Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture[2023 CVPR]

데이터의 label 없이, 데이터 자체의 구조나 관계로부터 스스로 정답을 만드는 self-supervised 방식은 널리 학습되는 방법중에 하나입니다. DINO는 데이터를 변형(augmentation)시키고 변형된 데이터와 원본 데이터와의 비교를 통해서 self-supervised 시키는 방법입니다. 이처럼 기존 self-supervise 방식들은 data augmentation을 진행해야 했습니다. 이러한 data augmentation 방식은 이미지를 자르거나(crop), 뒤집거나(flip)하는 등 다양한 방법이 존재했고 어떠한 방식을 쓰느냐에 따라서 성능이 달라졌습니다.
I-JEPA는 data augmentation 없이도 self-supervised learning을 할 수 있는 방법을 제시했습니다. 이미지의 한 부분을 보고 다른 부분의 representation을 예측하는 방식을 사용했다는데 어떻게 이를 통해서 self-supervised가 가능한지 확인해보도록 하겠습니다.
Introduction
기존 논문들이 제시한 self-supervise learning 방식은 크게 invariance-based 방식과 generative 방식 2가지가 존재했습니다.
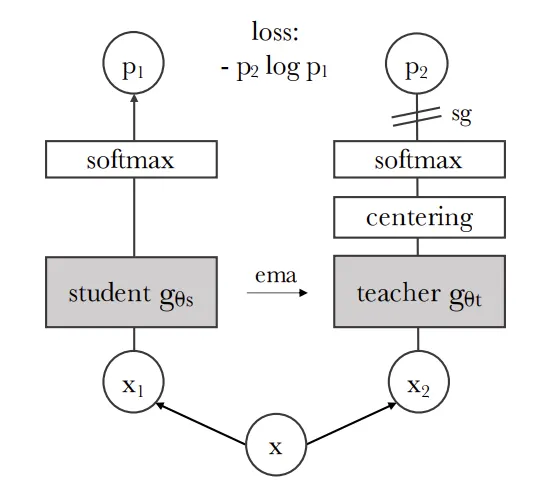
Invaraince-based 방식은 입력 이미지에 변형(augmentation)을 가해도 본질적인 representation은 변하지 않는다는 개념을 이용해서 data augmentation을 적용한 이미지와 원본 이미지와 embedding을 유사하게 학습하는 방식으로 대표적인 예시로 DINO가 있습니다. 해당 방식은 동일한 이미지에 대해서 변형을 가해도 동일한 의미를 갖도록 학습하기 때문에 이미지의 semantic representation을 학습할 수 있습니다. 하지만 위에서 언급한 것처럼 어떤 data augmentation을 쓰느냐에 따라서 bias가 심하게 생깁니다. 또한 이미지의 semantic representation을 학습하기 때문에 clasification에서는 성능이 좋을지 몰라도, segmentation과 같이 물체의 위치를 예측하는 task에서는 의미론적보다는 위치정보를 필요로 하기 때문에 적절하지 않은 사용방식입니다. 또한 audio나 text에서는 어떤 augmentation을 사용할지 모호하다는 단점도 존재합니다.
Genretaive 방식은 인지학적으로 우리뇌가 다음에 뭐가 나올지 예측하면서 똑똑해진다는 점을 이용한 방식으로, AI 모델도 가려진 부분을 예측하게 만드는 방식을 사용했습니다. 이미지의 특정 부분을 제거하거나 손상시킨 뒤 변형되지 않은 부분을 기반으로 변형된 부분을 예측하는 방식을 이용해서 학습을 진행했습니다. 해당 방식은 augmentation을 진행하지 않아 bias가 존재하지 않고, audio나 text에서도 사용할 수 있다는 장점이 존재합니다. 하지만 단순히 픽셀 혹은 패치 단위의 예측을 진행하기 때문에 이미지의 의미론적인 정보를 학습하기 어렵고, invariance-based 방식보다 성능이 안좋습니다.
2개의 방식들 모두 한계점이 명확하기 때문에 Invaraince-base의 semantic representation을 학습시킨다는 장점을 얻으면서도, Generative 방식의 augmentation을 진행시키지 않아서 얻는 2가지 장점을 모두 얻기 위해서 I-JEPA라는 방법을 제시했습니다. 이미지 변형을 가하지 않기 때문에 큰틀은 Generative 방식에서 사용한 특정 부분을 예측하는 방식을 사용하지만, 픽셀이나 패치 단위가 아닌 invariance-based 방식에서 사용한 임베딩이 유사하도록 하는 방식을 사용합니다.
결론적으로 I-JEPA는 generative방식보다 linear probing 성능이 좋다는 점을 통해서 이미지의 의미론적인 정보를 학습할 수 있고, invaraiance-based방식보다 object counting이나 depth prediction과 같은 low-level vision task의 성능이 좋은 것을 통해서 위치(spatial)정보 또한 더 잘 학습하는 것을 알 수 있습니다. 또한 기존 모델들보다 학습 속도가 압도적으로 빠르다는 3가지 점을 기여했습니다. 아래에서 더 자세히 살펴보도록 하겠습니다.
