논문을 선택하게 된 계기
ImageBind에 대한 리뷰를 하던 중 흥미를 느껴, 해당 논문의 후속으로 LLM(Latent Linear Models)을 추가한 ImageBind-LLM 논문을 찾았다. 간단히 정리해보도록 하겠다.
대략적인 개요

기존에 LLM 모델(GPT) 이미지를 넣었을 때 이에 대한 답을 해줬지만 비디오, audio등의 정보는 아직 잘 처리하지 못했다. 이에 ImageBind-LLM에서는 다양한 모달리티의 정보를 입력 데이터로 넣을 수 있도록 구조화 했다.
모달리티 종류: ImageBind에서 사용하는 6가지 정보(이미지, 오디오, 비디오, 텍스트, IMU, Thermal)에 Point Bind-3D가 추가 됐다.
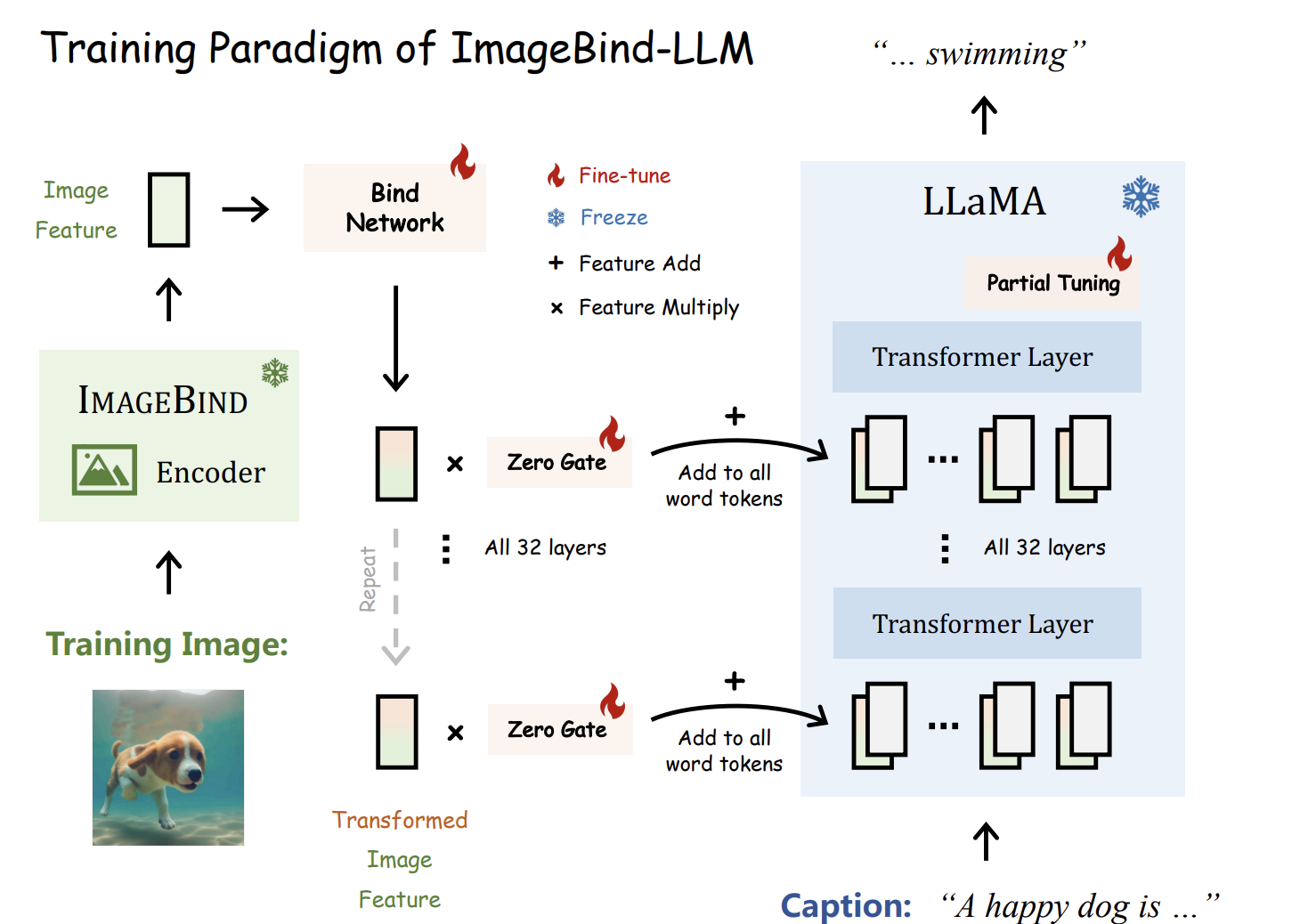
모델의 학습 방법이다. 이는 하나하나 아래서 자세히 설명하도록 하겠다.
