ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation
논문 링크
프로젝트 링크



코드 구현 결과
Text prompt:Smiling puppy.
Stage1:NeRF, VSD guidance

Stage2:Geometry Refinement

Stage3:Texturing, VSD guidance

Abstract
기존에 존재하는 SDS Loss를 이용해서 많은 모델이 text-to-3D 분야를 발전 시켜왔지만, over-saturation, over-smoothing, and low-diversity 3가지 문제점이 존재했습니다.
SDS Loss에서 3D 파라미터를 고정된 상수로 뒀지만, 새롭게 제안하는 VSD(Variational Score Distillation) 방식에서는 이를 변수로 둡니다.
이에 높은 해상도의 결과와, high-fidelity의 NeRF 결과를 출력하도록 ProlificDreamer를 설계했습니다.
Introduction
3D 분야는 게임, 영화 등 다양한 산업에서 발전됐지만, 이 분야에서 3D 표현을 하기 위해서는 많은 시간과 노력이 필요합니다. 이에 Text-to-3D 분야가 발전되기 시작했습니다.
대표적으로 2D diffusion model을 이용해서 SDS Loss를 사용한 DreamFusion이 존재합니다. 하지만 SDS Loss는 3가지 단점이 존재합니다.
- 과도한 채색(Over-saturation): 생성된 3D 이미지가 과도한 색상으로 채워지는 문제
- 과도한 매끄러움(Over-smoothing): 디테일이 손실되며, 생성된 3D 객체가 너무 매끄럽게 표현되는 문제
- 다양성 부족(Low-diversity): Text prompt가 다를 때도 결과가 비슷하게 나오는 현상
이러한 문제들을 저자는 SDS Loss를 사용할 때 3D 파라미터들이 고정되었고, 하나의 변수(노이즈)만을 업데이트 하기때문에 발생한다고 생각했습니다. 이에 3D 파라미터들을 변수로 설정한 VDS를 개발했습니다.
- particle-based variational inference
- Wasserstein gradient flow
- LoRA를 통한 렌더링된 이미지 Score estimating
위의 3가지 update를 통해서 VDS를 개발했습니다. SDS는 VDS의 특별한 경우로서 single-point Dirac distribution을 사용한 것입니다.
위의 VDS update요소 말고도 scene initialization을 통해서 더 높은 해상도의 좋은 결과를 도출할 수 있었습니다.
Background
Diffusion Models
forward process: 원본이미지에서 노이즈를 점점 추가하는 과정
reverse process: 완전한 노이즈로부터 이미지를 생성해 가는 과정
