Michelangelo: Conditional 3D Shape Generation based on Shape-Image-Text Aligned Latent Representation[2023 NEURIPS]

이미지나 텍스트로부터 3D를 생성할 때 3D를 바로 생성하지 않고 3D, 이미지, 텍스트 간의 차이를 줄이기 위해서 3가지 데이터를 하나의 공유된 shared latent space로 alignment시킵니다.
Related Work
Contrastive learning in 3D
CLIP 모델을 3D까지 확장해서 다양한 모달리티에 대해서 align을 진행한 여러가지 기존 방식들이 존재했으나, 해당 방식들은 전부 classification 또는 retrieval과 같은 3D recognition task에서의 적용이었습니다. 해당 논문에서는 이러한 align된 정보를 이용해서 3D를 생성하는 방식에 대해서 처음으로 제안합니다.
Our Approach
Shape-Image-Text Aligned Variational Auto-Encoder(SITA-VAE)
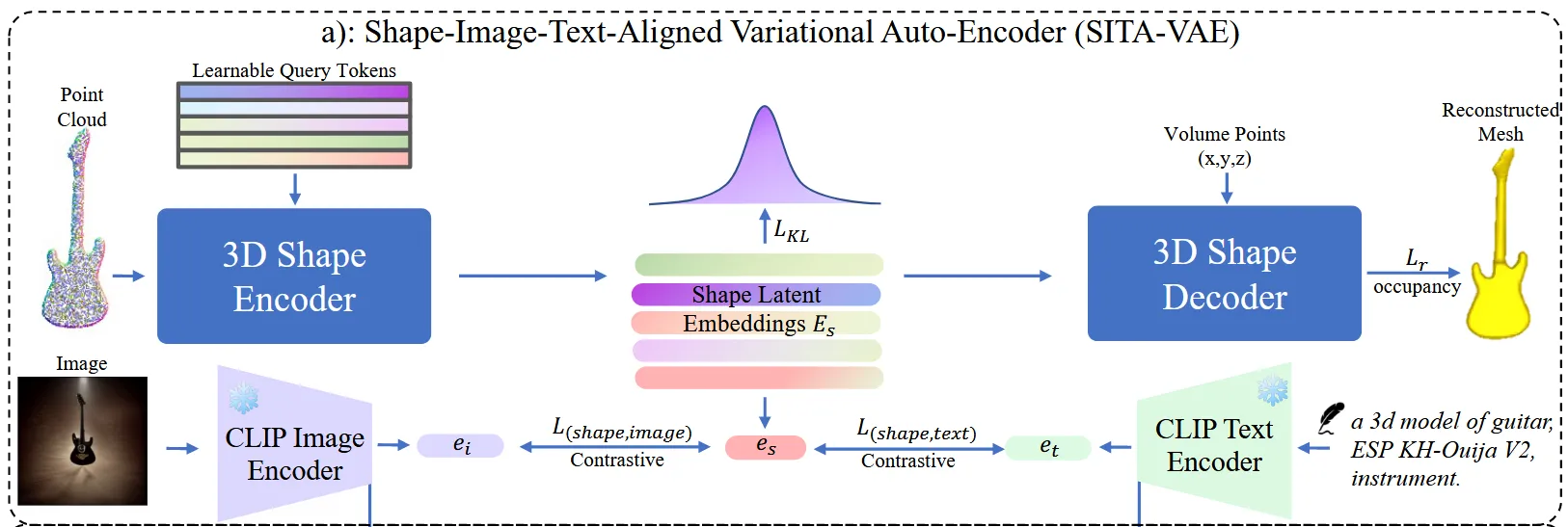
SITA-VAE는 사전학습되고 고정되어있는 CLIP image encoder, CLIP text encoder와 학습하는 3D shape encoder, neural field decoder 이렇게 4개로 구성되어 있습니다.
3D Shape encoder
첫번째로, 3D shape에 대해서 point cloud()를 추출합니다. 여기서 N은 point의 개수이고 C는 color나 normal과 같은 point에 대한 추가적인 정보를 나타내는 채널입니다.
다음으로 point cloud에 Fourier positional encoding을 적용해서 X()를 생성합니다.
