Native and Compact Structured Latents for 3D Generation[2025 arXiv]

Trellis 논문이 2025 CVPR Highlight를 받고 후속작으로 Trellis2가 나왔다. 아직은 저널이 발표되지는 않았지만 스타일상 2026 CVPR이 유력하다. 인트로에 나와있는 그림만봐도 확실히 디테일한 부분의 퀄리티가 좋아지고 해상도도 높아진거같다. 어떤점이 바꼈는지 자세히 확인해보도록 하겠다.
Introduction
3D 생성 모델들이 많이 발전했지만, full spectrum 정보를 담고 있는 3D 생성 모델은 아직 나오지 않았다. 예를들어서 기존 Trellis 논문이 Texture와 Geometry를 예측하지만, Material 정보까지는 예측하도록 설계되지 않았다. 지금까지 3D Latent Diffusion 모델들은 크게 2가지로 나눌 수 있다. Direct3D-S2 논문에서 잘 설명됐는데, Hunyuan3D같은 모델들은 latent를 정의할 때 구조화하지 않은 상태로 이용해서 수정과 학습이 어렵고, Direct3D나 Trellis와 같은 모델은 iso-surface와 같이 구조화된 상태를 이용해서 latent를 정의해서 수정과 학습이 용이하다고 나와있다. 하지만 후자의 방법은 SDF처럼 0인부분을 이용하기 때문에 역설적으로 두께가 없는 물체들이 나타내는 open surface 현상을 표현하지 못한다.
논문에서는 기하학적인 형태와 외관을 모두 포함할 수 있는 O-Voxel을 정의했다. O-Voxel에서 기하학적인 측면에서는 flexible dual grid를 통해서 open, non-manifold, fully-enclosed surface등 기존 모델들이 다루기 힘들었던 형상들도 처리할 수 있고, 외향적인 측면에서는 단순히 RGB같은 texture 뿐만아니라, physically-based rendering (PBR)를 통해서 투명한 부분까지 표현할 수 있다. 또한 O-Voxel은 최적화와 렌더링 과정을 진행하지 않기 때문에 CPU를 통해서 1초도 안걸리는 짧은 시간안에 3D asset을 O-Voxel로 다시 3D asset으로 변환할 수 있다. 이렇게 여러 정보를 나타내고 짧은 시간안에 변환할 수 있는 O-Voxel의 VAE모델은 16배 압축할 수 있고, 1024^3 해상도 3D asset을 얻을 수 있다.
40억개의 파라미터를 갖는 대용량 Flow matching을 학습했음에도 불구하고 1024해상도는 17초, 심지어 1536 해상도도 60초만에 생성할 수 있다.
굉장히 흥미롭다, 정리하면 Texture와 Geometry 심지어 PBR 정보까지 담을 수 있는 VAE가 있고, 이 VAE는 기존에 생성하지 못했던 open surface 현상도 해결하면서 1초도 걸리지 않는 변환과정이 필요하고, 생성 모델은 1536해상도까지 가능하다… 놀라운 정도로 발전된 Trellis를 이제 자세히 확인해보도록 하겠다.
Related Work
3D Representations for Generation
초기 연구는 occupancy fields나 SDF와 같은 implicit fields를 통해서 물체를 표현했다. NeRF는 appearance 정보까지 포함해서 사실적인 렌더링 이미지를 만들어냈지만, 3D asset 퀄리티는 떨어지고 계산 비용도 많다. Mesh, point cloud, Gaussian처럼 explicit representation이 나왔지만 이러한 방식은 우리의 이해를 도와줄 수는 있어도 AI가 쉽게 학습할 수 있는 구조화된 형태는 아니다. 왜냐하면 데이터의 순서가 뒤죽박죽이기 때문이다. 최근에는 Trellis와 같이 implicit representation을 latent로 압축하는 sparse voxels 개념을 도입했는데 여전히 물체를 implicit fields 방식으로 표현하기 때문에 open surface를 표현하지 못한다.
Latent 3D Representations
최근에는 explicit representation 방식으로 latent를 압축하는 방법이 많이 연구됐다. Introduction에도 설명했지만 크게 압축률이 크지만 구조적인 정보를 잃는 unstructured latent 방식과 압축률은 작지만 더 명확한 공간으로 구조를 표현하는 structured latent 방식이 있다.
Large 3D Asset Generation Models and Systems
3D asset을 생성하는 기존 방법들은 크게 형태를 먼저 만들고, 멀티뷰 이미지를 이용해서 texture를 입히는 2stage 방식을 이용한다. 이러한 방식들이 2D diffusion 모델을 이용할 수 있다는 장점이 있지만, rendering, baking, texture alignment라는 추가적인 과정이 필요하다는 단점이 존재한다. 따라서 이 논문에서는 이러한 추가적인 과정없이 end-to-end로 PBR material과 geometry 정보가 같이 저장되는 방식을 제안했다.
Method

위에서 O-Voxel이 기하학적 정보와 material 정보가 모두 포함된 공간이라고 했는데, Trellis1의 DINO v2를 이용해서 feature를 3D차원으로 보낸공간과 유사한거같다. 이후에는 동일하게 VAE 모델을 통해서 더 압축된 공간에서 생성 과정을 진행하는거같다.
O-Voxel: A Native 3D Representation
어떻게 렌더링 없이 기하학적인 정보와 material의 정보를 모두 갖게 됐는지 설명하는 문단이다.