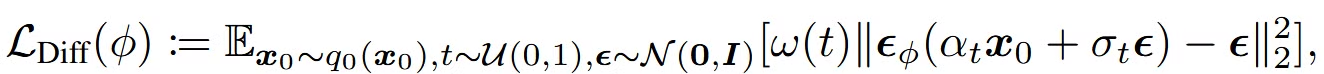
CFG(Classifier Free-Guidance): Diffsuion model에 text prompt에 알맞게 노이즈를 예측하는 과정
- 입력값으로 text prompt(y)가 추가로 들어와서, text prompt에 알맞는 이미지를 생성
Text-to-3D generation by score distillation sampling (SDS)
2D에서 사용하는 Diffusion model을 SJC(Score Jacobian Chaning)을 통해서 3D 분야에 적용하는 방법
하나의 3D represnetation의 파라미터(θ ∈ Θ)를 업데이트하는 과정
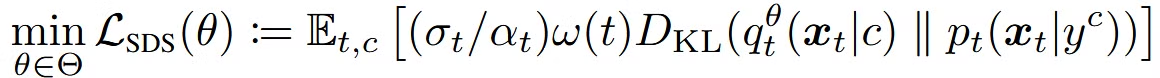
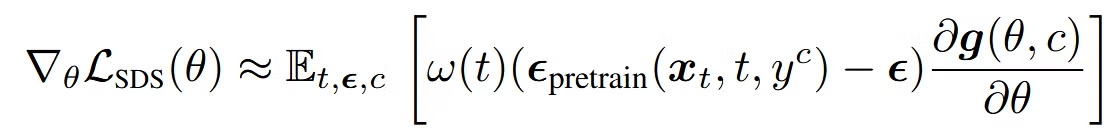
경험적으로 SDS Loss는 oversaturation, over-smoothing, and low-diversity issues가 존재합니다.
3D representations
NeRF와 textured mesh를 이용해서 3D를 표현할 것 입니다.
NeRF(Neural Radiance Fields)는 잘 아시다시피 MLP를 이용해 3D object를 나타내는 방법입니다.
Textured mesh는 triangle meshes를 이용해서 3D object를 나타내는 방법입니다.
Variational Score Distillation
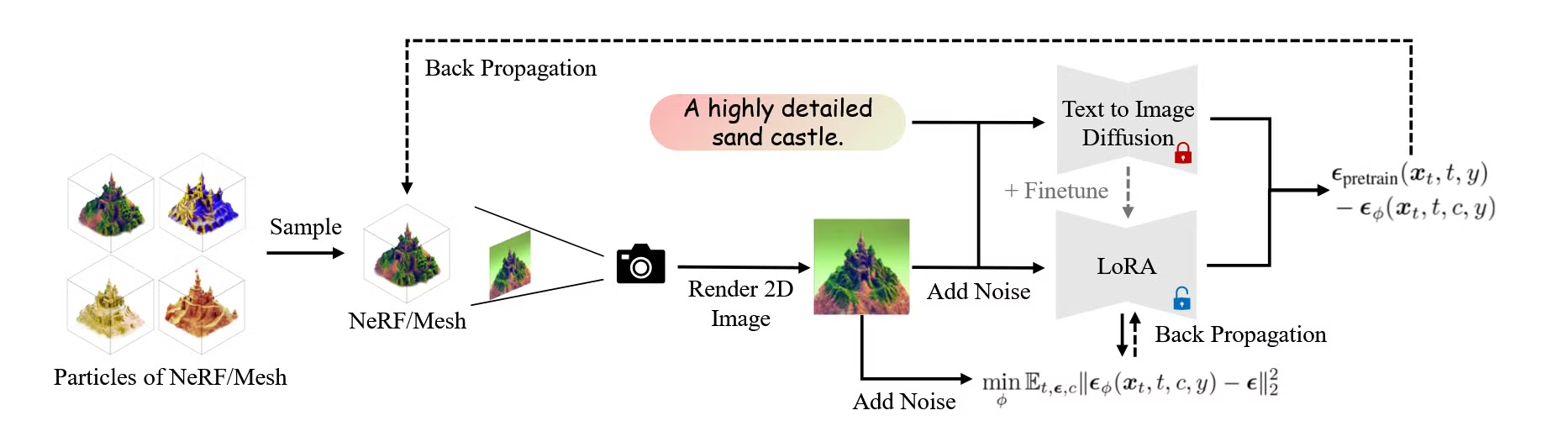
Sampling from 3D Distribution as Variational Inference
이부분에서는 VSD를 통해서 어떻게 3D Sampling이 최적화되는지를 설명합니다.
결론부터 말하면 VSD는 3D Represnetation의 파라미터 θ만을 업데이트 하는 것이 아닌, 확률 분포 자체를 업데이트 합니다. 또한 이미지 시점의 값이 아닌, 노이즈화된 t시점에서 업데이트 합니다.
μ(θ|y): 특정 text prompt(y)에 알맞은 확률 분포를 나타내는 3D Representation(θ)
: 카메라 파라미터(c)에 따라서 렌더링된 이미지()가 주어져있을 때의 확률 분포
: 사전 학습된 diffusion model에 view-dependent prompt()가 들어왔을 때 렌더링된 이미지의 확률 분포
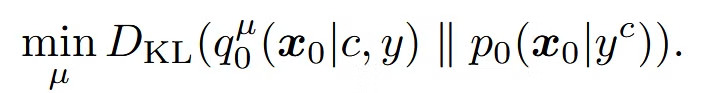
모든 view에 대해서 특정 prompt에 알맞은 두 확률분포의 차이를 최소화 시킵니다.
diffusion process의 성공을 기반으로, 문제를 쉽게 풀기 위해 노이즈가 추가된 중간 단계에서 최적화를 진행합니다.
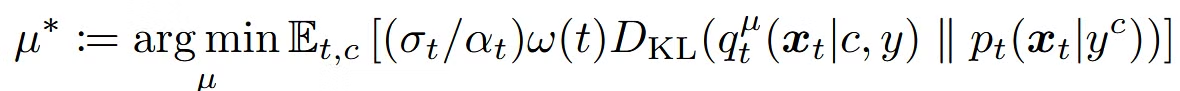