X는 learnable query tokens Q()을 학습할 땟 ㅏ용합니다. 이때 의 차원은 1차원의 global head token 와 L차원의 low-level geometric structure 정보로 구성되어 있습니다. 이후 self-attention을 진행해서 최종 shape embedding 를 얻습니다.
Alignment among 3D shapes, images, and texts
텍스트나 이미지에 비해 3D 데이터가 부족하기 때문에 사전학습된 vision-language space에 3D 임베딩을 가깝게 하는 것을 목표로 합니다.
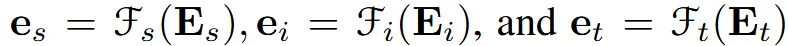
3가지 임베딩을 동일한 space에 보내기 위해서 embedding projector가 필요합니다. 이때 이미지와 텍스트의 projector는 학습하지 않고, 3D의 projector만 학습하도록 합ㄴ디ㅏ.
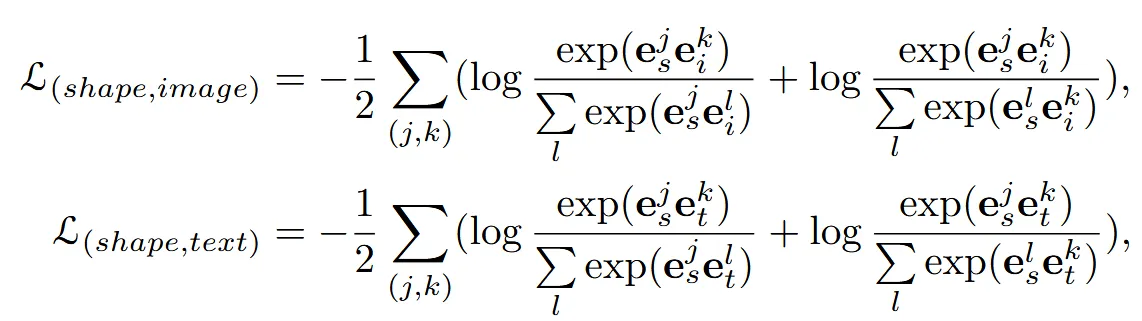
이전에 말한 것처럼 이미지와 텍스트는 고정시키고, 3D 정보만을 2개의 space와 비슷한 공간으로 보내기 위해서 위와 같은 contrastive loss를 계산합니다.
3D Shape Decoder
Shape embeddings 값을 이용해서 3D neural field를 얻기 위해서 Decoder를 학습합니다. KL divergence loss를 이용해서 latent 공간을 연속적이고 의미 있는 분포로 만듭니다.
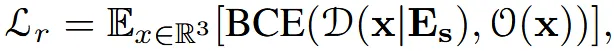
Shape embedding 와 3D point cloud x(x,y,z 3차원) 2개에 대해서 cross-attention을 진행해서 occupancy를 예측합니다. Occupancy는 해당 좌표에 물체가 존재하는지 안하는지에 대해서 존재하면 1 존재하지 않으면 0을 나타냅니다. BCE(binary cross-entropy) loss를 통해서 occupancy 확률값을 학습합니다.
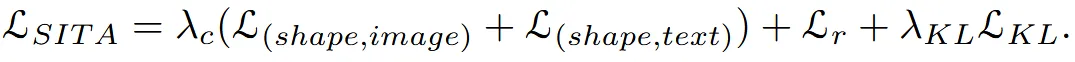
SITA의 최종적인 확률 값은 위와 같이 align loss + KL divergence loss + occupancy loss로 구성되었습니다.
