GenesisTex2: Stable, Consistent and High-Quality Text-to-Texture Generation 논문 리뷰

2D 데이터에 비해서 3D 데이터의 성능이 작고, 학습할 수 있는 양이 부족하기 때문에 Text-to-Texture를 생성할 때 2D diffusion을 이용해서 학습을 합니다. 이렇게 2D를 이용해서 학습을 하다보니까 자연스럽게 view끼리 일치하지 않는 inconsistency나, seam(경계선)이 나타나는 문제가 발생했습니다. 이를 극복하기 위해서 GenesisTex2가 나왔습니다.
Method
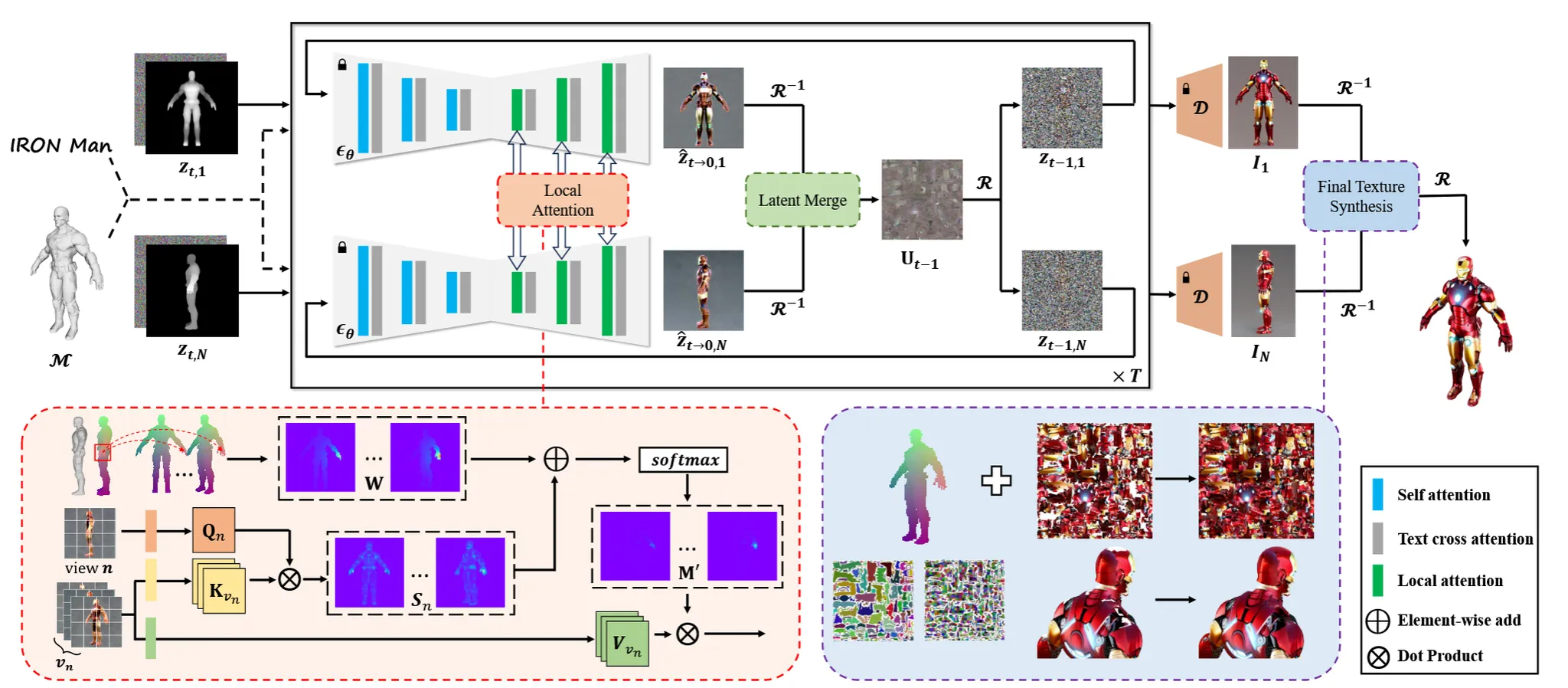
모델의 전체적인 아키텍처입니다. 하나씩 살펴보도록 하겠습니다.