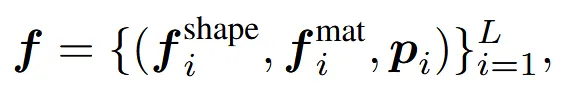
O-Voxel은 NxNxN 3D grid로 나눠진 sparse voxel로 표현된다. 각 voxel안에는 위와같이 3개의 정보가 들어있는데 은 물체의 기하학적인 정보를, 는 material 정보를 는 voxel의 3차원 좌표를 나타낸다. 여기서 모든 voxel이 아닌 물체의 위치를 나타내는 voxel만을 활성화한다.
Flexible Dual Grid for Shape
O-Voxel은 Flexible Dual Grid 공식 덕분에 어떠한 형태든 3D를 표현할 수 있게 됐다. 지금 우리는 새로운 NxNxN 3D grid를 정의했기 때문에 이 공간에서 물체가 어느 부분에 위치하는지에대한 기하학적인 정보인 를 구해야 한다.
기존의 방식들은 Voxel을 Grid로 나누고 SDF의 값을 통해서 voxel안에서 3D의 위치를 interpolation을 했다. 이러한 과정은 물체의 날카로운 부분이 뭉개지는 현상이 발생하고, 얇은 물체의 경우 SDF의 값을 통해서 물체가 인식이 안되는 경우가 있다. 후자의 경우를 조금만 더 자세히 설명하면 우리는 SDF의 값이 양수인점을 통해서 물체 밖에 있다는 것을 알고, 음수인점을 통해서 물체 안에 있다는 것을 알 수 있다. 그리고 0이라는 부분이 물체의 경계라는 점을 이용해서 물체의 형태를 파악해왔다. 하지만 하나의 voxel안에 있는 정말 얇은 물체라면 어떻게 될까? 이 경우 voxel의 두 꼭짓점 모두 양수가 돼서 물체 밖이라고 인식되어 물체가 있는지 여부를 판단할 수 없다.
이와 같은 문제를 해결하기 위해서 이 논문에서는 SDF 방식을 이용하지 않고 모서리가 물체에 부딪힌 경우 해당 모서리 주변의 4개의 voxel 점들을 연결해서 하나의 face를 만드는 방식을 이용해서 정확한 기하학적인 정보를 찾는다. 아래에서 자세한 과정을 하나하나 살펴보겠다.
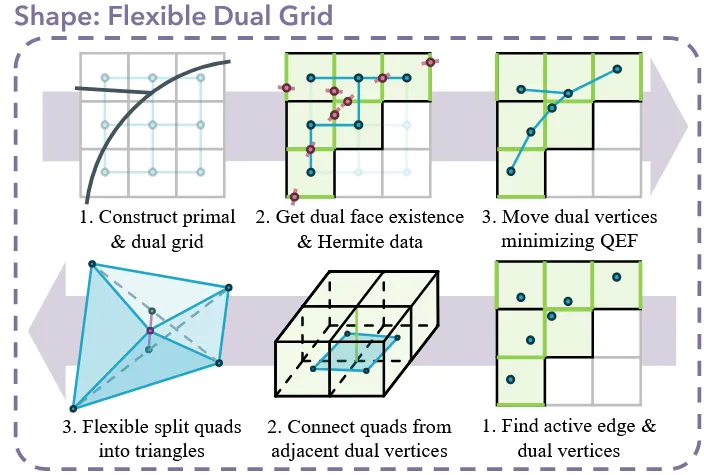
해당 과정이 조금 어렵기 때문에 최대한 쉽게 풀어서 설명해보겠다. 일단 이 방식은 Dual Contouring(DC) 알고리즘에서 영감을 얻었다. 기존 Marching cube 방식이 SDF의 부호의 변환을 통해서 물체의 유무를 확인하고, 이를 interpolation 해서 물체의 위치를 얻는다. DC는 물체 유무 확인까지는 동일하게 하고, Hermite Data를 이용해서 물체의 정확한 위치를 얻는다. Hermite Data는 물체가 부딪힌 위치와 그 물체의 normal값을 나타낸다. 여기서 기존 DC는 물체의 위치를 SDF를 이용해서 얇은 물체의 경우 인식되지 않는다는 한계가 존재했다. 이를 극복하기 위해서 논문에서는 SDF값을 이용하지 않고 부딪힌 위치를 직접 사용하는 방식을 이용했다.
위의 그림을 기반으로 조금 더 쉽게 설명해보겠다. 위의 그림은 Mesh → O-Voxel로 가는 과정을, 아래의 그림은 이의 반대과정을 나타낸다.
Mesh → O-Voxel
Construct primal & dual grid
위의 과정을 먼저 차례로 설명해보겠다. 우리는 새로운 NxNxN grid를 정의했고, 그림상으로 검정색 모눈종이가 이를 나타내고 Primal grid라고 정의한다. 각 grid안에 중심점을 파란색으로 찍고 이를 연결한 작은 grid를 dual grid라고 한다. 1번에서 설명한 primal, dual grid는 각각 설명했고 검정색 실선이 실제 물체라고 생각하면된다. Primal grid는 새로운 정형화된 공간에서 물체를 표현하기 위해서 우리가 정의한 grid이고, dual grid는 우리가 최종적으로 Primal grid에서 물체의 정확한 위치 좌표를 얻기 위해서 필요한 정보이다. Dual vertex자체가 학습할 때 ground truth가 되고, Dual grid의 각 점들을 연결해서 mesh의 face를 만들기도 한다.
Get dual face existence & Hermite Data
물체가 primal grid와 부딪히는 점과 부딪힐 때 물체의 face가 바라보는 방향 2가지 정보가 Hermite Data고 그림상 빨간점이다. 처음에 Sparse voxel 즉 물체가 있는 부분만을 표현한다고 정의했으므로, 물체가 있는 부분만 dual grid와 primal grid를 나타내고 나머지는 흰색 부분으로 표시한다.
