RoCoTex: A Robust Method for Consistent Texture Synthesis with Diffusion Models 논문 리뷰

Text-to-texture gerneration 논문들을 보면 사람의 눈의 대칭이 안 맞는다거나(눈 왼쪽은 작고, 오른쪽은 크고), 아니면 캐릭터의 앞면과 뒷면이 일치하지 않는 현상들을 많이 보셨을 것입니다. 또한 Sphere 같은 물체를 생성할 때 Seam(선)이 생성되는 부분들도 많이 보셨을 것입니다. 이러한 inconsistency와 seam 문제를 해결하기 위한 논문으로 ROCOTex가 나왔습니다.
Proposed Method
Symmetrical Views and Regional Prompts
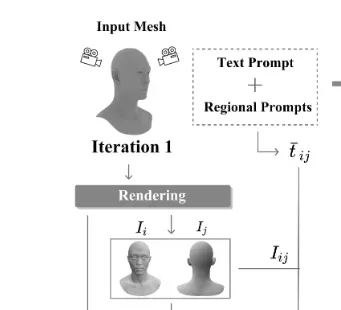
Diffusion을 이용해서 1개의 이미지만 생성할 경우 context loss와 view inconsistency 문제가 발생하기 때문에 2개의 뷰를 동시에 생성하도록 알고리즘을 설계했습니다. 위의 그림을 보시면 정면과 뒷면이 수평적으로 붙여서 이미지가 생성되는 것을 확인할 수 있습니다.

