VQA vs KB VQA

VQA는 주어진 이미지에서 답을 찾는다
KB VQA는 이미지 외부의 추가적인 지식을 사용하여 질문에 답하는 것
KB VQA 문제
- 필요한 지식이 KB(Wikipedia)에서 성공적으로 검색되지 않을 수 있다
- 필요한 지식이 검색되더라도 관련 없는 많은 지식이 필연적으로 도입
GPT-3
GPT-3의 사용
- 명시적 KB를 사용하는 연구 외에도 LLM을 이용해서 필요한 지식을 검색
- 입력값으로는 이미지를 Caption으로 변환한 값 + Question
GPT-3의 한계
- 생성된 캡션은 이미지에 필요한 모든 정보를 포함할 수 없다
- few-shot learning 시킬 때 제공되는 예제들이 중요한 영향을 미친다. 하지만 어떤 예제들이 들어가든 ‘오라클 전략(정답의 유사성)’보다는 성능이 낮다
Answer Heuristics
GPT-3의 한계 극복 방법: Answer Heuristics
- Answer Heuristics: 문제 해결을 돕기 위한 경험적인 방법이나 전략
- Answer candidates: 특정 질문에 대해 가능성이 높은 여러 답변
- Answer-aware examples: 유사한 질문과 답변을 포함하는 예제
