Textured 3D Regenerative Morphing with 3D Diffusion Prior[2025 ICCV]
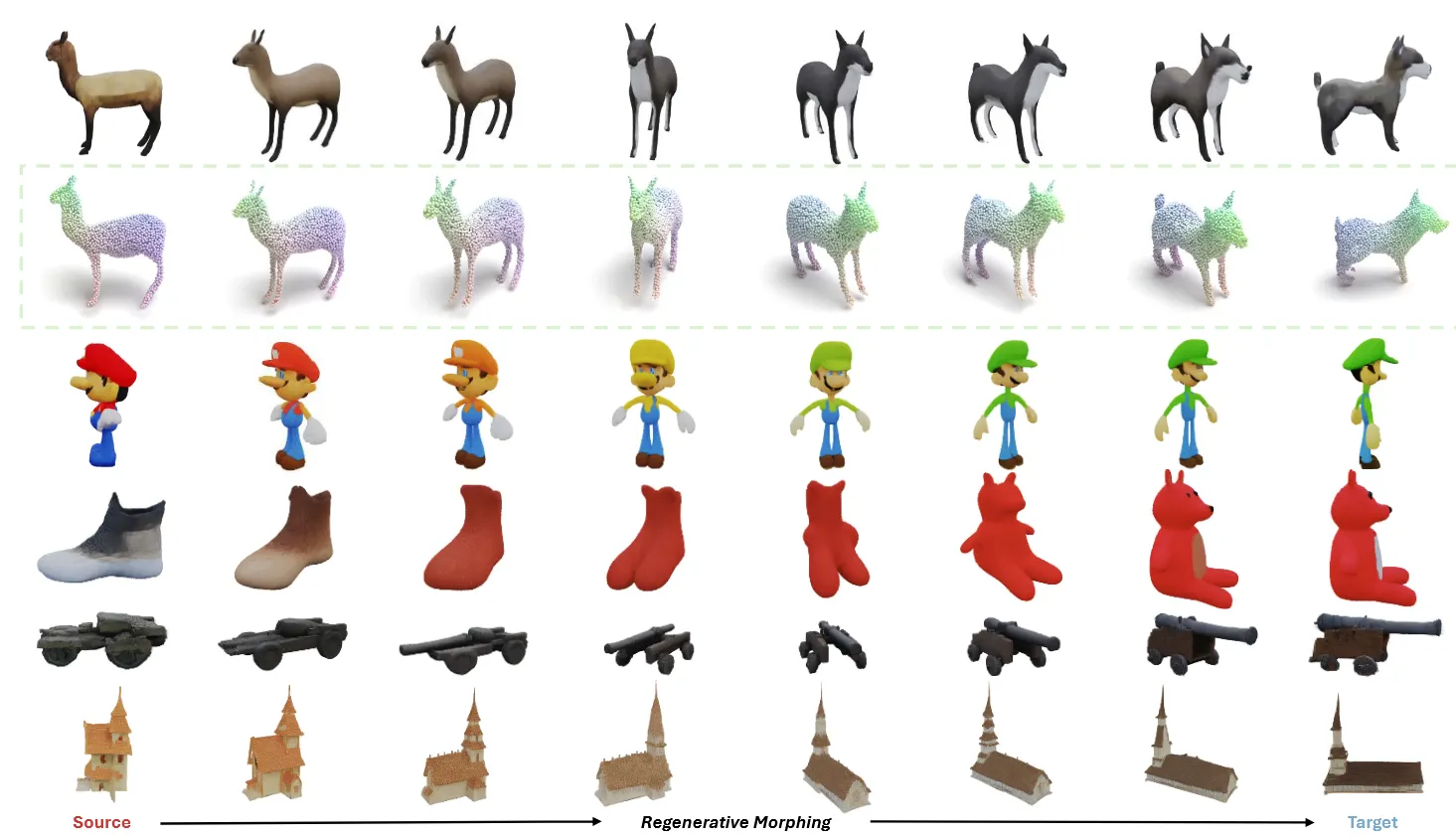
Textured 3D Morphing은 texture가 입혀진 3D object사이를 smooth하고 plausible하게 생성하는 과제이다. 기존방식들은 texture 없이 3D geometry만 변형하는데 초점이 있었는데, 이 논문에서는 texture interpolation까지 가능하도록 모델을 설계했다. 어떻게 이를 가능하게 했는지 살펴보도록 하겠다.
Introduction
Morphing 분야는 영화나 미디어에서 물체간의 전환을 자연스럽게 이루어지기 위해서 많이 사용된다. 데이터의 유형에 따라서 크게 Image와 3D Morphing 2가지로 나눌 수 있다. Image는 2D상에서 픽셀의 변화만을 다루기 때문에 제한적인 변화만 가능하지만, 3D는 물체자체를 변화시킬 수 있기 때문에 시각 효과 제작 과정이 더 자연스럽다. Image는 시점을 고정한 3D Morphing의 특수한 경우로 봐도 무방하다.