Preliminaries
2D image diffusion 부분은 잘 아실테니까 notation 부분만 간단히 언급하도록 하겠습니다.
Mesh(M): 색칠이 안된 3D mesh(색칠 안되어있는 아이언맨)texture map($\tau$): 색칠에 대한 정보view point(C): 카메라의 시점redering function($R$): 3D에서 2D로 변환하기 위해서 특정 시점의 이미지를 렌더링
Local Attention
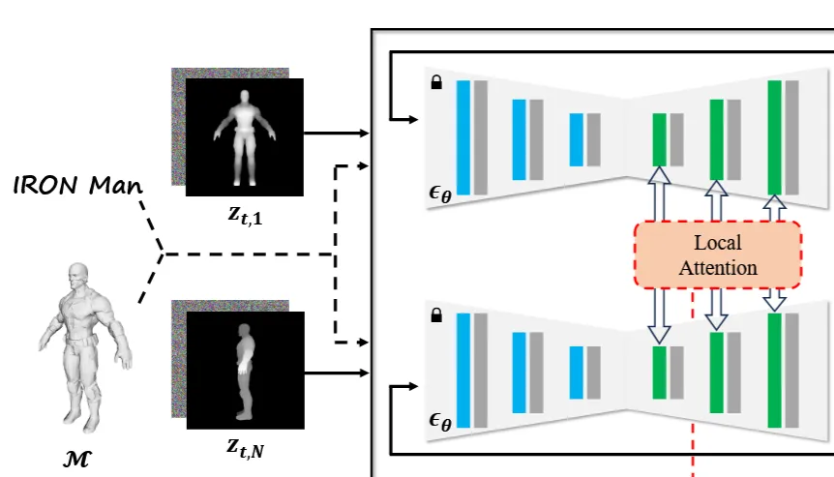
첫번째로 U-Net의 self-attention 부분을 서로다른 뷰에 대해서 cross-attention을 진행해서 view끼리의 consistency를 높인 local attention을 설명해드리겠습니다.
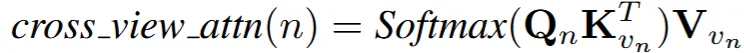
많은 3D representation과 texture 논문에서도 U-Net의 Self-attention 부분을 다른 view와의 cross-attention으로 바꾸고 해당 논문에서도 진행했습니다.

Cross-attention을 진행하게 되면 아래 사진처럼 확실히 이전에 비해서 뷰끼리의 consistency가 일치하는 것을 확인할 수 있습니다. 하지만 여기서의 문제는 texture가 단조로워진 다는 것입니다. 뷰끼리 일치시키려다 보니까 color diversity와 local details를 감소시킵니다. 가장 큰 이유는 cross-attention을 통한 분산 감소입니다. 어느 각도에서 보느냐에 따라서 light, highlight가 달라질 수 있지만, cross-attention을 통해서 이를 일치시켜서 texture가 단조로워집니다.

또한 위의 그림은 서로다른 뷰의 패치간에 attention map을 나타내는 것인데 정면에서 얼굴위주로 attention이 찍혀있지만, 다른 뷰에서는 얼굴이 아닌 다른 부분에 attention이 찍혀있습니다. 즉 서로 다른 부분에 대해서 일치시킨다는 문제점이 발생합니다.
이를 극복하기 위해서 attention bias matrix(W)를 추가합니다. 일반적으로 Cross-attention을 할 때 로 나타내는데 여기에 W를 추가한 로 수식을 변경합니다.
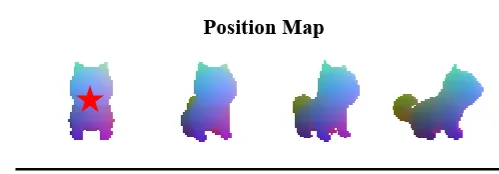
Attention bias matrix를 계산하기 위해 우선 특정시점의 position maps(O)을 생성합니다. Position map은 특정시점에서 보이는 3D좌표(x,y,z)를 (r,g,b)로 변환된 결과입니다. 이후에 각 시점별로 position map끼리의 Euclidean distance()를 구합니다.