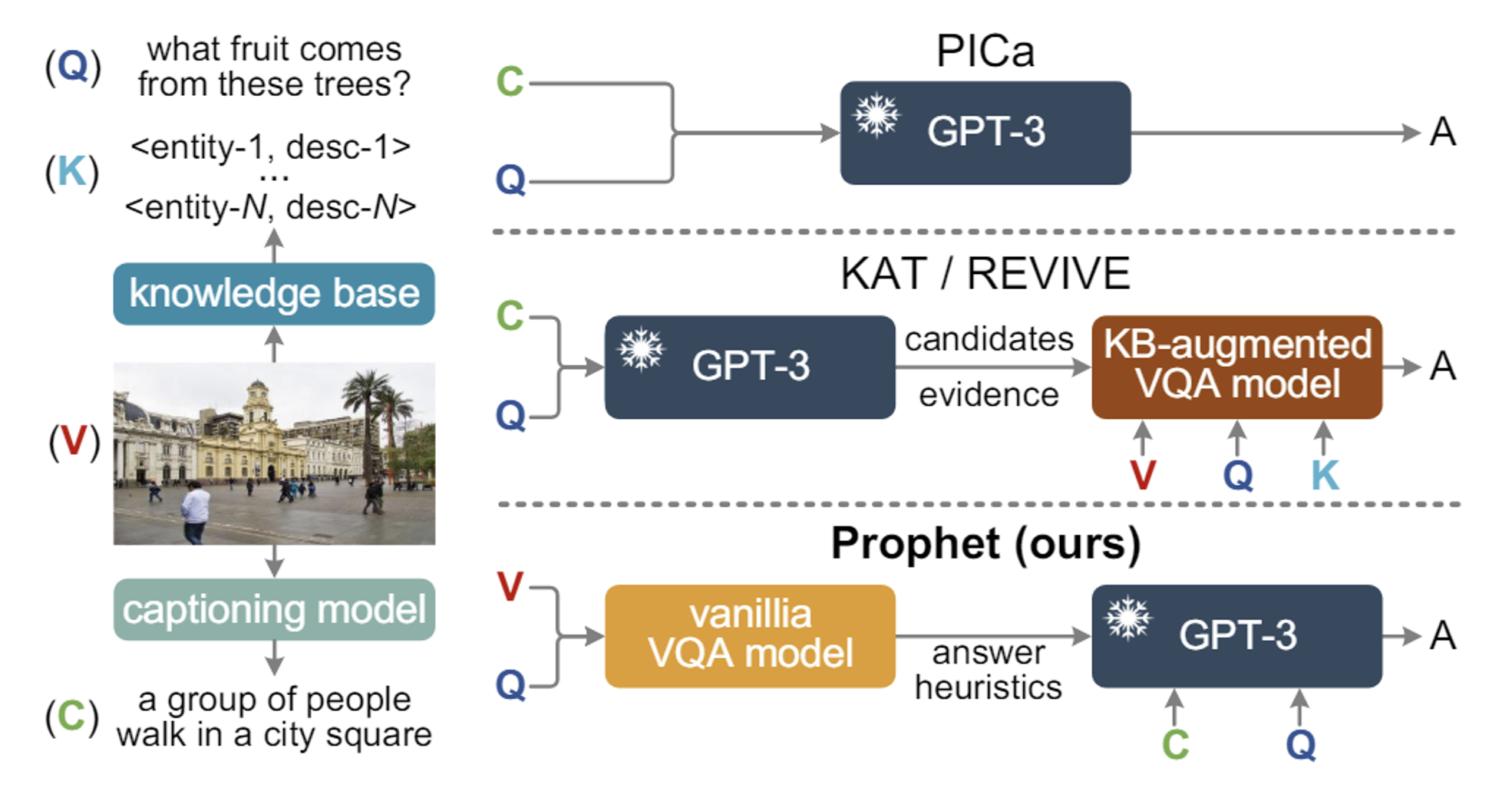
기존 방식: 캡션과 질문을 GPT-3에 직접 프롬프트로 제공 → 정보 불충분
새로운 방식: GPT-3에 Answer Heuristics 정보를 추가적으로 제공
Prophet
Preliminaries
- 이전까지의 출력과 프롬프트를 바탕으로 다음 토큰을 예측
Autoregressive Langauge Model: GPT-3는 시퀀스를 순차적으로 예측하는 언어 모델. 즉, 이전 단어들을 바탕으로 다음 단어를 예측
Testing Input (x): 모델에 제공되는 테스트 입력
Target (y): 모델이 예측해야 하는 목표
Prompt Head (h): 작업을 설명하는 지시문. 예를 들어, “질문에 답하세요”
In-context Examples (E): n개의 맥락 내 예제. 각각의 예제는 입력과 그에 대한 정답 쌍(ei = (xi,yi))
- E={e1,e2,...,en}
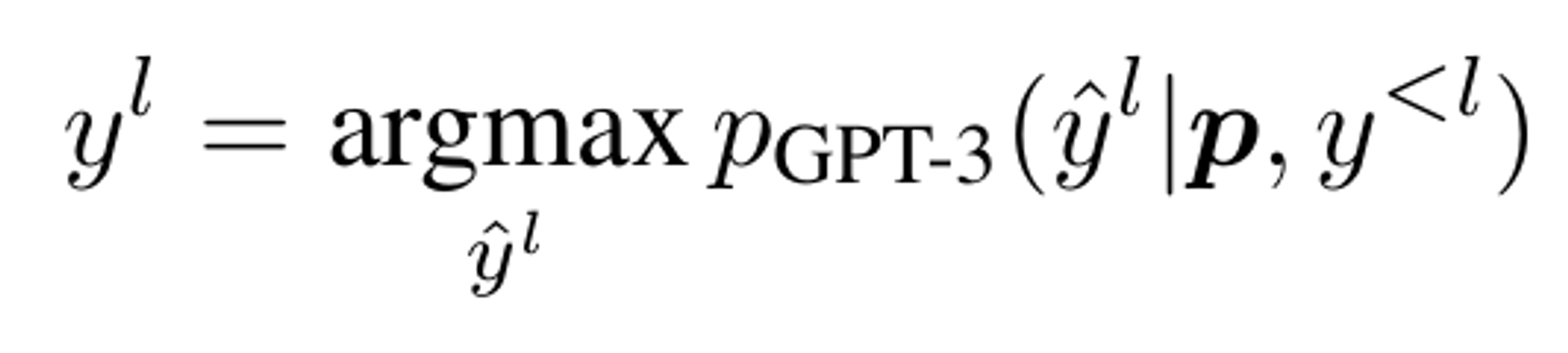
I번째 토큰 yl 예측 방법
- 이전까지의 출력 (y<l)과 프롬프트 (p)를 바탕으로, I번째 위치에서 가장 높은 확률을 가지는 토큰 y^l 선택
Prompt 방법
- Testing input
