논문 링크
샘플 링크

Shap-E 모델은 conditional generative model for 3D assets입니다. 기존 모델들의 출력값이 하나의 3D representation이였다면, Shap-E는 텍스처된 mesh와 neural radiance fields를 표현할 수 있는 implicit function을 출력값으로 지정합니다.
훈련 단계는 크게 2단계로 나누어져 있습니다.
- 3D asset을 표현할 수 있는 implicit function의 파라미터를 나타내는 encoder를 학습
- encoder의 출력값을 conditional diffusion model으로 학습
1단계
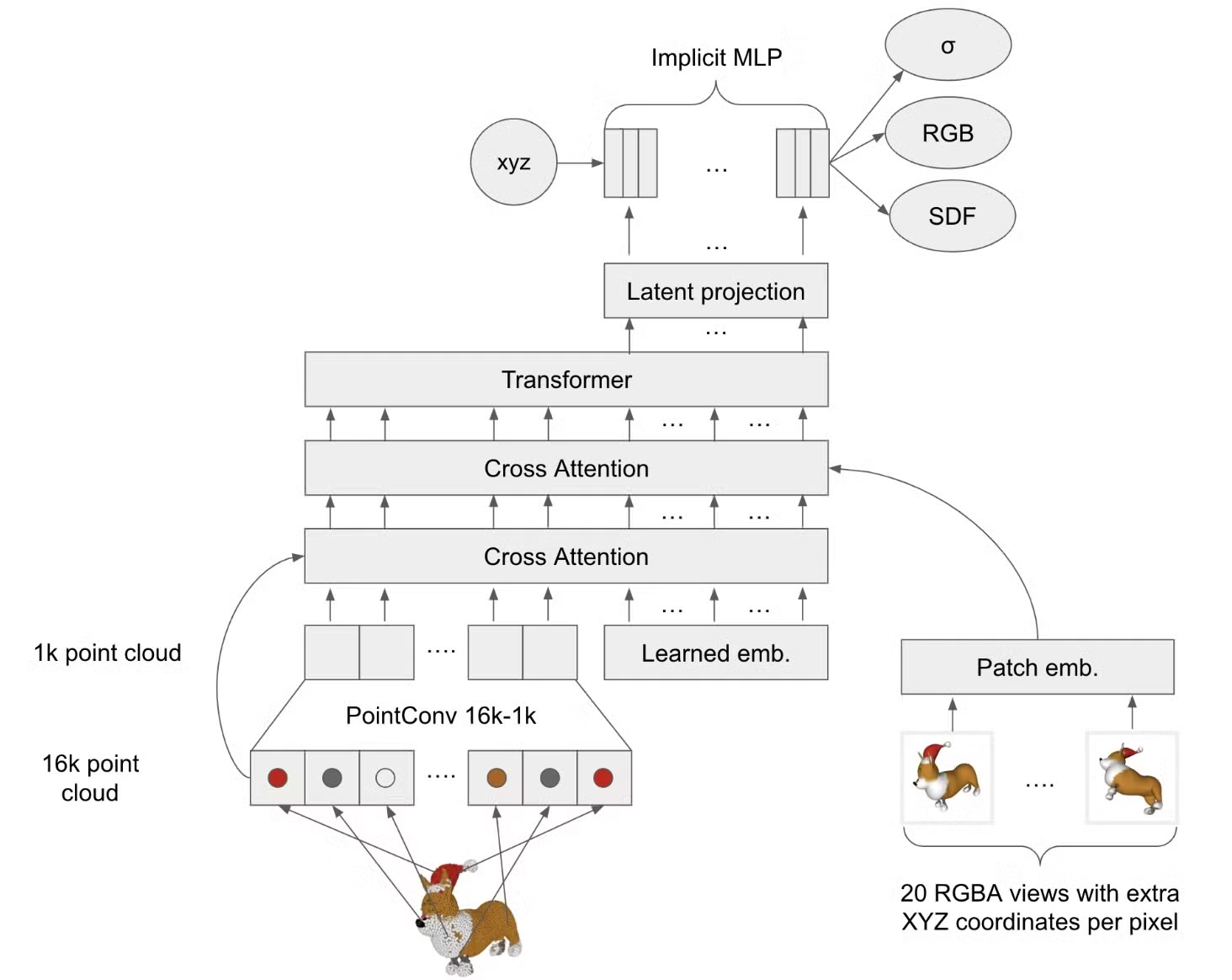
입력값: 3D point clouds + rendered views of a 3D asset
출력값: MLP의 가중치 행렬 (이때의 MLP는 NeRF에서 사용하는 MLP라고 생각하시면 됩니다.)
