모델 등장 배경
계산 복잡도를 줄이기 위해
RNN은 각각의 단어를 임베딩 해서 학습하지만, Transformer는 문장 하나를 임베딩해서 학습하기 때문에 계산 복잡도가 줄어듭니다.
가변길이 벡터를 사용하기 위해
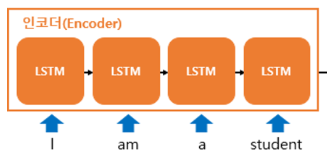
기존 RNN, LSTM, Seq2Seq 모델들은 고정된 크기의 context vector를 사용했기 때문에 긴 문장을 사용할 수 없다는 단점이 있습니다.
가변 context vector를 사용하기 위해 Attention 모델이 나왔습니다.
병렬처리를 사용하기 위해
순환 모델은 각 시간 단계에서 이전 상태에 의존하기 때문에 계산이 순차적으로 이루어져야 합니다. 이는 병렬 처리를 어렵게 만들어 처리시간과 메모리 사용량이 크게 증가합니다.
이와 달리 Transformer의 Attention 메커니즘을 사용하면 Sequence의 모든 요소를 동시에 처리할 수 있습니다
Query, Key, Value
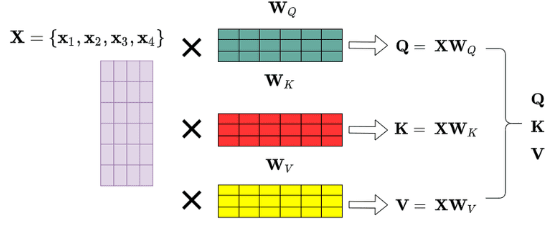
Q(Query): 물어보는 주체
K(Key): 물어보는 대상
V(Value): 값
예를 들어서 I am a student중 I가 Querry, I / am / a/ student 각각이 Key가 되어 Q와 K의 연관성을 학습하게 됩니다.
Query, key, value의 차원은 <임베딩 차원 / h> 입니다. (논문에서는 512/ 8 = 64로 이용했습니다.)
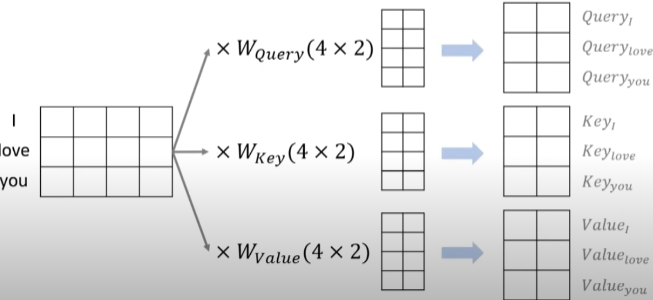
예시 그림으로 처음 3개의 단어가 있는 문장이 3X4 행렬로 있고 이를 각각의 Q,K,V로 만들어줍니다.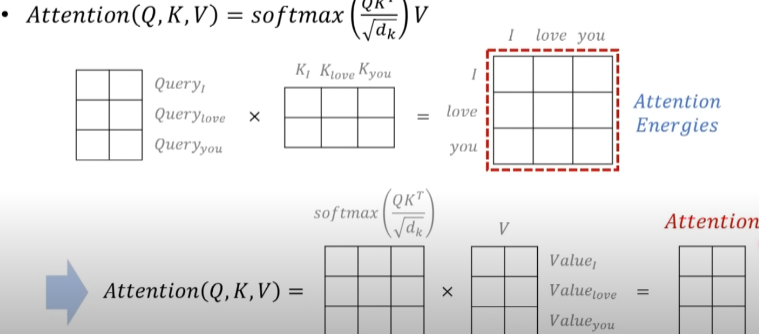
Q와 K의 행렬곱을 취한 후 각각의 단어가 어떠한 단어와 연관성을 보여주는지 나타내주는 Attention Energies를 생성합니다.