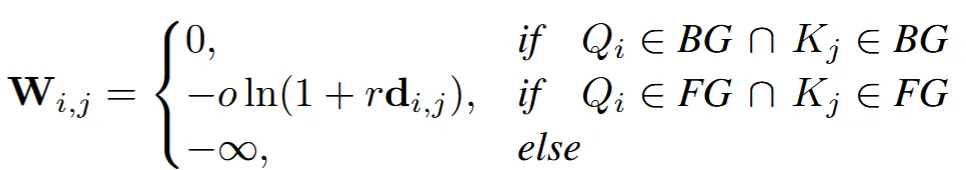
Position map끼리의 거리를 구하면 최종적으로 Attention bias matrix(W)를 구합니다. 우선 각 패치가 Background(BG)인지 Foreground(FG)인지 확인해야 합니다. 2개의 값을 어떻게 구한다고는 나와있지 않지만 일반적으로 position map이 0이면 해당 부분이 BG가 될 것입니다. 어쨌든 패치별로 BG냐 FG냐를 나타내고, 그 값을 기반으로 W를 구해서 softmax를 취하기 전에 더해줍니다.
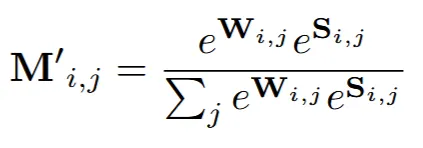
결론적으로 local attention의 수식은 위와 같이 나타낼 수 있습니다.

결과적으로 weigth map이 오른쪽 위와 같이 뷰별로 동일한 부분을 보기 때문에, 해당 부분에 대해서만 디테일하게 texture를 공유할 수 있습니다.B는 Block을 T는 Transformer layer를 나타내는데, 뒤로 갈수록 확실히 orginal attention은 모든 부분을, weigth map은 동일한 특정 부분만의 attention이 강조되는 것을 확인할 수 있습니다.

또한 이전 W를 결정할 때 정하는 하이퍼파라미터 o의 수치를 비교한 결과인데, 결론적으로 2가 가장 적절한 값임을 실험적으로 결정했다고 합니다.
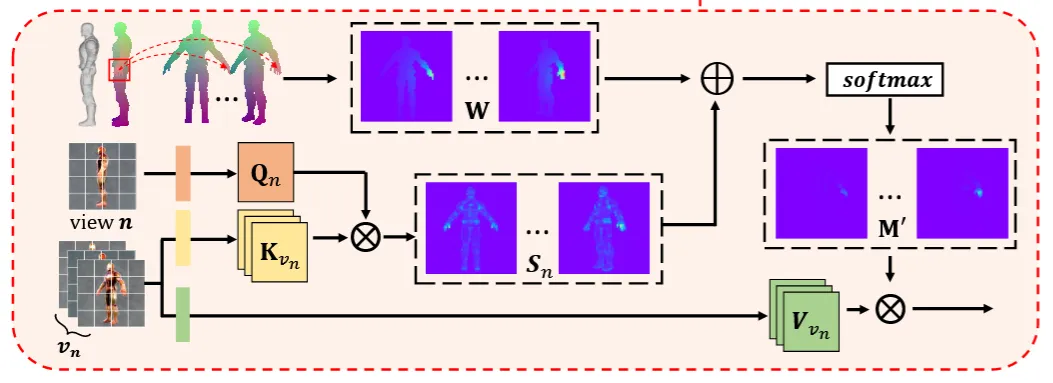
그림을 통해서 local attention의 알고리즘을 최종적으로 파악해보겠습니다. 기존에 U-Net의 self-attention부분을 cross-attention으로 바꿔서 다른 뷰()에 대해서 진행을 하는데, 그냥하면 texture가 단조로워지는 문제가 발생합니다. 이를 극복하기 위해서 attention bias matrix(W)를 추가해서 softmax를 취하게 돼서 시점별로 동일한 부분에 대해서 동일한 위치에 대한 부분의 attention을 얻게 됩니다.