Transformer의 하나의 출력값은 벡터 형태인데, 이 벡터는 고차원이기때문에 이를 저차원으로 변환해주는 Latent Projection을 거치면 다시 저차원 벡터로 변환됩니다. 이 저차원 벡터가 MLP Weight의 하나의 row라고 생각하시면됩니다. 예를들어서 Transformer의 출력이 512차원이고, Latent Projection(linear layer)를 거쳐서 128차원의 벡터로 변환되면 이 128차원의 벡터고 MLP Weight의 첫번째 row값입니다.
Encoder는 NeRF로만 pre-training 시켰습니다. 이는 NeRF가 mesh-based objectives를 optimize하는데 가장 안정적이기 때문입니다. pre-training 이후에 SDF와 texture color projection을 추가했습니다.
Decoding with NeRF Rendering
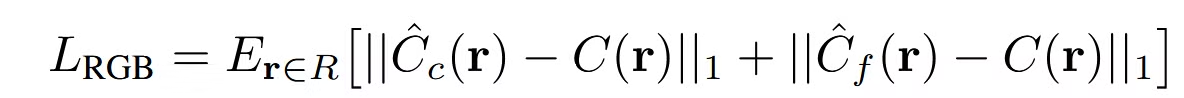
NeRF의 방식과의 유일한 차이점은 coarse와 fine model의 파라미터를 공유하지 않는다는 점입니다.(즉 서로다른 MLP를 사용하고 있는 것입니다.) 4096개의 ray를 이용해서 L1 loss를 최소화 합니다.
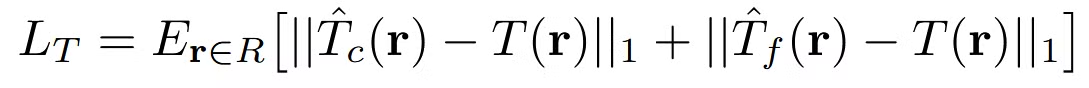
추가 Loss: 각각의 ray에 transmittance(투과율)에 관한 loss
ground-truth(T(r))에 대해서 coarse와 fine model모두 투과율이 비슷해지도록 학습을 진행
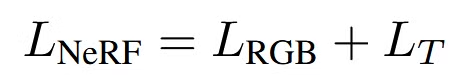
최종적으로 2개의 Loss를 더한 것이 NeRF를 pre-training할 때 사용한 Loss입니다.
Decoding with STF Rendering
NeRF로 pre-training을 한 뒤 추가적인 STF output heads(SDF + Texture)를 통해서 SDF 값과 texture colors를 예측합니다.(MLP 구조는 동일하고 추가적인 출력값만 생성하도록 설정)
SDF 값을 이용해서 Marching cubes 33를 적용한 결과 삼각형 mesh를 생성합니다.이후 생성된 mesh에 대해서 texture color head를 이용해서 mesh의 color를 예측합니다.
pytorch3D 라이브러리를 통해서 mesh와 texture를 렌더링합니다. 이전에 말했던 것처럼, 모든 방향에서 동일한 조명 설정을 진행했습니다.
STF ouput head는 처음에 불안정하기 때문에 distillation을 이용해서 학습을 시작합니다. SDF는 Point-E를 기반으로, texture color는 근처 point cloud의 RGB값을 기반으로 distillation을 진행합니다.

STF 렌더링시에 L1은 부적절해서 L2 Loss를 사용했습니다.

STF가 안정적으로 distillation을 진행하면 NeRF에서부터 다시 end-to-end의 학습을 진행합니다.
