VoxHammer: Training-Free Precise and Coherent 3D Editing in Native 3D Space [2025 arXiv]
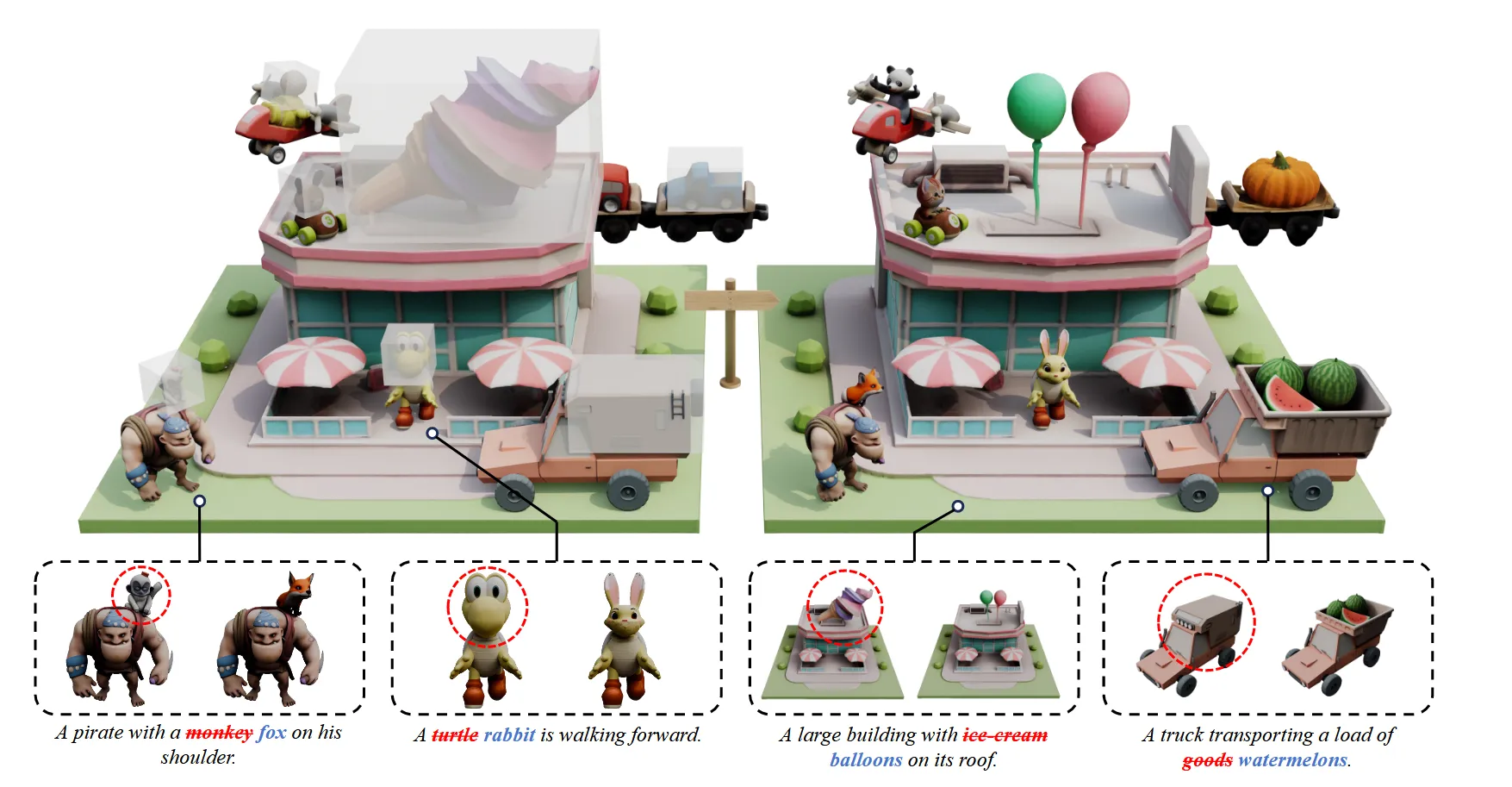
해당 논문은 3D model을 text prompt에 맞게 변형을 진행하는 모델을 계발 했습니다. Trellis 모델을 학습없이 inversion과 editing을 통해서 high-quality의 결과를 만들 수 있다고 했는데 어떻게 이를 가능하게 했는지 살펴보도록 하겠습니다. 또한 해당 논문에서 자체적으로 Edit3D-Bench라는 데이터셋도 공개 했는데 어떤 데이터셋인지도 확인해보겠습니다.