Consistent Texture Synthesis

Local attention을 통해서 위에서 아래로 뷰끼리의 consistency가 좋아졌지만, 그래도 여전히 보이지 않은 미세한 부분들에 대한 consistency는 부족한 상태입니다. 따라서 이를 보완하기 위해서 latent space상에서 aligment 전략을 사용합니다.

다른 논문들에서도 latent space상에서의 aligment를 진행했지만, 이전 논문들에서 진행한 결과는 texture가 너무 단조로워지는 결과를 나타냈습니다. 따라서 새로운 latent merge pipeline을 해당 논문에서 제시했습니다.
Latent merge pipeline

초기에 각 뷰()가 랜덤 노이즈 N(0,1)에서 시작할 때, 텍스처()도 동일하게 랜덤 노이즈 N(0,1)에서 시작합니다. 가장먼저 z값을 이용해서 값을 얻습니다.
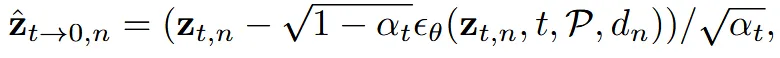
이때는 depth를 이용한 Controlnet을 사용해서 위의 수식처럼 를 얻습니다.
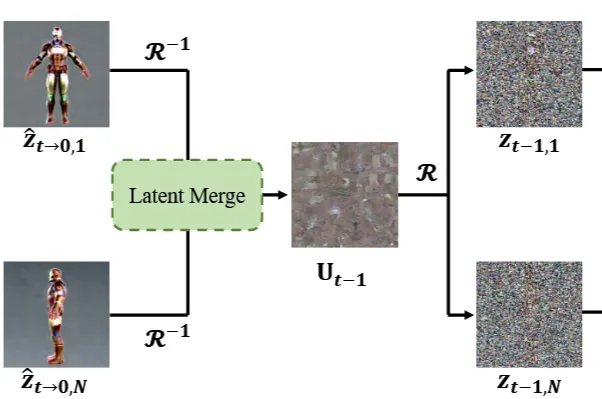
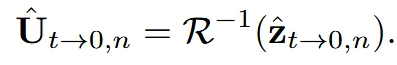
이후에 pre-view texture를 얻기 위해서 projection()을 진행해서 texture()를 얻습니다. 이렇게 얻은 texture는 아직 3D consistency를 얻지 못한 상태입니다. 3D로부터 texture를 얻을 때 단순히 평균을 구하면 디테일한 요소들을 잃을 수 있기 때문에 view-dependent aggregate를 진행합니다.
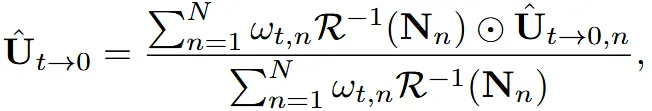
위의 수식에서 은 consine similarity map으로 각 픽셀별로 normal vector와 view direction의 코사인 결과입니다. 은 view n에서의 가중치를 나타냅니다. 초기에는 해당값이 1이지만 을 선형적으로 interpolation으로 값이 변합니다. 이때 는 view point 과 사이의 각도이고, γ는 하이퍼파라미터입니다.
초반에는 가중치가 모두 1이기 때문에 texture의 결과가 모든 시점에서의 평균적인 결과라서 디테일한 부분들이 부족하겠지만, 시간이 지날수록 특정뷰의 가중치가 증가해서 특정 뷰에 의존적인 texture가 생성됩니다. 이러면 해당 뷰의 디테일한 요소들이 표현된 texture가 생성됩니다.

이렇게 디테일한 요소들의 정보가 들어간 texture에 대해서 diffusion의 한 step을 진행해서 의 값을 얻게 됩니다.
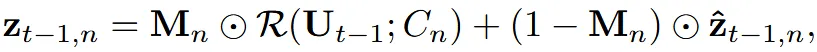
업데이트 된 로부터 다시 렌더링을 통해서 t-1시점의 z값을 얻고 지금까지 진행한 과정을 반복하게 됩니다. 이때 forground에 해당하는 부분에 대한 mask를 으로 나타내서, 해당 부분만 texture를 기반으로 업데이트하고, 나머지 부분은 latent merge 이전 결과를 사용합니다.