모델 학습 방법

전체 그림에서 가장 왼쪽에 있는 부분이다. 논문에서는 Global 이미지 특징을 얻기 위해 ImageBInd의 이미지 인코더 부분을 Frozen 시킨다고 나와있다. 인코더를 거친 후 Image Feature를 추출한다.

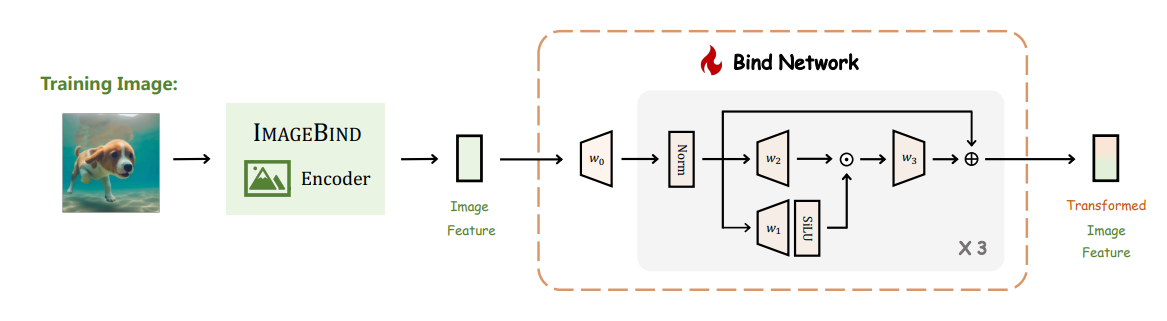
Image Feature는 Bind Network를 통과하여 ImageBind와 LLaMA의 embedding space로 합쳐진다. Bind Network는 총 3번 학습되며, 이 과정에서는 linear projection layer weight matrix인 w0를 거친 후 RNS Norm을 적용하고 SiLU Activation Function을 사용한다. 중간에 있는 화살표는 residual connection을 나타낸다.
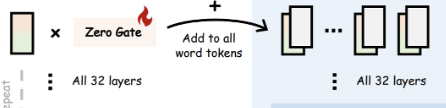
Bind Network를 통해 얻은 값은 Zero gate를 이용하여 LLaMA transformer layer에 word token으로 적용된다. Zero gate는 초기에 0으로 설정되어 있어 초기에는 이미지 특징이 전달되지 않는다. 그러나 학습 중에 이 가중치는 점진적으로 증가하며, 이는 LLaMA에 더 많은 시각적 의미를 주입하여 초기 학습 단계에서 안정적인 학습을 돕는다.
다양한 모달리티 적용 방법
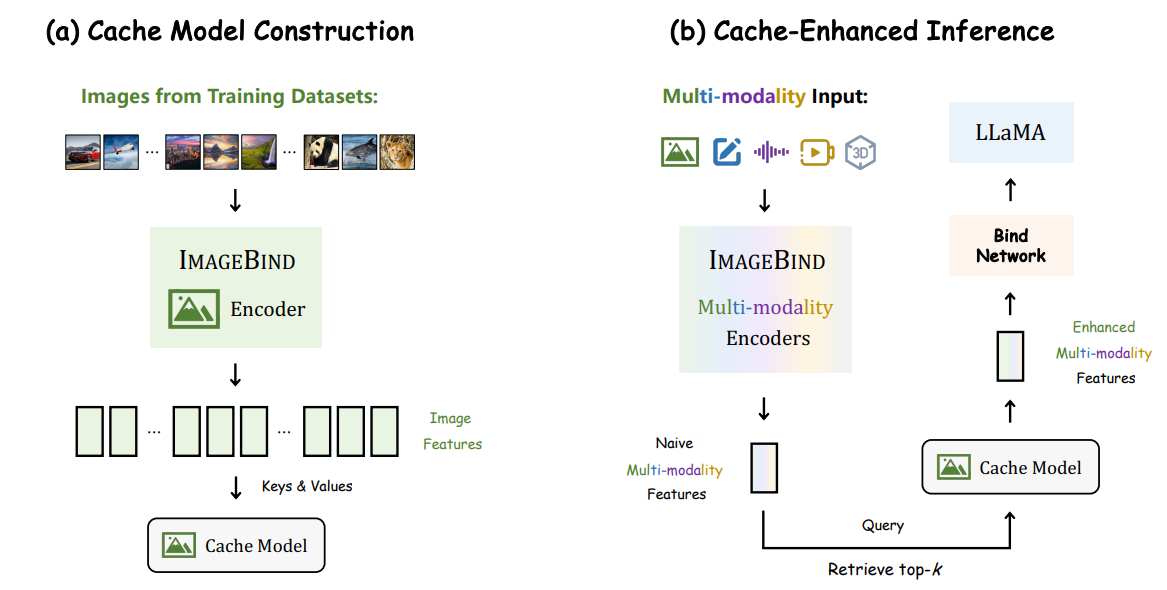
Bind Network이전에 있는 IMAGEBIND의 이미지 인코더 대신 다른 모달리티의 인코더를 넣으면 그 데이터를 사용할 수 있게된다.