기존 3D Morphing 방식들은 2개의 mesh의 point cloud를 매핑하면서 interpolation 하는 과정에만 집중했다. 또한 학습할 데이터들을 동일한 3D 상태로 매핑해야되는 전처리 과정이 필요하다는 한계점이 존재했다. 이러한 전처리 과정때문에 학습할 데이터가 부족했고, 데이터의 부족은 곧 좋지 않은 결과로 이어졌다. 동시에 동일한 카테고리가 아닌 전혀 새로운 카테고리로의 변환은 명백한 condition이 들어가지 않으면 힘들었다.
이러한 한계를 극복하기 위해 크게 2가지 해결책이 존재했다. 첫번째 해결책은 2D diffusion을 이용해서 3D를 생성해보자는 방식이다. 이러한 방식은 2D 모델이 3D 지식이 없다는 점과, 3D consistency가 일치하지 않다는 점이 한계점으로 지적됐다. 두번째 해결책은 3D diffusion 모델을 사용하는 것이다. 3D diffusion 모델은 3D 지식도 있고, consistency도 일치하기 때문에 이 논문에서는 3D diffusion 모델을 사용하는 해결책을 사용했다.
3D diffusion에서 morphing을 자연스럽게 생성하기 위해서 Attention Fusion 전략을 사용했다. Attention Fusion을 사용해서 Morphing은 부드러워졌지만, 결과물이 비현실적으로 변하거나 깨지는 현상이 발생했다. 따라서 3D 결과가 잘 나오도록 의미론적인 정보를 일치시키는 Token Reordering 방식을 제안했다. 지금은 단순히 데이터의 인덱스 순서대로 정보가 섞이는데, 구조적으로 비슷한 부분끼리 짝이 맞도록 순서를 재배열 한 뒤, 자연스러운 변형이 이루어지도록 한다. 또한 Attention Fusion이 모델의 전체적인 형태를 잡는 저주파 신호를 제대로 유지하지 못하고 손상시키는 문제를 발견했고, denoising 단계에서 저주파 신호를 증폭시키는 Low-frequency Enhancement 방법을 제안했다.
Related Work
Image Morphing
전통적인 방식은 특징들을 혼합해서 섞다보니 단순히 중간값은 잘 나타내지만, 새로운 부분을 만들 수 없다. 예를들어서 찡그린 얼굴을 웃는 얼굴로 변환한다고 했을 때 웃는 과정에서 입을 벌릴 때 없던 치아를 잘 생성하지 못한다. 데이터기반 방식들은 특정 클래스에서 좋은 성능을 내고, 클래스가 바뀌는 결과는 좋지 않다. 최근에는 Diffusion 모델을 활용해서 이를 극복하고 서로다른 클래스에 대해서 Morphing이 가능하게 했다.
3D Morphing
이전의 3D Morphing 방식은 형태만을 집중해서 변형했다. 기존방식은 크게 딥러닝을 사용했냐 안했냐로 나눌 수 있다. 딥러닝을 사용하지 않은 방법을 공리적(Axiomatic) 방법이라고 한다. Sparse landmarks, functional maps, energy-minimizing & skinning 그리고 optimal tranportation 방식들이 존재한다. 딥러닝 기반 방식은 생성 모델의 지식을 활용하는 방식이다. 멀티뷰 이미지나 DINO나 Language Vision모델을 이용해서 정보를 추출하는 방식등이 존재한다. 유저가 작성한 text prompt를 기반으로 물체를 변형하는데, text prompt를 임베딩으로 변환하는 CLIP 모델은 디테일한 부분은 잘 알지못하는 한계점이 존재한다. 이러한 방식들은 2D model을 사용하기 때문에 3D와 불일치해서 추가적으로 일치시키는 과정이 필요하다.
3D Diffusion Model
3D diffusion 모델은 2D 지식을 활용하는 방식과 3D를 직접 이용하는 방식으로 나눠진다. 2D 지식을 활용하는 방식은 Score Distillation Sampling 방식을 이용해서 3D 정보를 2D diffuison으로부터 얻는다. 이는 멀티뷰 이미지를 생성하고 이로부터 3D를 생성하는 방식으로 이용된다. 하지만 이 방식은 직접적으로 3D를 얻는 방식보다 정보 손실이 발생한다. 이러한 정보 손실을 줄이기 위해서 최근에는 3D로부터 직접 latent를 얻는 방식들이 나왔다. 이 논문에서는 이러한 방법중 하나인 GuassianAnything을 골랐다. 개인적으로 다른 좋은 모델도 있는데 이 논문을 고른 이유는 저자가 같기때문이라고 생각한다.