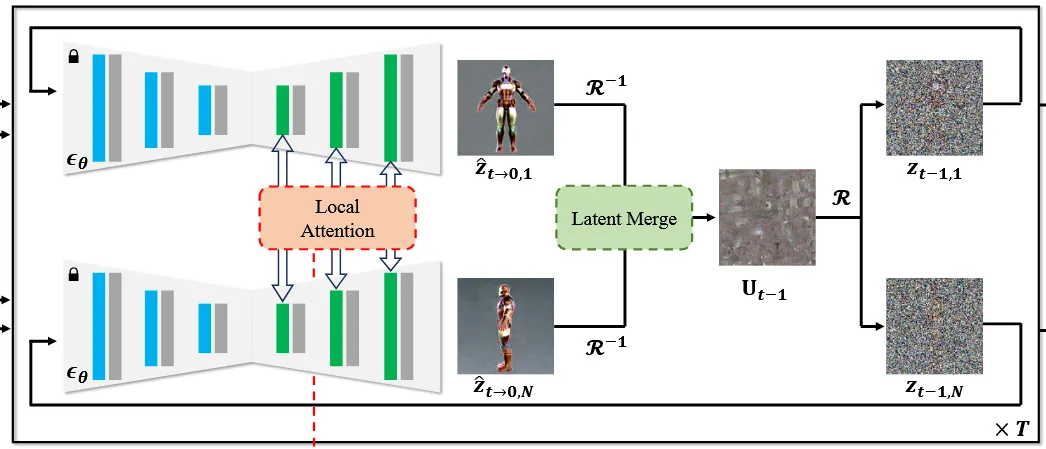
그림상으로는 위와 같습니다. T시점에서 시작해서 local attention, latent merge를 통한 texture update, update된 texture를 렌더링해서 다시 T-1시점의 z값을 얻고 이를 다시 T-2, T-3 …0 시점의 결과를 얻는 것입니다. 참고로 마지막 5 step에서는 latent merge를 수행하지 않아서 저해상도 latent를 reprojection해서 artifact가 발생하는 것을 방지했습니다.
Final Texture Synthesis
현재 위의 과정은 모두 latent space상에서 진행했기 때문에 이를 decoder를 통해서 의 이미지를 얻습니다.
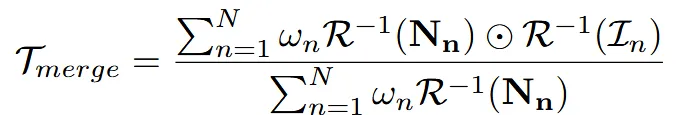
그리고 마지막으로 나타내는 texture는 위와 같습니다. 이전의 texture map의 가중치 업데이트하는 식과 똑같은데 U대신에 I가 들어갔다고 생각하시면 됩니다.
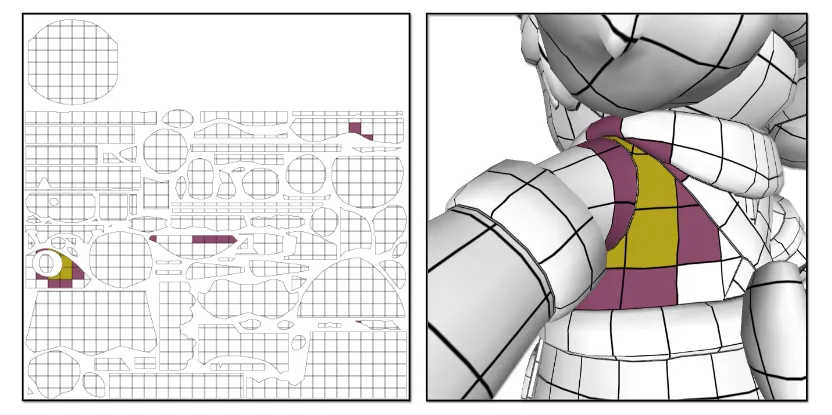
그리고 마지막으로 보이지 않는 영역에 대한 texture를 채워넣는 Surface space color dilation 설명은 Appendix A에 있습니다. 우선 UV map을 위의 그림처럼 equal-sized grids로 더 잘게 나눠진 sub-UV islands를 생성합니다. 이후 sub-UV islands에서 인접한 영역끼리 adjancey matrix를 구합니다.