Move dual vertices minimizing QEF
물체의 정확한 위치 즉 학습에 사용할 ground truth로 활용하기 위해서 위에서 dual vertex를 얻는것이 목표라고 언급했었다. Dual vertex는 dual grid의 각 점들을 Hhermite Data의 위치에 맞게 움직이는 QEF 과정을 진행하면서 얻을 수 있다. QEF는 하나의 Primal grid에 있는 모든 Hermite Data 점들의 위치와 방향 정보를 이용해서 겹치는 지점 하나를 만드는데 이 점이 dual vertex가 되는것이다. Hermite Data의 위치는 모서리에 종속되지만, dual vertex는 하나의 voxel안 어디든 가능하기 때문에 더 디테일한 위치를 표현할 수 있다.
O-Voxel → Mesh
Find active edge & dual vertices
위의 부분에서 우리가 dual vertex 이야기를 중점적으로 했는데 mesh를 복원하기 위해서는 active edge 즉 primal grid에서 물체와 부딪힌 edge인 active edge 값도 필요하다. 2개의 값을 기준으로 어떻게 다시 mesh를 생성하는지 아래 2단계를 설명해보겠다.
Connect quads from adjacent dual vertices
하나의 edge는 grid에서 4개의 voxel(cell)이 연결되어있다. 2번 그림을 보면 초록색 edge를 기준으로 4개의 voxel이 표현된 것을 확인할 수 있다. 이 edge를 기준으로 4개의 각 voxel의 dual vertex를 연결한 사각형이 이 edge에 해당되는 face가된다. 따라서 모서리 하나당 1개의 face가 생성된다.
Flexible split quads into triangles
4개의 점을 이어서 만든 사각형(face)는 항상 같은 평면에 존재하지 않는다. 이렇게 같은 평면에 존재하지 않은 점을 이어서 만든 사각형은 렌더링이 깨지거나 그림자가 이상하게 지게 된다. 따라서 삼각형 2개로 무조건 같은 평면에 존재하게 한다. 사각형을 삼각형으로 쪼개는 방법은 대각선이 2개이기 때문에 2가지 방법이 존재한다. 논문에서는 짧은 대각선을 선택해서 굴곡을 더 자연스럽게 표현할 수 있다고 했다.
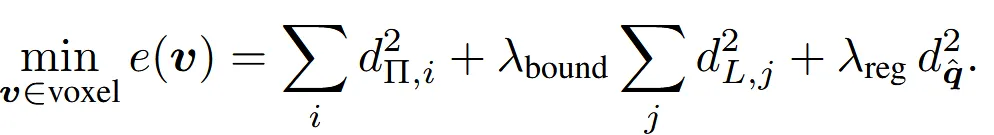
변환과정은 이제 완벽히 이해했으니 수식적으로 조금 더 자세히 살펴보겠다. QEF의 수식이 원래 DC에서는 맨 앞항만 존재하는데, 이 논문에서는 2개의 항을 추가했다.
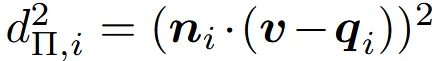
기존 첫번째 항의 수식은 위와 같다. Hermite data 와 dual vertex 를 위의 수식을 통해서 Hermite data가 나타내는 평면 에 제일 가까워지도록 하는 것이다. 이렇게 하나의 voxel안에 있는 모든 Hermite data에 위의 수식을 진행하는 것이 원래 DC의 방식이다.
첫번째 항만 존재할 경우 만약 모든 점들이 하나의 평면에서 표현된다면, 그 평면 위에 어디에있던 dual vertex는 적절하다고 판단될 것이다. 심지어 voxel밖에 있고 이 평면에 있더라도 적절하다고 판단되는 부적절한 현상이 나타난다. 왜냐면 우리는 dual vertex가 이 voxel안에 있길 기대하기 때문이다. 또한 만약 2개의 평면이 겹치지 않고 무한히 평행하다면 절대 교점이 생성되지 않아 dual vertex는 적절하게 생기지 않는다.
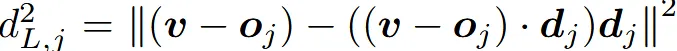
추가된 첫번째 항은 물체가 voxel안에 있으면서 디테일한 부분을 생성하기 위해서 추가했다. 여기서 는 물체의 끝 부분인 boundary edge의 시작점이고, 는 boundary edge의 방향이다. 위의 수식의 의미를 파악해보면 점 v에서 boundary edge까지의 최단거리 즉 수직인 거리이다. 이 거리를 최대한 짧게 한다는 의미는 vertex가 boundary edge에 존재하도록 유도하는 것이다.
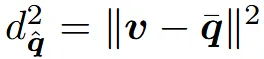
두번째 항은 Hermite Data의 위치 점들의 평균값에서 멀어지지 않도록 하는 수식이다. 만약 Voxel안의 평면들이 서로 평행할 경우 vertex의 위치가 무한히 먼 곳으로 보내질 수 있는데, 여기서는 Hermite Data의 위치와 너무 멀어지지 않도록 제약사항을 둬서 해당 경우를 방지한다.
이러한 긴 과정을 통해서 생성되는 은 결론적으로 dual vertex, edge intersection flags(edge activation), splitting weights(어느 대각선을 자를지에 대한 confidence) 3가지 정보를 담고있다. Flexible Dual Grid를 선택함으로써 빠른 양방향 전환이 가능하고, 어떠한 형태도 모델링할 수 있고 마지막으로 디테일한 부분을 잘 표현할 수 있는 방법이 되었다.
Volumetric Attributes for Material
이 부분에서는 material을 나타내는 을 어떻게 나타냈는지 설명한다. Material은 physicallybased rendering (PBR) 파라미터를 통해서 정의한다.
