
기존 SAM(1, 2) 모델들이 point나 box를 이용해 특정 객체 하나를 분할하는 것에 집중했다면, SAM 3는 텍스트나 이미지 예시를 입력받아 해당 Concept에 해당하는 모든'객체를 찾아내고 비디오에서 추적하는 능력까지 갖췄습니다. 이를 위해 대규모 데이터셋과 새로운 벤치마크까지 제시했습니다.

또한, SAM 3는 Open-Vocabulary 환경에서도 기존 모델보다 훨씬 정밀한 마스크 생성, 작은 객체 탐지, 그리고 희귀한 개념 처리 능력을 보여주며 확실한 성능 향상을 입증했습니다.
과연 모델 내부적으로 어떤 구조적 변화가 있었기에 이런 비약적인 발전이 가능했는지, 아래에서 자세히 확인해보겠습니다.
Promptable Concept Segmentation(PCS)
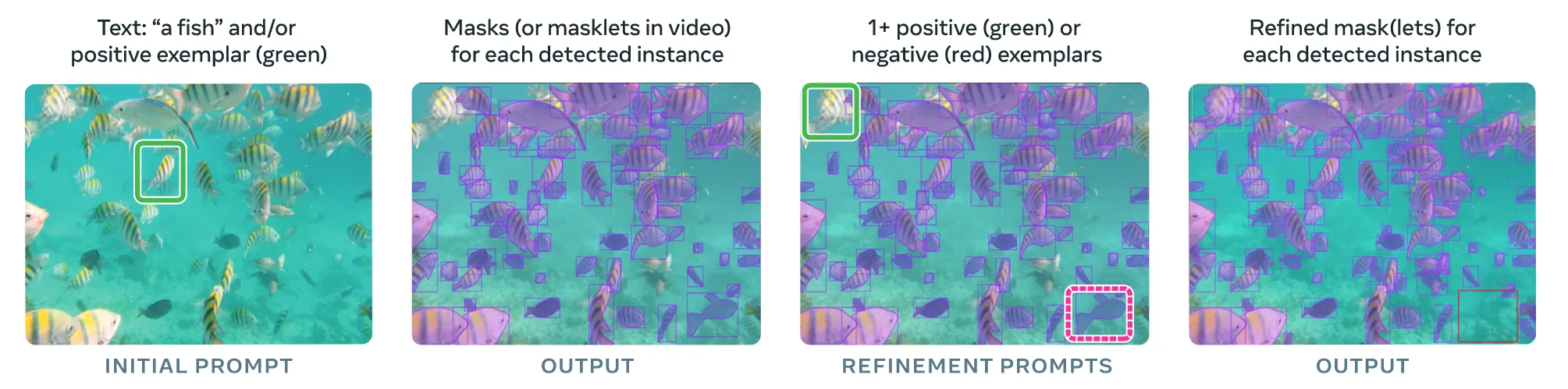
하나의 이미지나 30초보다 작은 길이의 짧은 비디오가 들어오고, 해당 입력에서 detect나 segment하고 싶은 부분에 대해서 text나 positive exempler(왼쪽에 초록색 박스)를 넣으면 condition에 맞는 모든 객체를 detect나 segment하는 방식이 Promptable Concept Segmentation(PCS)입니다.
여기서 사용하는 text prompt는 sinple noun phrases(NPs)로 문장이 아닌 간단한 단어로 표현되어야하고, 컴퓨터에 사용되는 mouse와 동물의 mouse처럼 이중적인 단어나 cozy나 large처럼 주관적인 단어 그리고 brand identity와 같은 모호한 단어들을 학습하기 위해서 전문가 3인의 검증을 거친 평가 프로토콜을 구축하고, 모델 내에 별도의 Ambiguity Module을 탑재했습니다. 자세한 내용은 appendix(E.3, C.2)를 참고하시면 됩니다.
Exempler같은 경우 위의 그림에서 3번째 부분처럼 선택되지 않은 영역을 유저가 초록색 박스처럼 positive로 지정할 수 있고, 빨간색 박스처럼 원하지 않는 부분을 negative로 선택해서 결과를 수정할 수 있습니다.