이를 그림의 밑에 부분처럼 softmax함수 취한 후 Value와 곱해주면 최종적인 Attention 결과가 나오게 됩니다. 이 부분은 아래에 다시 한번 설명을 자세히 하니 참고해서 보면 좋을 거 같습니다.
Scaled Dot-Product Attention
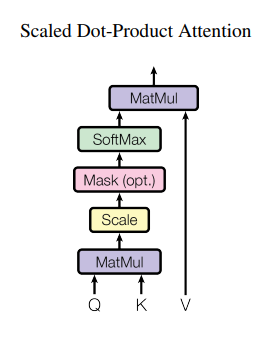
사진을 보면 Q, K가 들어오면 행렬곱을 수행한 후 간단하게 스케일을 해준 후 (Mask는 선택 옵션) 각각의 연관성을 SoftMax를 이용해 값으로 나타나게 됩니다.
이후 이 확률값과 Value를 행렵곱을 취하는 것이 하나의 과정입니다.
cf. Mask 행렬
특정 단어는 무시할 수 있도록 마스크값으로 음수 무한의 값을 넣어 softmax 출력값이 0에 가까워지도록 합니다.
Multi-Head Attention
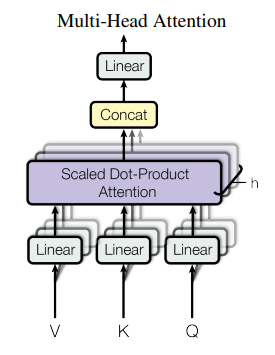
입력값이 들어왔을 때 V,K,Q로 분리한 후 이를 h개로 구분합니다.
h개의 서로 다른 attention값들을 학습해 구분된 다양한 특징들을 학습하게됩니다. 입력값과 출력값을 같게 해주기 위해서는 Concat를 수행시켜 줍니다. 마지막으로 Linear Layer를 거치면 출력값이 나오게 됩니다.
ENCODER
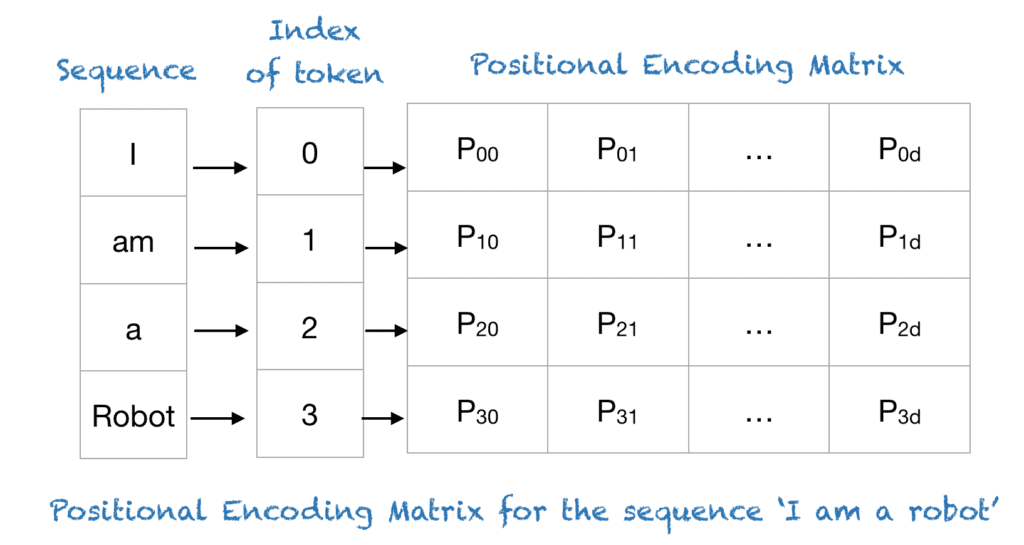
전통적인 임베딩과 같은 방식으로 단어의 개수만큼(4개) 행을 만들고, dimension(논문에서는 512로 지정)만큼 열을 만듭니다.