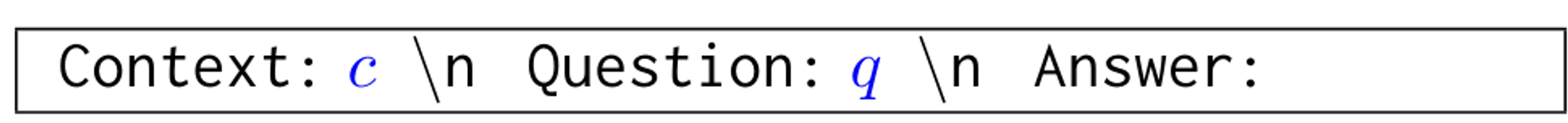
- Example input
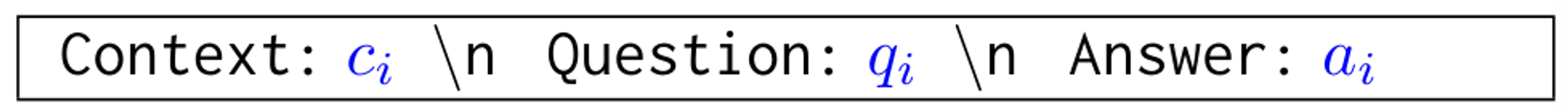
- Prompt head: 작업을 설명하는 지시문
- 예시
Prompt Head: Please answer the following questions based on the provided context.
---
Context: A man is riding a bicycle. \n Question: What is he doing? \n Answer: Riding a bicycle.
---
Context: A woman is cooking in the kitchen. \n Question: What is she doing? \n Answer: Cooking.
---
Context: A group of people are walking in a park. \n Question: What are they doing? \n Answer:
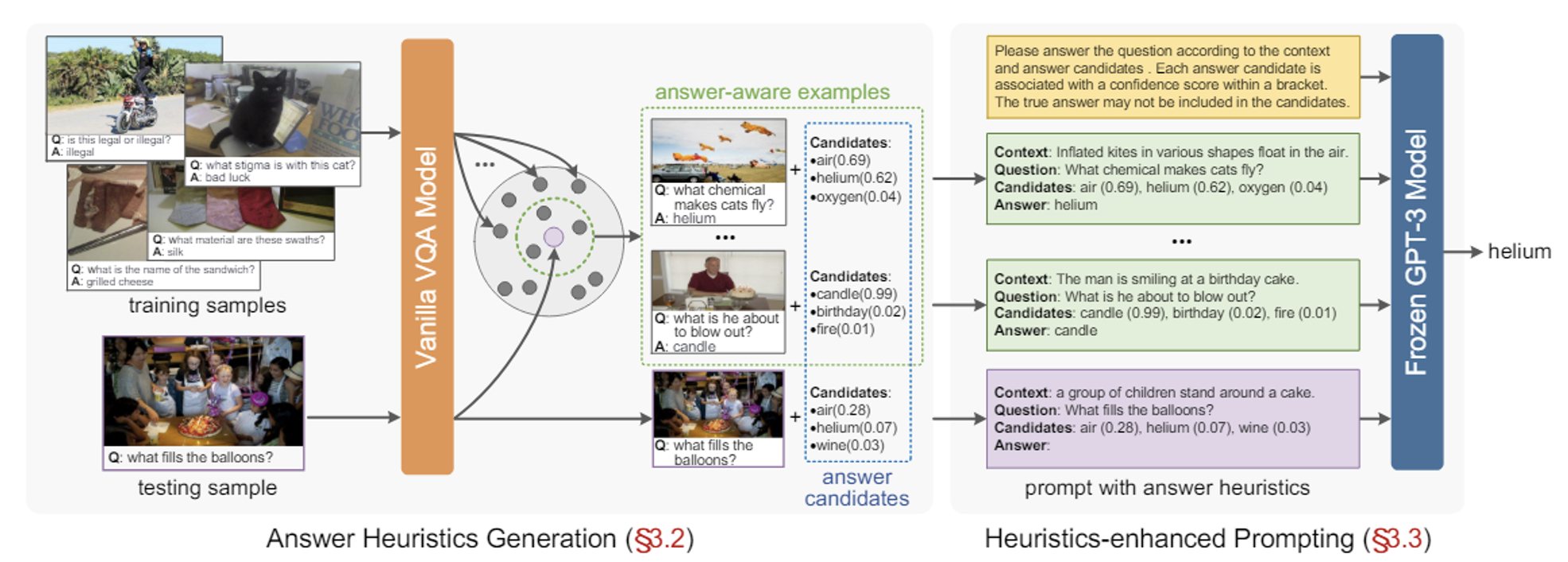
Stage-1: Answer Heuristics Generation
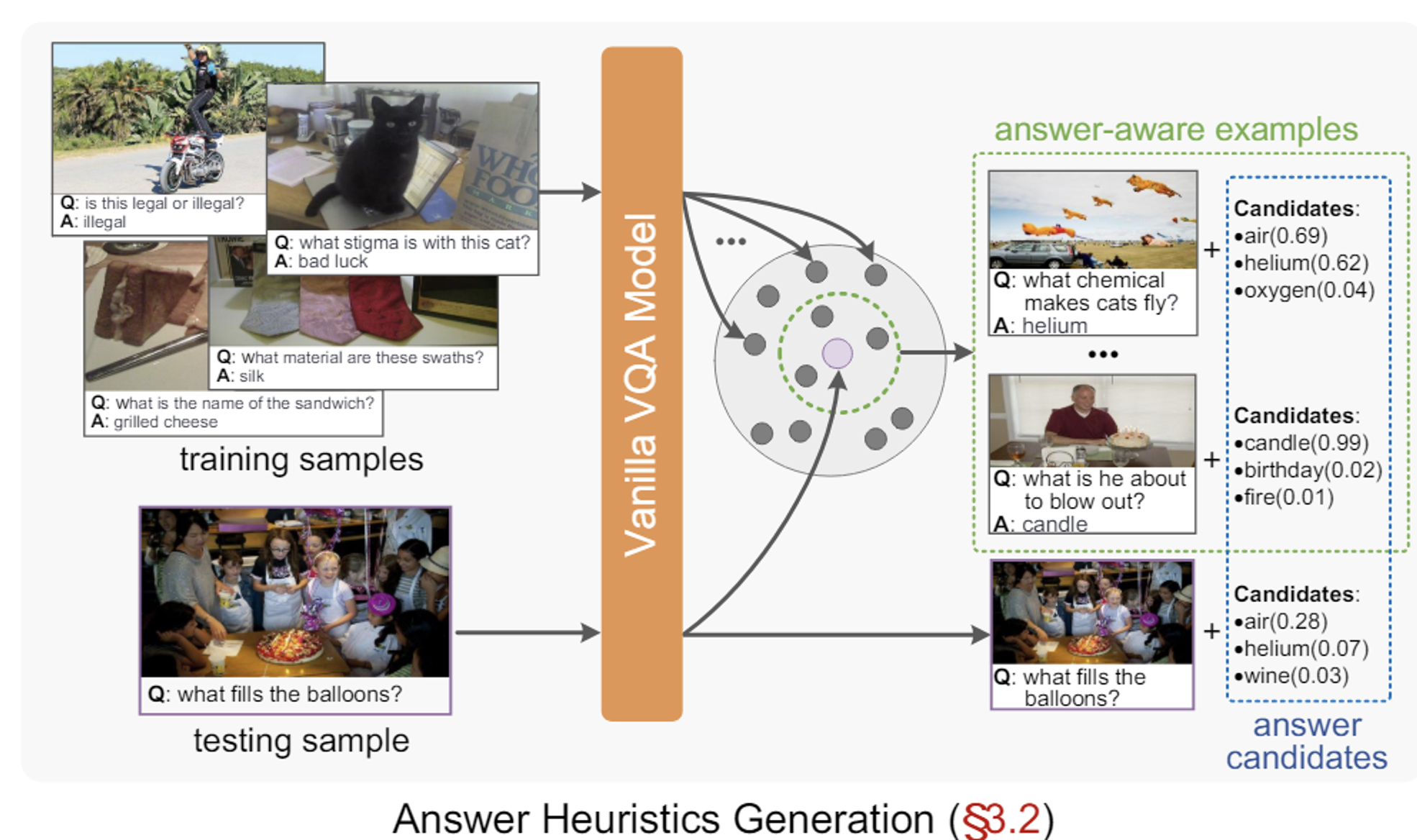