Background
Self-supervised learning은 무엇과 무엇이 어울리는지를 배우는 과정입니다. 이를 수학적으로 정답 쌍의 에너지를 낮추는 EBM(Energy Based Model) 프레임워크로 설명할 수 있습니다. EBM을 통해 간단하게 설명해보면, 정답 데이터 쌍에 대해서는 에너지를 낮추고, 오답 데이터 쌍에 대해서는 에너지를 높이는 것입니다.
Joint-Embedding Architectures
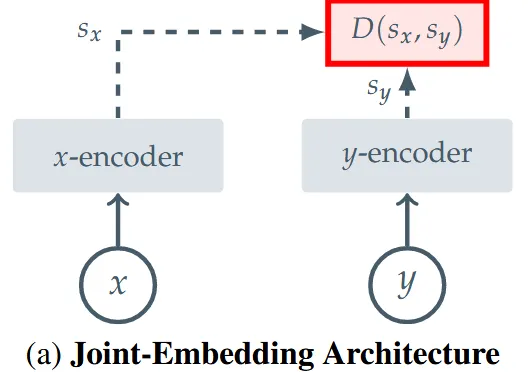
Invariance-base 방식은 Joint-Embedding Architecture (JEA)에 포함됩니다. JEA는 위의 그림과 같이 입력으로 들어온 x와 y에 대해서 Encoder를 통과시켜서 얻은 임베딩을 비교합니다. 두 임베딩 사이의 거리(Distance)가 크면 이미지가 유사하지 않고, 작으면 유사할 것입니다. 따라서 같은 이미지 일 경우 크기를 작게, 다른 이미지일수록 크기를 키우는 방식으로 학습합니다. 이전에 언급한 것처럼 동일한 이미지에 뒤집거나, 다른 뷰를 넣는것처럼 변형을 가하면서 학습을 하는 방식을 사용합니다.
JEA에서 문제가 되는 부분은 표현이 붕괴되는 현상입니다. 동일한 이미지를 넣고, 이 이미지들끼리 거리만 줄이는 것이 목표이기 때문에, Encoder가 생성하는 임베딩이 모두 똑같은 답을 내는 현상이 발생합니다. 다른 이미지를 넣어도 똑같은 임베딩이 생성되는 현상을 표현이 붕괴된다고 합니다. 이를 해결하기 위해서 명시적으로 negative examples을 추가하는 등의 연구들이 진행되었습니다.
Generative Architectures
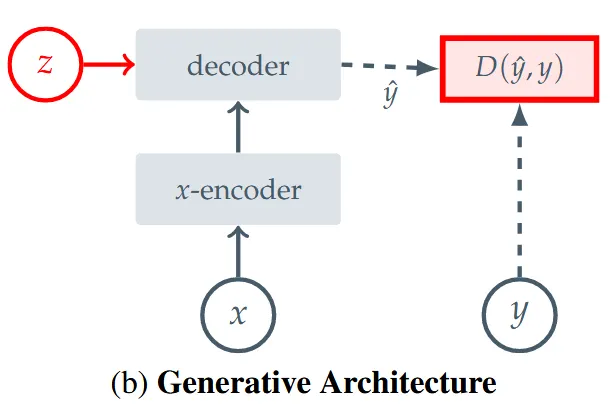
Generative 방식은 입력 x와 추가적인 변수 z를 받아 Decoder를 통해 복원한 와 y의 거리를 비교하는 것입니다. 입력하는 x는 원본 이미지 y에서 특정 부분을 마스크로 가린 이미지이고, 이를 통해서 가리지 않은 부분의 이미지 패치는 encoder를 통해서 패치 임베딩으로 전환되고, 가려진 부분의 위치 정보를 포함한 추가적인 변수 z와 함께 decoder를 통과해서 가려진 부분을 생성한 이미지 를 만듭니다. 가려진 부분을 생성하는 알고리즘이기 때문에 표현이 붕괴되는 현상이 나타나지 않습니다.
Joint-Embedding Predictive Architectures
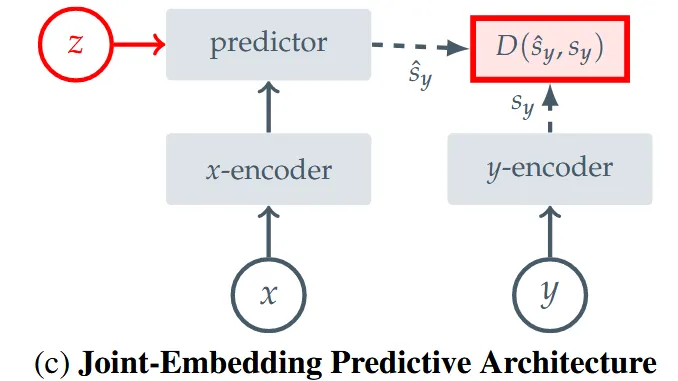
Joint-Embedding predictive 방식의 큰틀은 Generative 방식과 유사하지만, 가장 큰 차이점은 Distance를 구할 때 Decoder를 통과한 이미지가 아니라 임베딩끼리 비교한다는 점입니다. I-JEPA는 Joint-Embedding predictive에서 발생하는 표현 붕괴 현상을 막기 위해서 y-encoder의 가중치를 x-encoder의 EMA으로 업데이트하는 비대칭적인 구조를 활용합니다. EMA는 잘 아시겠지만 쉽게 말해서 y-encoder의 가중치를 천천히 업데이트하겠다는 방식입니다. 이를 통해서 2개의 임베딩 값이 같아지는 표현 붕괴 현상을 막는 것입니다.
