기존에 다양한 멀티모달들이 나왔지만 6개의 모달리티를 엮을 수 있다는 논문이 있다는 소식에 궁금해서 논문을 읽게 됐다.
논문을 읽기전 논문에 대해 내가 궁금한 점을 적어두고 이를 해결하면서 읽어가면 잘 이해되는거같아 가장 위에 적어두고 논문을 다 읽고나서 이에대한 해답을 같이 알아보도록 하겠다.
1. 꼭 6개의 모달리티를 전부 사용해야될까?
(6개 모달리티: image, video, audio, depth, IMU, thermal data)
2. CLIP과의 공통점과 차이점은 무엇일까?
3. 이미지를 중심으로 나누는 이유?
IMAGEBIND가 나오게 된 배경
이전까지 다양한 멀티모달 모델들이 나왔다. 하지만 6개의 모달들을 묶는 모델은 나오지 않았다. 또한 이 모델의 핵심은 꼭 6개의 모달의 정보가 모두 있지 않아도된다. 몇개의 정보만을 이용해서 image-retrival 혹은 zero-shot classification이 가능하다.
image-retrival: 주어진 쿼리 이미지에 대해 유사한 이미지를 검색하는 것
zero-shot: 새로운 클래스에 대한 분류를 위해 보조 정보를 사용
데이터 처리 및 변환
- 이미지와 비디오: 모두 ViT(Vision Transformer)를 사용하여 인코딩된다.
비디오는 2초 동안 샘플링된 2프레임 비디오 클립을 사용한다. - 오디오: 2초 동안 샘플링된 오디오를 멜 스펙트로그램으로 변환하고 이를 ViT를 사용하여 인코딩한다.
- Thermal images and depth images: 각각 1개의 채널로 구성되며 ViT를 사용하여 인코딩된다.
- IMU 신호: 가속도계와 자이로스코프 측정값을 x, y, z 축으로 포함하고, 5초 클립을 2,000 타임 스텝으로 나누어 1D 컨볼루션과 Transformer를 사용하여 인코딩된다.
- 텍스트: CLIP를 사용하여 인코딩된다.
이후 linear projection을 수행해서 d차원 임베딩 수행. 이는 정규화 되고 InfoNCE loss를 사용가능하게한다.
다중 모달리티 학습의 유연성
이미지와 텍스트를 주된 학습 데이터로 사용하지만, 학습된 표현을 오디오, 비디오 등 다른 모달리티로 학장할 수 있는 능력을 갖추고 있다.
<다른 모달리티로의 확장 순서>
1. single joint embedding space를 구축. 이미지와 텍스트를 동일한 잠재 공간에 투영하여 각 모달리티의 특성을 유사한 방식으로 표현
2. 이미지와 텍스트로 학습된 임베딩 공간을 다른 모달리티로 확장. 다른 모달리티의 데이터를 모델에 입력하고, 해당 데이터의 특성을 이미지와 텍스트로 학습된 임베딩 공간에 매핑
3. 이후 전이학습과 파인튜닝 기법을 사용
Single joint embedding space<단어정리>
하나의 일관된 방법으로 표현하기 위한 것으로 InfoNCE Loss함수를 사용해서 학습한다.
InfoNCE Loss

- zi: 주어진 데이터 포인트의 임베딩 벡터
임베딩: 고차원의 데이터를 저차원의 공가능로 변환하는 기법 - zp: 대상과 관련된 positive sample의 임베딩 벡터
- znk: 무관한 negative sample의 k번째 임베딩 벡터
- sim(⋅): 두 벡터 간의 유사도를 계산하는 함수. 일반적으로 내적(dot product) 또는 코사인 유사도(cosine similarity)가 사용
- τ: softmax의 온도(temperature) 파라미터. 이는 출력의 sharpness를 조절하는 역할
scalar temperature: Softmax의 입력값을 조절해 출력값의 분산을 조절하거나, 모델의 일반화 성능을 향상시키는데 사용될 수 있다. 값이 높을수록 Softmax 함수의 출력값이 더 부드럽게 변화한다.(클래스에 대한 확률이 균등해진다) - K: 노이즈 예시의 수
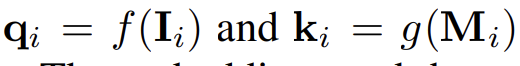
InfoNCE Loss에서 다시 single joint embedding space로 돌아오면 I는 이미지를 의미하고 M은 다른 모달리티를 의미한다. normalized embedding을 이용해서 각각을 q와 k로 바꾼다.
