Image Sculpting: Precise Object Editing with 3D Geometry Control[CVPR 2024]

기존 2D 이미지를 편집하기 위해서는 2D 상에서의 변형을 가하는 방식들이 많았지만, 처음으로 3D상으로 변환한 뒤 3D 공간에서 편집을 진행하고 이를 다시 2D 상으로 렌더링하는 방법을 제시했습니다. 이를 통해 Pose 변환, 회전, 위치 변환, 3D 오브텍즈 조합, 물체 일부 잘라내기, 요소 추가등 다양한 분야에서 높은 성능을 달성했습니다.
Overview of 3D Shape Deformation
Space Deformation
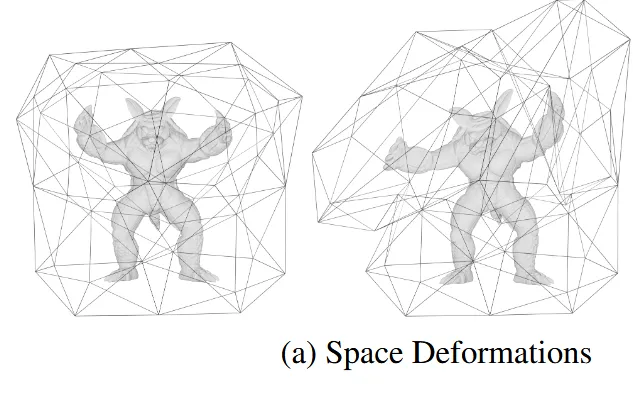
3D 공간 전체에 적용되는 변형 함수(3차원 → 3차원)를 이용하여 물체를 변형하는 방식입니다. 점들에 대해서 변형하는 함수만 사용하다보니 전체적인 형태를 인지하지 못합니다.
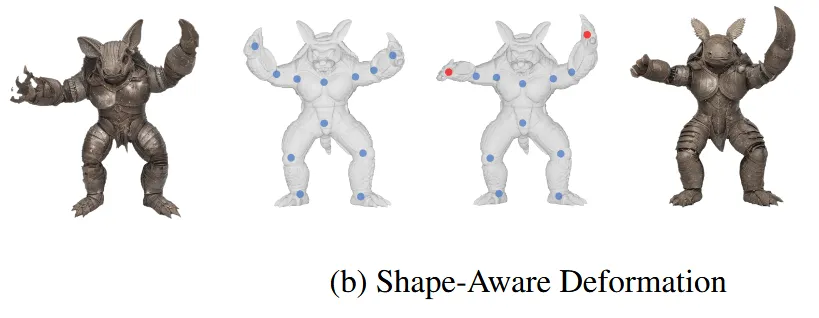
물체의 표면 구조를 고려하여 설계된 변형 방식입니다. 위의 그림에서 보이는 것처럼 몇개의 제어포인트만으로 부드러운 곡면을 정의하는 것입니다. 제어 포인트의 변형을 통해서 자유롭게 물체를 변형할 수 있습니다. 하지만 제어포인트를 찾는게 어렵다는 단점이 존재합니다.
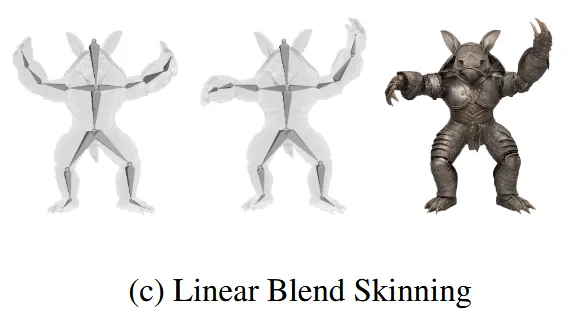
가장 널리 쓰이는 방식으로 물체의 각 점을 여러 affine transformation의 가중 평균으로 정의합니다. 각 점이 몇개의 뼈대에 얼마나 영향 받는지를 수치로 정하고, 이들을 선형 결합하여 나타냅니다.