Aligned Shape Latent Diffusion Model (ASLDM)
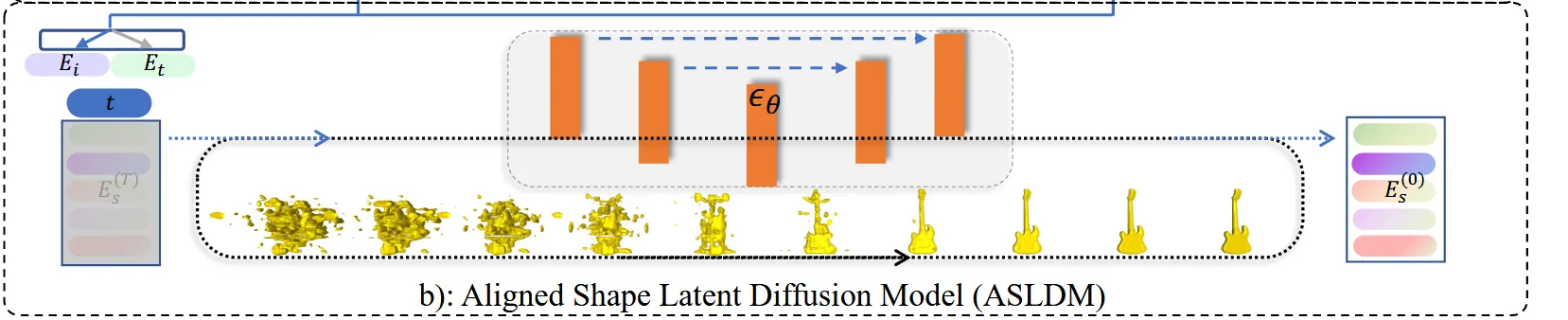
이제 텍스트나 이미지를 주면 그에 맞는 3D latent를 sampling해서 생성하는 모델이 필요합니다. 해당 모델을 Latent diffusion Model(LDM)을 사용했고, 해당 모델의 이름을 Aligned Shape Latent Diffusion Model(ASLDM)으로 정의했습니다.
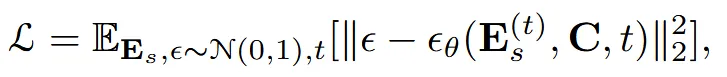
Model은 condition(텍스트 or 이미지)가 주어졌을 때 이에 맞는 shape latent embedding을 생성하는 것을 목표로 합니다. 는 에서 노이즈를 추가한 것입니다. Inference시에는 단순히 gaussian noise에서 시작해서 점진적으로 를 예측합니다.
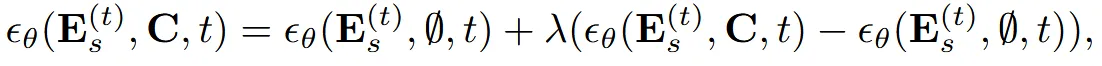
Condition을 반영하기 위해서 classifier-free guidance(CFG)를 적용했습니다. 학습 도중에 10%의 condition C가 None으로 들어가서 모델을 일반화 시켰습니다.
Experiments
Implementations
SITA-VAE 구조: Cross-attention 1 block + Self-attetnion 8 blocks
Neural Field Decoder: Self-attention 16 blocks + Cross-attention 1 block
ASLDM 구조: UNet과 유사한 transformer diffusion model