Method
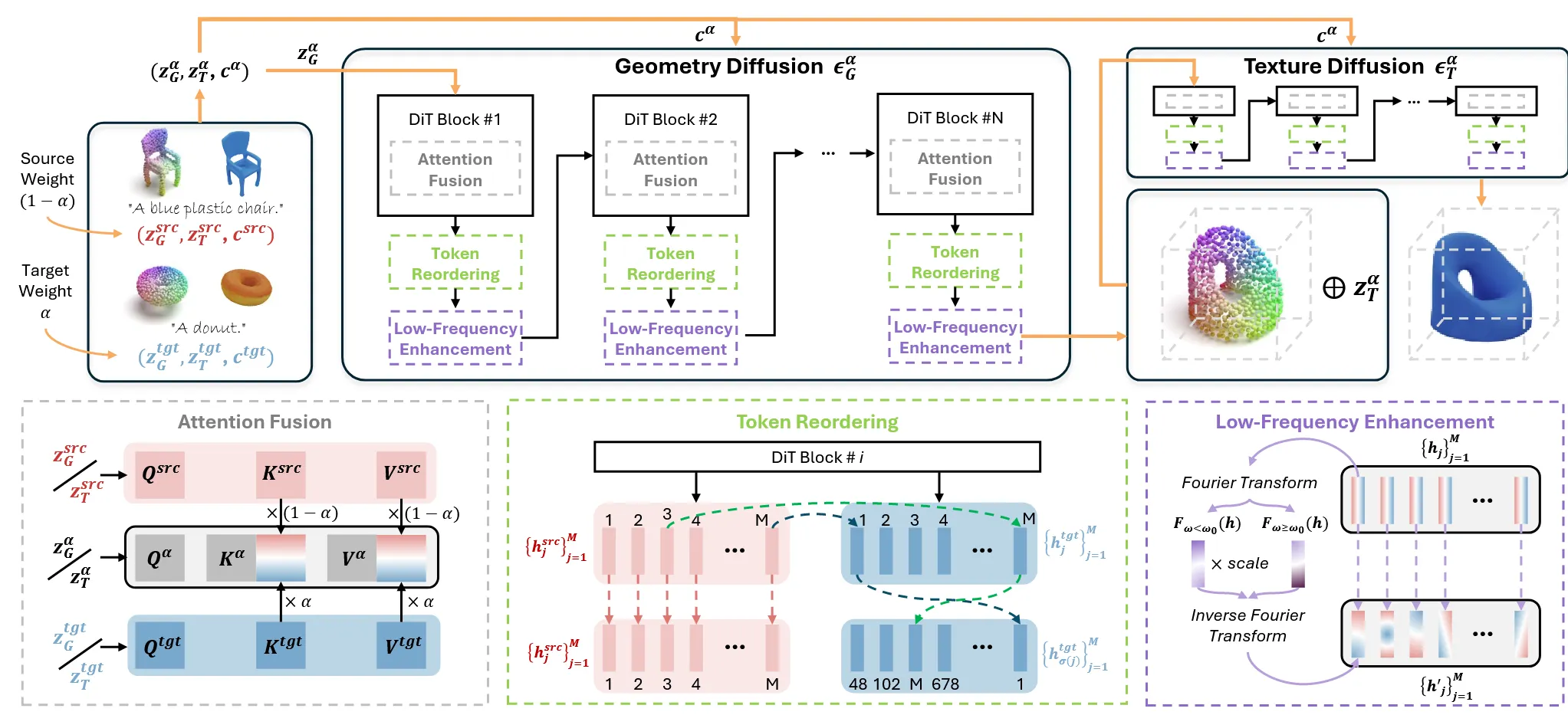
위의 파이프라인은 이 모델의 구조를 나타낸다. 방법은 크게 3가지로 나눌 수있다. Interpolation 과정이 진행되는 Basic Interpolation, 이 interpolation 과정을 부드럽게 진행시켜주는 Attention Fusion 마지막으로 모델의 plausibility를 증가시키는 Token Reordering과 Low-frequency Enhancemnet로 나눠져있다.
Preliminary
3D Diffusion Model
3D Diffusion 모델로 Gaussian Anything을 선택했다. Two-stage로 point cloud의 latent 공간과 DiT 구조를 활용한다. 기하학적인 부분을 생성하는 모델인 와 texture를 생성하는 모델 로 구성됐다. 초기에 gaussian noise로부터 textual condition c를 이용해서 point cloud()를 생성한다. 생성된 point cloud에 gaussian noise를 더한 값을 texture 생성 모델을 이용해서 denoising한 최종 결과 를 생성한다. 1단계 생성 결과인 와 2단계 생성 결과인 를 decoder()에 넣어서 최종 3D Gaussian 형태인 를 만든다.
Attention
Diffusion 모델에서 text condition을 활용할 때 사용되는 cross-attention을 설명하는 부분이다.
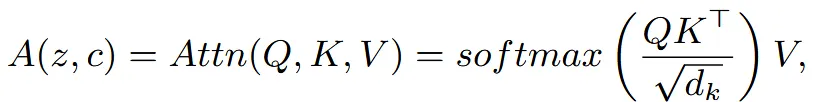
Self-attention은 z랑 c가 동일할 경우이며 수식은 동일하다.
