BridgeShape: Latent Diffusion Schro ̈dinger Bridge for 3D Shape Completion[2025 arXiv]
3D shape completion 방법은 일반적으로 diffusion 모델을 사용할 때 concat하거나 cross-attention을 사용해서 복원했습니다. 이때 어떻게 불완전한 것에서 완전한 것으로의 변환을 나타내는지에 대한 transport path를 모델링 하지 않았기 때문에 부적절한 결과를 만들었습니다.
해당 논문에서는 불완전한 모양에서 완전한 모양으로 변형되는 optimal transport를 schrodinger bridge 이론을 통해서 모델링했습니다.또한 VQ-VAE의 다양한 시점에서의 depth map을 넣고 DINOv2 를 함께 활용하는 방안을 제시했습니다. 어떻게 이를 진행했는지 아래에서 구체적으로 설명하도록 하겠습니다.
Related Work
3D Shape Completion
3D Shape Completion은 불안전한 shape으로부터 완전한 shape을 생성하는 과정입니다. 기존 방식들은 CNN 혹은 transformer를 기반으로부터 완전한 shape을 예측해왔습니다. 이후 GAN이나 autoencoder와 같은 생성 모델을 이용해서 확률론적 shape 생성 과정으로도 발전 됐습니다.
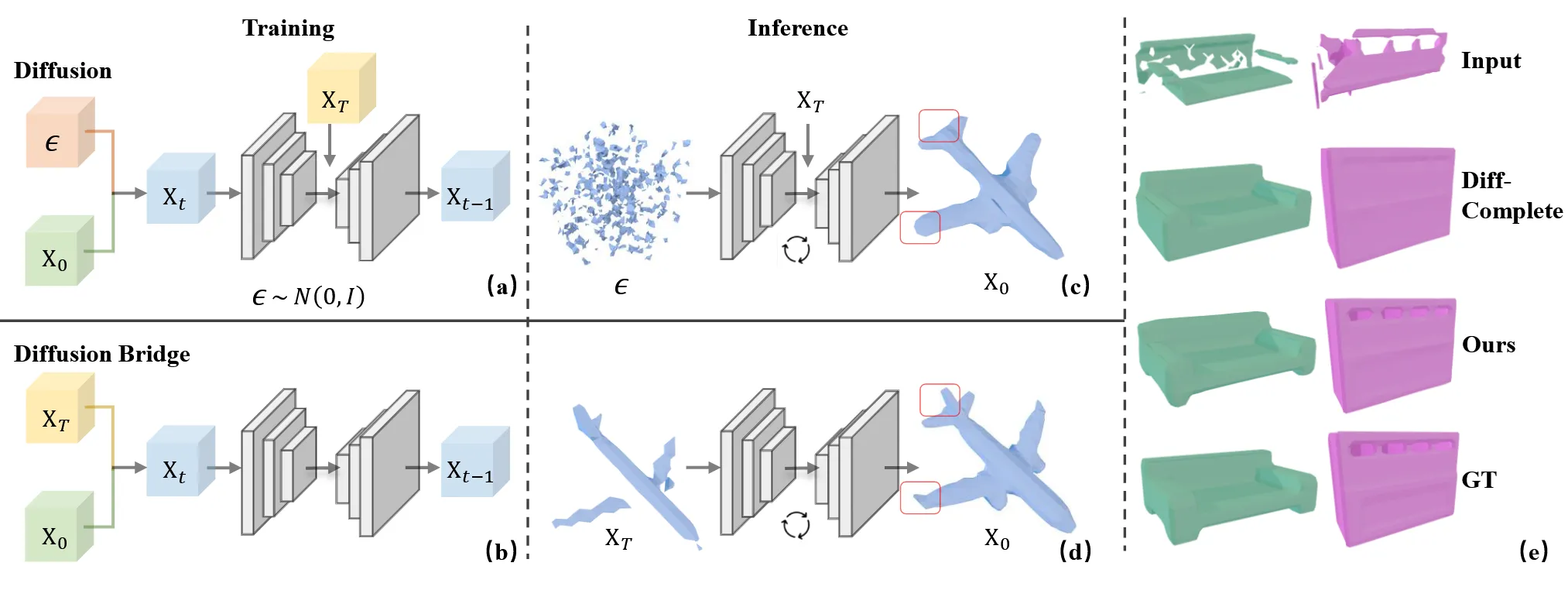
BridgeShape에서는 이전 모델들과 다르게 불완전한 형태에서 완전한 형태로 가는 변화 과정 자체를 명시적으로 모델링했다는 차이점이 존재합니다.