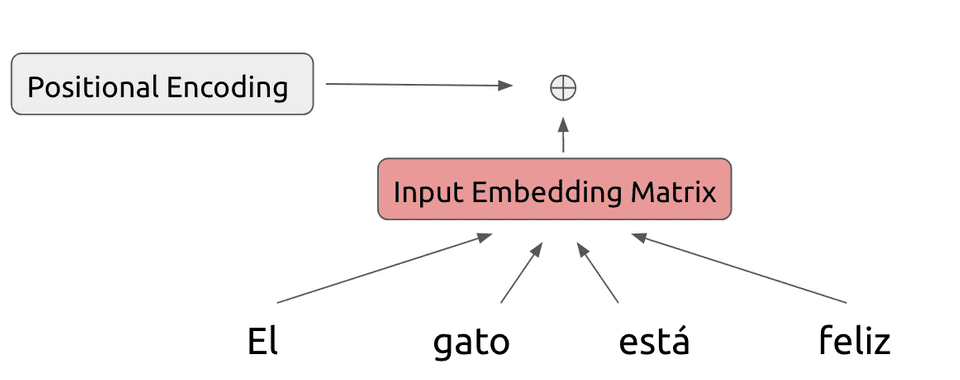
위의 결과로 나온 매트릭스에 위치 정보인(positional Encoding)을 추가해 줍니다.
위치정보는 주기 함수(sin,cos등)를 활용한 공식을 사용합니다.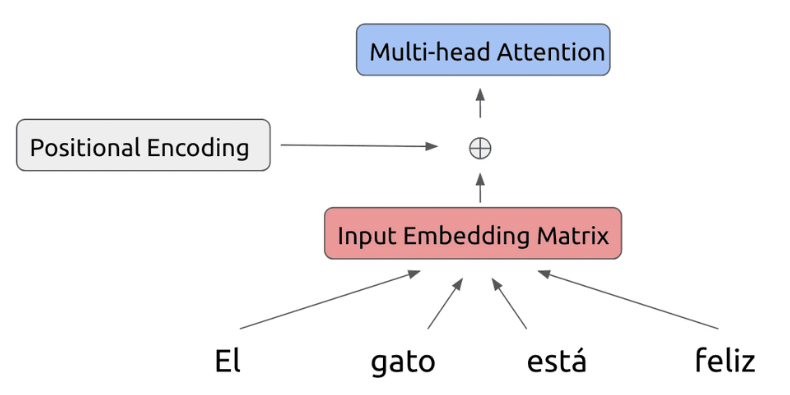
위치 정보까지 더해서 나온 값을 바탕으로 Multi-head Attention을 진행합니다.
여기서 진행하는 Attention은 Self-attention이라고 각각의 단어끼리 어떤 연관성을 가졌는지 분석하는 것입니다.
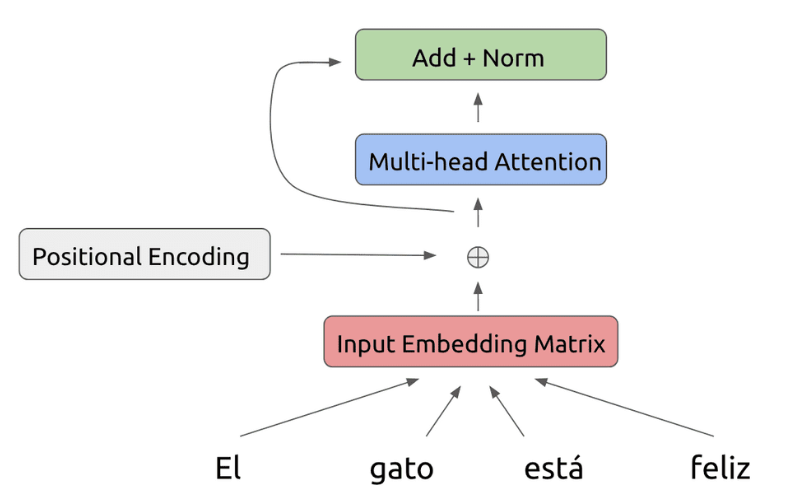
여기에 추가로 잔여 학습(Residual Learning)을 사용합니다. Resnet에서 가장 많이 사용하는 방법으로 학습하지 않고 다음 layer에 값을 전달해 주는 것입니다. 학습 난이도가 낮아 초기에 모델 수렴 속도가 높아져 global optimal을 찾기 쉬워집니다.