Basic Interpolation
Interpolation
Interpolation을 하기위해서는 source, target, weights() 3가지 값이 필요하다. 가 0인 경우 source 를 생성하고, 가 1인 경우 를 생성한다.
2개의 모델에 초기값으로 사용하는 Initial Noise는 2개의 3D representation 각각을 diffusion inversion 한 값을 interpolation 한다. 여기서 interpolation 할 때 linear가 아닌 고차원 정보기 때문에 spherical linear interpolation을 한다. 개인적으로 이 부분이 이해가 안갔는데, 결론만 말하면 고차원일수록 데이터의 분포는 중심으로부터 루트 d만큼 떨어진 거리에 존재한다. 반지름이 루트 d인 구가 있다고 할 때 그 표면에 데이터들이 분포하기 때문에, 이 분포의 interpolation을 구를 기준으로 해야한다. 왜 루트 d만큼 떨어졌는지, 분산은 어떻게 되는지 확인하기 위해서는 모든 정규분포의 평균과 분산, 그리고 차원이 증가했을 때 평균과 분산을 계산해보면 된다.
Geometry와 Texture 2개의 모델 모두 LoRA(Low-Rank Adaptation)을 이용해서 fine-tuning 한다.
Condition은 image를 넣어서 DINO 모델의 결과인 이미지 임베딩이 아니라, text를 CLIP에 넣은 텍스트 임베딩을 사용했다. 저자는 text를 condition으로 사용했을 때 더 의미론적으로 일치한다고 주장했다. Target과 Source에 대해서 각각 텍스트 임베딩을 얻고 notation으로 , 라고 표현했고, interpolation된 텍스트 임베딩을 라고 한다.
Problems
위와 같이 Interpolation하는것이 가장 직관적이긴 하지만 그대로 진행할 경우 2가지 문제가 발생한다.
Abrupt Chnages (Smoothness)
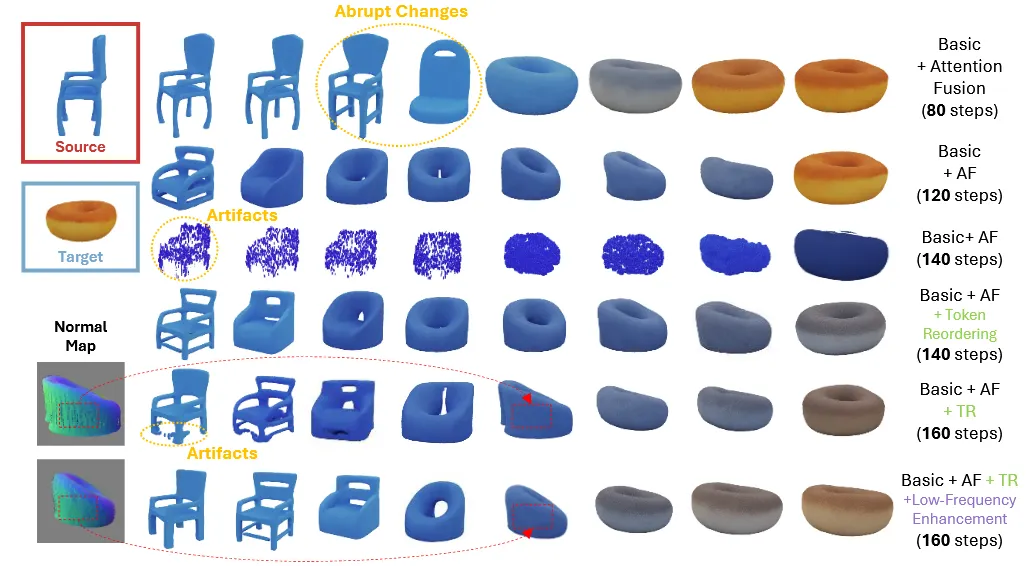
들어가기에 앞서 한가지를 명확하게 알고 넘어가야한다. Source에서 Target으로 변화할 때 Smooth하는게 목적이고, Smooth하기 위해서는 linear해야 한다. 직관적으로 직선을 다른 직선으로 바꿔도 결과적으로 직선이라는 성질은 변하지 않는다. 하지만 Diffusion과 같이 Non-linear한 함수가 들어간 모델을 이용할 경우, linear가 Non-linear로 변하고 결론적으로 Smooth하지 않은 결과가 나온다. 논문에서는 Diffusion 모델을 사용했기 때문에 위와 같은 이유로 Non-linear한 현상이 나타나고, 이는 위의 그림에서 노란색 동그라미 친 부분에 갑자기 확 물체가 변하는 것을 통해서 확인할 수 있다. 또한 Condition으로 사용하는 텍스트 임베딩을 interpolation 해서 얻은 가 의미론적으로 condition의 중간값이라는 보장이 없다.