Method
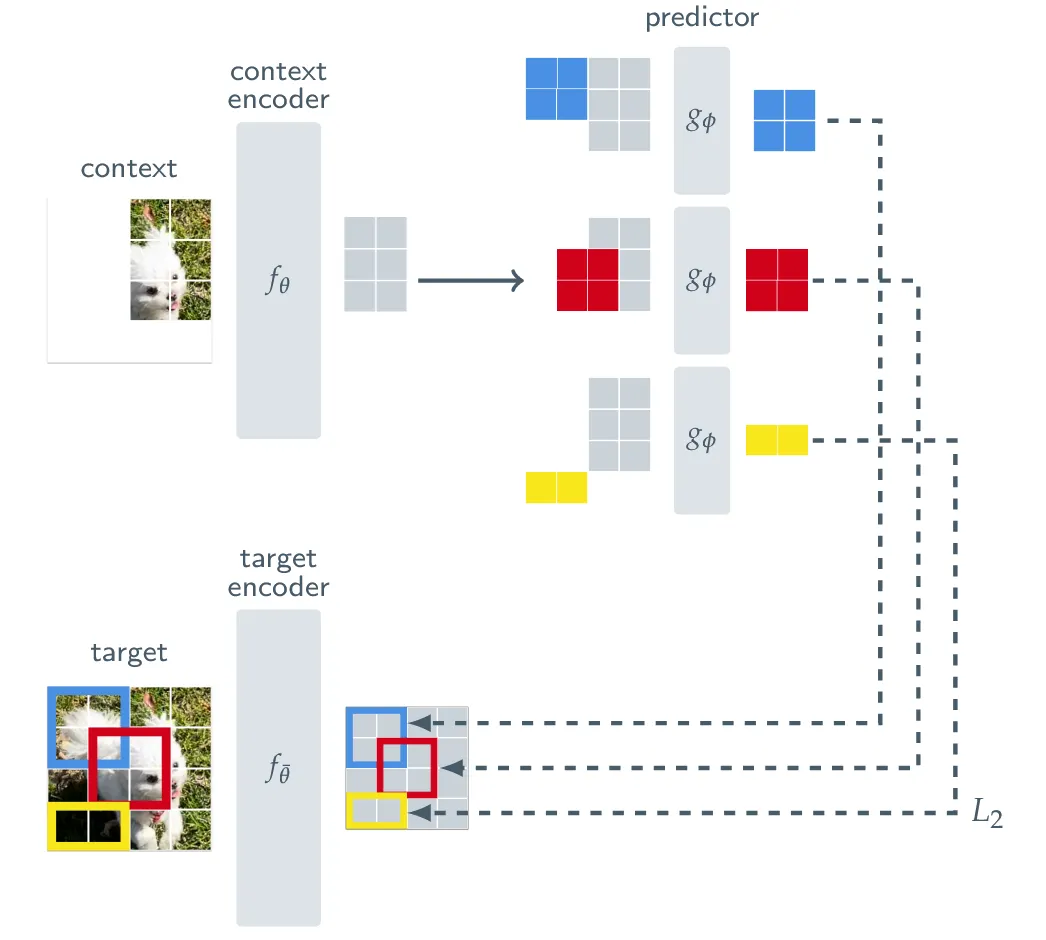
위의 그림과 같이 그림의 일부분이 주어진 context를 이용해서 이미지 전체를 나타내는 target을 예측하는 self-suprevised 방식입니다. Context-encoder, target-encoder, predictor는 모두 ViT 모델을 사용했습니다. Target, Context, Prediction, loss 총 4개의 부분을 나눠서 논문에서 설명한 흐름 그대로 진행하도록 하겠습니다.
Target
입력 이미지 y가 주어지면, 이를 N개의 겹치지 않은 패치들로 나눕니다. 나눠진 N개의 패치들은 target encoder를 통해서 representation 를 얻습니다. 이후에 위의 그림의 빨간색, 파란색, 노란색 박스처럼 랜덤한 박스 M개()를 선택합니다. M은 4를 선택했습니다.
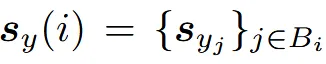
각 박스에는 여러 패치들이 포함되어 있을 수 있기 때문에, 위와 같이 박스에 포함되는 패치들을 정의합니다. 랜덤한 박스의 가로, 세로 비율은 (0.75, 1.5) 사이를 갖도록 하고, 크기는 (0.15, 0.2)사이를 갖도록 설정했습니다.