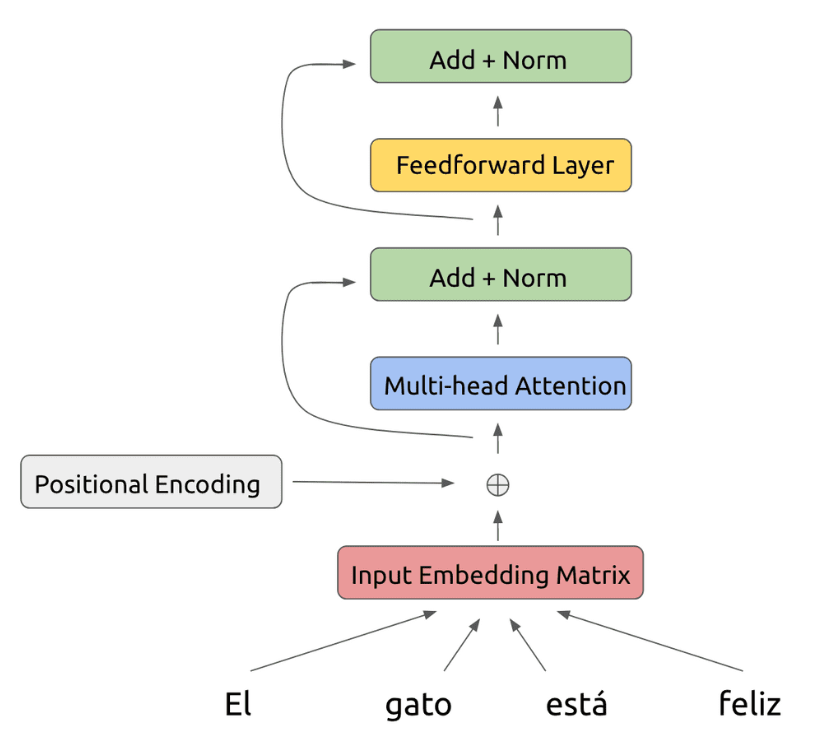
이그림은 최종적으로 Encoder에서 하나의 layer에 해당하는 그림입니다. 이전까지의 설명에 Feedforward Layer를 추가하고 마찬가지로 잔여 학습시키는 것입니다.