Artifacts (Plausibility)
Morphing을 하기위해서 노이즈, 모델, condition 등 다양한 값을 interpolation 했고, 이러한 interpolation된 space들이 일치하지 않기 때문에 모델은 Artifact를 종종 생성한다. 위의 그림에서 노란색 Artifacts를 보면 point cloud가 망가지거나, mesh에서 의자의 다리가 망가진 것을 확인할 수 있다.
Attention Fusion
Attention을 혼합하는 과정이 좋다는 것은 2D diffusion을 사용하는 image morphing 분야에서 입증 됐다. 기존 방식들은 모델 자체에서 사용하는 attention에 대해서 fusion을 진행했지, condition으로 들어가는 부분에 대해서 fusion을 진행하지 않거나 해당 부분을 정확히 다루지 않는다. 이 논문에서는 condition으로 들어가는 cross-attention fusion까지 진행한다고 한다.
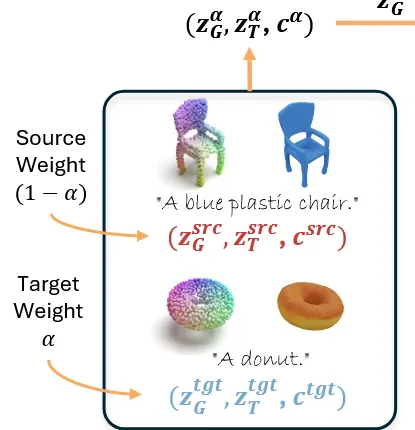
첫번째 단계는 condition과 Inversion된 noise를 Interpolation한 결과 를 만든다.
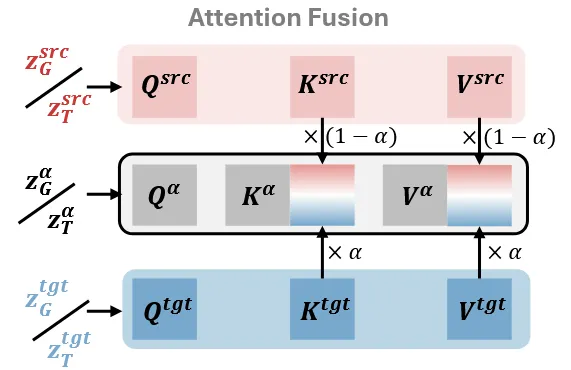
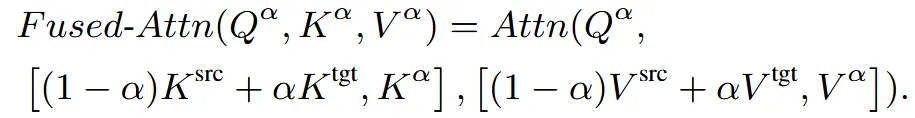
Interpolation 결과를 이용해서 위와 같은 attention을 진행하는 경우를 Fused Attention이라고 한다. 조금 더 구체적으로 살펴보면, 하나의 denoising step은 DiT를 이용해서 진행되는데, DiT 안에는 여러개의 Attention block들이 존재한다. 이 Attention block을 사용할 때 self-attention에서 noise를 tgt, src, 어떤걸 쓰느냐에 따라서 Q,K,V가 달라지고 이거를 위와 같이 계산하면 Fused Attention이 되는거고, Cross-attention에서는 noise와 condition이 tgt, src, 로 달라질 때 Q,K,V도 달라지는 경우를 위와 같이 계산하면 Fused Attention을 이용했다고 보면된다. 요약하면 Attention block에서 다른 값을 이용해서 계산한 Q,K,V를 합치는(interpolation하는) 과정을 Fused Attention이라고 한다.
Token Reordering
Motivation
3D point cloud는 토큰화 되어서 가 된다. 이 과정에서 point cloud가 정렬되지 않았기 때문에 의미론적으로 point끼리 연결되기 어렵다. 따라서 논문에서는 diffusion feature를 이용해서 의미론적으로 point끼리 연결시키는 작업을 진행하는 방식을 제안했다.
Experimental Analysis
Vanila attention fusion을 할 때 같은 인덱스 토큰끼리는 대응된다고 가정하고 계산되는데, point cloud는 순서가 정해지지 않아서 실제로는 같은 정보를 담는다는 보장이 없다. 이거를 정량적으로 측정하기 위해서 의미론적으로 유사한 feature끼리는 가깝다는 정보를 이용한다.