Context
Context 이미지를 얻기 위해서 랜덤한 (0.85, 1.0)사이의 크기와 가로, 세로가 동일한 비율인 블록을 생성합니다. 이렇게 랜덤하게 생성된 context는 우리가 랜덤하게 생성한 박스와 겹쳐지는 부분이 생길 수 있습니다. 이렇게 겹쳐지는 부분은 학습을 하기위해서 context 블록에서 제거합니다.

위의 그림은 원본 이미지로부터 생성된 context, 그리고 예측해야되는 target들입니다. 처음 생성된 context는 가로 세로 비율이 동일하지만, target과 겹쳐지는 부분을 제거하다 보니 특이한 형태의 mask가 생성됩니다. Context 블록에 해당하는 부분의 패치들만 context-encoder를 통해서 패치 임베딩으로 변환합니다.
Prediction
Context 블록에 해당하는 패치 임베딩을 이용해서 우리는 target 부분의 이미지 임베딩을 예측해야 합니다. 예측해야하는 target의 위치 정보를 포함하는 정보를 condition으로, context블록의 임베딩 값을 입력으로 prediction(ViT)모델에 넣어서, target의 패치 임베딩 값을 예측합니다. Predictor에 입력되는 마스크 토큰들은 positional embedding이 더해진 learnable vector로, 학습을 통해서 target의 패치 임베딩 값이 되도록 설계 되었습니다.
Loss
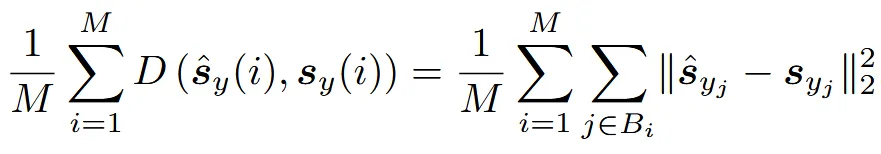
Loss는 M개의 target 마스크에 대해서 각 패치 임베딩의 값을 L2 Loss를 이용해서 최소화하는 방식입니다. Context-encoder와 predictor의 파라미터는 gradient-base optimization을 이용해서 학습되고, target encoder는 EMA 방식을 이용해서 천천히 학습됩니다.
Related Work
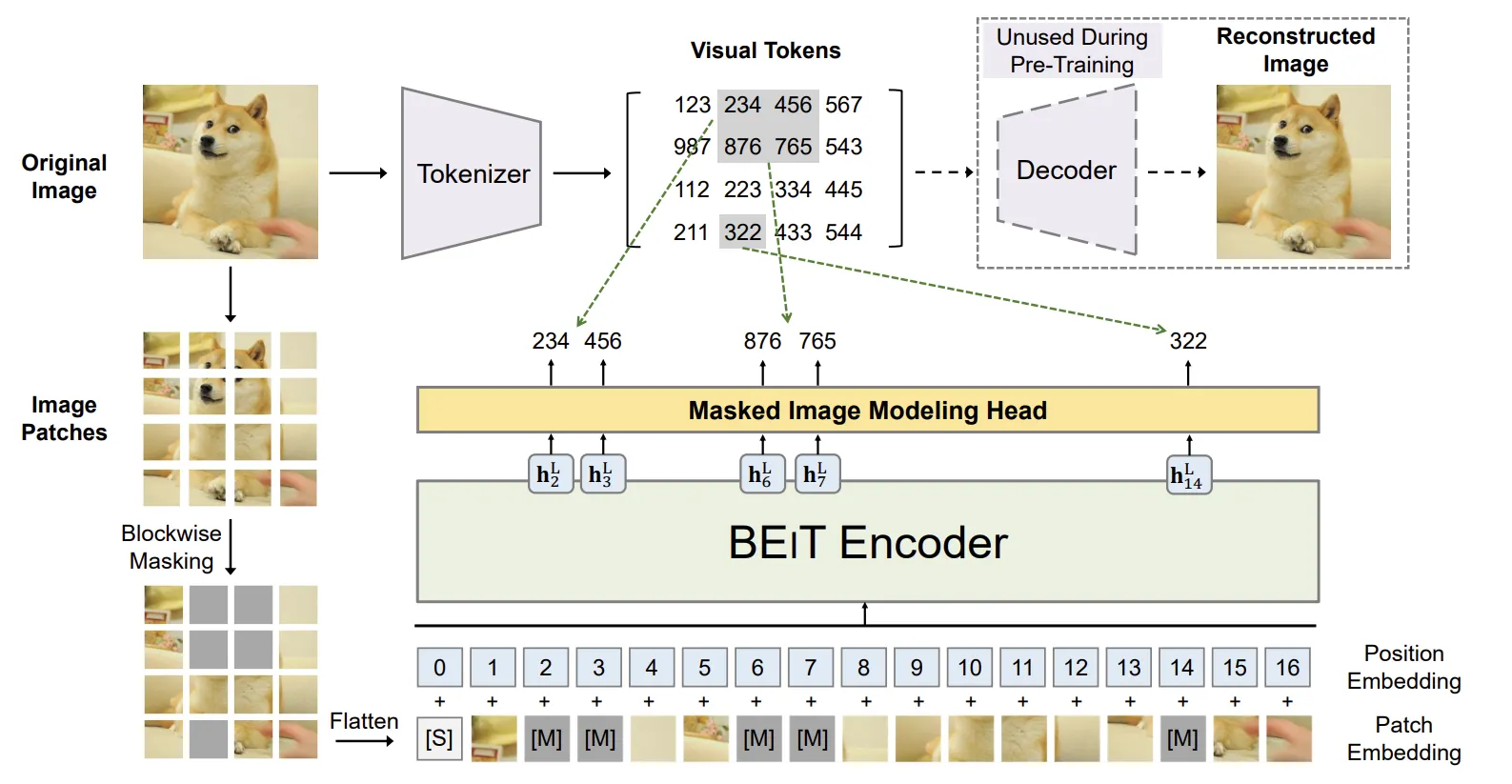