Encoder의 하나의 layer 순서를 다시 정리하면 각 단어를 임베딩 시키고 위치 정보를 더해 이를 attention을 이용해 단어들의 연관성을 파악한 뒤 잔여 학습과 FF layer를 거치면 하나의 결과값이 나옵니다.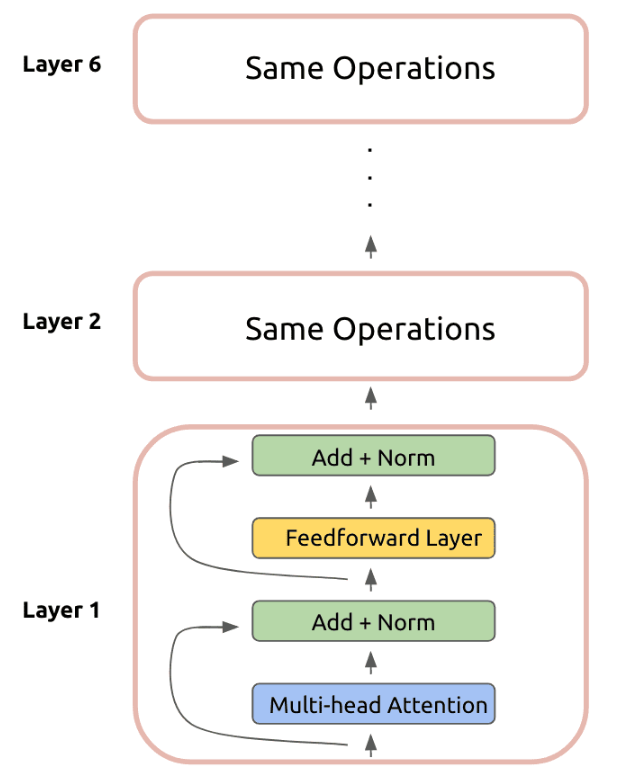
이렇게 논문에서는 총 6개의 layer를 사용했고 이 결과가 앞으로 배울 각 Decoder layer의 input 값이 됩니다.
DECODER
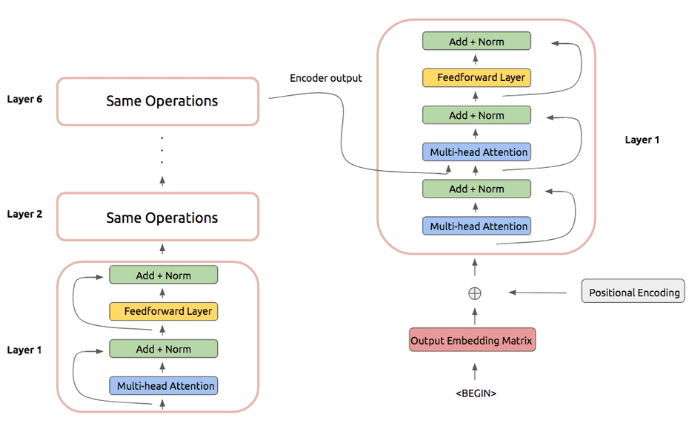
Decoder 부분에서는 우선 Encoder와 마찬가지로 처음에 출력 임베딩 행렬에 위치정보를 추가하고 attention을 한번 거칩니다.
여기서 2번째 attention은 방금 Decoder에서 나온 행렬과 Encoder에서 나온 행렬을 이용해 attention을 취합니다.
이후 나머지 방법은 ENCODER와 마찬가지로 Feed Forward layer와 잔여 학습을 거치면 하나의 Decoder layer의 출력값이 나오게 됩니다.
cf. 여기서 Decoder의 처음 부분에 수행하는 Attention Masked Decoder Self-Attention은 Encoder Self-Attention과 다르게 뒤쪽에 나온 단어를 참고하면 치팅을 할 수 있기 때문에 앞의 단어만을 참고해서 학습을 합니다.
cf. Masked Decoder Self-Attention 결과과 Q가 되어 Encoder의 출력값을 K, V로 사용해 학습하는 것을 Decoder의 2번째 Attention 부분인 Encoder-Decoder Attention입니다.

Encoder와 마찬가지로 6개의 layer를 거치면 최종적으로 우리가 원하는 출력값을 얻게 됩니다. 참고로 Encoder의 출력값은 Decoder의 모든 layer에 2번째 attention 수행 시 사용하게 됩니다.
마무리
"Attention Is All You Need" 논문을 한마디로 표현하면 기계 번역 및 기타 시퀀스 간 작업의 효율성과 성능을 크게 향상시키기 위해 반복 레이어 없이(각 레이어마다 파라미터가 다르므로) Attention 메커니즘에만 의존하는 새로운 신경망 아키텍처인 Transformer 모델이라고 할 수 있습니다.