Model
Detector
아키텍처에서 사용한 detector는 DETR 방식을 선택했습니다. Image나 Text prompt는 각각의 encoder를 통해서 encoding되고, image exemplar가 존재할 경우 exemplar encoder를 통해서 encoding됩니다. 여기서 생성된 text token과 image exemplar token을 논문에서는 prompt token이라고 정의했습니다.
Image token과 prompt token에 대해서 Cross Attention을 수행한 후 DETR기반의 Decoder를 사용해서 이미지에서 prompt에 맞는 부분을 탐지합니다. 각각의 Decoder layer는 물체가 prompt에 해당하는지를 binary label과 confidence로 나타내고, bounding box의 변화량을 delta로 나타냅니다. 즉 첫번째 layer에서 물체에 대한 bbox와 confidence를 예측하면, 다음 layer는 이를 기반으로 bbox를 더 정교하게 예측하기 위해서 deltat만큼 변화시키고, 이에 대한 confidence를 예측하는 식으로 진행합니다. 특정 box를 집중적으로 보기 위해서 box-region-positional bias와 vanilla attention 방식을 사용했습니다. DETR은 Detection모델이기 때문에 Segmentation을 진행하기 위해서 MaskFromer를 추가로 사용합니다.
Presence Token
하나의 Token으로 물체가 존재하는지 확인하면서 어디에 있는지 동시에 확인하는 작업을 어렵습니다. 왜냐하면 물체의 유무는 global한 정보이고, 어디에 있는지는 local한 정보이기 때문입니다. 이에 SAM3는 presence token의 학습을 통해서 이 과정을 분해했습니다. Presence token은 target concept이 존재하는지에 대해서 존재 여부만을 나타냅니다.
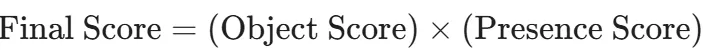
최종 점수는 위와 같이 Presence Score를 기반과 기존 object score를 곱해서 나타내기 때문에 물체가 존재하지 않으면 presence score가 0이라서 최종 score도 0이됩니다. 따라서 기존의 DETR의 token은 물체의 존재여부를 알고 있는 상태에서 물체의 위치만 알 수 있도록 학습 될 수 있기 때문에 global과 local에 대해서 2개의 token으로 분해해서 더 정확한 결과를 얻을 수 있습니다.
Image Examplars and Interactivity