초기 연구는 이미지에 랜덤한 노이즈를 추가해서 이를 복원하는 과정을 통해서 이미지의 의미를 학습하는 방식을 선택했습니다. Vision Trnasformer가 나온 뒤에는 해당 모델을 이용해서 패치의 일부분을 가리는 Masked Autoencoder(MAE) 방식을 사용하도록 바꼈습니다. MAE 방식은 가려진 픽셀을 생성하도록 하는 방식을 사용해서 좋은 성능을 나타냈습니다. BEiT는 픽셀 대신 가려진 패치가 어떤 패치인지 분류하는 모델로 이를 수정했지만, 픽셀 단위 예측보다 성능이 떨어진다는 단점이 존재했습니다.
이러한 방법들과 달리 I-JEPA는 임베딩 자체를 예측해서 Fine-tuning 의존도를 낮추는 것을 목표로 합니다. I-JEPA와 가장 유사한 모델로는 data2vec과 Context Autoencoders가 있습니다. 특히 data2vec은augmentation을 피하고자 Online Target Encoder를 통해 마스킹된 패치의 임베딩을 예측한다는 점에서 I-JEPA와 작동 방식이 비슷합니다. 하지만 I-JEPA는 이들보다 계산 비용이 낮고, 더 좋은 semantic 성능을 냅니다. 이러한 결과는 기존 모델들은 임베딩 값 자체를 곧바로 예측하지만, I-JEPA는 predictor를 통해서 예측하도록 설계한 점이 가장 큰 차이점이라고 생각합니다.
Image Classification
다양한 이미지 분류 작업을 수행하면서 I-JEPA의 성능을 입증했습니다. 각 모델들은 ImageNet-1K 데이터셋을 이용해서 학습을 진행했고, 자세한 사항은 Appendix A를 참조하시면 됩니다.
ImageNet-1K
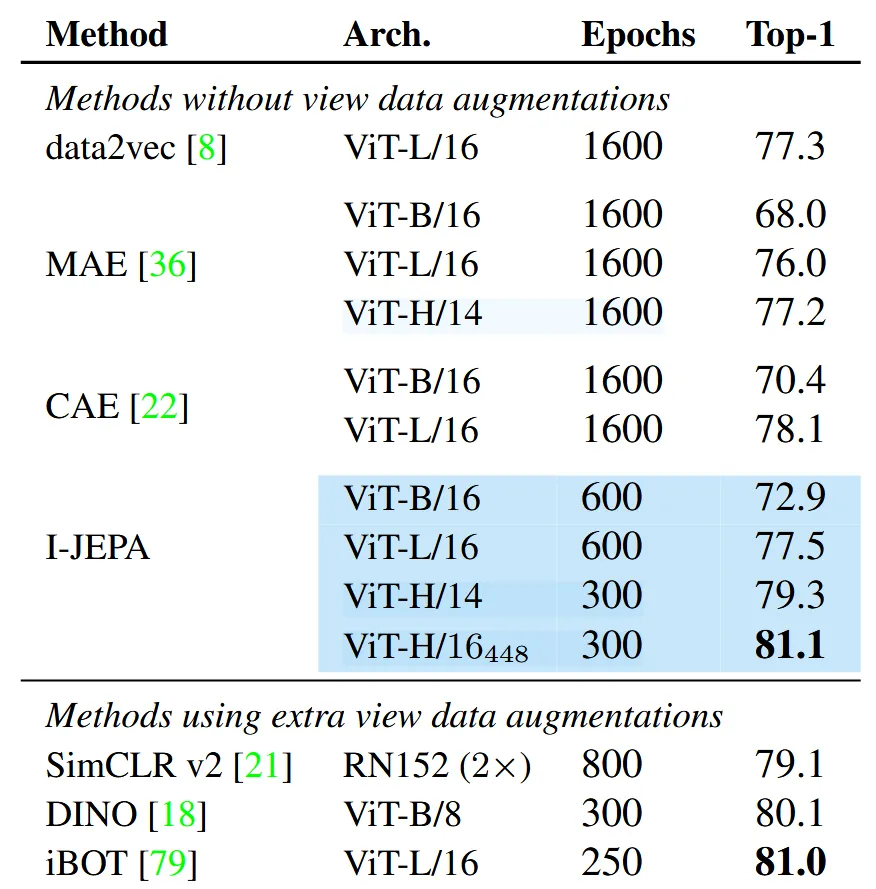
Augmentation을 사용하지 않는 모델들과 ImageNet-1K 밴치마크 데이터셋에 대해서 비교해본 결과 I-JEPA의 성능이 학습한 epoch의 수가 더 적음에도 불구하고 성능이 좋은 것을 윗부분을 통해서 확인할 수 있습니다.