위의 Theorem1은 노이즈가 추가된 t시점에 두 확률분포의 차이가 없다면, 노이즈가 제거된 0시점의 두 확률분포의 차이도 없다는 것입니다.
Update Rule for Variational Score Distillation
위의 2가지 분포를 비슷하게 학습시키기 위해서 추가적인 파라미터를 학습시키는 것은, 많은 계산 비용과 최적화 복잡성을 가져옵니다. 이전의 particle-based variational inference를 기반으로, 3D Representation(θ) n개의 집합이 확률 분포를 나타낸다고 정의합니다.
Theorem 2를 설명하기 전에 Background 2개를 먼저 설명해드리겠습니다.
ODE (Ordinary Differential Equation, 상미분 방정식)
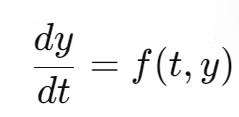
기본적인 형태는 위와 같고, 시간 t가 지남에 따라 우리가 구하고자하는 y가 어떻게 변하는지를 나타냅니다.
Wasserstein Gradient Flow
Wasserstein 거리: 두 확률 분포 간의 거리를 측정하는 방법
Wasserstein gradient flow: 확률 분포가 Wasserstein 거리를 기반으로 한 기울기 방향으로 최적화되는 과정
Theorem 2
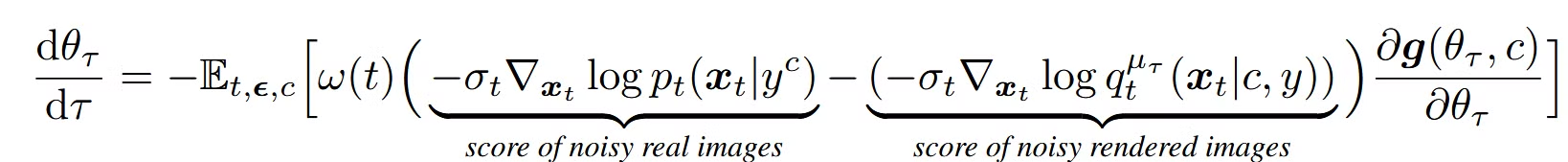
초기 분포 μ0에서 시작해서, ODE를 통해 Wasserstein gradient flow에 따라 3D 파라미터들의 분포가 점진적으로 최적화되며, 최종적으로 최적의 확률 분포 μ에 도달하게 된다는 것을 증면하는 과정입니다.
수식을 살펴보면 괄호안의 첫번째 항은 사전 학습된 diffusion model을 통한 결과, 두번째 항은 렌더링된 이미지의 결과입니다. 두 차이를 기반으로 가중치가 업데이트 되는 것을 알 수 있습니다.
맨 오른쪽 부분은 3D representation의 파라미터가 업데이트 될 때, 렌더링된 이미지가 어떻게 변하는지를 나타내는 부분입니다.
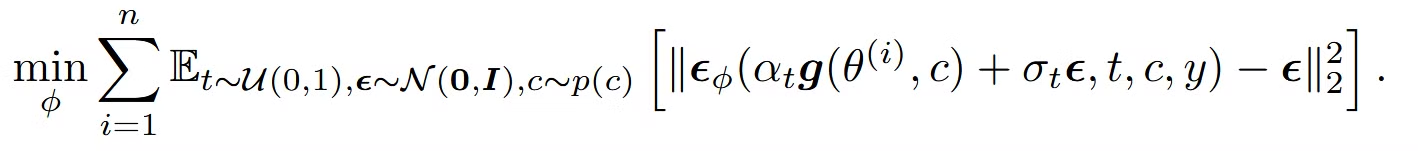
확률 분포를 나타내는 n개의 3D representation에 대해서, 노이즈 예측 네트워크(U-Net, LoRA)를 통해서 노이즈를 예측하면서 학습을 진행하는 과정입니다. LoRA가 U-Net보다 성능이 좋은데, 이는 LoRA가 few-shot fine-tuning에 매우 효율적이고, 사전 학습된 diffusion model에 포함된 이미지와 텍스트 정보를 잘 활용할 수 있다고 언급했습니다.
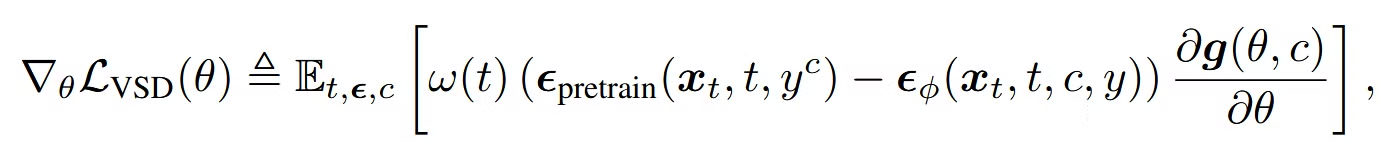
사전 학습된 노이즈 예측 모델과 현재 학습 중인 노이즈 예측 모델 간의 차이를 줄이기 위해, 3D 파라미터 𝜃가 어떻게 업데이트되어야 하는지를 설명하는 수식
Comparison with SDS
결론적으로 SDS는 VDS에서 θ의 개수(n)이 1인 경우 입니다. 비록 n=1인 경우에도 SDS와 다르게 εφ 네트워크를 학습시킨 다는점에서 차이가 존재합니다.
VSD에서 CFG 값을 매우 유연하게 조절할 수 있습니다. 이에 text-to-image에서 일반적으로 가장 높은 성능을 내는 7.5로 설정을 했습니다. 하지만 SDS에서는 단일 파라미터만 업데이트를 진행하기 때문에 정교화된 업데이트가 필요해 CFG 값을 100으로 설정했습니다. CFG값이 클수록 텍스트 프롬프트와 더 잘 맞아떨어지지만, 그만큼 다양성이 줄어들 수 있습니다.
VSD vs. SDS in 2D experiments that isolate 3D representations

