논문을 선택하게 된 계기
최근 CLIP에 관해서 관심이 생겼고 그중에서도 contrastive learning부분을 바꿔보고싶었다. 기존 CLIP는 이미지-텍스트 쌍을 사용하여 학습했지만, 저는 3가지 모달리티를 활용하여 contrastive learning을 수행할 수 있는지 궁금했다. 그래서 이와 관련된 논문을 찾아보게 되었다.
모델 설명
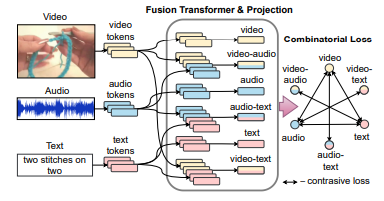
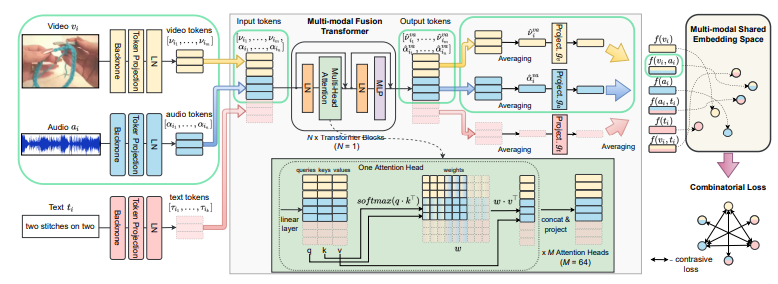
먼저 모델의 전반적인 흐름을 설명하자면, 모델은 3가지 모달리티에 대해 각각 토큰을 생성한다. 이러한 토큰들은 추가적인 학습 없이 그대로 사용된다. 그 후, 2개의 모달리티씩 묶여진(video-audio, video-text, audio-text) 토큰 3개를 추가로 학습을 통해 생성한다. 이렇게 총 6가지 종류의 토큰을 이용하여 contrastive learning을 수행한다.
token 생성
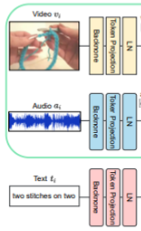
위의 사진은 각각의 모달리티 입력값에 대해서 token을 얻는 과정을 나타낸 것이다.
논문에서는 specific backbones → learnable modality-specific projections → Layer Normalization 이 순으로 통과한 후 token을 얻는다고 나와있다. 백본은 CNN 혹은 vit를 사용했겠지만 projection 과정이 설명되지 않았다. 이 점이 궁금했는데 추후에 찾으면 정리해두겠다. 이렇게 생성된 3개의 token은 나중에 contrastive learning에 그대로 사용되고, 아래에 추가적으로 설명한 과정들은 3개의 mix token을 만드는 과정이다.
3개의 추가 token 생성 과정
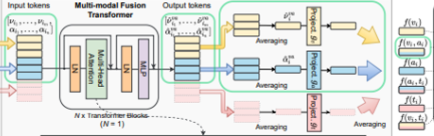
위의 방법처럼 생성된 3개의 토큰을 Multi-modal Fusion Transformer를 통과해서 다시 토큰으로 생성한다. 여기서 말하는 토큰들은 쿼리, 키 ,벨류 값들로 이루어져있다.
Multi-modal Fusion Transformer는 LN→multihead self-attention→LN→MLP 형식으로 나타나있다.
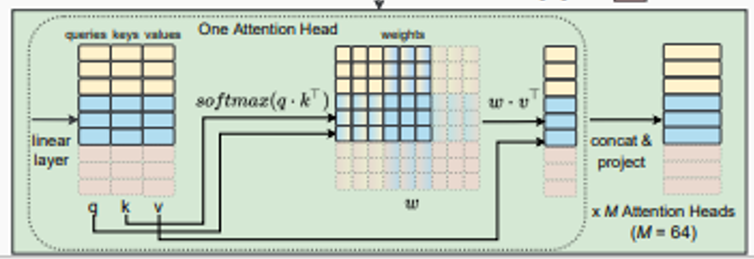
이사진이 하나의 Multihead self-attention그림이다.
다른 트랜스포머 기반 방법과 달리, 토큰에 위치 또는 타입 임베딩 정보를 추가하지 않는다.
타입 임베딩X→이미 다른 유형의 입력이므로 자체적인 지문(fingerprints)를 갖고 있다고 가정
위치 임베딩X→randomly sampled되기때문에 순서가 중요하지 않다. 추가적으로 클립이 항상 행동의 시작에서 시작되지 않을 수 있다는 점을 고려
Contrastive learning
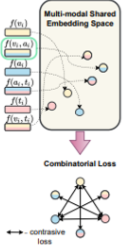
3가지 token과 추가로 생성한 3개를 더해 총 6개의 token을 이용해서 contrastive learning을 구한다.
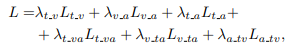
위의 식이 총 Loss값을 구하는 과정이다. L과 람다 뒤에 적혀있는 값이 어떤 token을 이용할지를 나타내고, L은 Loss, 람다는 weight값을 나타낸다.
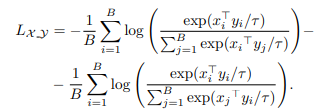
loss는 NCE loss를 이용해서 계산한다.(B:사이즈, r:temperature)
위 논문을 읽고 CLIP에 적용?
이 논문을 읽은 목적이 CLIP의 contrastive learning을 바꾸기 위해서였는데 사실 나에게 가장 필요한 projection과정이 자세히 나타나지 않아서 아쉬웠다. 추가적으로 나는 3차원 contrastive learning 즉 6개의 과정을 한번에 진행하고 싶어 나중에 내가 코드를 구현한다면 이 논문과 비교하면 좋을거같다.