Low-Shot ImageNet-1K
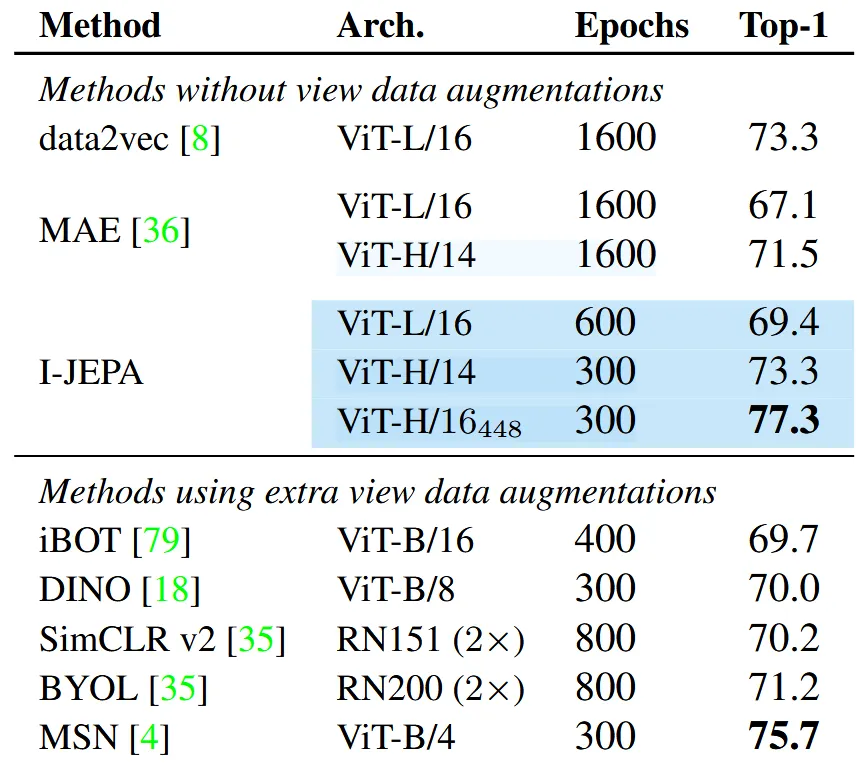
Class당 12, 13개의 이미지만을 사용하면서 ImageNet의 1% 데이터셋만을 학습했을 때의 성능을 비교한 결과입니다. 해당 비교과정 역시 I-JEPA가 기존 모델들보다 성능이 증가한 것을 확인할 수 있습니다. 기존 Augmentation을 이용한 아래 방법들보다도 해상도를 448도 올렸을 때 성능이 좋은 것을 확인할 수 있습니다.
Transfer learning
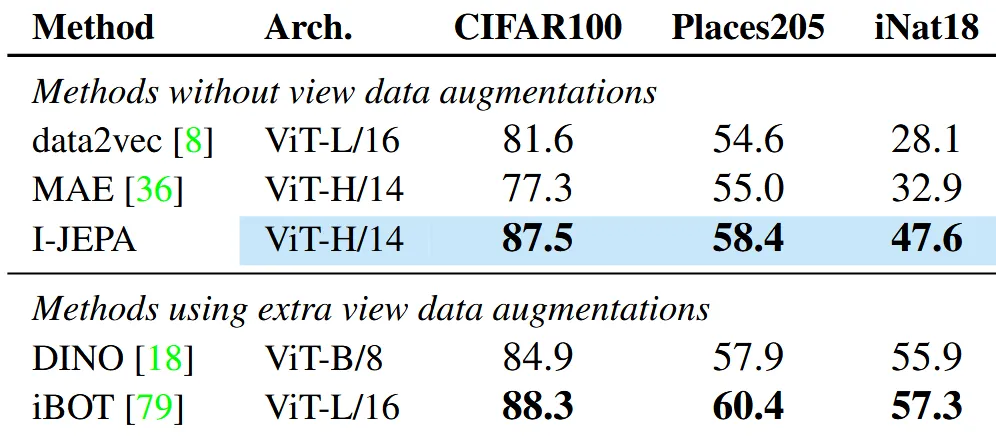
ImageNet을 제외한 다른 밴치마크랑 비교한 결과 augmentation을 진행하지 않은 모델들보다는 성능이 앞도적으로 증가한 것을 확인했고, augmentation을 한 모델보다는 성능이 약간 떨어지는 것을 확인할 수 있습니다.
