Retrieval-Augmented Score Distillation for Text-to-3D Generation 논문 리뷰

이전 Text-to-3D의 결과를 보면 mesh가 잘 생성이 되지 않은 결과들이 많았습니다. 점토같이 나온다던가, 아니면 얼굴이 2개나오는 Janus issue가 생성이 된다던가 하는 문제입니다. 해당 논문에서는 Retrival Augmented 방법을 사용해서 3D dataset에서 text prompt와 비슷한 object를 기반으로 3D mesh를 생성하게 되면 이전에 비해서 이상하게 나오는 문제를 해결할 수 있다고 합니다.
논문을 읽기전에 사전지식으로 SDS와 VSD 개념이 필요합니다. VSD를 발표한 ProlificDreamer의 논문을 읽고 오시면 조금 더 이해하시기 쉬우실 겁니다.
ProlificDreamer 논문리뷰: https://velog.io/@guts4/ProlificDreamer-High-Fidelity-and-Diverse-Text-to-3D-Generation-with-Variational-Score-Distillation-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
Retrieval-augmented score distillation
Formulation
SDS와 달리 VSD는 분포 자체를 학습하기 때문에, particle-based variational inference(ParVI) 프레임 워크를 기반으로 3D Representation을 생성합니다.
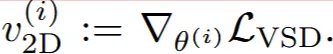
VSD의 수식은 렌더링된 이미지의 분포가 특정 camera 정보와 text prompt를 condition으로 받아 2D diffusion이 생성한 이미지의 분포와 비슷해지게 학습되기 때문에, 수식은 위와 같습니다. 왼쪽 부분이 2D diffusion의 생성결과, 오른쪽 부분이 비슷해지게 학습되는 과정입니다.
해당 논문의 목표는 3D databse D와 text prompt c를 이용해서 얻은 ξN (c, D) asset과 비슷해지게 학습하는 것입니다. 3D asset을 얻는 과정은 입력으로 들어간 text prompt의 임베딩 값과, 3D asset을 정의하는(미리 저장된) 텍스트 임베딩 값과의 차이가 가장 적은 1개를 선택합니다.
Initialized distribution as a geometric prior
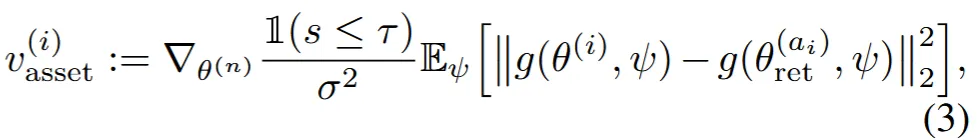
τ가 warm-up phase를 정의하는 threshold인데, 해당 값의 이전 iteration까지는 위의 수식을 사용한다는 것입니다. 위의 수식은 초기에 reference asset의 데이터 분포와 우리가 학습하고자 하는 varitational distribution을 을 비슷하게 만드는 과정입니다. 간단하게 수식을 설명하면 || . ||안에 왼쪽 수식이 우리가 학습하고자 하는 i번째 particle의 렌더링된 결과, 오른쪽 수식이 N개의 reference asset 중에서 i번째 index의 값을 가져오고 해당 asset을 렌더링한 결과입니다. 결국 variational distribution을 reference distribution으로 옮기는 과정입니다.
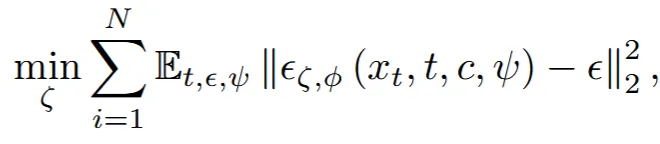
Warm-up 단계에서 초기화된 Variational Distributionγ(θ∣c)를 LoRA로 fine-tuning된 Diffusion 모델의 텍스트 조건부 분포와 정렬하는 과정이 진행됩니다.이 과정은 기존 VSD와 동일하게, Denoising Score Matching을 기반으로 이루어지며,입자들이 텍스트 프롬프트를 잘 반영하는 방향으로 최적화됩니다.