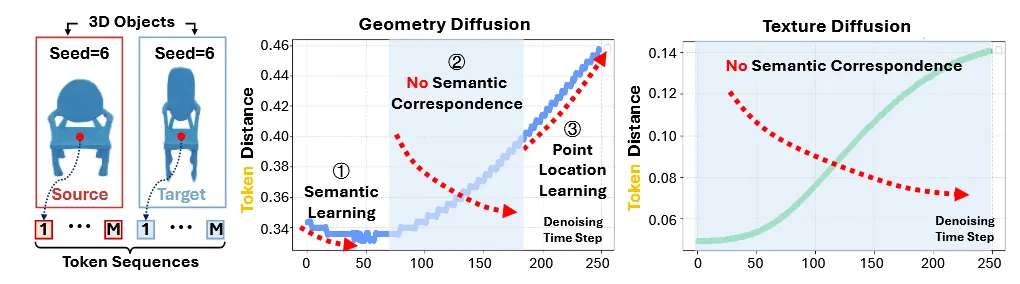
3D diffusion에서 실험을 진행하기 위해서 3D object에 대해서 scale만을 변환시킨 2개의 object를 준비한다. Scale의 경우 모든 point cloud에 대해서 동일하게 진행되기 때문에 같은 인덱스에는 같은 토큰이 대응된다. 이때 동일한 인덱스끼리 토큰 거리가 어떻게 변하는지, 즉 의미론적으로 어떻게 변하는지를 실험적으로 나타낸게 위의 그림이다.
이상적으로는 denoising과정에서 의미론적으로 일치시키는 과정(논문에서는 200 steps라고 주장)에서는 거리가 줄고, position을 일치시키는 과정에서는 거리가 늘어날 것이다라고 주장했다. 근데 이거에 대한 근거가없어서 정확히 맞는지는 모르겠다. 어쨌든 의미론적으로 줄어드는 부분이 있어야한다는 주장은 동의한다. 하지만 위의 그림을 보면 오히려 의미적으로 멀어지는 것(특히 Texutre Diffusion)을 확인할 수 있다. 따라서 동일 인덱스 토큰을 대응으로 가정하고 섞는 vanilla Attention Fusion은 의미적으로 implausible한 연결을 만들기 쉽고, 이것이 artifact로 이어질 수 있다.
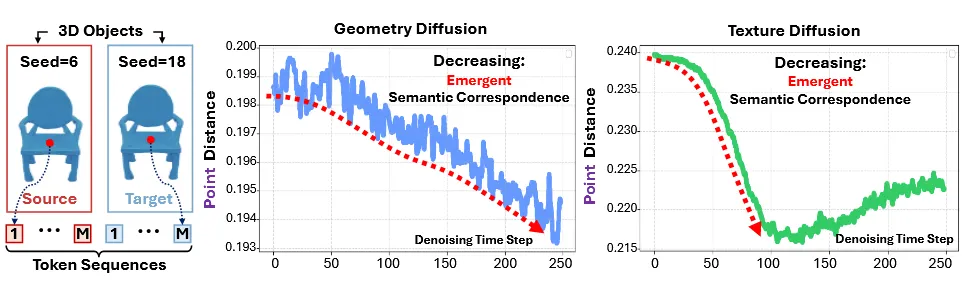
두번째 실험에서는 각 timestep에서 가장 의미적으로 유사한 token에 해당하는 point끼리의 최종 결과에서의 거리를 측정하는 실험이야. 초기 step에서는 의미론적인 부분이 학습되지 않아서 가장 유사한 token을 골라도 최종 결과에서 거리가 멀어져있는데, denoising을 진행하면서 의미론적인 부분을 학습하고 가장 유사한 토큰들은 최종 결과에서도 유사한 부분에 있다는 것을 실험하는 것이다.
Implementation
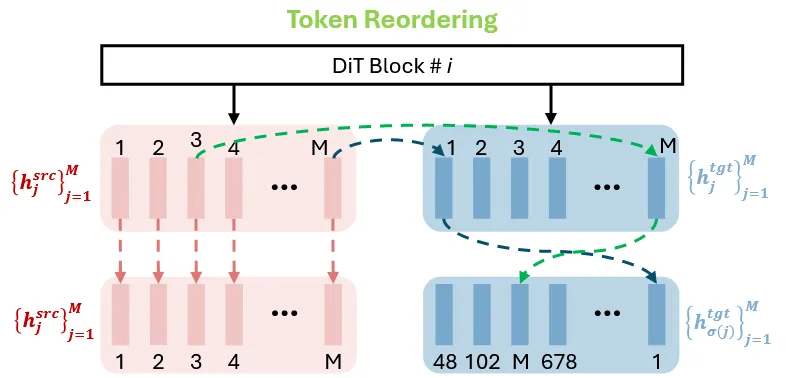
2번의 실험을 기반으로 diffusion의 각 block을 통과하고 token을 재정렬하는 과정을 진행한다.
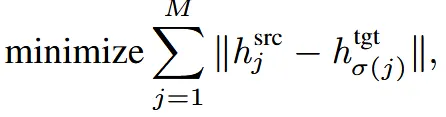
M개의 block 각각에 대해서 토큰의 거리의 합이 최소가 되도록 설정한다. M은 토큰의 총 개수이고,σ(j)는 target에서 source의 j index와 토큰 feature 거리가 가장 가깝도록 하는 인덱스이다.
논문에서 가 [0,0.5]일 때는 target token을 재정렬했고, 가 [0.5,1]일 때는 source token을 재정렬했다. 방향성이 있기때문에 반반 진행한거는 합리적이지만 이유는 나와있지않다.