단순 VSD와 SDS를 비교하기 위해서 g(θ, c) ≡ θ로 설정해서, 2D 이미지 상에서의 비교를 진행했습니다. SDS에서는 7.5와 100 모두에서 실망스러운 결과를 제시했습니다. 일반적으로 CFG는 100으로 사용되는데 이때 over-saturation and oversmoothing와 같은 문제가 발생합니다. 반면에 일반적으로 2D image에서 적용되는 CFG값인 7.5를 VSD에 적용했을 경우 성능이 좋게 나오는 것을 확인할 수 있습니다.
ProlificDreamer
Design Space of Text-to-3D Generation
크게 2Stage 학습을 진행합니다. 첫번째로 고해상도(512) NeRF를 VSD를 이용해서 학습을 합니다. 이후 DMTet을 이용해서 texture-mesh를 이용해 디테일들을 fine-tuning합니다.
2Stage는 optional합니다. 만약 1Stage만 진행할 경우 기존 NeRF의 출력값과 동일한 다양한 시점에서의 이미지, 2Stage까지 진행한다면 고해상도 mesh가 출력될 것입니다.
3D Representation and Training
High-resolution rendering for NeRF training
Instant NGP를 VSD를 사용해서 64부터 512까지 다양한 해상도의 NeRF 결과값을 얻습니다.
Scene initialization for NeRF training
: density strength / r: density radius / μ: coordinate
물체 중심 장면에서는 Magic3D와 동일하게, object-centric initialization를 적용했습니다( = 10 and r = 0.5).
복잡한 장면에서는 scene initialization를 사용했습니다( = -10 and r = 2.5).
2개의 장면을 나누는 기준은 로 설정했습니다.
Annealed time schedule for score distillation
초기: t ∼ U(0.02, 0.98) // 점진적 변화: t ∼ U(0.02, 0.50)
처음에는 KL 발산을 큰 시간 단계에서 최적화해 합리적인 최적화 방향을 설정하고, 시간이 지날수록 점진적으로 작은 시간 단계로 전환하여 세밀한 디테일을 잡아내는 방식입니다.
Mesh representation and fine-tuning
NeRF에서 mesh로 변환할 때 좌표 기반 hash grid 인코더를 사용하여 mesh texture를 표현합니다.
Fantasia3D에서 사용된 방법을 따르며, 먼저 geometry를 최적화한 다음 texture를 최적화합니다. geometry를 최적화 할 때는 SDS를 사용했습니다. 이는 VSD가 초기 최적화시에는 많은 디테일을 제공하지 않기 때문입니다.
Experiments

Results of ProlificDreamer
자세한 내용들은 Appendix에 나와있고, 위의 결과를 통해서 해당 모델이 다른 모델들에 비해서 더 고해상도의 사실적인 3D를 생성하는 것을 알 수 있습니다.
Ablation Study

기본적인 세팅인 64해상도 SDS 방법에서, 512 해상도, Annealed 방식의 추가, VSD 방식의 추가를 나타낸 그림입니다.
Conclusion
SDS의 문제점을 principled particle-based variational 방식과 추가적인 3D network의 학습을 통해서 고해상도의 사실적인 3D를 생성할 수 있는 VSD방식을 개발했습니다.
Limitations and broader impact
많은 시간이 소모되고, 몇개의 text prompt의 실패, janus problem까지 기존에 존재하는 문제들은 여전히 존재합니다.