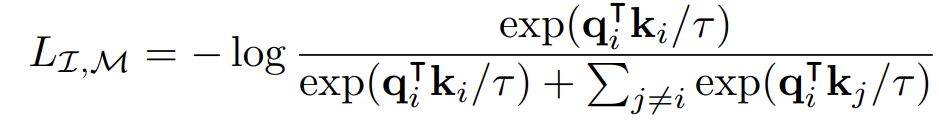
InfoNCE Loss함수를 사용해서 학습하고 이는 I에서 M으로의 방향과 M에서 I로의 방향 모두 이루어진다.
이미지출처:https://thecho7.tistory.com/entry/%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-IMAGEBIND-One-Embedding-Space-To-Bind-Them-All
Emergent zero-shot learning
기존 zero-shot learning에서는 보조 정보가 필요했다면 imagebind 논문에서 말하는 emergent zero-shot learning에서는 특정한 작업에 대해 직접적으로 학습하지 않았음에도 불구하고, 모델이 그 작업을 수행할 수 있는 능력
예를들어 (이미지, 텍스트)와 (이미지, 오디오) 같은 이미지와 짝을 이루는 데이터만을 사용하여 학습한다. 즉 오디오를 직접 텍스트와 짝지어 학습시키지 않음에도 불구하고, 텍스트 프롬프트를 사용하여 오디오를 분류하는 능력을 갖추게 된다.
새로운 데이터 유형과의 상호작용

달리에서 텍스트를 이용해서 이미지를 생성하는 것을 오디오 데이터를 사용하여 이미지를 생성하는 새로운 방식을 이용했다.
실험결과
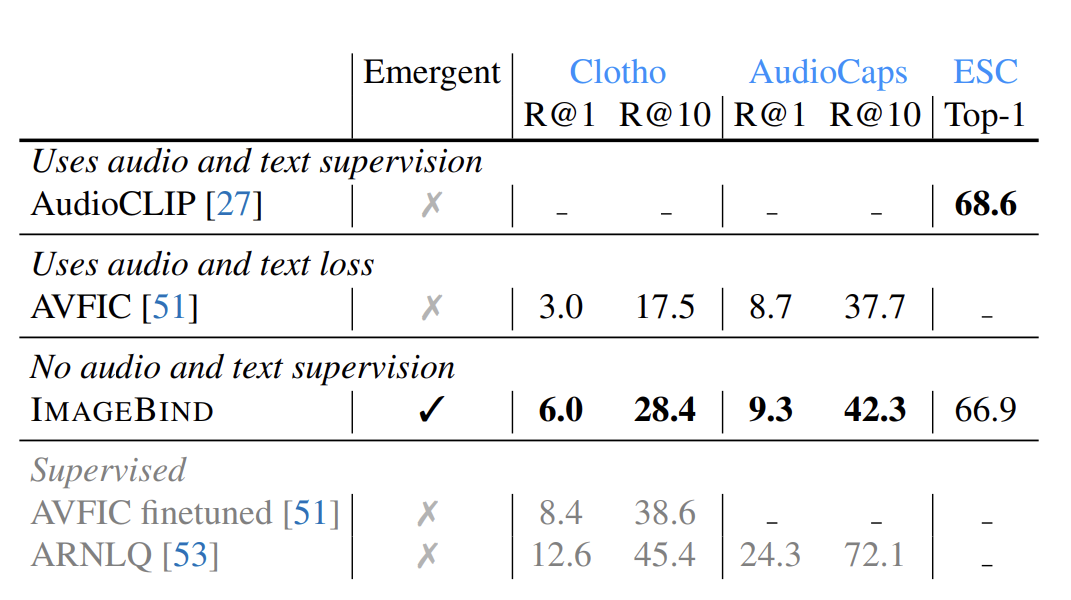
audio retrieval과 classification 비교