첫번째 사진이 3D 데이터베이스에서 text prompt와 가장 알맞은 3D mesh 데이터이고, 아래의 이미지들은 가져온 데이터를 기반으로 학습한 particle이 렌더링된 결과입니다.
Lightweight adaptation of 2D prior
2D diffusion 모델들은 대부분 정면 이미지들로만 학습되었기 때문에, 정면 사진만 잘 만들고 나머지 시점의 사진을 잘 못 만드는 경향이 있습니다. 이러한 경우 2D diffusion으로 학습된 3D asset의 표현력은 안 좋은 결과로 나올 것입니다.

해당 그림을 보면 text prompt로 뒷모습, 앞모습을 넣은 경우에도 극단적인 맨왼쪽 사진을 제외하고는 모두 거의 앞모습의 이미지를 생성하는 것을 확인할 수 있습니다.
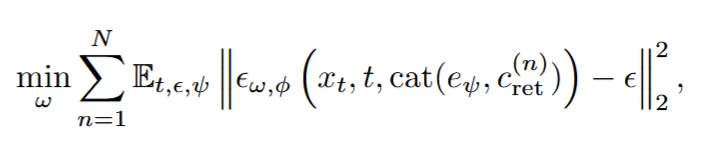
위와 같은 정면 이미지에 편향된 문제점을 극복하기 위해서 lightweigth adaptation 기법을 적용합니다. 수식은 위와 같습니다. 여기서 는 3D asset을 표현하는 미리 저장된 text prompt의 임베딩 값입니다. 는 ‘front view’와 같은 view prefix 임베딩 값입니다. 는 LoRA로 학습된 모델입니다. x는 n번째 3D asset의 렌더링된 이미지, 마지막으로 w는 diffusion U-net의 learnable 파라미터입니다.

맨위의 3D asset을 condition으로 넣어주면서, (b)의 그림이 (c)의 그림처럼 변한 것을 확인할 수 있습니다. 이전에 비해서 확실히 정면 시점에만 국한되지 않고, 옆 뒤 모습이 모두 잘 나온 것을 확인할 수 있습니다.
Retrival of 3D assets
3D asset을 가져오는 방법은 간단합니다. 우선 사전 준비를 위해서 text prompt(c)를 CLIP Embedding을 통해서 텍스트 임베딩 값을 생성하고, 3D asset의 데이터에 대해서 미리 정의된 caption과 렌더링된 이미지를 각각 CLIP을 통해서 임베딩 값을 얻습니다.
첫번째로 Top-K 방식을 이용해서 입력 텍스트 임베딩 값과 asset의 caption 임베딩 값을 비교해서 가장 비슷한 N’개를 추출합니다. 이후 N’개중에서 텍스트 임베딩 값과 asset의 렌더링된 이미지의 임베딩 값을 비교해서 다시 N개를 추려냅니다.(N’ > N)
시간은 3초밖에 걸리지 않을만큼 빠르게 진행됩니다.
Ablation Study

첫번째 부분이 3D asset을 이용해서 초기화 하지 않고 진행한 것, 두번째 부분이 Lightweight adaptation부분 없이 diffusion 모델을 이용한 것, 마지막이 모두 이용한 것입니다. 확실히 3D asset을 이용한 경우 볼륨감이 잘 생성된 것을 확인할 수 있습니다. 근데 개인적으로 마지막 Lightweight adaptation 유무의 차이는 2D 부분에서는 확실하게 느껴졌는데, 3D부분에서의 차이는 미미한거 같습니다.
Limitations
논문의 마지막 부분에 한계점으로 2개가 나옵니다. 첫번째로는 학습시간입니다. PorlificDreamear(VSD를 사용한 baseline 논문)이 학습에 8시간이 걸렸고, 그것보다는 적은 6시간이긴 하지만 여전히 많은 시간이 소요됩니다.
두번째로 복잡한 텍스트 프롬프트가 입력되면 Diffusion 모델 자체에서 잘 이해하지 못해서 3D 결과가 안좋게 나온다는 점입니다.