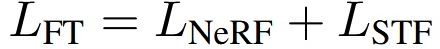
이 부분에서 개인적으로 안정적으로 학습됐다는 기준이 없어서 헷갈렸지만, 해당 부분에 대한 설명은 논문에 없어서 넘어가도록 하겠습니다.
Latent Diffusion
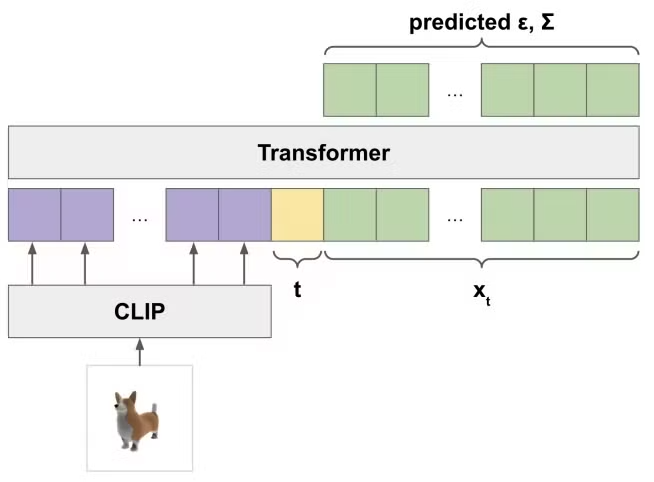
Point-E에서 사용한 transformer-based 아키텍처를 사용했지만 point clouds대신 latent vectors를 사용했습니다(위의 그림은 Point-E의 모델 아키텍처). 입력값으로 들어가는 latent vectors는 MLP weight metrices(1024x1024)입니다. 사용방식은 Point-E와 동일하게 적용했습니다.
일반적으로 diffusion model에서 위에 보이는 것처럼 노이즈를 예측하지만, (원래 데이터)를 직접 예측하는 것이 더 일관된 샘플을 생성하는 것으로 나타나 를 예측하도록 설계했습니다.
코드정리
PointConv 16k-1k
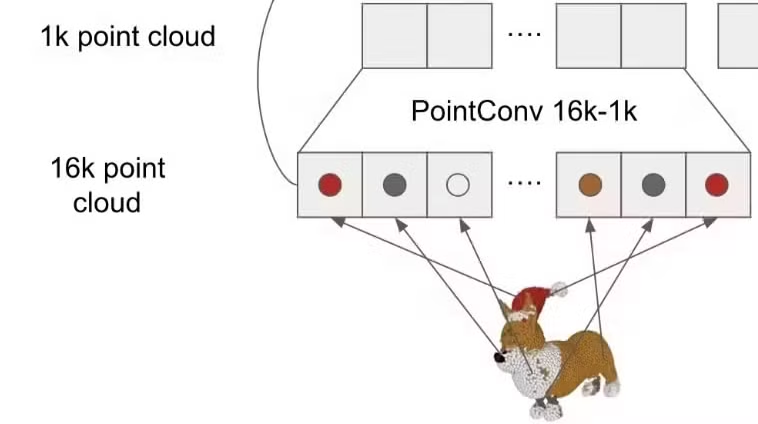
FPS(Farthest Point Sampling)
목표: 16K → 1K point cloud의 개수를 줄이자!
경로: shap-e/shap_e/models/transmitter/channels_encoder.py
def sample_pcl_fps(points: torch.Tensor, data_ctx: int, method: str = "fps") -> torch.Tensor:
"""
Run farthest-point sampling on a batch of point clouds.
:param points: batch of shape [N x num_points].
:param data_ctx: subsample count. (Maybe 1K)
:param method: either 'fps' or 'first'. Using 'first' assumes that the
points are already sorted according to FPS sampling.
:return: batch of shape [N x min(num_points, data_ctx)].