해당 논문에서는 3가지 방식을 모두정확하게 예측할 수 있습니다.
Method
2D 이미지가 들어오면 이를 3D로 변환한 뒤 우리가 원하는 조작을 가하고 다시 2D 상으로 돌려서 우리가 원하는 변화가 반영된 2D 이미지를 얻는 것을 목표로 합니다.
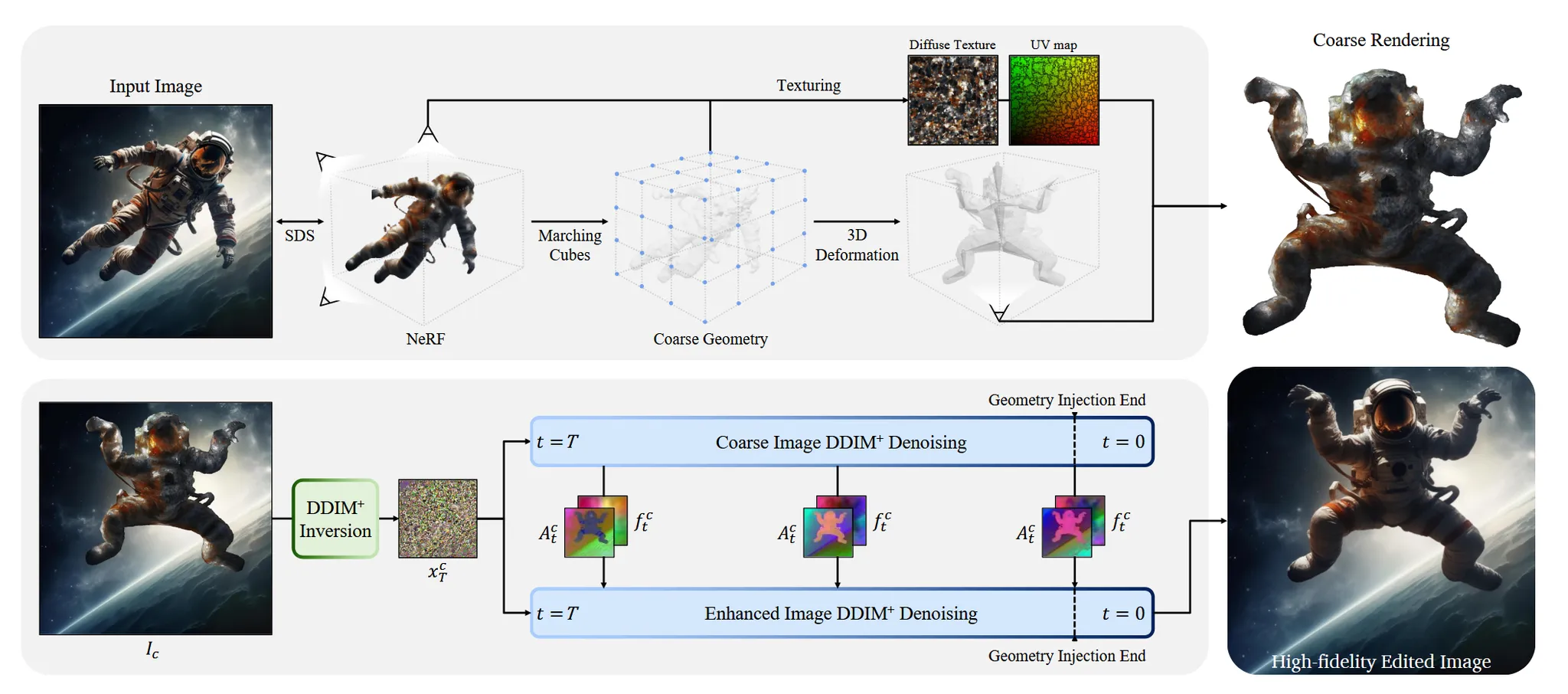
De-Rendering and Deformation
2D 이미지를 3D 모델로 재구성해서, 3D에서 사용자가 원하는 형태로 조작할 수 있는 과정을 설명하는 문단입니다.