SAM3도 SAM(1,2)처럼 point나 box를 통해서 prompt를 줄 수 있지만 기존 모델들과 다르게 하나의 객체 탐지가 아니라 이미지내에 prompt와 동일한 모든 객체를 찾습니다. 이를 위해서 prompt가 어딨는지 위치 정보를 주기 위해서 position embedding, positive인지 negative인지 알려주기 위해서 label embedding, prompt에 해당하는 이미지 정보를 주기 위해서 ROI-pooled visual feature를 이용해서 학습을 진행합니다.
Tracker and Video
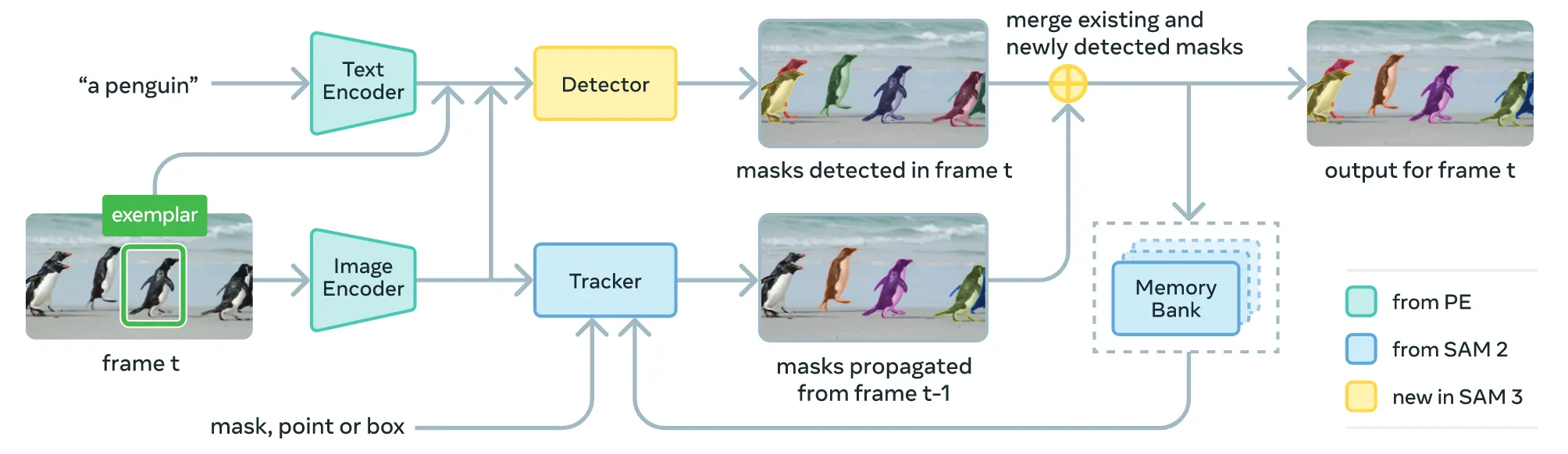
Video에서 매 프레임마다 물체를 탐지하기 위해서 Detector와 Tracker를 사용합니다.
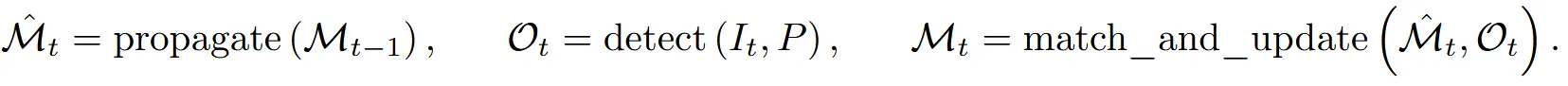
Detector는 매 프레임마다 새로운 물체를 예측해서 결과 로 나타고, Tracker는 이전 프레임에 생성된 mask들 에 대해서 현재 위치에 존재하는지에 대해서 예측한 mask 로 나타냅니다. 이후 Detector가 예측한 와 Tracker가 예측한 를 비교해서 물체가 동일하게 존재하는지, 존재한다면 그 물체를 추적하는 형식으로 진행합니다.
Tracker는 SAM2 모델을 이용했고 detector와 동일한 image/frame encoder를 사용합니다. Detector를 우선 학습한 뒤 PE backbone만을 freeze시키고 prompt encoder, mask decoder, memory encoder, and a memory bank를 포함해서 tracker를 학습시킵니다. Memorey encoder는 이전 프레임에 대한 정보를 저장하는 모델로 transformer 형태의 아키텍처로 현재 프레임과 이전 프레임의 정보를 cross-attention를 기반으로 정보를 공유하는 방식으로 설계 되어있습니다. 자세한 내용은 appendix(C.3)를 참고하시면 됩니다.
Matching and Updating Based on Detections
Detector와 Tracker가 예측한 mask가 동일한지 비교하기 위해서 겹치는 정도를 나타내는 IoU(Intersection over Union) 값을 이용했고, 이 값이 threshold보다 낮다면 새로운 객체로 정의하고 masklet을 생성하여 추적을 시작합니다. 해당 방법만을 이용한다면 엉뚱한 것들이 매칭 되거나, masklet이 잘못 생성될 수 있기 때문에 2가지 해결 방법을 제시했습니다.
첫번째로 특정 masklet이 지난 몇 프레임 동안 Detector의 마스크 결과와 비교해서 threshold보다 낮다면 가끔 안보이는 불안정한 mask로 판단하고 제거합니다.
두번째로 주기적으로 Tracker의 예측을 Detector의 예측으로 변경하여 memory bank에 가장 확실한 정보를 제공합니다.
추가적으로 유저가 중간에 positive, negative mask를 지정해서 이를 기반으로 maks를 refine하는 과정도 추가했습니다.