"""
n_points = points.shape[1] # 배치당 point cloud 개수 (Maybe 16K)
if n_points == data_ctx:
return points
if method == "first":
return points[:, :data_ctx]
elif method == "fps":
batch = points.cpu().split(1, dim=0) # points를 배치별로 나눈다
fps = [sample_fps(x, n_samples=data_ctx) for x in batch] # 배치별로 sample_fps 함수(아래 정리) 실행
return torch.cat(fps, dim=0).to(points.device) # 다시 배치로 합치고 GPU로 변환
else:
raise ValueError(f"unsupported farthest-point sampling method: {method}")경로: shap-e/shap_e/models/transmitter/channels_encoder.py
def sample_fps(example: torch.Tensor, n_samples: int) -> torch.Tensor:
"""
:param example: [1, n_points, 3 + n_channels]
:return: [1, n_samples, 3 + n_channels]
"""
points = example.cpu().squeeze(0).numpy() # 첫번째 차원(배치 1) 제거 -> (n_points, 3 + n_channels)
coords, raw_channels = points[:, :3], points[:, 3:] # 좌표 정보(x,y,z)와 추가정보 분리
n_points, n_channels = raw_channels.shape # 추가 정보의 채널 수 파악
assert n_samples <= n_points # 출력 point cloud 개수가 들어오는 개수보다 크면 오류 발생
channels = {str(idx): raw_channels[:, idx] for idx in range(n_channels)} # 추가 정보를 채널별로 리스트 형태 저장
max_points = min(32768, n_points) # 최대 샘플링 포인트 수 지정
fps_pcl = (
PointCloud(coords=coords, channels=channels) # 좌표와 채널 정보 사용해 PointCloud 객체 생성
.random_sample(max_points) # 최대 개수만큼 샘플링
.farthest_point_sample(n_samples) # FPS 알고리즘(아래 설명)을 적용해 n_samples개의 포인트를 선택
)
fps_channels = np.stack([fps_pcl.channels[str(idx)] for idx in range(n_channels)], axis=1) # 선택된 point들의 채널 정보를 가져옵니다
fps = np.concatenate([fps_pcl.coords, fps_channels], axis=1) # 다시 좌표와 추가 정보를 합칩니다 -> (n_samples, 3 + n_channels)
fps = torch.from_numpy(fps).unsqueeze(0) # 배치 차원 추가하고 torch 형태로 변환
assert fps.shape == (1, n_samples, 3 + n_channels)
return fps의문: 왜 max_points = min(32768, n_points) 이부분에서 최대 샘플링 포인트 수 지정?
→ 아래에 나오는데 시간을 줄이기 위해서
경로: shap-e/shap_e/rendering/point_cloud.py
한줄 요약: 가장 멀리 떨어진 포인트들을 선택하는 과정
def farthest_point_sample(
self, num_points: int, init_idx: Optional[int] = None, **subsample_kwargs
) -> "PointCloud":
"""
Sample a subset of the point cloud that is evenly(고르게) distributed in space.
First, a random point is selected. Then each successive point is chosen
such that it is furthest from the currently selected points.
The time complexity of this operation is O(NM), where N is the original
number of points and M is the reduced number. Therefore, performance
can be improved by randomly subsampling points with random_sample()
before running farthest_point_sample().
:param num_points: maximum number of points to sample.
:param init_idx: if specified, the first point to sample.
:param subsample_kwargs: arguments to self.subsample().
:return: a reduced PointCloud, or self if num_points is not less than
the current number of points.
"""
if fps_cuda:
with torch.no_grad(): # 학습이 필요 없는 과정
indices = fps(torch.Tensor(self.coords).cuda().unsqueeze(0), num_points)
indices = indices.squeeze().cpu().numpy()
else:
num_points = int(num_points/4) # CPU를 사용하면 오래 걸려서 4배로 나눈다
if len(self.coords) <= num_points:
return self
# 첫번째 포인트 선택
init_idx = random.randrange(len(self.coords)) if init_idx is None else init_idx
indices = np.zeros([num_points], dtype=np.int64)
indices[0] = init_idx
# 각 포인트에 대한 거리 미리 계산
sq_norms = np.sum(self.coords**2, axis=-1)
def compute_dists(idx: int):