Cache Model: ImageBind에서 추출한 이미지 특성을 저장하고 검색하는 데 사용. 캐시 모델은 훈련 중에 이미지 특성과 해당 이미지의 레이블을 저장하여 키-값 데이터베이스 형태로 구성된다. 추론 중에는 테스트 샘플이 쿼리로 작용하여 키와의 유사도를 통해 정보가 검색된다. 이를 통해 캐시 모델은 이미지 특성을 검색하고 해당 정보를 활용하여 다양한 모달리티 입력에 대한 임베딩을 개선한다
Cache-enhanced Inference(Query / Retrieve top-K)
이미지와 다른 모달리티의 차이를 줄이기 위한 방법(train과 inference의 차이 줄이기)
training-free cache model
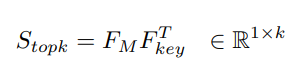
Fkey: 검색된 상위 k개의 유사한 시각적 키
FM: 입력 다중 모달리티 지시사항을 ImageBind로부터 얻은 쿼리 특성
이를 코사인 유사도와 L2-norm를 이용해서 계산
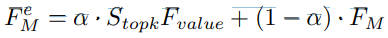
Fvalue: Stopk에 따라 형성된 캐시
FM에 Fvalue를 residual connection을 이용해 연결
a: 균형인자(balance factor)
다른 모달리티의 표현 품질을 향상시키고, 이들의 시맨틱 갭을 훈련에 사용된 이미지와 완화시킨다.
결과
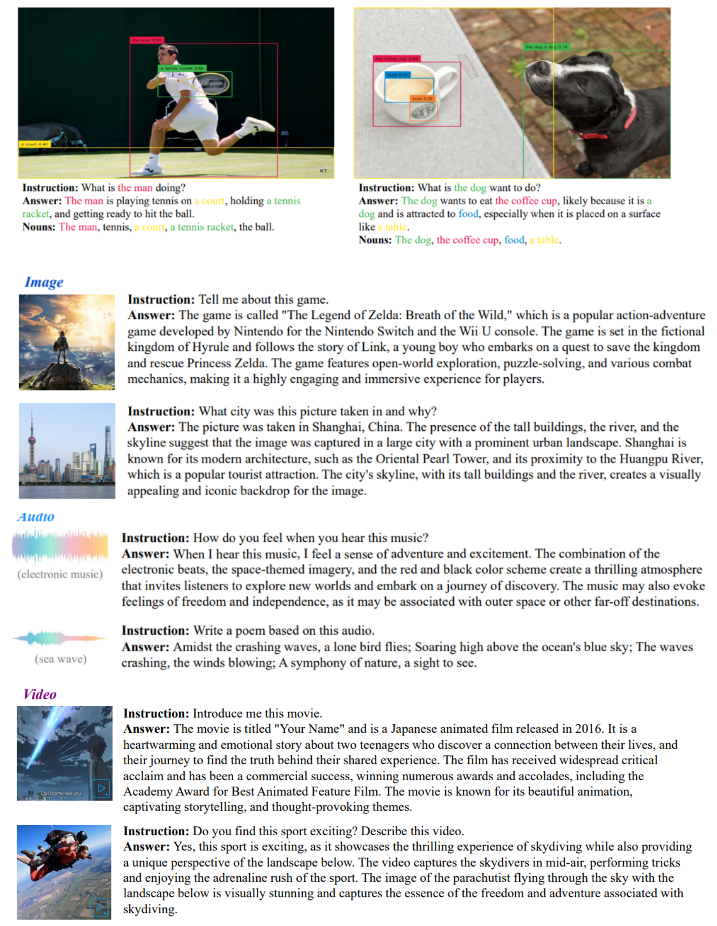

마무리
아직 LLM 부분에 대한 개념이 부족하여 ImageBind와 LLM을 함께 사용하는 부분에 대한 설명이 조금 부족했다. 나중에 추가적으로 공부하여 설명을 보완해야겠다는 생각이 들었다. ImageBind가 출시된 지 얼마 되지 않아 LLM이 추가된 논문과 함께 3D 모달리티도 출간되었다는 사실이 흥미로웠다.