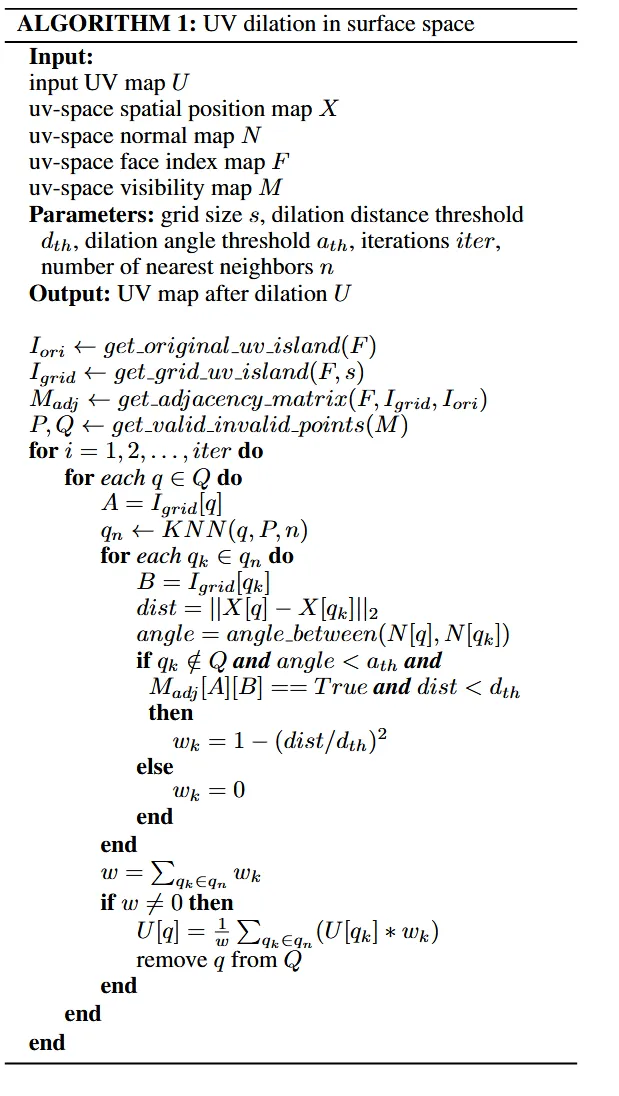
이후 우리가 보이지 않는 영역에 대해서 3D 거리가 인접한 부분, normal vector가 비슷한 부분, 이전에 계산한 adjancey matrix로 인접한 부분 3개의 부분에 대한 weighted averge로 해당 픽셀 값을 선택합니다. 자세한 내용은 위의 알고리즘을 참조하시면 됩니다.

Surface space dillation을 이용한 결과는 위와 같습니다. 2D UV space상에서 dillation한 결과보다 훨씬 더 자연스럽게 픽셀값이 확장 된 것을 확인할 수 있습니다. 참고로 UV Island Grid가 이상하게 보이는 이유는 영역을 구분하기 위해서 단순히 색깔을 다르게 한 것 입니다.
Method
이제 최종적인 아키텍처를 다시 살펴보도록 하겠습니다. U-Net의 Self-attention을 local attention으로 변경해서 서로다른 뷰에 대해서 디테일을 살리면서 consistency를 학습하고, 한번의 iteration동안 latent merge를 통해서 평균적인 정보가 아닌 특정 뷰를 기반으로 texture를 업데이트 해서 texture의 디테일한 부분을 표현하고, 마지막으로 surface space color dillation으로 보이지 않는 영역의 픽셀을 채워넣는 과정입니다.
Limitation
- 2D diffusion을 사용했기 때문에 texture가 mesh에 맞게 완벽하게 생성되지 않습니다.
- 또한 lighting effect를 고려하지 않은 점 역시 한계점으로 존재합니다.