하지만 Diffusion 모델들은 주로 정면 이미지로 학습이 되어있기 때문에 Back view에 대해서도 얼굴을 생성하는 Janus problem(위의 사진)이 나타납니다.
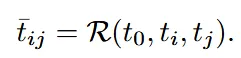
따라서 원래 입력으로 들어가는 text prompt()외에도, front view()와 back view()를 추가로 입력해서 Regional Prompter(R)를 이용해서 텍스트 임베딩을 생성합니다.
SDXL and Multiple ControlNets
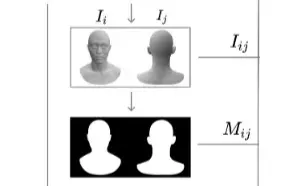
일반적인 stable diffusion은 512x512 해상도의 이미지를 생성하기 때문에 디테일한 부분을 생성하기 어렵습니다. 따라서 stable diffusion XL(F)을 사용해서 디테일한 부분도 생성할 수 있도록 설계 했습니다. Stable diffusion XL의 입력으로 2가지 뷰의 이미지 뿐만아니라, un texutred area에 대한 mask도 들어가게 됩니다. 해당 마스크는 texture를 채워야 될 영역을 생성합니다.
마스크를 너무 딱맞게 생성하면 inpainting의 결과로 테두리에서 artifacts가 발생합니다. 따라서 mask를 16 → 32 픽셀로 팽창합니다. 이러한 마스크를 inpainting mask라고 하고 라고 표기합ㄴ디ㅏ.
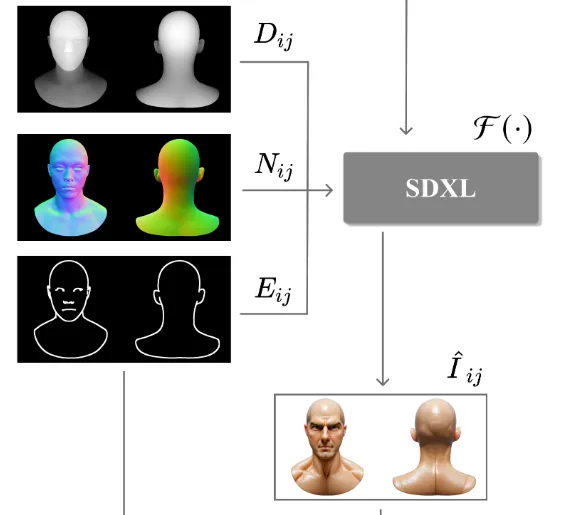
SDXL에게 더 많은 3D 정보를 주기 위해서 여러개의 ControlNet을 실행합니다. 는 각각 Depth, normal, edge map을 나타냅니다.
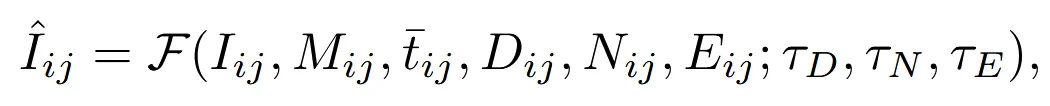
결론적으로 Stable diffusion XL에 들어가는 입력은 위와 같이 여러개의 입력값을 갖게 됩니다. 마지막에 나타난 는 각 controlnet에 대한 가중치 값입니다.
Confidence-based Texture Blending
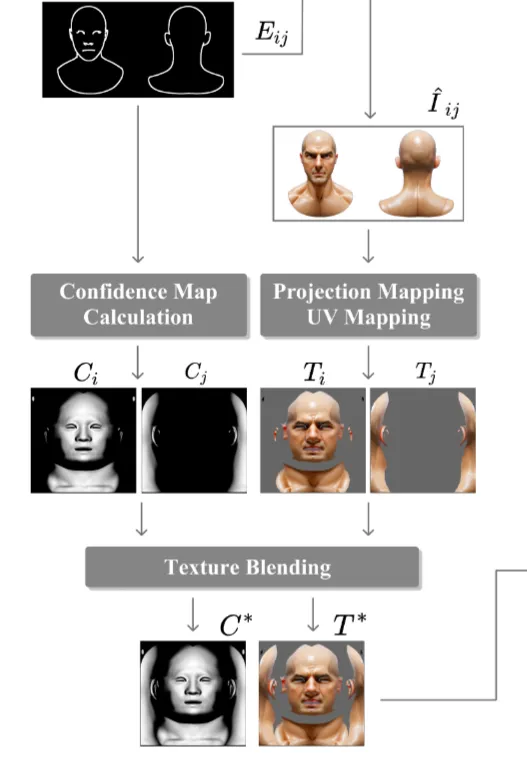
Stable diffusion XL의 결과로 나온 texture 이미지를 정면()과 후면()로 분리한 후, 이를 하나의 UV Map()으로 합칩니다.
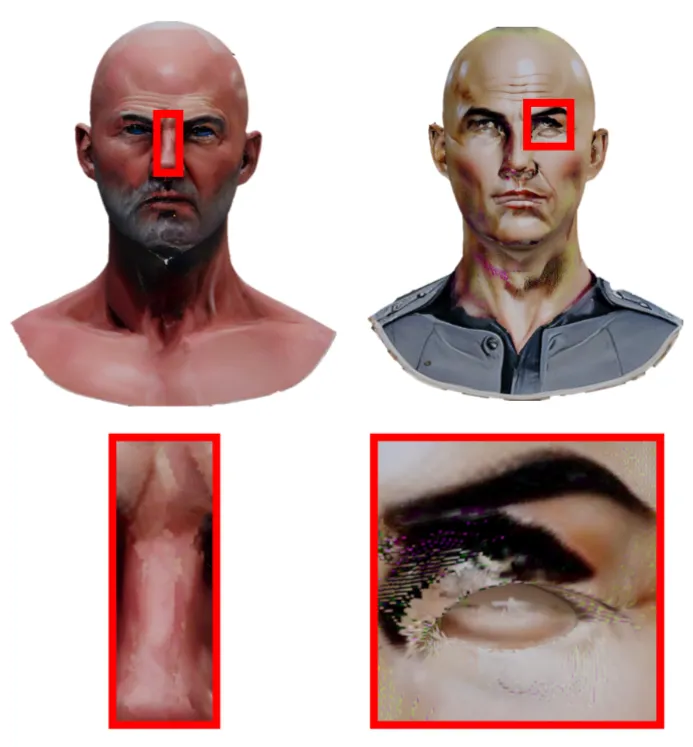
이때 Text2Tex처럼 accumulate하게 합칠 경우 위의 그림 중 왼쪽 부분처럼 seam이 나타나고, TEXture처럼 global optimization을 진행해도, artifact가 발생합니다.
이러한 현상을 극복하기 위해서 conofidence를 사용합니다. 정면 이미지에 대한 confidence()와 후면 이미지에 대한 confidence(), 그리고 전역 confidence()으로 나타냅니다. Confidence의 값은 surface normal과 viewing direction의 각도 차이에 의해서 0부터 1사의 값을 갖습니다.
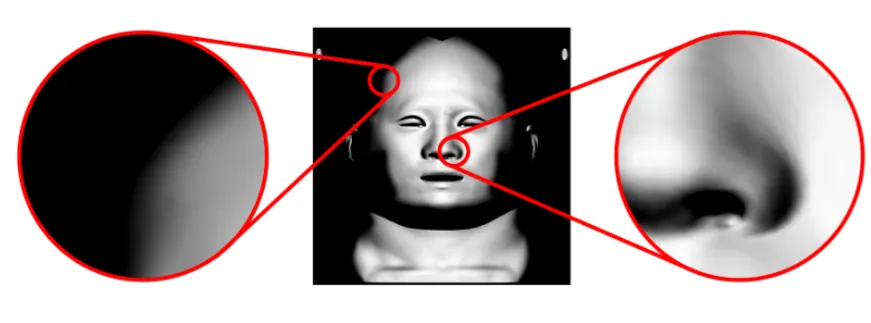
왼쪽 위처럼 시야에서 비스듬히 있는 영역은 confidence가 낮을 것이고, 정면의 코 부분은 confidence의 값이 높을 것이라고 생각해 볼 수 있습니다.

