarchical matching 방식도 사용합니다. 말 그대로 depth를 예측할 때 작은 이미지에 큰 이미지로 예측하면서 큰 이미지는 세부 사항만 업데이트 해서 계산량을 줄일 수 있습니다.
Gaussian Parameter Prediction
Depth map을 이용해서 3D Gaussian의 위치()를 생성하고, 나머지 Gaussian parameter(opacity, covariance, color)는 추가적인 2D U-Net을 통해서 얻습니다.
Train loss
Loss는 크게 Depth estimation과 관련된 부분과 View synthesis(3D GS)에 관련된 부분으로 나눠져 있습니다.
Depth estimation

는 모델이 예측한 detph이고, 는 ground truth depth입니다. 첫번째 부분에 대해서 L1 loss로 예측값과 실제 값을 최소화하고, 두번째 term에서는 x와 y에 대한 미분 변화량도 최소화하면서 학습을 진행합니다. 이렇게 하면 더 부드러운 표현을 가능하게 한다고 설명했습니다. 으로 UniMatch에서 사용한 값을 그대로 사용했습니다.
View synthesis
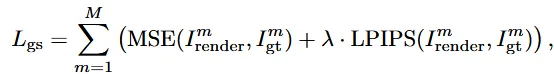
은 렌더링된 이미지, 는 ground truth 이미지로서 앞부분은 MSE loss로 픽셀간의 차이를 최소화하고, 두번째 LPIPS 부분에서는 사람이 인식할 때 더 자연스럽게 하도록 합니다.