- self-attention 13 blocks + skip connection
Attention: 12 heads x 64차원
FFN: 3072차원
Activation: GELU
CLIP: CLIP ViT-L/14사용
Datasets and Evaluation Metrics
Datasets
ShapeNet: 55개 category 5만개 3d mesh
- 세부 설명 텍스트 및 카테고리 존재
- train/val/test 기존 3DILG 논문과 동일하게 사용
Cartoon Monster Dataset: 811개의 캐릭터성 3d mesh
- train:615, val:71, test:125
(3D shpae, image, text) 데이터 준비
- Text: a 3D model of (shape tag), in the style of (description) 등 65개 문장 템플릿(ULIP 참조)
- Image: 4개 카메라 렌더링 → ControlNet(Depth)
Metrics
IoU(Intersection over Union): 생성된 3D 형태가 정답 3D와 얼마나 겹치는지
P-IS(Point-cloud Inception Score): PointNet++기반 3D point cloud 의미 다양성
P-FID(Point-cloud Frechet Inception Distance): PointNet++로 추출한 임베딩 기반 3D 샘플 분포와 생성된 샘플 분포간거리
멀티모달 평가 지표
SI-S(Shape-Image Score): Image와 Shape 임베딩간 cosine similarity
ST-S(Shape-Text Score): Text와 Shape 임베딩간 cosine similarity
Experimental Comparision
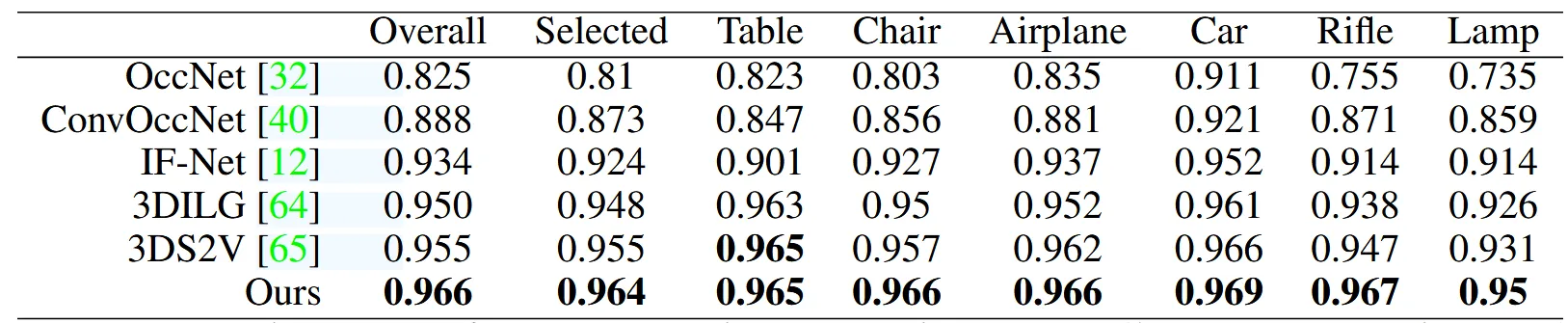
OCC, ConvOcc, IF-Net, 3DLIG, 3DS2V 모델과 ShapeNEt dataset의 reconstruction IoU 결과 비교

2가지 모델과 임베딩 값간의 비교를 하는 여러 지표를 통해서 정당성을 입증했습니다. =

2가지 모델과 image condition quality 비교
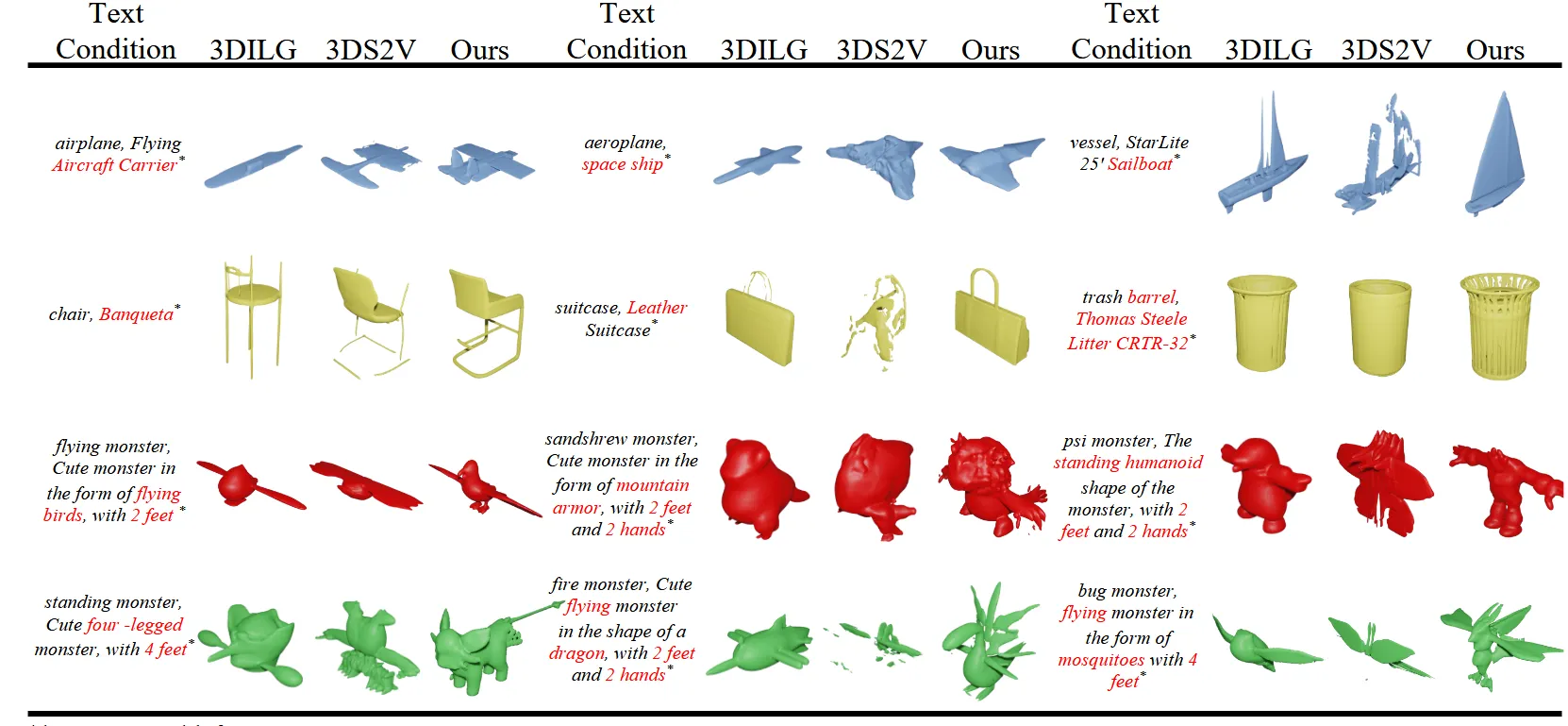
2가지 모델과 text condition quality 비교

시각적인 모델의 비교를 통해서 3DILG는 전체적인 형태를 잡지만 디테일이 부족하고, 3DS2V는 디테일은 좋지만 전체적인 형태에서 깨지거나 노이즈가 많은것에 비해 Ours는 모든것이 완벽한 것을 알 수 있습니다.

Text 기반 비교에서도 여전히 Ours가 디테일부터 전체적인 부분의 성능이 더 좋은 것을 확인할 수 있습니다.
Ablation Studies and Analysis
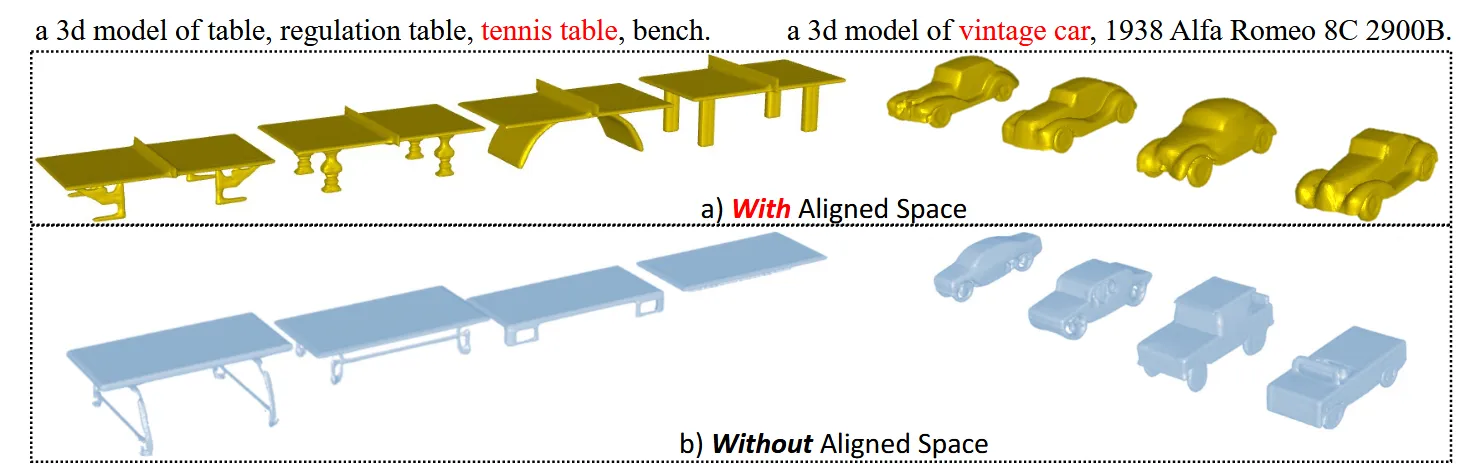
Embedding space를 align시킨 유무에 따라 확실히 디테일한 결과의 차이가 나타나는 것을 알 수 있습니다.

SITA-VAE를 학습시킬 때 CLIP모델이 아닌 SLIP VLM 모델을 이용할 경우의 성능 비교입니다. CLIP모델의 성능이 모든 부분에서 더 좋기 때문에 CLIP 모델을 이용해서 3가지 임베딩을 align시켰습니다.