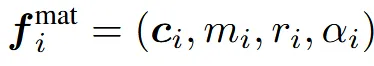
은 6차원으로 이루어져있다. 여기서 는 color로 3차원 정보를 갖고 있고, 는 metallic ratio로서 1차원 정보로 0부터 1사이의 값을 갖고, 는 roughness로서 동일하게 0~1사이의 값, 는 opacity로서 동일하게 0~1값을 갖는다.
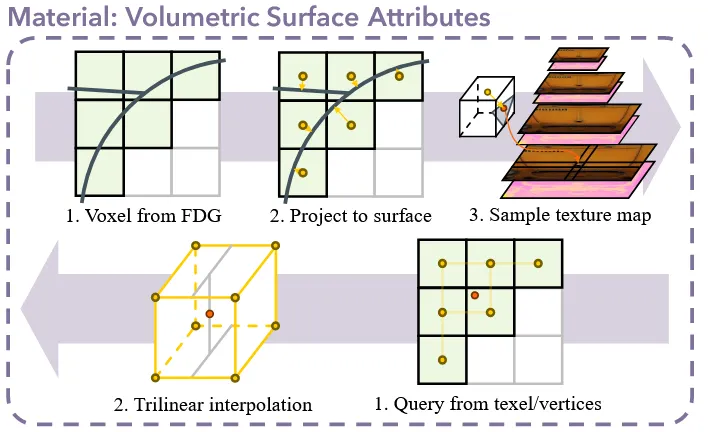
위의 그림은 이전처럼 윗부분은 Mesh에서 O-Voxel로 어떻게 material 정보가 변환되는지를, 아래 부분은 그 역과정이 나타나있다. 앞에서 우리는 active voxel(연두색 부분)을 구했다. Active voxel의 중심점에 대해서 물체와 가장 가까운 부분을 찾기 위해 projection 시킨다. Projection된 점에 해당하는 정보를 Texture map에서 가져와서 샘플링해온다. 매우 쉬운 과정이다.
O-Voxel에서 Mesh로 다시 색을 복구하는 과정에서 빨간색점처럼 우리가 정의한 노란 점의 위치와 겹치지 않을 수 있다. 따라서 Trilinear interpolation 과정을 통해서 빨간 점을 감싸고 있는 8개의 노란점을 거리에 비례해서 부드럽게 섞는다.
Sparse Compression VAE
O-Voxel을 더 압축된 latent 공간으로 보내기 위해서 VAE를 사용했다. 이 논문에서는 latent가 고해상도 3D를 생성할 수 있도록 설계하는 것을 목표로 했다.
Network Architecture
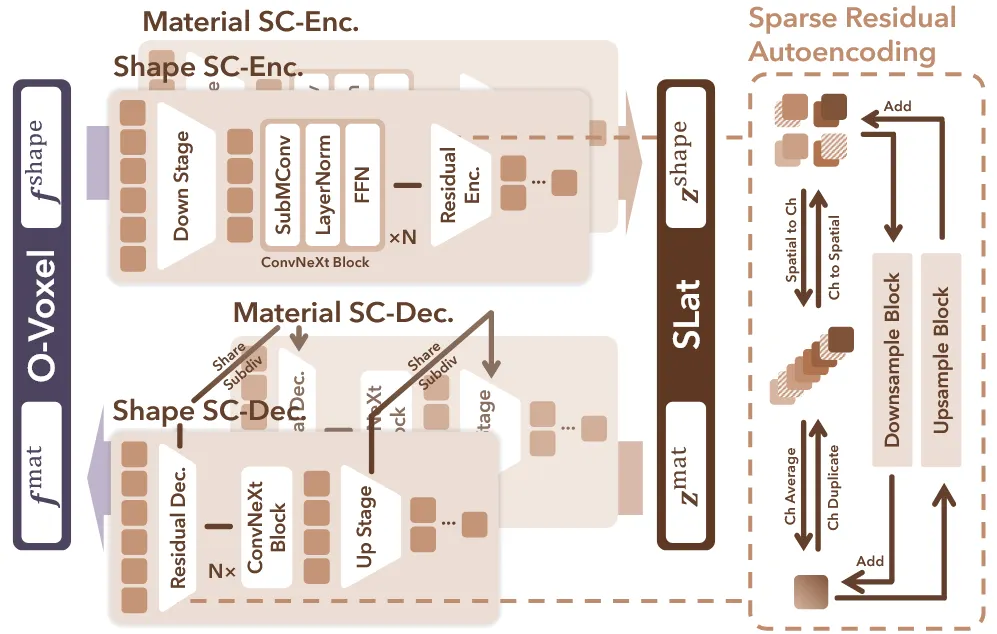
기존 3D VAE 방식들은 대부분 transformer 방식을 기반으로 아키텍처를 구성했지만, Sparse Compression VAE(SC-VAE)는 sparse-convolutional 네트워크를 이용해서 구성했다. O-Voxel자체가 sparse voxel 즉 활성화된 영역만을 다루기 때문에, 값이 들어있지 않은 부분의 연산을 생략하기 위해서 sparse-convolutional 방식을 선택했다.
Sparse Residual Autoencoding Layer
DC-AE 논문에서 사용한 Residual Sutoencoding 방식을 이용해서 파라미터 없이 sparse voxel을 압축했다. Downsampling 할 때 8개의 voxel을 하나의 차원으로 묶는다.
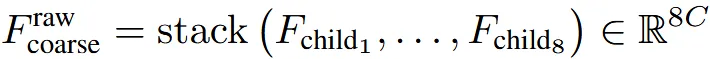
위의 수식과같이 8개의 voxel을 채널축으로 쌓아서 8차원을 갖고 해상도는 1/2배 압축된다. 기존 방식들은 2x2x2 덩어리를 1개로 합쳐서 정보손실이 발생하는데, 여기서는 단순히 채널축으로 확장했기 때문에 정보손실이 줄어든다.