Data Engine
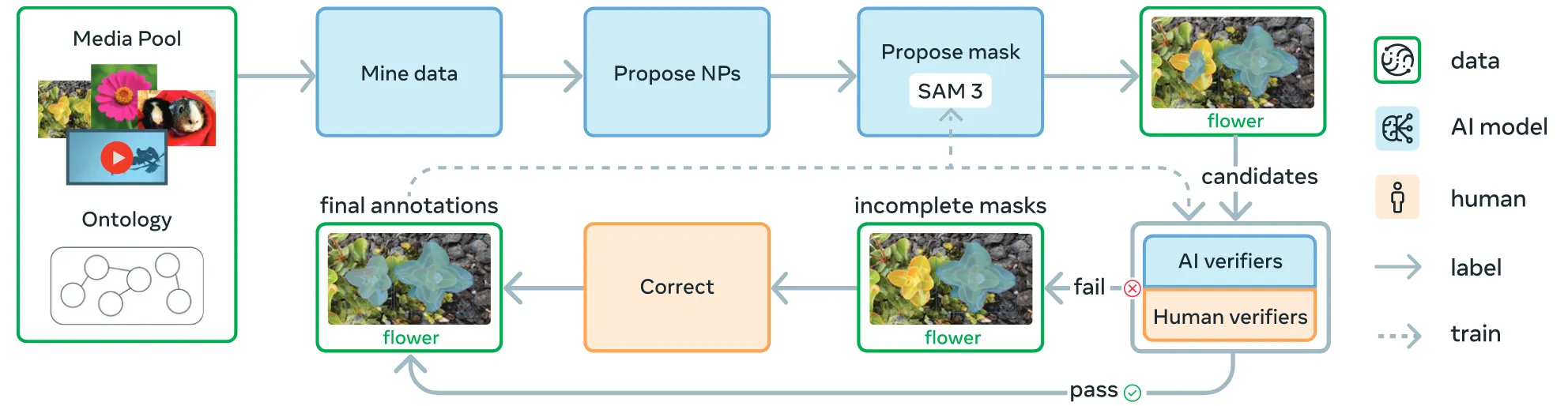
SAM3를 학습하기 위한 데이터를 구축하기 위해서 SAM3가 잘 해결하지 못하는 데이터를 만들고, 해당 부분을 다시 학습시키는 과정을 반복합니다. AI가 1차로 annotation을 하고, 어려운 문제들만 사람이 직접하는 형식을 사용했습니다. 초기에는 이미지들을 기반으로 학습하고 마지막에 비디오로 확장하는 방식입니다. 자세한 내용은 Appendix D에 나와있습니다.
제아된 마스크는 annotator들이 mask를 수용할지 결정하는 Mask Evrification(MV)과정과, 이미지의 모든 부분에 mask가 된지 확인하는 Exhaustivity Verification(EV)과정을 통해서 확인됩니다.
Data를 구축하는 방법은 자세히 Phase1~4까지 나타나있습니다. 아래는 각 Phase에서의 역할입니다.
Phase1: Human Verification
무작위로 샘플링된 이미지에 간단한 caption 모델을 사용해서 caption을 생성하고 여기서 Noun Phrases(NP)를 추출합니다. 기존의 SEgmentation 모델(OWLv2, GroundingDino)을 이용해서 텍스트에 해당하는 대략적인 박스를 찾습니다. 이 mask를 SAM2에 입력해서 mask를 생성합니다. 초기단계는 사람이 수행했고, 이 과정을 통해서 4.3M개의 image-NP의 쌍이 생성됐습니다.
Phase 2: Human + AI Verification
Phase1에서 생성된 데이터에 대해서 사람과 Llama 3.2모델을 통해서 위에서 설명한 MV와 EV과정을 진행합니다. Llama모델의 입력은 image-phrase-mask쌍이고 출력으로는 mask quality를 측정한 결과입니다. 사람은 Phase1 데이터중에서 challenging case에 집중해서 진행됐습니다. 데이터를 모으고 위와 같이 정제하는 방법을 6번 반복해서 SAM3와 fine-tuning된 Llama의 성능도 증가합니다. Phase2는 negative-NP에 대한 쌍도 만들었고 결론적으로 122M image-NP pair가 생성됩니다.