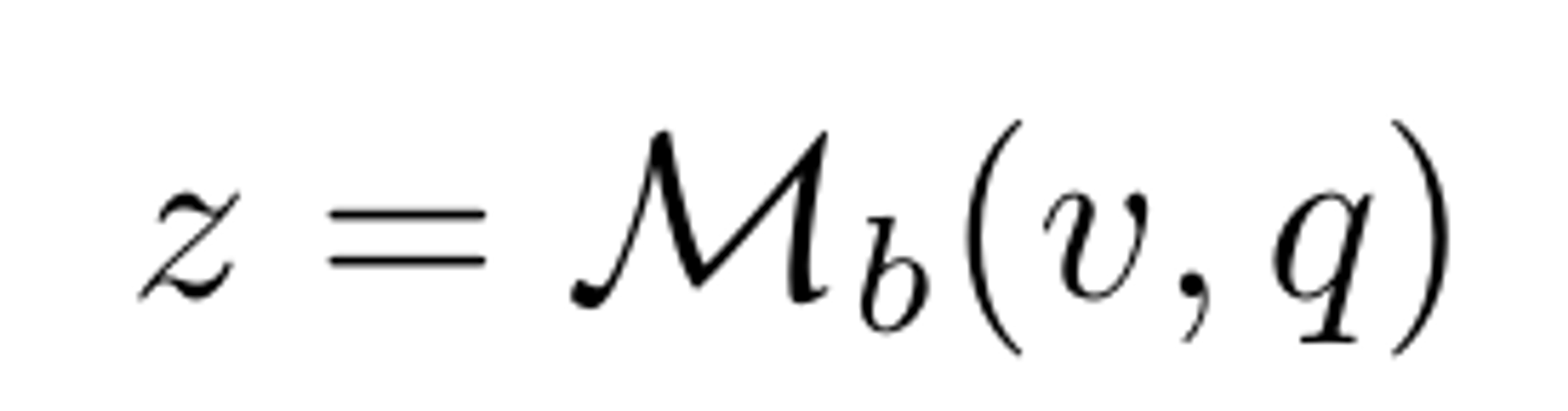
Vanilla VQA Model은 backbone(Mb)와 classification head (Mh)로 구성되어있다
Answer Vocabulary (W): 학습 데이터셋에서 가장 빈번하게 등장하는 정답들로 구성된 어휘 (S개의 답변 wj)
backbone의 역할: 입력값인 v와 q를 fusion해서 z (feature)를 추출
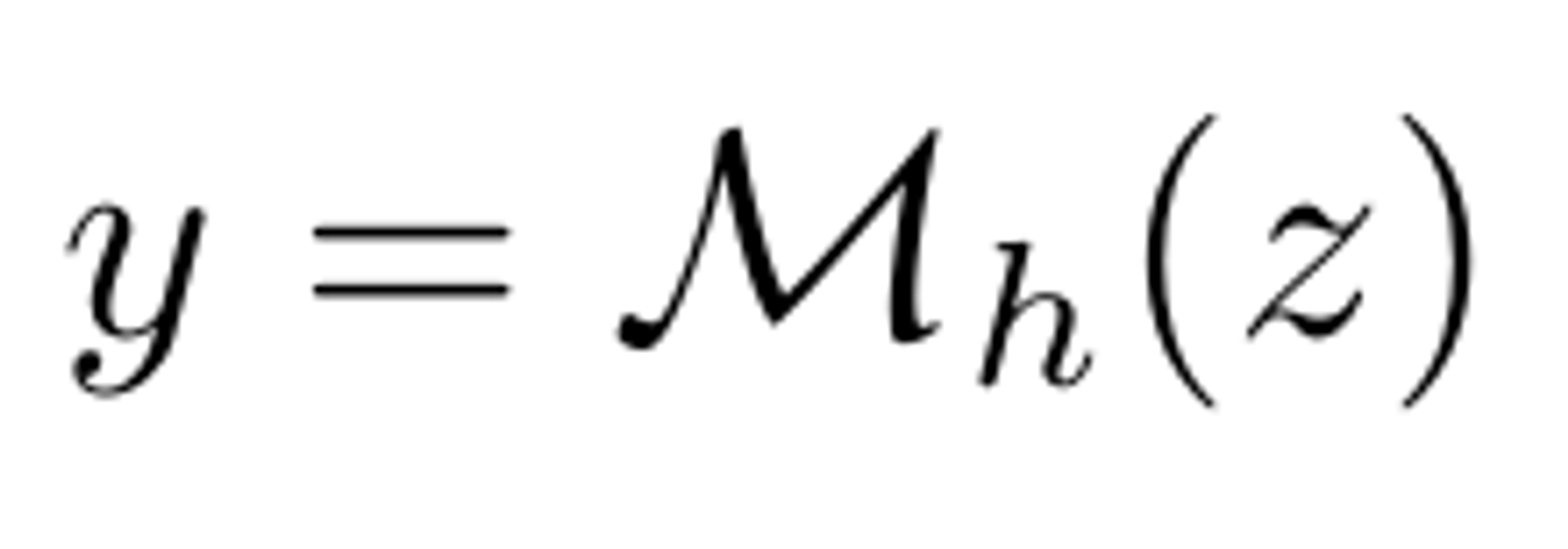
classification head의 역할: z를 통해 W 중에서 하나를 선택(linear + sigmoid)
cf. softmax가 아닌 sigmoid를 사용하는 이유는 하나의 질문에 대해 여러개의 정답이 있을 수 있기 때문이다. 즉 각 클래스에 대해 독립적인 확률 값을 출력(softmax는 확률의 합이 1)
최종 결과 (y): confidence score for answer wi
Answer candidates
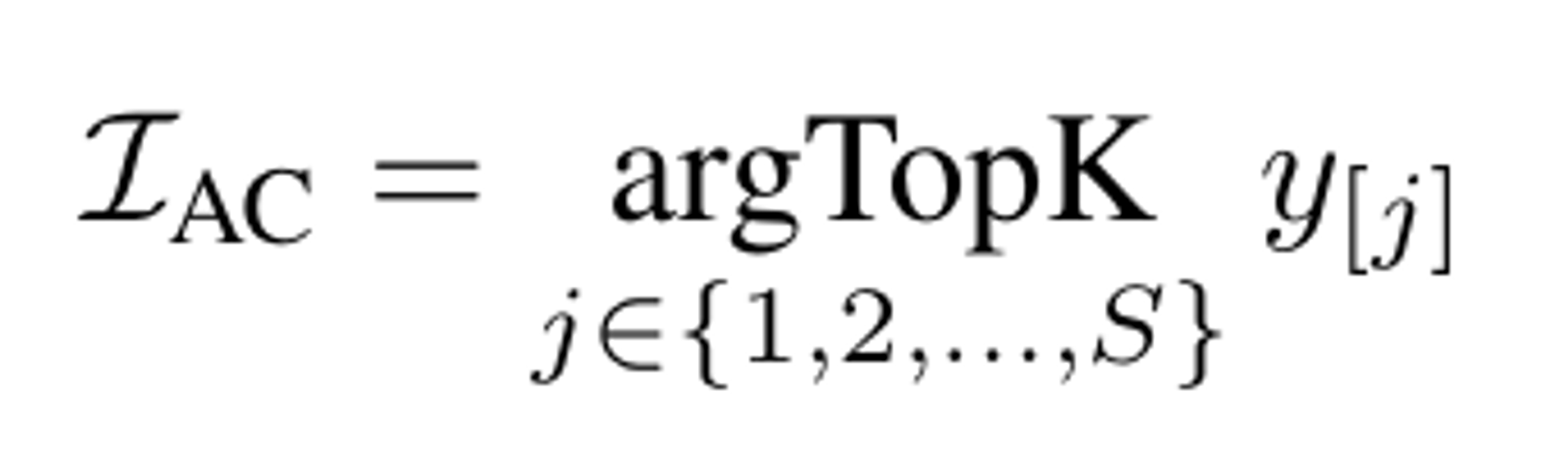
Top k를 이용해서 y중에서 k개를 선택
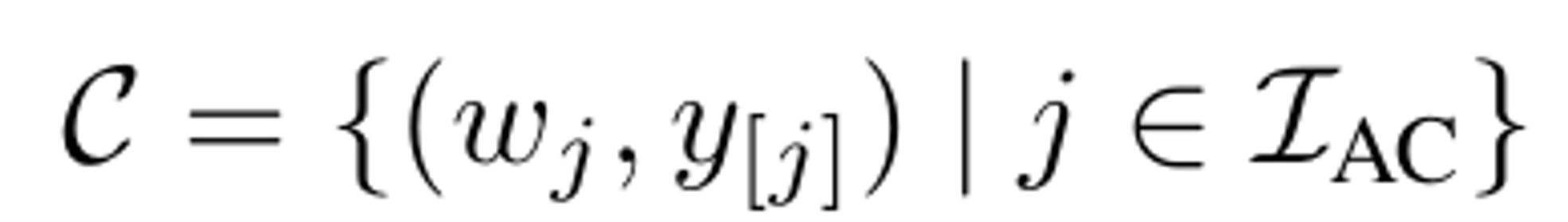