Image to NeRF
2D 이미지에서 SAM(Segment Anything Model)을 이용해서 물체만을 분리하고, 이를 SDS(Score Distillation Sampling)와 NeRF 방식을 이용해서 3D로 변환합니다.
완벽하게 이해하고 싶다면 ‘DreamFusion: Text-to-3D using 2D Diffusion’ 논문을 참고하면 좋을 것 같습니다.
NeRF to 3D Model
NeRF를 3D Mesh로 변환하기 위해서는 SDF(Signed Distance Function)와 Marching cubes 알고리즘을 이용합니다. 이렇게 생성된 3D Mesh의 texture가 존재하지 않기 때문에 Differentiable Rendering 기법을 사용해서 UV mapping을 진행합니다.
이부분은 사실상 3D 개념이 많이 들어가는데 SDF는 물체의 안인지 밖인지 확인할 수 있는 어떠한 값입니다. 이 값을 이용하면 0이 물체의 경계 즉 표면이라는 것을 알 수 있어서 이 정보를 이용해서 Marching cubes 알고리즘을 쓰면 3D Mesh가 나오는 것입니다. 마지막으로 색칠하는 UV mapping 과정은 3D 컴퓨터 그래픽스 개념으로 그냥 어떻게 색칠할지 정보가 있는 map이 있는데 그걸 3D Mesh에 적용하겠다 정도만 이해하시면 됩니다.
3D Model Deformation
3D 모델로 변환되면 사용자가 skeleton을 추가 후 포즈를 변경할 수 있습니다. 이때 UV 좌표값은 변경하지 않고 vertex position만을 수정하도록 설정합니다.
하지만 3D가 하나의 2D image로부터 생성되다 보니 퀄리티가 좋을 수 없습니다.
Coarse-to-Fine Generative Enhancement
이전에 나온 대략적인 이미지를 고화질로 바꾸는 과정을 설명합니다. 변형된 물체의 정확한 모양은 유지하면서도 텍스처와 배경을 원래 이미지와 자연스럽게 어우러지게 만드는 방법을 다루고 있습니다.

Dreambooth는 texture는 잘 복원하지만 구조는 잘 못 지켰고, 반대로 SDEdit는 구조는 잘 반영하지만 texture는 잘 지키지 못 했습니다.(위의 결과 참조)
따라서 해당 논문에서는 DreamBooth로 1장의 이미지를 기반으로 한 번만 fine-tune하여 텍스처 정보를 학습합니다. 이후에 feature map으로는 의미적인 정보를 attention map으로 모양에 대한 정보를 학습하도록 합니다(Plug-and-Play 논문 참조). 추가적으로 ControlNet으로 depth 정보를 함께 제공해서 물체의 입체적인 구조를 보완적으로 제공합니다.
One-shot Dreambooth
원본 이미지의 texture를 복원하기 위해서 Dreambooth를 사용합니다. Dreambooth 모델은 적은 수의 정면 이미지만으로도 충분히 이미지의 특징을 학습할 수 있습니다. 따라서 한장의 입력 이미지만을 학습해서 textual gap을 줄이도록합니다.
Depth Control
3D 모델을 만든 뒤 해당 모델에서 depth map을 추출합니다. 이 depth map은 이미지를 생성할 때 geometry를 유지할 수 있도록 Controlnet을 이용해 공간적인 가이드 역할을 합니다. 하지만 호박의 눈 모양이나 의자의 구부러진 다리처럼 세부적이고 미묘한 형태는 잘 표현하지 못합니다.