Local Prediction Tasks
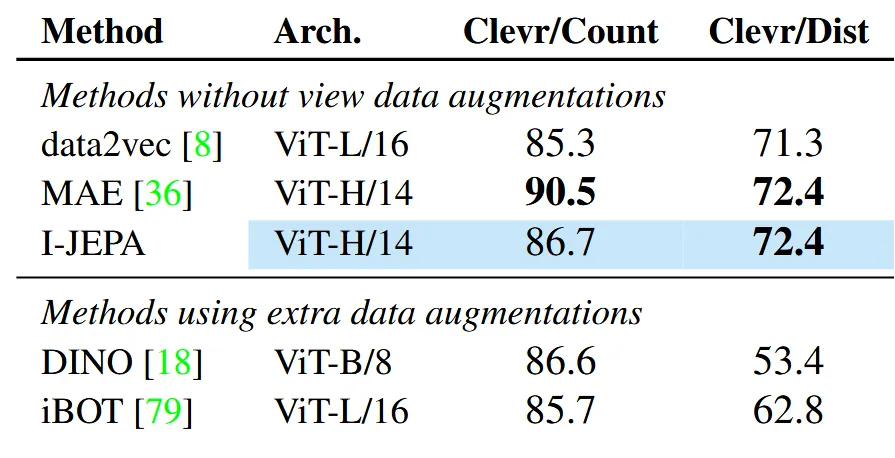
위의 표는 이미지 분류 비교뿐만아니라 object conunting이나 depth prediction에서도 좋은 성능이 나오는 것을 보여주는 것입니다. Encoder부분은 고정시키고 object conunting과 depth prediction을 위해서 linear model을 Clever dataset으로 학습한 결과입니다. Object counting에서는 성능이 비슷하거나 오히려 MAE가 조금 더 높고, depth prediction부분에서도 비슷하지만 그래도 가장 높은 성능이 보임을 통해서 다른 분야에서도 좋은 성능을 나타낸다고 확인할 수 있습니다.
Scalability
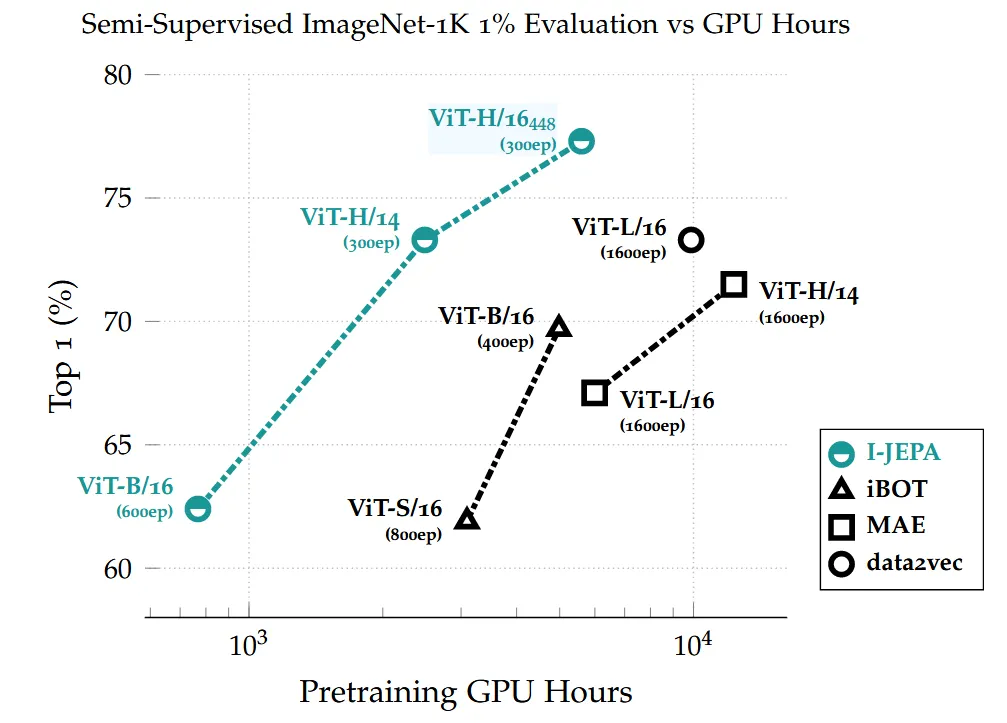
성능 비교가 압도적이지 않아도 I-JEPA가 많이 사용되고 유명한 이유는 계산의 효율성 때문이라고 생각합니다. 위와 같이 ImageNet-1K의 1% 데이터는 학습시키는데 걸리는 시간이 다른 모델들보다 적다고 언급했는데, 가장 큰 이유가 학습하는 epoch수 자체가 300으로 가장 적기 때문이라고 생각합니다. 적은 수의 epoch에도 불구하고 성능은 기존 모델들보다 좋은 것을 확인할 수 있습니다.