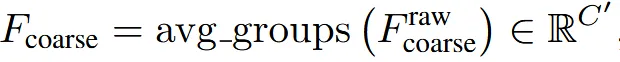
8차원은 너무 크기 때문에 이를 다시 2차원정도로 4차원씩 평균내어 최종적으로 채널 압축을 하게된다. 여기서 궁금했던게 그러면 결론적으로 기존이랑 동일하게 채널이 압축되어서 정보손실이 나타나지 않냐라고 생각이 들 수 있는데, 첫번째로 여기서는 voxel들을 채널축으로 쌓는 과정에서 공간상의 위치정보를 채널상에서 나타낼 수 있고, 이를 위치상 유사한 부분끼리 평균내었기 때문에 위치정보가 더 잘 보존된다.
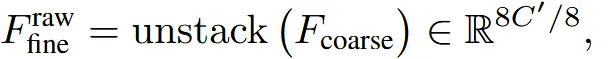
업샘플링 과정은 다운샘플링을 반대로 진행하면된다. 일단 해상도가 1/2배, 채널이 2배 늘었으니 반대로 해상도를 2배, 채널을 1/2배 늘리면된다. 예시를 통해서 설명하면 우리가 지금 이 해상도가 1, 채널이 64라고하면, 업샘플링된 우리의 목표 는 해상도가2, 채널이 32가 되어야한다. 따라서 일단 해상도가 2배가 되기 위해서 필요한 voxel의 수는 2x2x2=8개다. 의 채널을 필요한 voxel의 개수인 8로 나눠서 하나의 voxel당 8개의 차원을 갖도록 한다. 그러면 지금 해상도가 2이고 채널이 8인 가 나온다.
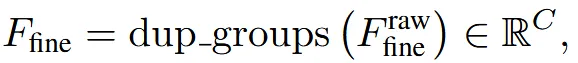
우리가 최종적으로 원하는 차원은 32이기 때문에, 8차원을 채널축으로 4번 동일하게 복사()해서 우리가 원하는 를 얻는다.
Early-pruning Upsampler
계속 언급중이지만 논문에서는 sparse-voxel 즉, 비어있는 영역에 대해서는 계산을 하고싶지 않은 상태이다. 따라서 ‘Learning transferable visual models from natural language supervision’ 논문에서 사용한 early-pruning 방식을 사용했다. Early-pruning은 업샘플링을 하기전에 binary mask 를 예측해서 voxel이 비어있는지 여부를 확인한다. 비어있다고 예측한 부분에 대해서는 계산량을 생략함으로써 메모리를 아낄 수 있게 된것이다.
Optimized Residual Block
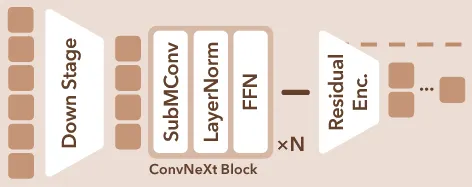
Sparse convolution을 사용해서 효율적인 계산이 가능했지만, 역설적으로 계산량이 줄어서 복잡한 3D 모양을 학습하지 못할 수 있다. 따라서 논문에서는 residual block의 구조를 수정함으로써 이를 보완했다.
2D에서 높은 성능을 낸 ConvNetXt-style을 적용하기 위해서 기존의 2개로 구성된 conv layers를 1개로 수정하고, normalization과 activation layers를 줄였다. 두번째 conv layer는 point-wise MLP를 통해서 채널축으로 확장했다가 다시 축소하는 과정을 통해서 point 각각의 디테일한 부분의 학습을 가능하게 했다. 이는 메모리 효율성을 높이면서도 디테일한 부분을 학습할 수 있게 설계한 방식이다.
위의 그림이 아키텍처인데 SubMConv 1개의 sparse convolution을 의미하고, LayerNorm은 normalization을 한번, 그리고 FFN이 point-wise MLP이다. Activation은 FFN에 있기 때문에 생략된 것으로 추정된다.(자세한 내용은 ConvNetXt-style을 참고해봐야될거같다)
VAE Training
Stage 1
SC-VAE는 두단계로 학습이 진행된다. 첫번째 단계에서는 저해상도의 데이터로 빠르게 모델을 학습한다.
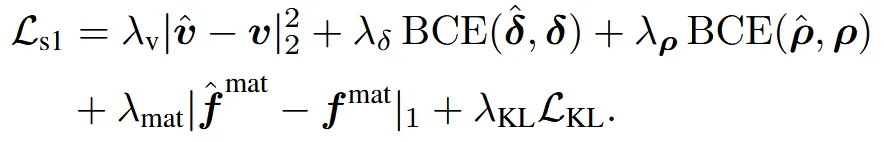
1~3항은 Geometry 부분을 위한 loss, 나머지 4번째 항은 material 마지막항은 latent의 분포에대한 loss이다. 첫번째 항은 dual vertex를 잘 찾는지에 대해서 MSE loss를, 두번째 항은 edge intersection flags를 잘 찾는지 유무를 확인하기 위한 BCE loss를, 마지막으로 세번째 항은 업샘플링 할 때 비어있는 voxel을 잘 예측하는지에 대한 BCE loss이다.
Material 부분에서는 4번째 항을 통해서 material의 feature를 잘 예측하는지에 대한 L1 loss, 마지막항은 latent가 정규분포를 따르는지에 대한 KL Divergence이다.