Feature Injection
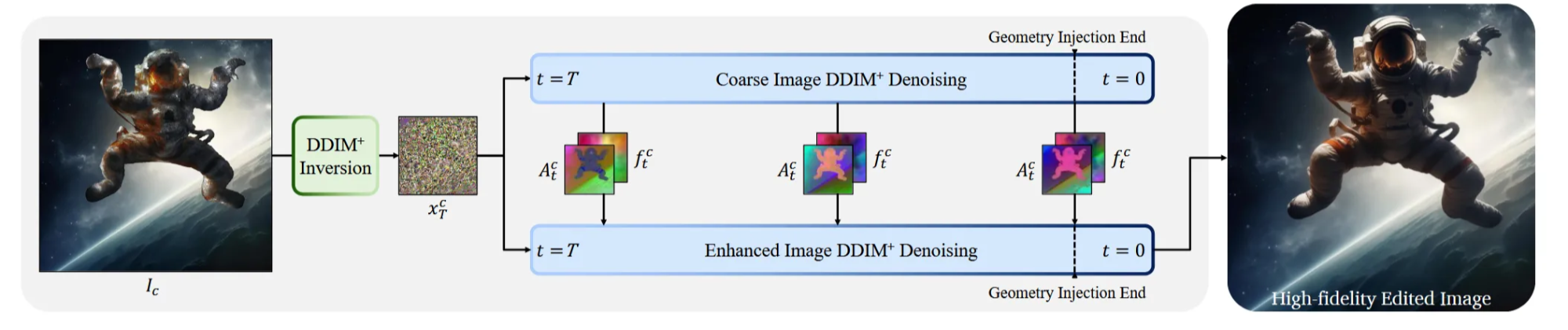
DDIM Inversion을 통해서 중간 결과인 coarse 이미지의 feature와 attention을 사용하는 방법입니다. DDIM Inversion은 다시 latent 공간으로 되돌리는 과정입니다. 이렇게 되돌린 coarse rendering latent와 우리의 target 값인 refined 이미지의 latent를 동시에 denoising하면서 Feature map(Residual block output: style 정보)와 Self-attention map(transformer block output: 물체의 구조) 2가지를 추출합니다. Target latent의 feature map과 attention map을 coarse 이미지에서 얻은 것으로 덮어씀
Background Blend-In
편집된 이미지를 원래의 배경과 자연스럽게 합성하는 과정을 설명합니다. 입력 이미지에서 객체가 차지하고 있는 영역을 비우고 가려진 배경을 inpainting 해서 채웁니다.

이후에 원래 이미지를 단순히 복사 붙여넣기 할 경우 부자연스러운 결과가 나타납니다. 윗줄이 그냥 복사 붙여넣기 한 결과이고, 아랫줄이 논문에서 제안한 방식을 사용한 결과입니다.(솔직히 물고기 빼고는 차이를 모르겠다..)
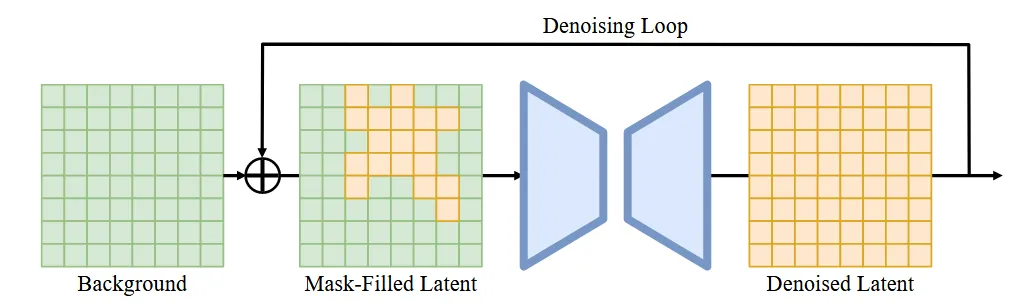
맨 왼쪽이 inpainting된 깨끗한 배경 → 중간부분에서 노란색이 새롭게 생성할 물체의 영역이고 초록색이 그대로 생성해야 될 배경 부분 → U-Net을 통해서 노란색 영역은 물체를 생성하고 초록색 부분은 마스킹해서 그대로 두면서 최종적으로 디노이징이 끝난 결과가 맨 오른쪽 노란색입니다.
Experiments