Diffusion models for 3D generation
최근 논문들은 point cloud를 latent space로 보낸 후 diffusion을 이용해서 생성을 진행했습니다. 하지만 이러한 모델들은 모두 최적 경로를 직접 모델링하지는 못했습니다. 단순히 조건을 줘서 결과만 나오게 할 뿐 그 과정이 어떻게 변화해야 하는지는 이해하지 못합니다.
BridgeShape는 불완전한 형태에서 완전한 형태로 어떻게 변화해야 되는지를 모델링하고 optimal transport를 제시합니다.
Diffusion Bridge Models
Diffusion bridge model은 A라는 확률 분포에서 B로 끝나는 경로를 만들려면 어떻게 확률적으로 이동해야 되는지를 다루는 모델입니다. 즉 출발점과 도착점이 정해져 있을 때 그 사이의 optimal transport를 찾는 모델입니다. 이미지 → 이미지, 혹은 음성 → 이미지 등 다양한 분야에서 적용되고 있지만 3D에는 적용되지 않았기 때문에 처음으로 BridgeShape에서 적용했습니다.
Method
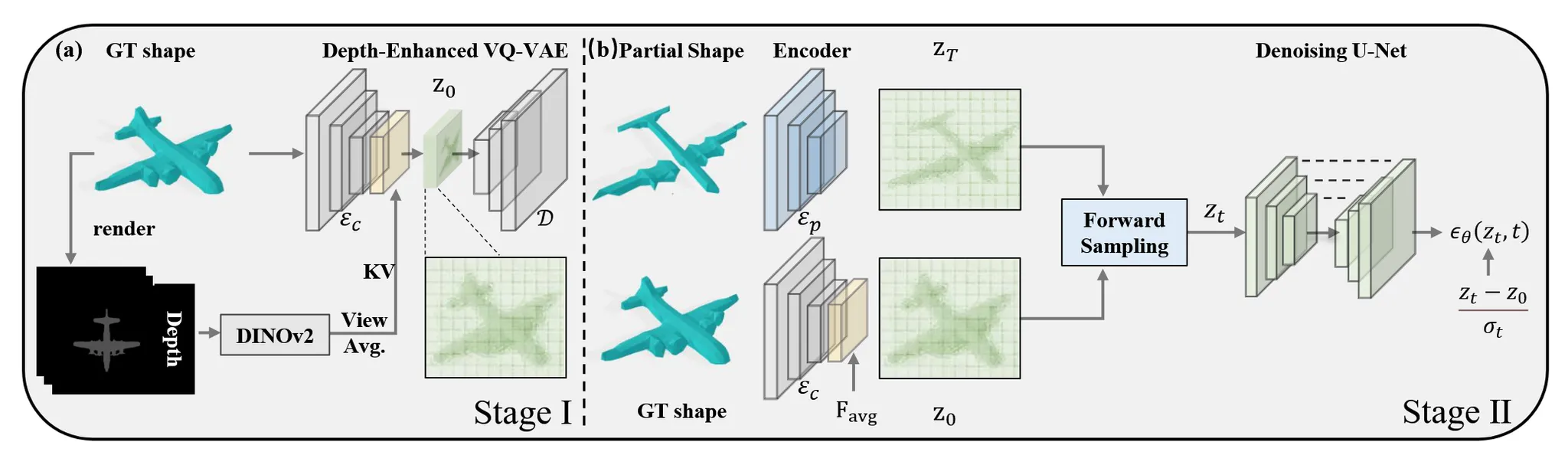
입력으로는 불완전한 3D shape을 TSDF(Truncated Signed Distance Field)로 표현하고, 정답인 완전한 3D shape은 TUDF(Truncated Unsigned Distance Field)로 표현합니다.
TSDF는 각 voxel이 표면에서 얼마나 떨어져 있는지를 나타내며, 표면 안/밖 여부를 부호로 구분합니다. TUDF는 그 부호 없이 거리만 나타낸 값입니다.
Stage 1에서는 VQ-VAE를 통해 TUDF 값을 low-dimensional latent 벡터로 압축합니다. 이 latent 표현은 multi-view depth 정보로 구조 인식이 강화되어 있습니다.