# Utilize equality: ||A-B||^2 = ||A||^2 + ||B||^2 - 2*(A @ B).
return sq_norms + sq_norms[idx] - 2 * (self.coords @ self.coords[idx])
cur_dists = compute_dists(init_idx)
for i in range(1, num_points):
idx = np.argmax(cur_dists) # 가장 멀리 떨어진 포인트
indices[i] = idx
# Without this line, we may duplicate an index more than once if
# there are duplicate points, due to rounding errors.
cur_dists[idx] = -1 # 중복 방지를 위해 -1로 설정
cur_dists = np.minimum(cur_dists, compute_dists(idx)) # 모든 포인트가 지금까지 선택된 포인트들 중 가장 가까운 포인트와의 거리가 저장
indices = np.concatenate([indices, np.random.choice(len(self.coords), size=(num_points*3,), replace=False)])
return self.subsample(indices, **subsample_kwargs)PointConv
경로: shap-e/shap_e/models/nn/ops.py
한줄요약: 1K로 샘플링 된 점들에 대해서 이웃한 점들을(어떠한 radius 기준으로 안쪽에 있는 점들을) Conv 입력으로 넣어서 Transformer의 입력 벡터 형태로 변환
class PointSetEmbedding(nn.Module):
def __init__(
self,
*,
radius: float,
n_point: int,
n_sample: int,
d_input: int,
d_hidden: List[int],
patch_size: int = 1,
stride: int = 1,
activation: str = "swish",
group_all: bool = False,
padding_mode: str = "zeros",
fps_method: str = "fps",
**kwargs,
):
super().__init__()
self.n_point = n_point
self.radius = radius
self.n_sample = n_sample
self.mlp_convs = nn.ModuleList()
self.act = get_act(activation)
self.patch_size = patch_size
self.stride = stride
last_channel = d_input + 3
for out_channel in d_hidden:
self.mlp_convs.append(
nn.Conv2d(
last_channel,
out_channel,
kernel_size=(patch_size, 1),
stride=(stride, 1),
padding=(patch_size // 2, 0),
padding_mode=padding_mode,
**kwargs,
)
)
last_channel = out_channel
self.group_all = group_all
self.fps_method = fps_method
def forward(self, xyz, points):
"""
Input:
xyz: input points position data, [B, C, N]
points: input points data, [B, D, N]
Return:
new_points: sample points feature data, [B, d_hidden[-1], n_point]
"""
xyz = xyz.permute(0, 2, 1)
if points is not None:
points = points.permute(0, 2, 1)
if self.group_all:
new_xyz, new_points = sample_and_group_all(xyz, points)
else:
new_xyz, new_points = sample_and_group(
self.n_point,
self.radius,
self.n_sample,
xyz,
points,
deterministic=not self.training,
fps_method=self.fps_method,
)
# new_xyz: sampled points position data, [B, n_point, C]
# new_points: sampled points data, [B, n_point, n_sample, C+D]
new_points = new_points.permute(0, 3, 2, 1) # [B, C+D, n_sample, n_point]
for i, conv in enumerate(self.mlp_convs):
new_points = self.act(self.apply_conv(new_points, conv))
new_points = new_points.mean(dim=2)
return new_points
def apply_conv(self, points: torch.Tensor, conv: nn.Module):
batch, channels, n_samples, _ = points.shape
# Shuffle the representations
if self.patch_size > 1:
# TODO shuffle deterministically when not self.training
_, indices = torch.rand(batch, channels, n_samples, 1, device=points.device).sort(dim=2)