학습하는 데이터의 크기가 커질수록 성능이 증가한다는 것을 통해, scalability 측면에서도 좋다는 것을 입증했습니다(첫번째 두줄 비교). 그리고 모델의 크기가 커질 때 Classification task(Place205, INat18)에서 성능이 증가한다는 것 역시 입증했습니다(아래 두줄 비교).
Predictor Visualizations

Condition으로 들어가는 위치 정보를 모델이 잘 이해하고 있는지 시각화를 통해서 확인하는 부분입니다. 초록색 네모친 영역에 대한 위치정보를 넣고, 다양한 랜덤시드로 모델이 해당 부분을 예측한 결과를 시각화한 것입니다. 결과를 통해서 모델이 위치정보를 기반으로 객체의 부위나 포즈를 정확히 예측할 수 있음을 알 수 있습니다.
Ablations

ImageNet-1K의 1% 데이터셋만을 이용해서 학습할 때 서로다른 loss를 사용했을 때 결과를 비교한 표입니다. Pixels는 기존의 방법처럼 Predictor가 예측한 임베딩을 decoder를 통해서 이미지로 만들고, 이를 원본 이미지와 픽셀 단위로 비교해서 Loss를 계산하는 방식이고, Target-Encoder Output은 I-JEPA에서 제안한 임베딩 공간상에서 비교를 통해서 Loss를 계산하는 방식입니다. 성능차이가 1.5배 이상 차이나는 것을 통해서 임베딩 공간상에서 비교하면서 학습하는 방식이 더 적절한 것을 알 수 있습니다.
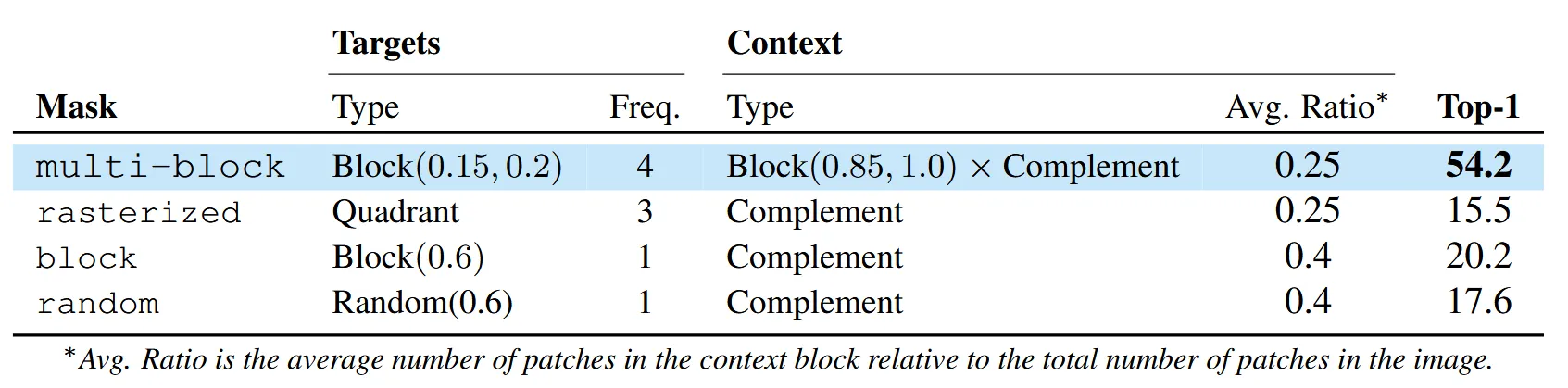
마스크를 어떻게 생성하느냐에 따라서 성능 차이를 보여줍니다. Multi-block은 I-JEPA에서 사용하는 방식으로 block의 크기를 특정 제약조건에 맞게 생성하고, 겹치는 부분은 제거하는 Complement 방식을 사용했습니다. Rasterized는 4개의 영역으로 나눠서 1개의 영역만을 보여주고 나머지 부분을 예측하는 방식으로 가장 낮은 성능을 기록했습니다. Block은 I-JEAP와 유사하지만 다른 제약조건을 사용한 결과이고, Random은 block이 아닌 말 그대로 픽셀단위에서 랜덤하게 생성한 결과입니다. 확실히 특정 제약조건을 사용한 multi-block 방식이 가장 높은 성능을 기록한 것을 확인할 수 있습니다.
Conclusion
Data augmentation을 사용하지 않고도 의미론적으로 우수한 표현을 학습하며, 기존 모델 대비 계산 비용을 획기적으로 절감했습니다. 임베딩 공간에서의 예측이라는 간단한 아이디어를 통해, I-JEPA는 Invariance-based을 넘어 Joint-Embedding Architecture가 나아가야 할 범용적인 학습의 길을 제시했습니다.