최종 형태는 위와 같이 answer candidate와 confidence score로 구성
Answer-aware examples
- 입력과 유사한 답변을 가진 학습 데이터셋의 예제를 선택
위에서 나온 feature(z)를 코사인 유사도를 분석해서 유사한 예제를 추출
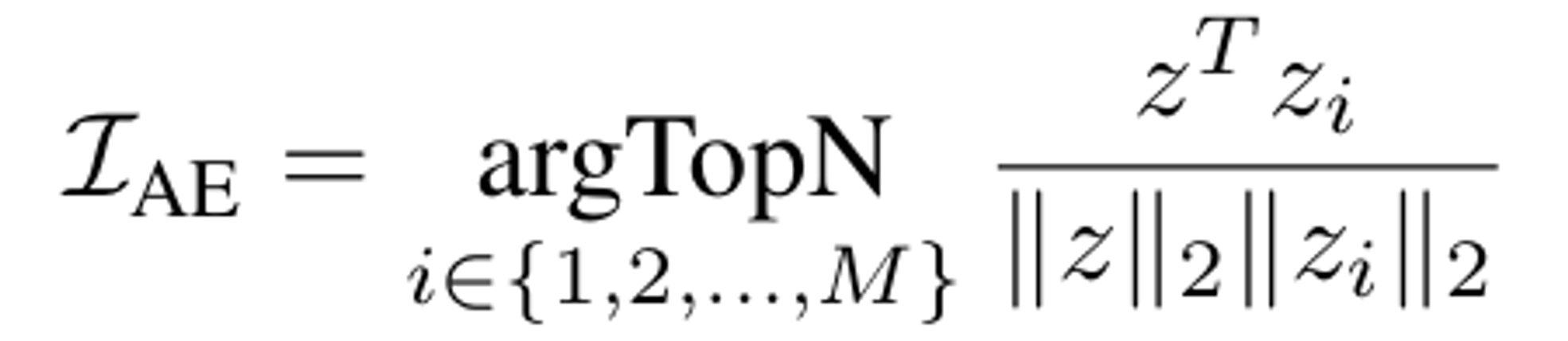
Top N를 이용해서 z중에서 N개를 선택
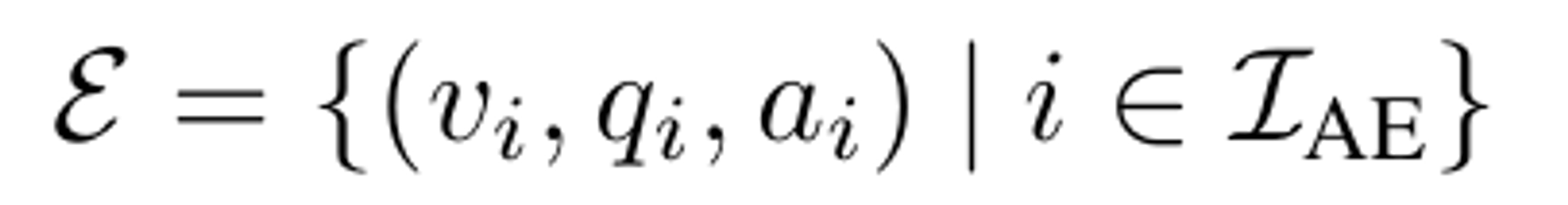
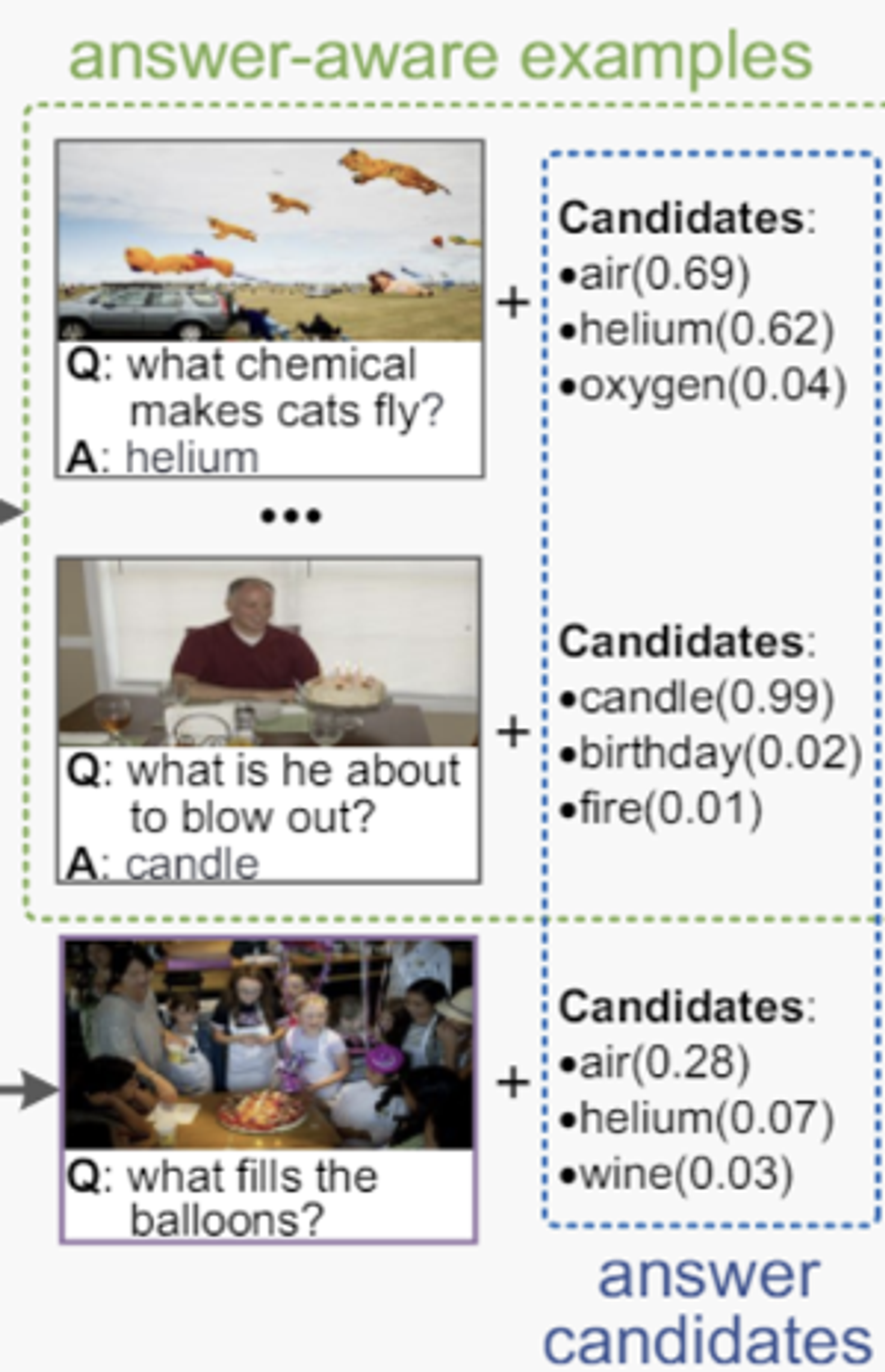
최종 형태는 위와 같이 모든 세트가 들어가야한다
Stage-2: Heuristics-enhanced Prompting
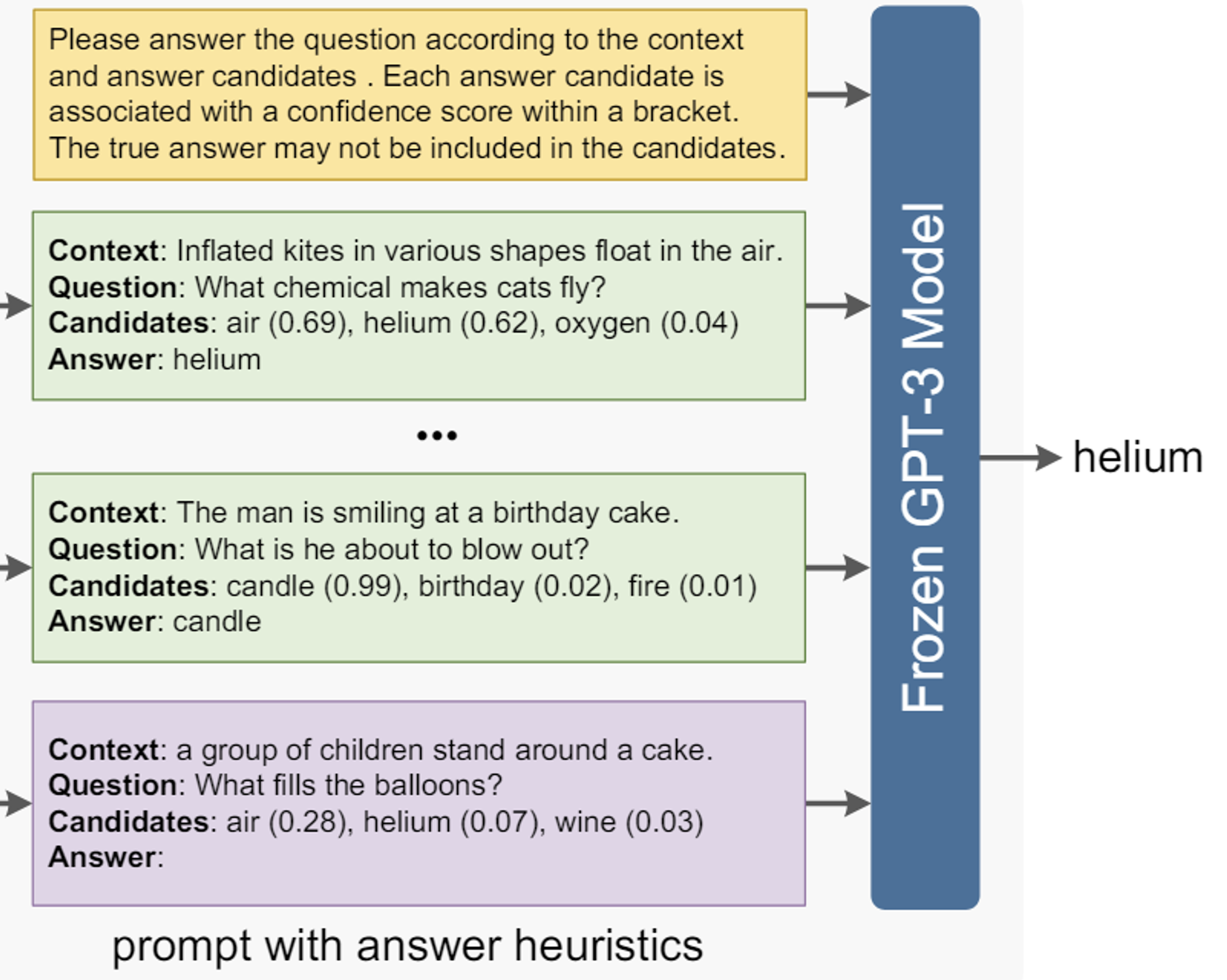

위와 같은 형태로 GPT-3에 입력값을 넣고, 이를 통해 최종 Answer를 도출
emsemble strategy
여러 번의 프롬프트를 통해 얻은 답변을 종합하여 최종 답변을 결정
N개의 답변 예제와 T번의 병렬 프롬프트를 생성
Experiments
OK-VQA: 일반적으로 사용되는 지식 기반 VQA 데이터 세트
- Train: 9K , Test: 5k (image-text pair)
- 한 이미지에 대해서 10개의 Open-ended Answer
- 예시(What is the main object in the image?)
- "dog"
- "puppy"
- "canine"
- "pet"
- "animal"
- "golden retriever"
- "furry friend"
- "man's best friend"
- "mammal"
- "four-legged friend"
- soft score: 모델의 답변이 10개의 주석 답변 중 몇개와 일치하는지, 또는 유사한지
- 예시(What is the main object in the image?)
A-OKVQA: 가장 큰 지식 기반 VQA 데이터 세트
- Train:17000, Test:1000, Valid:7000
- 주관식(DA): 10개의 open-ended Answer
- 객관식(MC): 4가지 선택지 중에서 정답을 선택
- 예시
Context: A man is riding a bicycle. \n Question: What is he doing? \n Choices: [riding, running, walking, swimming] \n Answer: riding.