Low-Frequency Enhancemen
Motivation
Fusion Attention을 진행함에 따라 원래 학습된 diffusion 공간에서 멀어진다. 이에따라 denoising 과정에서 diffusion모델의 능력을 최대로 활용하지 못하고, 결과는 악화된다.3D diffusion 모델의 어떤 부분에 악영향을 미쳐서 성능 저하를 이끌었을까? 라는 의문을 논문의 저자는 갖게 됐다.
Experimental Analysis
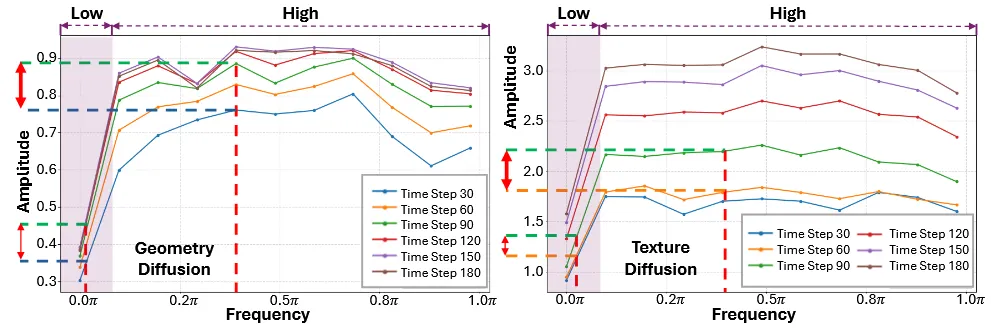
위의 그림을 통해서 step별로 low-frequency와 high-frequency에서 변화를 확인할 수 있다. 전반적으로 low-frequency에서는 변화가 적지만, high-frequency는 많이 변하는 것을 확인할 수 있다. Low-frequency가 3D의 전반적인 품질을 나타내고, High-frequency가 3D의 디테일한 정보를 담당하는데 low-frequency 변화가 적다는 것은 3D의 전반적인 품질이 변하지 않는다는 것이다. 따라서 3D의 전반적인 품질을 높이기 위해서 Low-frequency를 강조해야한다.
Implementation
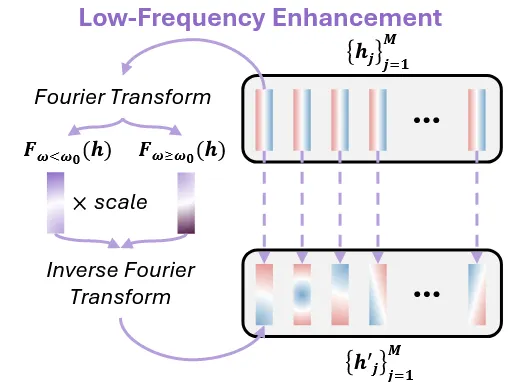
따라서 논문에서는 3D interpolation을 진행할 때 low-frequency 신호를 강조하는 방식을 제안했다.
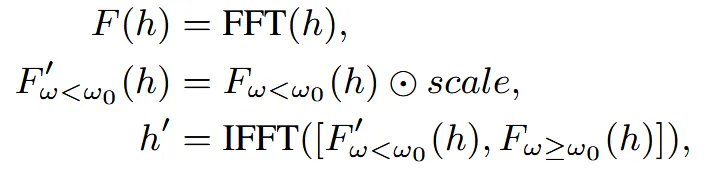
h는 토큰을 나타내고, F(h)는 Fourier 특징들을 나타내고, h’은 저주파가 향상된 토큰이다.

Scale의 값이 커질수록 low-frequency를 더 강조하게 된다. 위의 그림에서 scale이 작을 때 표면이 상대적으로 불안정한데, 커질수록 전체적인 구조가 명확해지는 것을 알 수 있다.
Experiments
Implementation Details
Morphing Configuration
모든 실험은 250 denoising steps를 진행했다. Morprhing과정에서 의 제약조건이 없다면 변화가 큰 부분을 중심으로 값을 설정하는 Beta distribution 방식(DiffMorpher에서 사용)을 이용한다. Attention Fusion은 geometry diffusion은 1~160steps, texture diffusion은 80~200steps에서 진행했고, Low-frequency Enhancement는 200~230 steps에서 scale=5, 임계치 를 이용했다.
Baselines
Textured 3D Morphing을 비교하기 위해 MorphFlow 모델을 이용했고, Image에서의 Morphing은 DiffMorpher, AID 2개의 모델과 비교를 진행했다. 이미지 비교를 할 때 동일한 시점을 렌더링한 이미지에 대해서 morphing한 결과를 비교하는 것이다. 멀티뷰 모델인 MV-Adapater도 동일한 시점으로 렌더링한 이미지를 이용해서 생성하고자 하는 시점의 임베딩을 섞어서 결과를 생성하도록 했다. 마지막으로 비디오 모델인 Luma는 첫 프레임을 source, 마지막 프레임을 target으로 줘서 중간 프레임을 생성하게 했다.