Phase 3: Scaling and Domain Expansion
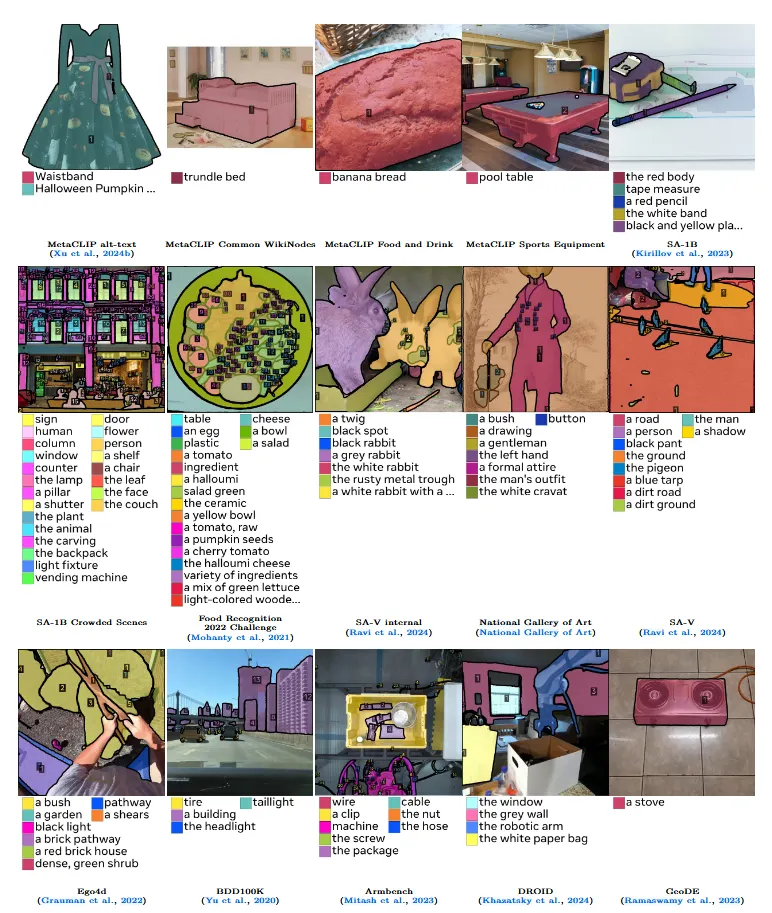
Phase3에서는 더 어렵고 광범위한 분야에 대해서 데이터를 생성합니다. 새로운 분야에 대해서 mask를 수용할지에 대한 MV 과정은 잘 작동하지만 이미지에 물체가 모두 존재하는지 판단하는 EV 과정은 성능이 좋지 않아서 human supervision을 통해 재학습을 진행했습니다. 희귀하고 세밀한 개념들을 포착하기 위해서 Alt-text, SA-Co Ontology dataset을 통해서 추가적인 데이터를 확보했습니다. SAM3 모델은 위와 같은 과정을 7번, AI verification 과정은 3번의 update를 통해서 고품질 데이터셋 19.5M개의 image-phrase쌍을 추가했습니다.
Phase 4: Video Annotation
이미지로 학습된 SAM 3모델에 비디오를 학습하기 위해 데이터를 추가하는 과정입니다. 장면 전환이나 움직임이 뚜렷한 영상만을 선택해서 프레임 단위로 짜릅니다. 이 프레임 이미지들은 기존의 학습된 Llama 모델을 통해서 caption을 생성하고, 이를 다시 SAM 3에 대해서 시간축으로 넣어서 학습하도록 합니다. 비디오 데이터는 52.5K개, maskletes는 467K개를 생성했습니다.
생략 부분
데이터셋 벤치마크 그리고 experiments에 대해서는 생략하도록 하겠습니다.
- Segment Anything with Concepts (SA-Co) Dataset
- Experiments
- Related Work
Conclusion
Promptable Concept Segmentation(PCS) task와 SA-Co 벤치마크 제시, Presence Token을 통한 global과 local token 분리, data engine 제시한 점을 논문이 기여한 점으로 제시했습니다. SAM3는 좋은 성능을 제시하고 다양한 형태와 도메인의 데이터로 학습했지만 여전히 학습하지 않은 데이터에서는 성능이 떨어짐을 나타냈습니다.