MCAN-large(Modular Co-Attention Network): Vanilla vqa 모델로 선택
- 이미지 특징 추출 방법 변경
- 기존방식: Bottom-up Attention 매커니즘(여러 개의 region으로 나누고 각 지역에서 시각적 특징 추출)
- CLIP의 시각 적 인코더(RN5-X64)를 이용해서 이미지 전체를 그리드 형태로 나누어 특징 추출
- LSTM → Pretrained BERT-large로 변경
Pretraining
VQAv2와 Visual Genome를 이용한 사전학습을 진행
Prompting stage
OSCAR+: PICa와 동일하게 캡션 모델로 사용
- K=10, N=16, T=5, GPT-3: text-davinci-002, 샘플링 온도:0
Ablation Studies

2-stage를 external KB를 이용한 MAVEx 모델과 비교
비교를 위해 ViLBERT로 다시 학습

4가지 VQA model을 사용해서 성능을 비교
결과: 1단계에서 성능이 높아지면 더 좋은 answer heuristics를 제공하기때문에 최종 성능이 좋았다
CLIP의 시각적 특징이 대규모 사전학습으로 인해 더 풍부한 시각적 지식을 포함하고 있기 때문에 성능이 더 좋은것으로 추정
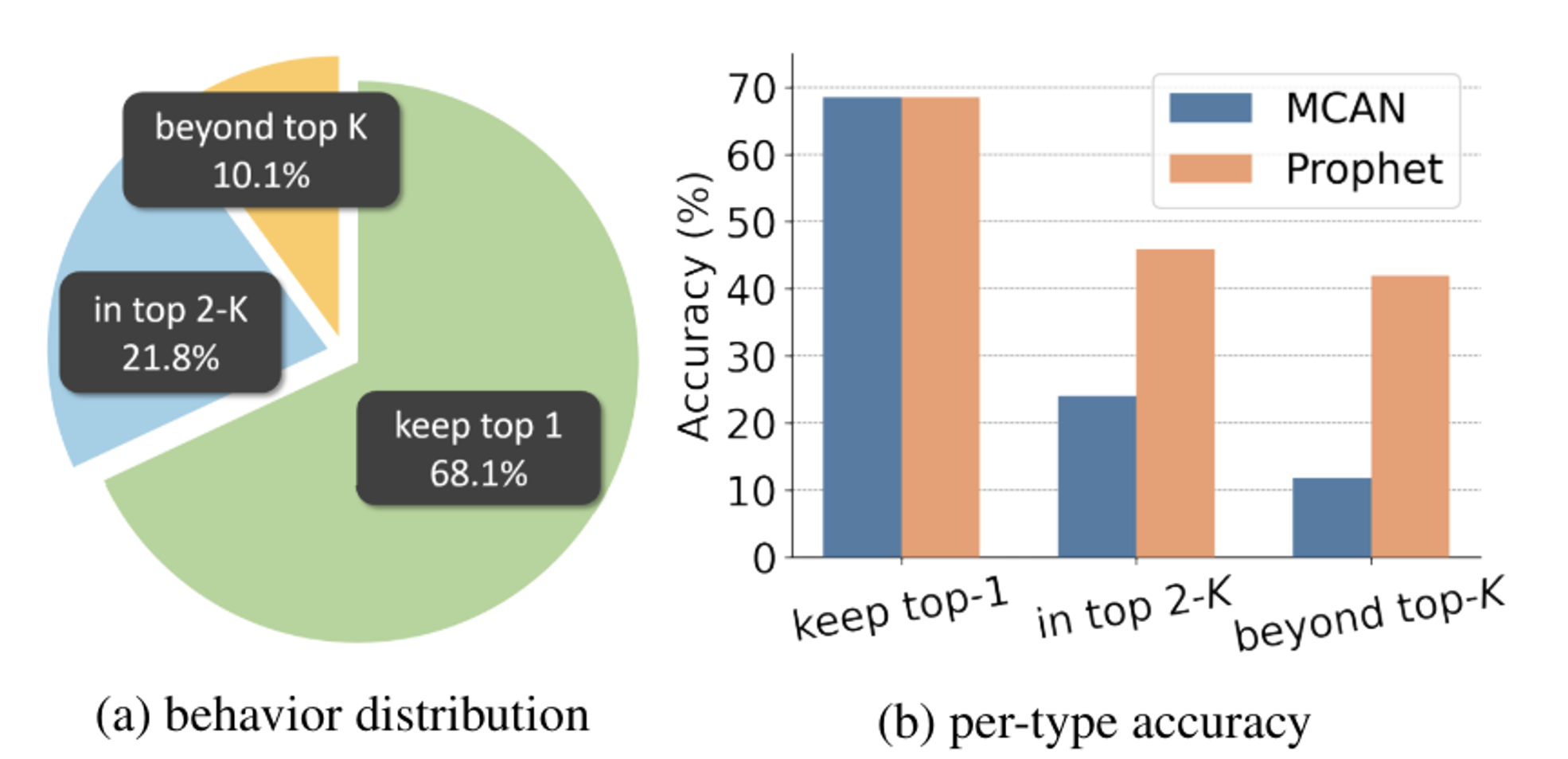
top-1: confidence가 가장 높은 것
top-2: confidence가 2,3번째로 가장 높은 것
beyond top-k: confidence가 k+1번째로 가장 높은 것부터 사용
결론적으로 어려운 샘플일수록 Prophet에서 더 나은 답변 제시
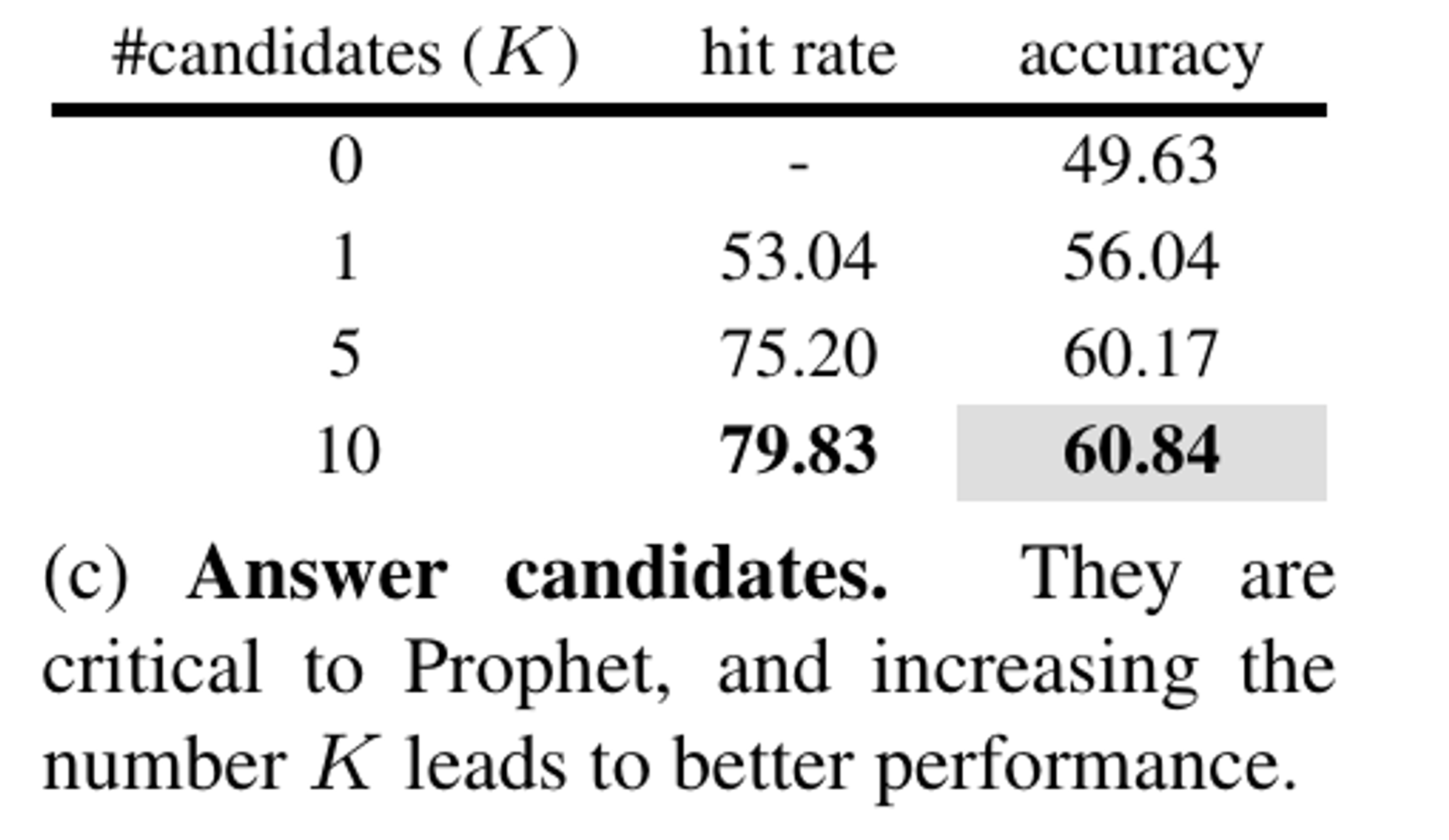
Stage1에서 생성하는 답변 후보가 많아질 수록 성능이 증가
0에서 1로 변경함으로서 성능이 기하급수적으로 증가 → answer candidate가 중요하다!
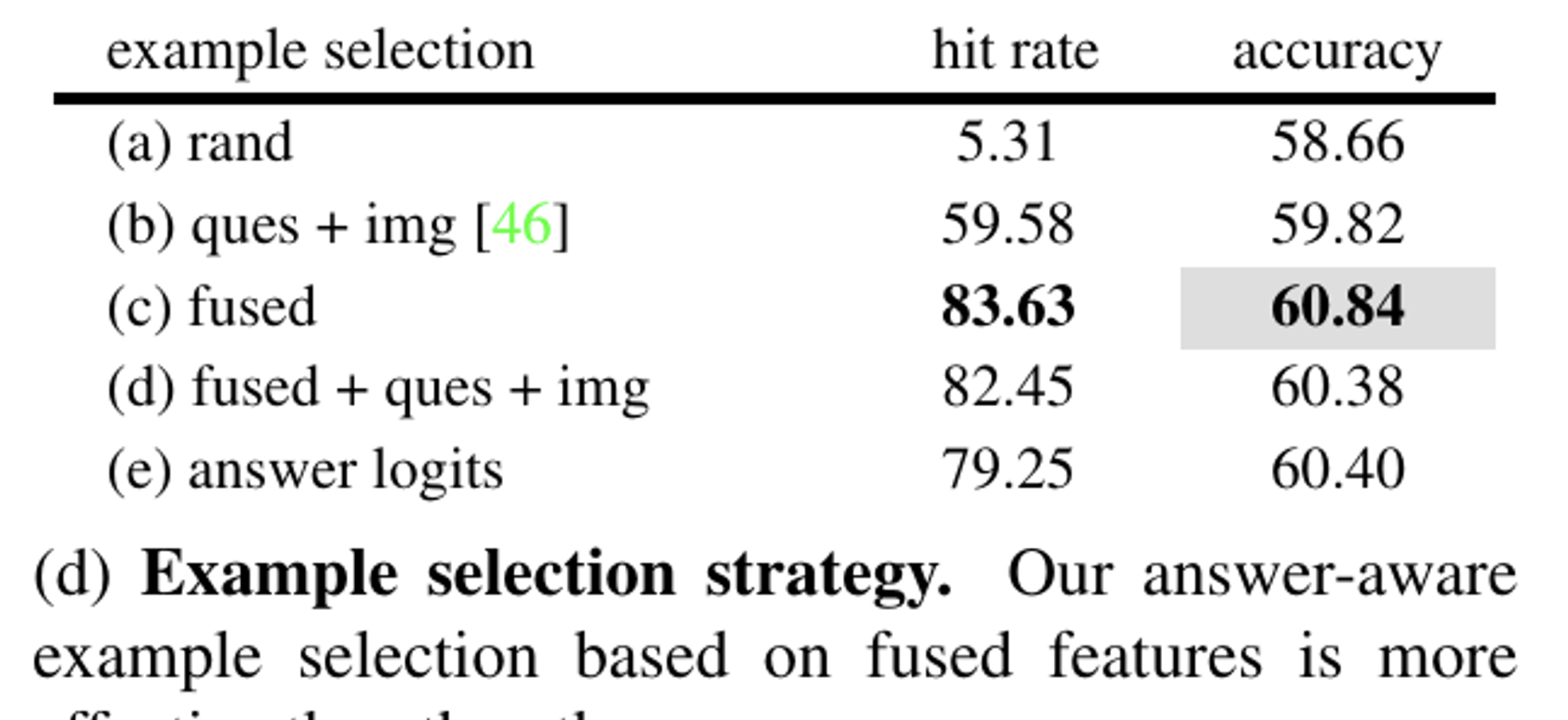
예제를 설정하는 방법을 5가지 적용함으로서 성능을 비교

예제와 Prompt 횟수를 증가할수록 성능이 증가

b: 프롬프트 헤드 제거
c: confidence score 삭제
d: 이미지 캡션 제거
e: 외부 모델에서 예측 태그 추가
결론
- Confidence socre는 중요하다
- image caption 없이도 안정적인 성능
- 프롬프트 헤드를 제거해도 성능이 크게 줄지 않는다