imagebind의 emergent zero-shot performance는 기존 Audio CLIP 혹은 AVFIC보다 훌륭하다
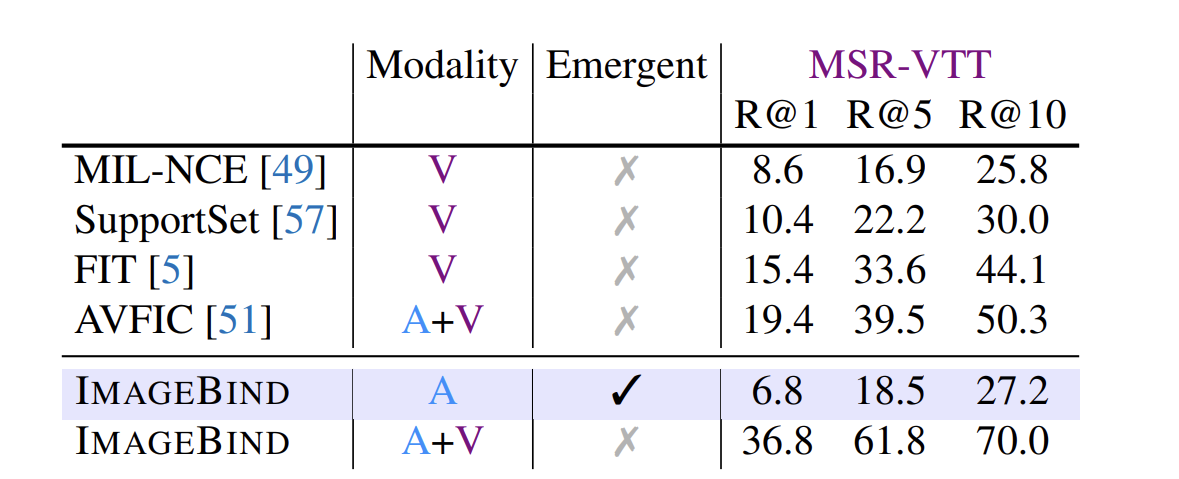
text to audio and video retrieval 평가 비교
audio만 이용해도 좋은 성능을 나타내고 audio와 video를 둘다 이용하면 더 좋은 성능을 나타내고있다.

image + audio 정보를 이용해서 Image retrival
첫번째 이미지를 예로 들어서 설명하면 과일 사진에 새가 지저귀는 오디오를 넣으면 과일과 새가 보이는 이미지를 찾는다.
마무리
다시 처음 생각했던 3가지의 질문에 답을 해보겠다.
1.꼭 6개의 모달리티를 전부 사용해야될까? -> 아니다
2.CLIP과의 공통점과 차이점은 무엇일까?
->ImageBind는 CLIP의 원리를 기반으로 하되, 이를 더 넓은 범위의 데이터와 작업에 적용할 수 있도록 발전시킨 모델이라고 볼 수 있다.
3.이미지를 중심으로 나누는 이유는? -> 논문에 정확히 나오지 않았지만 데이터의 수가 많고, 다양한 작업에 적용 가능한 범용적인 모달리티이기 때문이다.
본 논문에서는 기존의 image-text에 국한되지 않고 다양한 모달리티를 이용하는 모델이다. 직접적으로 학습하지 않아도 사용가능한 emergent zero-shot learning으로 정말 다양한 분야에 적용이 가능할거같다. 앞으로 본 논문에 어떤점을 수정할지에 대해서 더 깊이 연구해보면서 추가적인 자료를 올리도록 하겠다.
