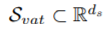
논문을 읽게된 이유
최근에 계속 contrastive loss관련해서 의문점이 생겨 이에대한 논문들을 읽고있다. 특히 서로다른 모달리티(예를들어 이미지, 텍스트, 오디오)를 하나의 공간에 joint embedding space를 해야될까 라는 의문이 생겼고, 만약에 해야한다면 어떻게 해야되는걸까 라는 생각을 하다가 이 논문에서 제시한 방법론을 따라가야겠다고 판단이 들어 자세히 읽어보게 되었다.
Fine-grained vs Coarse-grained
위의 내가 궁금한 점에서 적은 것처럼 각각의 모달리티들을 vector space에 보내기 위해서 simple doct products를 이용한다고 나와있다.
이를 통해서 visual, audio, text가 하나의 spacce로 모인다는 것이다. 여기서 주목해야 될점은 visual,audio데이터와 text데이터가 다르다는 점이다. visual과 audio 데이터들은 fine-grained이지만, text데이터는 coarse-grained된다.
여기서 말하는 fine-grained는 세부적인 특성이나 정보를 많이 포함한다는 것이고 coarse-grained는 덜 세부적이거나 더 일반적인 특성을 나타낸다.
=>개인적으로 여기서 내가 들었던 의문점은 CLIP에서는 image와 text를 contrastive loss를 이용해서 활용하는데 그때의 결과는 잘나왔다. 이 논문에서는 fine-grained, coarse-grained로 다르다고 했는데 말이다.
각 모달리티 별 데이터 사용방법
RGB stream video: few-second sequence of RGB frames
audio track: 1D audio samples
some linguistic narrations: discrete word tokens
Shared Space
논문에서는 3가지 방법을 제시하고 그중에서 왜 FAC방법을 선택했는지 설명하는 방식을 택했다. 그중 선택하지 않은 첫번째 방법 Shared Space는 모든 모달리티 정보를 하나의 공간으로 임베딩 시킨다.
장점: 비교가 용이하다
단점: 각 모달리티의 구체적인 정보 손실.
(서로 다른 모달리티의 정보들을 하나의 공간으로 임베딩 시키다 보니 차원이 바뀌면서 구체적인 정보 손실 발생)
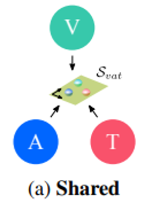
Disjoint space
2번째 사용하지 않은 방법으로 Disjoint space를 제시했다.
2가지 공간(visual-audio / visual - test) 사용
장점: shared에 비해 구체적인 정보 손실 적다.
단점: audio-text mapping 어렵다.
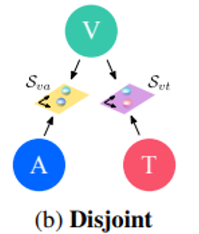
FAC(Fine and coarse spaces)
마지막으로 이 논문에서 사용한 FAC방법이다.
우선 visual과 audio는 위에서 말한것처럼 fine-grained이기 때문에 2가지 정보를 하나의 공간으로 통일시켜 학습시킨다. 이후 학습된 정보를 coarse-grained 정보를 담고있는 text와 합쳐서 최종 결론을 내린다.
모델 설명
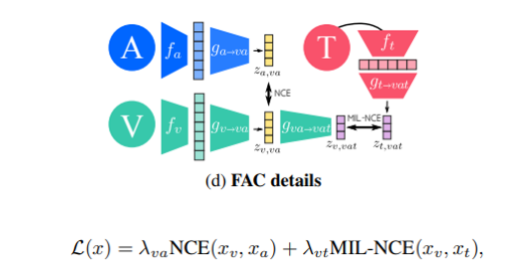
대략적인 그림은 (d)의 그림과 같다. 우선 오디오와 비디오가 각각 인코더를 통과한후 va차원에 임베딩 시켜 NCE Loss를 계산한다. 이후 텍스트 데이터를 인코더를 통과시키고 vat차원으로 임베딩. NCE Loss를 계산한 값도 vat차원으로 임베딩 시켜 최종적으로 MILNCE Loss를 이용한다.
여기서 NCE Loss와 MILNCE Loss의 차이점을 간단하게 설명해보겠다. 쉽게 말해서 그냥 다양성으로 인해 생기는 차이이다.
NCE Loss(visual and audio)
->특정 시각적 장면이나 객체와 관련된 소리는 일반적으로 구체적이고 명확하다. 예를들어 사진에서 강아지가 짖고있으면 강아지 짖는 소리가 나온다
MILNCE Loss(visual+ audio and text)
→반면 특정 시각적 내용을 기술하는 방법은 다양할 수 있으며, 같은 시각적 장면에 대한 다양한 텍스트 설명이 그낭하다. 예를들어 해가 지는 장면을 "해변에서의 일몰” "노을이 바다에 비치는 모습” “해가 진다” 라고 다양하게 표현할 수 있으므로 다양성으로 인해 여러 인스턴스 간의 유사성을 평가하는 것이 더 적합하다.
cf. Info-NCE Loss(CLIP) vs NCE
NCE는 주어진 데이터와 노이즈 데이터(가상 데이터)를 구별하는 데 중점을 두는 반면, InfoNCE Loss는 주어진 데이터 쌍에서 일치하는 이미지와 텍스트를 구별하는 데 중점을 둡니다.
동적이미지 비디오 = 정적 이미지(?)
논문에서는 동적이미지인 비디오와 정적 이미지를 동등하게 처리하기 위한 방법으로 2가지를 제시했다.
1.3D convolutional based networks: 비디오를 처리하는 네트워크 아키텍처를 변경하여 3Dconv연산 대신 2D conv 연산을 사용.
2.TSM networks: TSM을 비활성화. 이렇게하면 이미지 처리에 표준적으로 사용되는 아키텍처가 사용
하지만 zero-padding때문에 우리가 원하는 결과 x(단일 이미지 정적 비디오에서는 수용 영역이 클립 경계를 벗어나는 부분에 대해 제로 패딩이 적용되고, 이러한 사실이 간단한 축소 작업에 반영되지 않기 때문에 원하는 동등성이 달성되지 않는다.)
->γ and β 배치 정규화 레이어에서 사용되는 매개변수를 사용해서 해결. L1을 줄이려고 노력한다. 이 손실은 단일 이미지 정적 비디오를 입력으로 받았을 때 원래 비디오 네트워크의 출력과 동일한 이미지에 대해 축소된 네트워크의 출력 사이의 차이를 측정한다.
마무리
3가지 모달리티를 하나의 차원으로 embedding시키는 방법은 제시해 줘서 내가 하고싶은 모델 만들기(3가지 contrastive learning)는 가능할거같지만 fine-grained와 coarse-grained부분에 대해서 알게되면서 오히려 이 부분에 의문이 생긴거같았다.