Stage 2
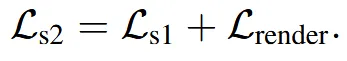
Stage2에서는 고해상도 데이터에 대해서 rendering 기반 인지 학습을 통해서 모델을 학습한다. Mask, depth, normal maps에 대해서 L1 loss를, normal을 augmentation 한 이미지는 SSIM과 LPIPS를 진행한다. 렌더링할 때 물체에 가까운부분에 카메라를 랜덤하게 설정해서, 물체의 내부도 렌더링 되도록 했다. 이를 통해서 물체 외부 뿐만아니라, 내부도 정확하게 예측할 수 있도록 됐다.
VAE는 Geometry와 Material을 분리해서 2개를 각각 예측하도록 설계했다. VAE 구조는 2개가 모두 동일한데 Geometry VAE를 먼저 학습시키고, Material VAE는 Geometry VAE의 binary mask 예측하는 부분만 학습없이 그대로 사용하도록 설정했다. 당연히 2개의 VAE에 학습에 사용되는 입력과 출력은 각각의 형태에 맞게 설정되어있다.
Generative Modeling
생성 부분은 Trellis1과 거의 똑같다.
Model and Generation Pipeline
sparse structure generation는 sparse voxel grid 유무를 예측하고, geometry generation은 최종적인 geometry 형태를 예측한다. 2개의 구조는 Trellis1과 동일하다. 추가적으로 예측하는 material generation은 geometry generation 결과를 입력으로 받고 최종적으로 PBR material을 예측하도록 설계됐다.
Architectural and Training Details
DiT 모델의 큰 구조는 Trellis1과 동일하고 요기에 적용되는 기법들만 최신 모델들로 수정했다고 보면된다. AdaLN-single modulation, Rotary Position Embedding (RoPE), DINOv3-L이 수정된 최신 모델들이다. 또한 VAE가 개선됐기 때문에 기존 복잡한 convolutional packing과 skip connection은 제거하고 vanilla DiT를 사용했다.
학습은 초기에 32채널의 512 x 512 해상도를 이용했고, 이후 해상도를 확장해 64채널의 1024 x 1024를 이용했다.
Experiments
Implementation details
Trellis-500K 데이터셋으로 SC-VAE를 학습했다. 학습하는데 16개의 H100 GPU를 사용했고 배치사이즈는 128이었다. TexVerse에서 사용한 800K 데이터셋을 이용해서 generative model을 학습했다. Generative model의 총 파라미터는 1.3B개이고, 32개의 H100 GPU를 사용했고 배치사이즈는 256이다.
3D Asset Reconstruction
Shape Reconstruction
Dora, TRELLIS, Direct3D-s2, SparseFlex 4개의 모델과 비교를 진행했다.
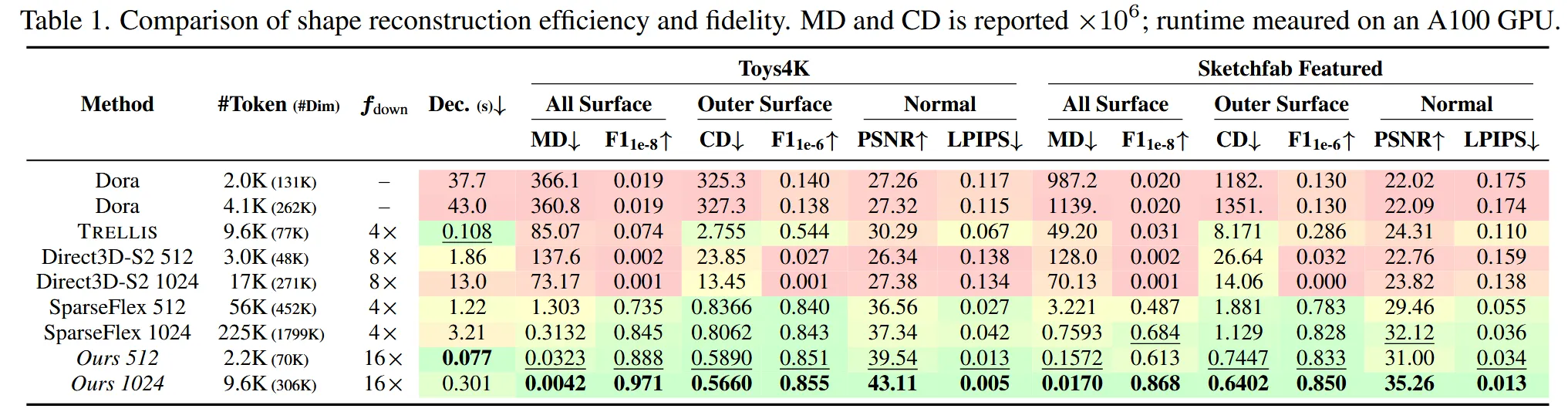
Mesh Distance(MD): Point-to-Mesh Distance with F1-score라고 나와있는데 조금 더 자세히 설명하면, 생성한 mesh가 한번은 pointcloud, 한번은 mesh가 되고 ground truth는 생성 mesh가 pointcloud이면 mesh 반대로 mesh이면 pointcloud가 된다. 이렇게 서로다른 상황에서 point cloud의 한 점에서 mesh에서 triangle 중 가장 가까운 거리를 측정해서 생성된 결과가 얼마나 기존 결과와 일치하는지 정도를 point-to-mesh distance를 측정하고 이렇게 두번 측정하면 precision, recall값이 나오기 때문에 이를 F1 score를 이용해서 나온 최종값이 Mesh Distance가 된다. 여기서 측정하는(생성된) 결과물이 point cloud인 경우 잘 생성됐는지 확인하니까 Precision, mesh인 경우 정답과 비교해서 빼먹은 부분을 측정하니까 Recall이다. 따라서 Mesh Distance는 밖에 보이는 부분 뿐만아니라, 안에 있는 부분까지 정확도를 측정할 수 있다.