Metrics
G-Objarverse의 데이터셋에 대해서 15개의 페어를 만든것을 Test dataset으로 이용했다. 우선 15개에 대해서 Source와 Target 2세트 그리고 각 세트마다 100개씩 렌더링해서 총 3000개의 이미지가 나온다. 3000개의 이미지로부터 특정 시점으로 morphing한 결과가 나오니, 결과는 총 1500개가 나온다.
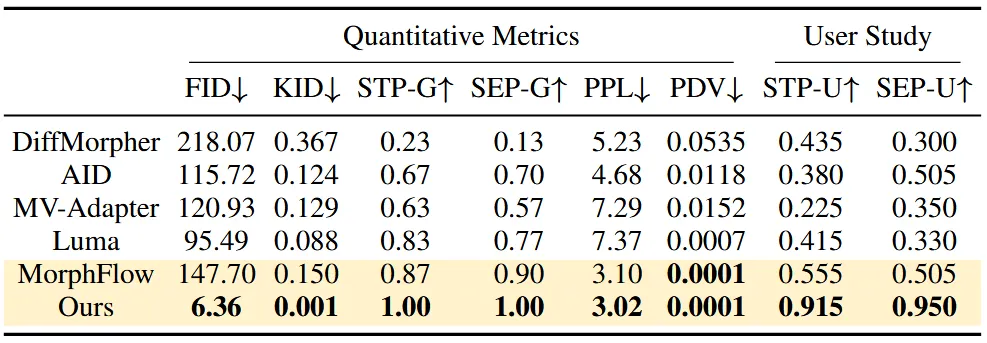
FID와 KID는 생성된 1500개의 이미지와 3000개의 source target 이미지의 분포를 비교한 결과이다.
STG-G는 구조를 SEP-G는 의미를 LLM(GPT-4o)이 평가한 것이다.
Perceptual Path Length (PPL)은 20 프레임에서 인접한 프레임끼리의 perceptual loss를, Perceptual Distance Variance (PDV)는 PPL에서 측정한 perceptual distance들의 분산을 본다.
STP-U와 SEP-U는 각각 구조와 의미에 대해서 User가 평가한 결과이다.
Evaluation
Textured 3D Morphing

Texture Morphing에 대해서 MorpFlow와 비교한 결과(핑크색 부분)는 MorphFlow가 품질이 안좋고, 의미론적으로 전혀 좋은 결과를 내지 못하고 있다. 또한 이전에 나온 Table 결과도 모든 지표에서 해당 모델이 좋았다고 하는데.. 개인적으로 이 모델 퀄리티도 별로인거같다.
3D-Aware (Multi-View Image) Morphing
Texture Morphing 모델이 많이 없어서 다른 모델들과 추가적인 비교를 진행했다.
2D image Morphing(DiffMorpher, AID)는 Inversion과정에서 이미지의 흰색 배경이 악영향을 미쳐서 결과가 악화됐을 것이라고 논문에서는 주장했다. 또한 3D consistency는 일치하지 않는것이 결과를 통해서 확인할 수 있다. 멀티뷰의 경우 단순히 feature들을 섞었기 때문에 픽셀들이 정렬되지 않는다. 마지막으로 비디오는 생성 제어가 약해서 완전히 일관성이 없어진 결과가 나온다.
Ablation Study
실험을 통해서 Geometry diffusion은 넓은 범위에서, Texture diffusion은 좁은 범위에서 Attention Fusion을 해야함을 확인했다.

첫번째 줄에서 Attention fusion을 적용해서 결과가 부드러워졌지만, steps를 뒤까지 추가할수록 구조적으로 붕괴됐다. 4번째줄부터 추가된 Token Reordering(TR)은 이 현상을 완화시키지만 결과 퀄리티가 나빠진다. Low-Frequency Enhancement (LE)를 적용해서 구조적으로 안정된 결과를 얻을 수 있게 됐다.
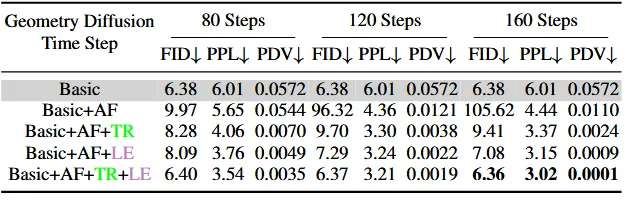
이를 정량적으로 측정한 지표가 위와 같다.
Conclusion
Texture morphing에서 smooth하면서도 좋은 결과를 낼 수 있는 모델을 제시했고 여기에는 Attention Fusion, Token Reordering, Low-frequency Enhancement 방법이 제시됐다. 하지만 복잡한 3D morphing은 할 수 없다는 한계점이 존재한다.
개인적으로 interpolation 하는 세팅부터 잘못되지 않았을까 하는 생각이있다.