Stage 2에서는 이 latent 공간 위에서 Diffusion Schrödinger Bridge를 적용해, TSDF 형태의 불완전한 입력이 어떤 경로를 따라 완전한 형태로 복원되는지를 확률적으로 학습합니다.
3D Shape Compression
VQ-VAE는 3D shape을 latent space로 변환하는 encoder와 이를 다시 shape로 변환해주는 decoder가 존재합니다.
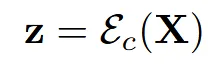
입력 X()가 TUDF값을 나타낸다고 할 때, encoder를 통과한 z는 차원을 나타냅니다.
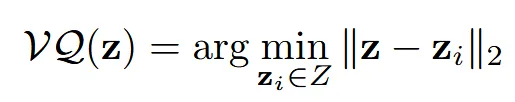
Latent vector z는 codebook Z안에서 가장 가까운 벡터 를 찾습니다.
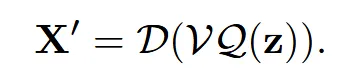
마지막으로 quantized된 latent로부터 Decoder를 통과시켜 3D shape로 복원합니다.
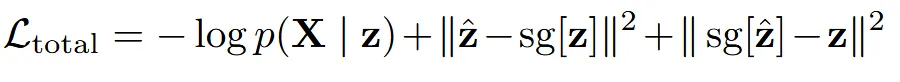
VQ-VAE의 total loss는 위와 같습니다. Reconstruction, commitment, vq loss 3가지로 구성 됐습니다.
Enhancement with Multi-View Depth Features
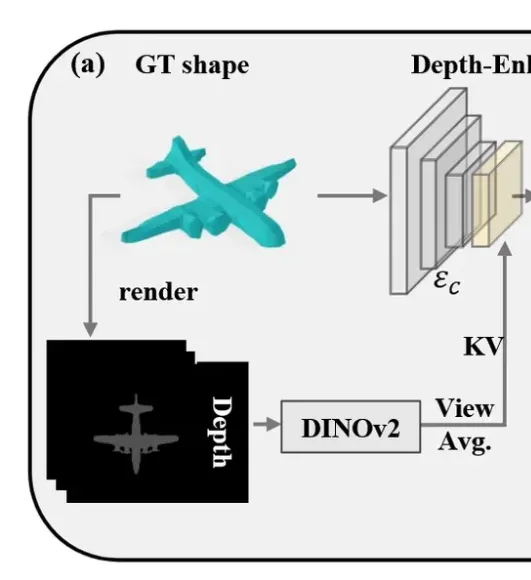
기존 VQ-VAE 구조만으로는 복잡한 구조나 세부 형상 표현에 한계가 있을 수 있습니다. 이를 보완하기 위해, 여러 시점에서 생성한 depth map에 대해 DINOv2를 이용해 feature를 추출하고, 이 feature들의 평균을 내어 얻은 통합 feature를 Encoder의 마지막 단계에서 key/value로 사용합니다. 한편, 3D latent feature는 query로 사용되어 cross-attention을 수행함으로써, depth 기반의 시각 정보를 latent 표현에 강화하는 과정을 거칩니다.