points = torch.gather(points, 2, torch.broadcast_to(indices, points.shape))
return conv(points)Multiview → Patch Emb
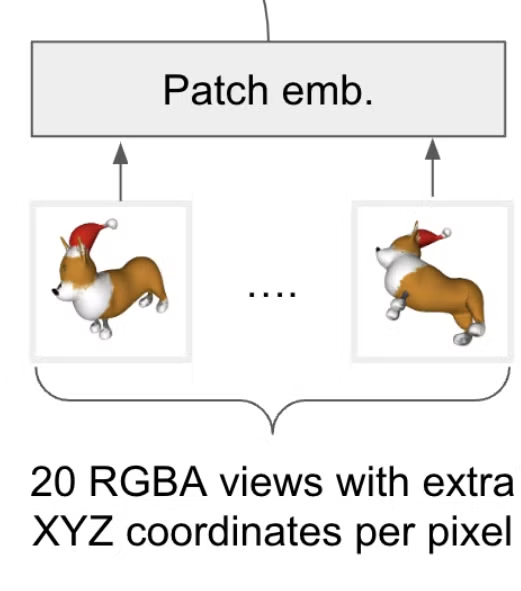
경로: shap-e/shap_e/models/transmitter/multiview_encoder.py
한줄 요약: 이미지와 해당 이미지를 렌더링할 때 camera view 정보를 임베딩값으로 변환
def encode_to_vector(self, batch: AttrDict, options: Optional[AttrDict] = None) -> torch.Tensor:
_ = options
all_views = self.views_to_tensor(batch.views).to(self.device) # 멀티뷰 이미지를 텐서로 변환
if self.use_depth:
all_views = torch.cat([all_views, self.depths_to_tensor(batch.depths)], dim=2)
all_cameras = self.cameras_to_tensor(batch.cameras).to(self.device) # 카메라 메트릭스를 텐서로 변환
batch_size, num_views, _, _, _ = all_views.shape
views_proj = self.patch_emb(
all_views.reshape([batch_size * num_views, *all_views.shape[2:]])
)
views_proj = (
views_proj.reshape([batch_size, num_views, self.width, -1])
.permute(0, 1, 3, 2)
.contiguous()
) # [batch_size x num_views x n_patches x width]
cameras_proj = self.camera_emb(all_cameras).reshape([batch_size, num_views, 1, self.width])
h = torch.cat([views_proj, cameras_proj], dim=2).reshape([batch_size, -1, self.width])
h = h + self.pos_emb
h = torch.cat([h, self.output_tokens[None].repeat(len(h), 1, 1)], dim=1)
h = self.ln_pre(h)
h = self.backbone(h)
h = self.ln_post(h)
h = h[:, self.n_ctx :]
h = self.output_proj(h).flatten(1)
return h경로: shap-e/shap_e/models/transmitter/multiview_encoder.py
한줄 요약: 이미지를 텐서로 변환
def views_to_tensor(self, views: Union[torch.Tensor, List[List[Image.Image]]]) -> torch.Tensor:
if isinstance(views, torch.Tensor): # 이미 텐서 형태인 경우 반환
return views
tensor_batch = []
for inner_list in views:
assert len(inner_list) == self.num_views
inner_batch = []
for img in inner_list:
img = img.resize((self.image_size,) * 2).convert("RGB") # 이미지를 resize 합니다
inner_batch.append( # numpy, tensor 변환 + 정규화
torch.from_numpy(np.array(img)).to(device=self.device, dtype=torch.float32)
/ 127.5 - 1
)
tensor_batch.append(torch.stack(inner_batch, dim=0)) # 모든 뷰의 이미지를 하나로
return torch.stack(tensor_batch, dim=0).permute(0, 1, 4, 2, 3)
경로: shap-e/shap_e/models/transmitter/multiview_encoder.py
한줄 요약: 카메라 정보를 텐서로 변환
def cameras_to_tensor(self, cameras: Union[torch.Tensor, List[List[ProjectiveCamera]]]) -> torch.Tensor:
if isinstance(cameras, torch.Tensor): # 이미 텐서 형태인 경우 반환
return cameras
outer_batch = []
for inner_list in cameras:
inner_batch = []
for camera in inner_list:
inner_batch.append(
np.array(
[
*camera.x,
*camera.y,
*camera.z,
*camera.origin,
camera.x_fov,
]
)
)
outer_batch.append(np.stack(inner_batch, axis=0))
return torch.from_numpy(np.stack(outer_batch, axis=0)).float()
이후 Transformer 부분과 NeRF부분은 생략했습니다.
추가적으로 latent vector를 이용해서 진행하는 Stage2 과정은 fintune.py를 참고하시면됩니다.
코드 결과
Text: Smiling puppy