위의 표에서 MD는 단순히 생성된게 mesh이거나 point cloud일 때 측정한 거리의 평균이고, F1이 여기서 측정한 거리에 임계치를 줬을 때 생성된 F1값이라고 보면된다.
Chamfer Distance(CD): 여러뷰에서 ray를 쏴서 첫번째로 부딪힌 point들을 샘플링해서 얻고, 동일한 뷰에서 얻은 point 끼리 비교해서 나온 거리가 Chamfer Distance다. Ray를 통해서 첫번째로 부딪힌 point들이다 보니, 안쪽보다는 바깥쪽 물체의 정보만을 담고있다. 이렇게 비교한 거리들에 대해서 우리가 임계치를 정해서 성공 실패 여부를 나눌 수 있다. 여기서도 비교대상에 따라서 Precision과 Recall값이 바뀐다. 생성한 모델의 point cloud 하나에 대해서 모든 ground truth point cloud와 비교하면 precision 반대면 recall이다.
위의 표에서 CD는 point cloud 거리가 2번 나오니까 이 거리의 평균이 CD이고, 여기서 임계치를 기반으로 2개의 값을 비교한게 F1이다.
surface quality metrices: 동일한 뷰에서 랜더링한 생성한 mesh의 이미지와 GT mesh의 이미지를 비교해서 PSNR(픽셀끼리 비교해서 노이즈가 얼마나 낀지)와 LPIPS(임베딩끼리 얼마나 유사한지)를 확인한다.
위에 설명한 3가지 지표가 가장 좋은 것을 확인할 수 있었다. 추가적으로 왼쪽에 나와있는 Toekn은 latent의 크기를 나타내고, 은 해상도를 얼마나 압축했는지, 는 최종 mesh가 나오는데 걸리는 시간이다.
Material Reconstruction
비교할 baseline model이 없어서 TRELLIS2만 PBR attribute map과 shaded 이미지를 렌더링해서 ground truth와 비교했다. 조명 유무에 따라서 비교한 2개의 이미지를 비교하면서 신뢰도를 높였고, PBR에 대해서는 38.89 dB / 0.033, shaded image에 대해서는 38.69 dB / 0.026를 각각 PSNR과 LPIPS score를 기록했다.
Image to 3D Generation

Image-to-3D 결과를 위의 그림을 통해서 확인할 수 있는데, 디테일한 부분이 잘 생성된 것을 알 수 있다. 아래에 생성된 여러개 작은 결과는 material 생성과정을 나타낸다.
Qualitative comparison

확실히 Hunyuan3D 2.1로 geometry 측면에서는 퀄리티가 진짜 좋은 것을 알 수 있는데, 여기서 PBR까지 포함하면 디테일한 부분은 Trellis가 이그림상에서는 더 좋아보인다.
Quantitative comparison
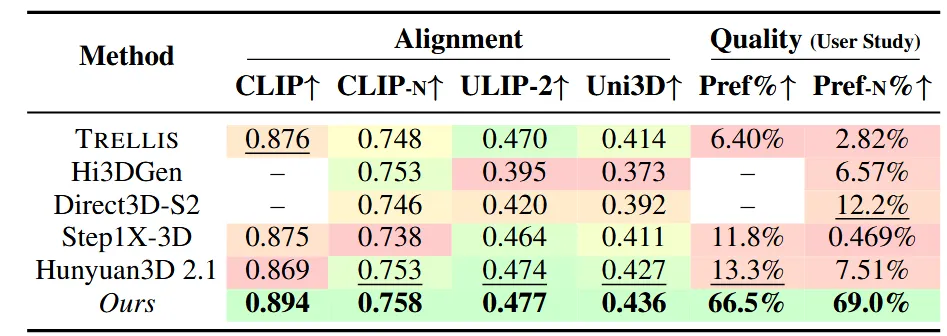
입력 이미지와 렌더링한 RGB 이미지를 비교하는 CLIP, 렌더링한 Normal과 비교하는 CLIP-N, 입력 이미지와 생성된 3D를 비교하는 ULIP-2, Uni3D 모두 가장 높은 성능을 냈다. 사실 이 지표들은 Hunyuan3D-2.1과 유사한데 맨 오른쪽 User study는 Trellis2가 가장 좋게 나왔다.
Shape-Conditioned Texture Generation
3D mesh와 입력 이미지가 주어졌을 때 texture를 잘 생성하는지 비교하는 부분이다. Hunyuan3D-Paint와 UV-based TEXGen 2가지 baseline 모델과 비교를 진행했다.