Latent Diffusion Schr ̈odinger Bridge
이전에 학습한 VQ-VAE는 freeze시키고, 이를 통해서 불완전한 shape으로부터 인코딩한 latent를 얻고, 이 latent를 완전한 shape의 latent로의 변환 과정을 학습해야 됩니다. 기존 논문들은 랜덤 노이즈로부터 정답을 얻었지만 해당 논문에서는 불완전한 입력에서 시작해서 완전한 정답으로 가는 경로를 모델링
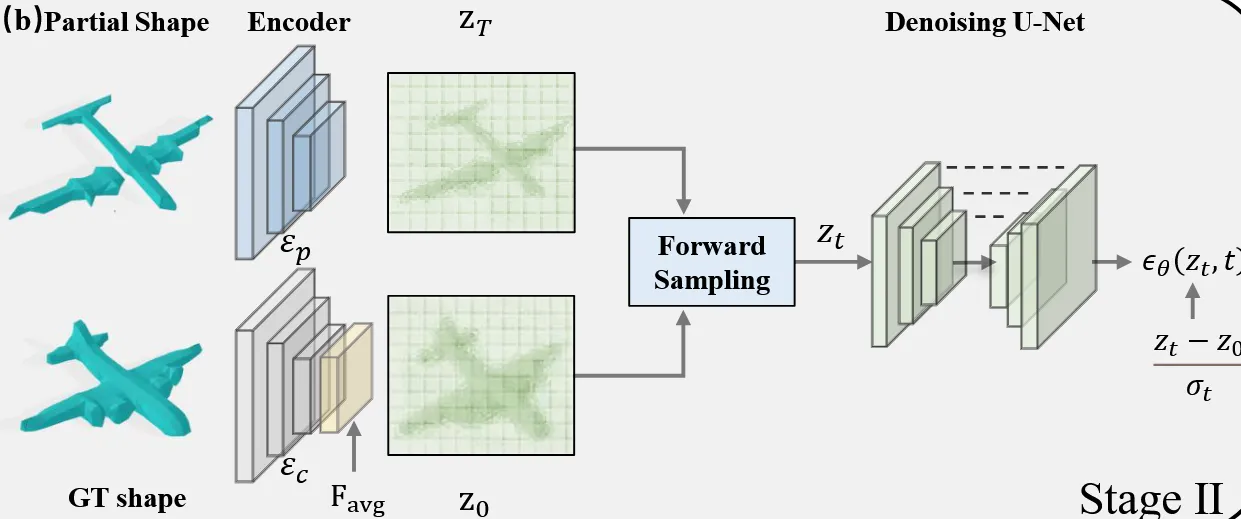
위의 그림처럼 VQ-VAE는 freeze시켰지만 새로운 encoder 는 학습을 시켜서 동일한 latent space로 보내도록 합니다.
Optimal Transport via Diffusion Schro ̈dinger Bridge
우리가 목표로 하는 것은 불완전한 latent에서 완전한 latent로 가는 확률적 경로(trajectory)를 찾는 것입니다. 이를 위해 Kullback-Leibler(KL) divergence를 최소화하는 Diffusion Schrödinger Bridge를 사용합니다.
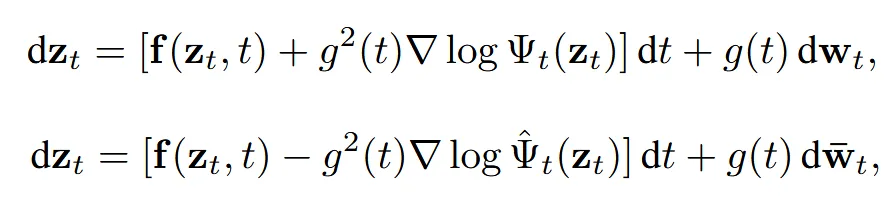
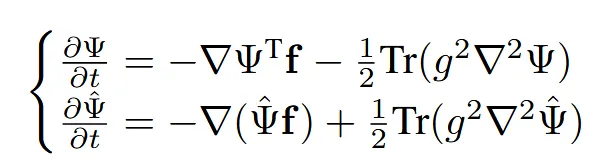
이 과정은 확률적 미분 방정식(SDE)으로 정의되며, forward/backward 방향 모두 추가 drift (∇logΨ)이 포함된 형태입니다. 하지만 이 SDE를 직접 푸는 것은 계산 비용이 크므로, 최근에는 paired data를 이용해 근사하는 방식이 사용됩니다.
구체적으로, 완전한 shape의 latent를 , 불완전한 shape의 latent를 라고 할 때,둘 사이의 중간 시점 는 정규분포 로 모델링됩니다.
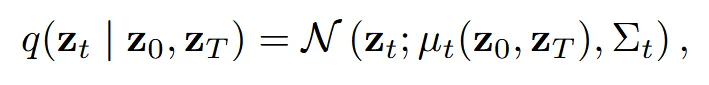
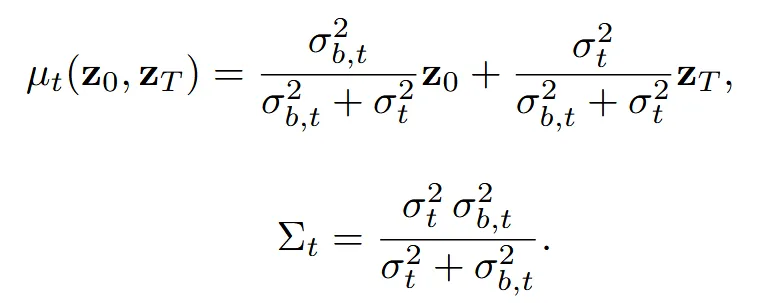
이 수식은 시간 t에 따른 과 사이의 확률적 보간을 의미합니다. 그리고 입력된 불완전한 shape가 너무 sparse한 경우, latent에 노이즈를 추가하여 불확실성을 보강합니다.