각 값들을 이용해서 global한 값들을 업데이트하게 됩니다. 이렇게 될 경우 가중치에 따라 우리가 원하는 부분에 대해서 더 좋은 texture를 얻고, seam과 artifcat 현상이 나타나지 않는다고 합니다.
Soft-inpainting with Differential Diffusion
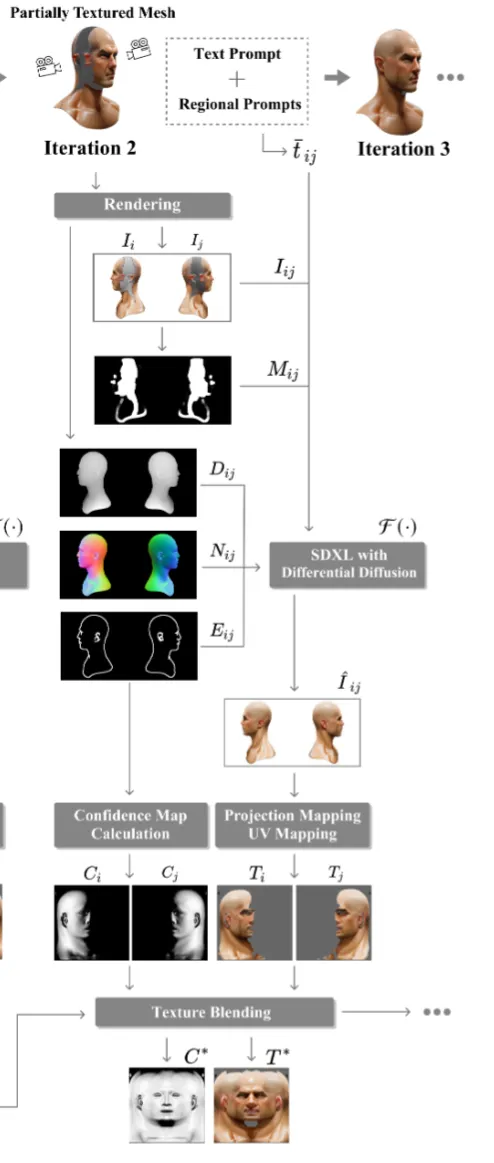
이전까지의 결과를 통해서 첫번째 iteration 결과를 얻은 것이고, 이를 이용해서 iteration을 반복하게 됩니다. 이때 문제가 되는 부분은 mask inpainting 부분입니다. 새로운 부분에 대해서 mask를 생성해서 inpainting을 하면 경계 부분에서 갑작스러운 texture 변화와 seam 현상이 나타납니다.

이를 극복하기 위해서 soft-inpainting 방식을 사용합니다. Soft-inpainting 방법은 첫번째로 이전 mask를 blur(위의 사진)처리해줍니다. 두번째로 Differential Diffusion 방식을 사용해서 각 픽셀별로 서로다른 strenght를 이용해서 inpainting을 해줍니다. 경계 부분은 약한 strength를, 중심부는 강한 strength를 주어서 경계를 부드럽게 해줍니다.

왼쪽 사진이 soft-inpainting의 결과이고, 오른쪽 사진이 Text2Tex에서 사용한 일반적인 inpainting 방식의 결과입니다. 확실히 texture가 부드럽게 변하는 것을 확인할 수 있습니다.
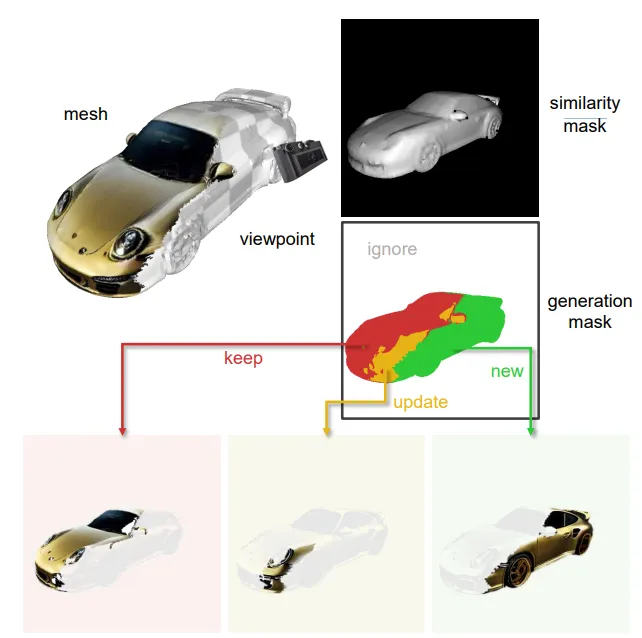
위의 그림은 Text2Tex에서 confidence를 이용해서 new, update, keep mask를 생성하는 과정입니다. 이렇게 각각의 영역에 대해서 동일한 strength의 denoising 과정을 진행하기 때문에 seam 현상을 극복하기 어렵다고 논문에서 밝히고 있습니다. 이와달리 해당 논문에서는 Differential diffusion을 사용했기 때문에 픽셀별로 strength를 다르게 줄 수 있어 seam 현상을 극복할 수 있습니다.
Limitations
- Iterative texture 생성으로 인해서 occlusion issue를 완벽하게 해결하지는 못했다.
- Lighting issue는 고려하지 않았다.