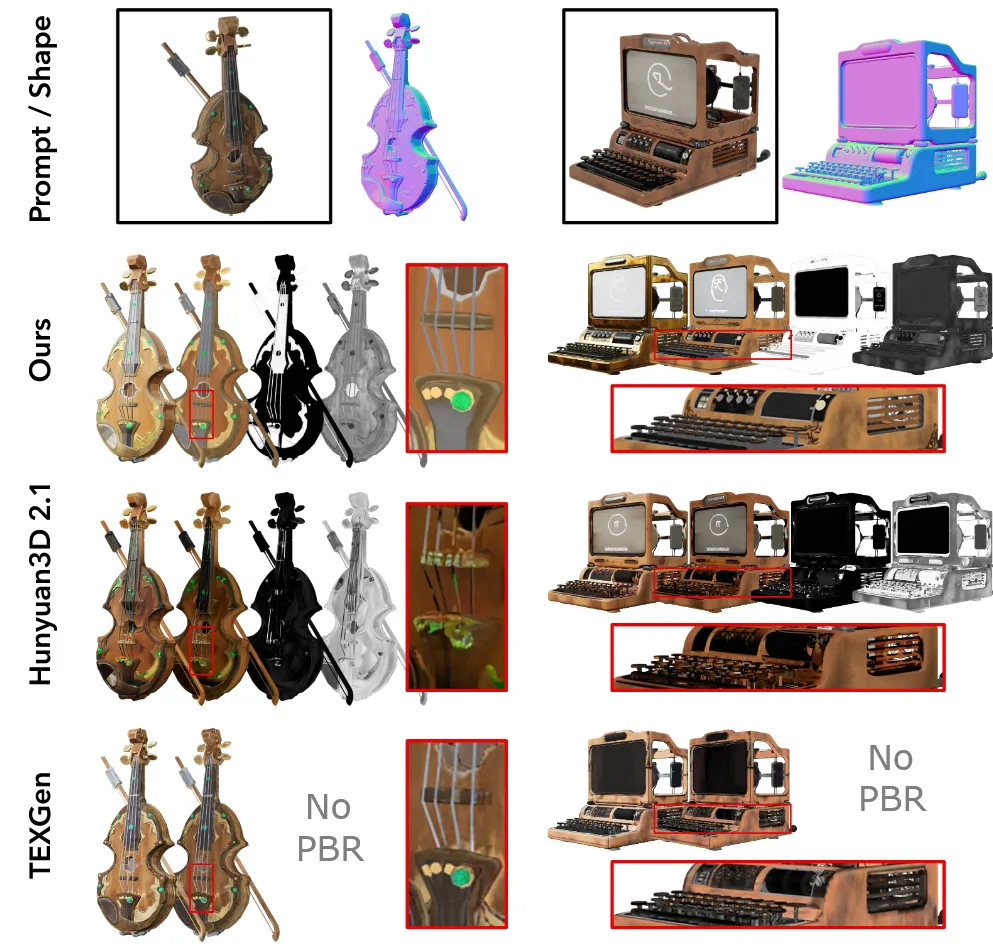
멀티뷰 방식을 이용하면 3D texture가 일치하지 않는 현상들이 발생하는 것을 Hunyaun3D 2.1을 통해서 확인할 수 있고, UV 기반 방식은 seam현상이나 퀄리티가 낮은 것을 TEXGen을 통해서 확인할 수 있다.
Ablation and Design Analysis
Ablation study는 모두 해상도에서 진행됐다.
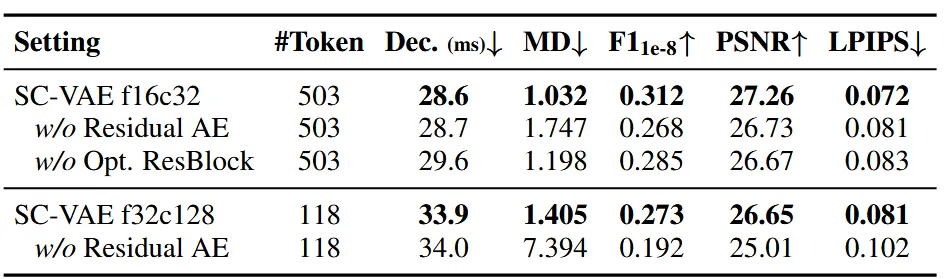
Sparse residual autoencdoer의 구조를 분석하는 Ablation study이다. w/o Residual AE는 채널차원으로 voxel을 쌓는게 아니라 단순히 평균내고, decoder에서는 단순히 이웃 값을 사용하는 방법이다. Latent차원이나 결과가 나오는 시간 차이는 거의 없지만, 결과 특히 MD에서는 많은 차이가 있다. Voxel의 유무를 binary mask로 예측하는 Opt. ResBlock 유무도 미미하지만 결과에 차이를 준다.
Test-time Compute and Resolution Scaling

왼쪽 자동차그림은 입력으로 1024차원의 mesh를 넣었는데 1536의 해상도 차원을 출력할 수 있는 Scale up이 가능하다는 점을 밝혔다. 오른쪽 그림은 처음에 1024 해상도를 한번에 생성하는 것보다, 512 해상도로 O-Voxel을 만들고, 이를 1024 해상도로 확장했을 때 3초가 추가되지만, 더 디테일한 결과를 얻을 수 있다고 주장한다.
Conclusion
Open surface등 다양한 mesh들에 대해서 디테일한 geometry와 material 정보를 다룰 수 있는 O-Voxel을 정의했고, Sparse Compression VAE를 이용해서 기존보다 더 압축된 공간으로 latent에 보낼 수 있게 됐다. Flow-matching models 통해서 입력 이미지의 디테일한 geometry와 texture를 최종적으로 생성할 수 있다.
Limitation Discussion and Future Work
Supplementary에 있는 limitation을 다뤄보겠다.
- Voxel에는 하나의 표현만 가능하다는 제약조건
Voxel하나에 여러개의 디테일한 정보가 있을 경우 이를 평균내서 하나로 표현해야 된다. 따라서 2개의 정보가 혼합돼서 하나로 표현되어 artifact가 발생한다.
- 생성된 결과물에 hole이 포함된다.
생성된 mesh에 바늘구멍과 같은 작은 구멍들이 생성된다. 하지만 이러한 구멍들은 hole-filling을 통해서 해결할 수 있다. 이렇게 구멍이 뚫리는 이유는 sparse convolution이 띄엄띄엄 계산을 하기 때문이다.
- 의미론적인 정보가 없다.
모델이 geometry와 material은 잘 예측하지만, 구조적이나 의미론적인 정보는 잘 모른다. 구조와 의미론적인 정보를 안다면 segmentation과 rigging이 쉬워지기 때문에 이는 future works로 언급했다.