Noise Prediction and Inference
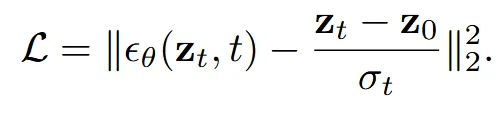
Diffusion 모델은 timetstep t에서 latent를 보고 해당하는 노이즈를 예측합니다. 이때 노이즈의 ground truth는 원래의 latent 과 t에서의 latent 의 차이 즉 실제 주입된 노이즈의 값입니다. 해당 과정은 정답 노이즈와 예측한 노이즈 간의 차이를 줄이는 것이 학습 목표입니다.
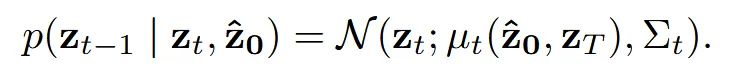
Inference시에는 불완전한 shape의 latent 에서 시작해서 거꾸로 을 복원하는 과정을 진행합니다. 해당 과정은 Schrödinger Bridge가 생성하는 경로 분포와 동일한 분포를 갖는다고 말하면서 해당 경로가 optimal transport라고 설명했습니다.
Experiments
Settings
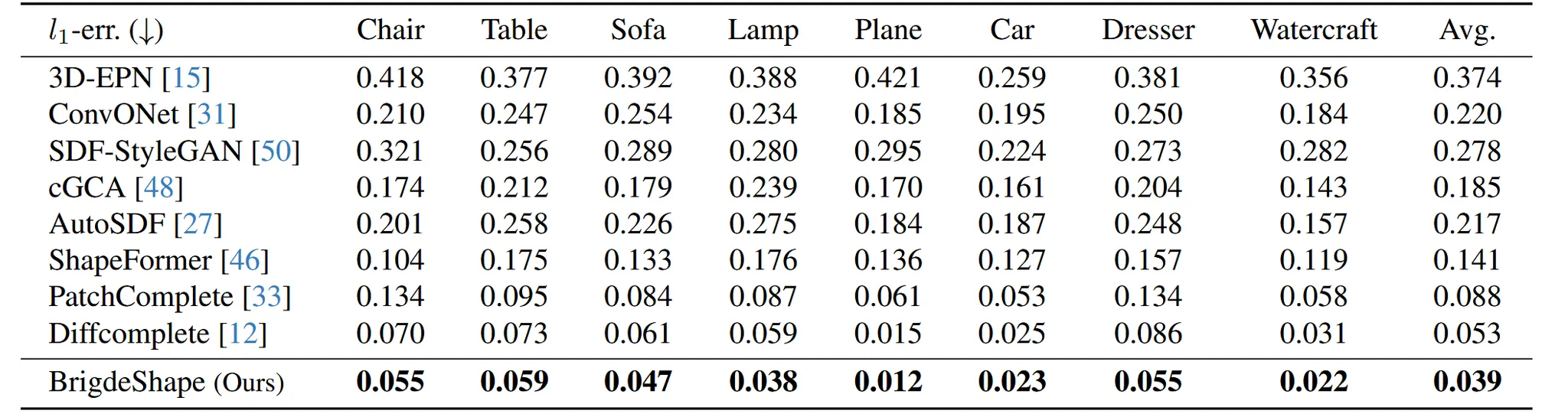
3D-EPN dataset
ShapeNet에서 가져온 8개의 카테고리(train:15,590, test: 5,384) 각 객체당 6개의 partial scan이 존재해서 총 153,540개의 training sample 생성
PatchComplete dataset
- ShapeNet 기반 synthetic data
- train: 18개 카테고리, 3,202개 모델
- test: 8개 카테고리, 1,325개 모델
- ScanNet 기반 실제 스캔 데이터
- bounding box에서 추출된 실제 스캔 객체
- 완벽한 shape는 Scan2CAD를 통해 정렬된 CAD 모델로 대체