Method
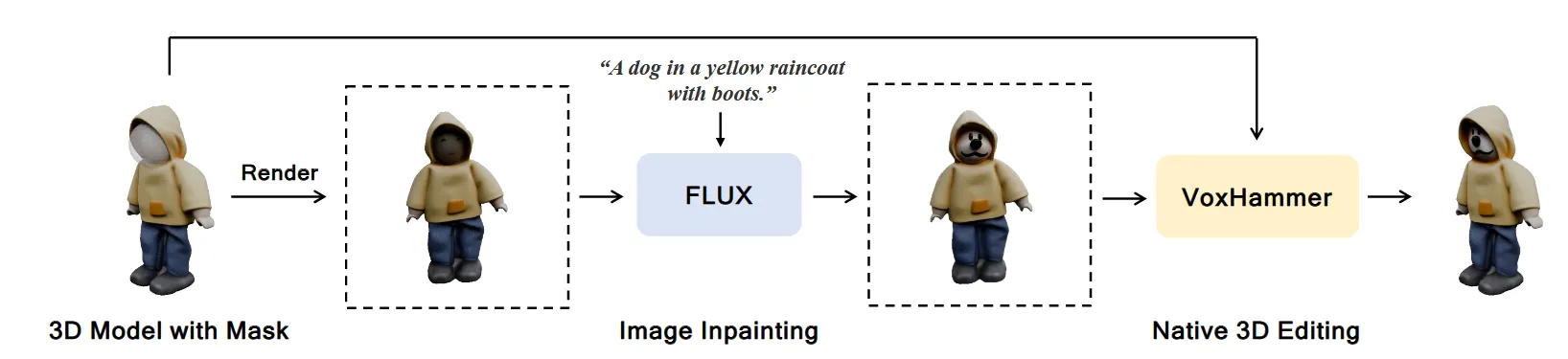
모델의 아키텍처는 위와 같습니다. 입력으로 3D model, 수정하고자 하는 영역의 mask, 그리고 원하는 text prompt를 넣으면 FLUX를 이용해서 렌더링된 이미지를 text prompt에 맞게 변형시킨 후(Image inpainting) 이를 VoxHammer를 이용해서 3D로 변형시킵니다.
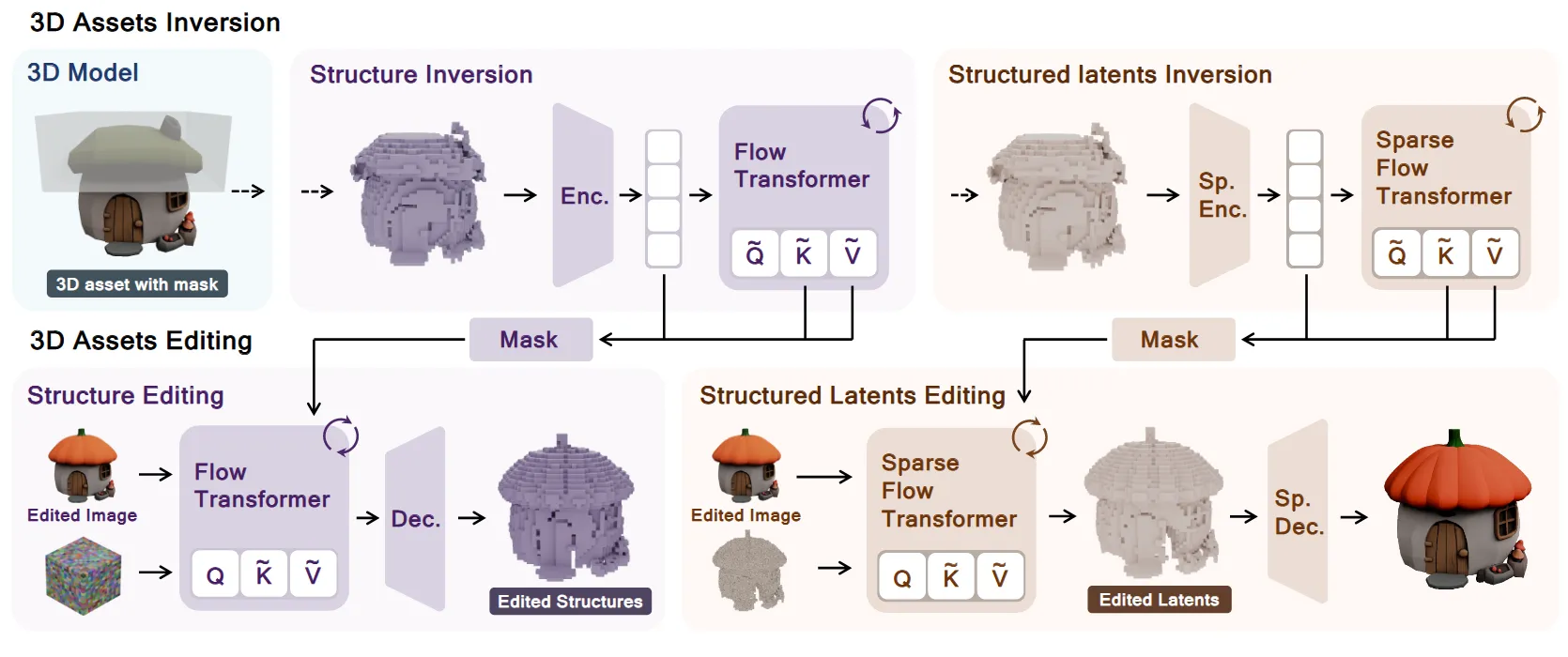
VoxHammer의 구조는 위와 같습니다. 3D asset을 노이즈 형태로 변환한 뒤, denoising process에서 사용할 key-value 토큰을 저장해둡니다.
Preliminary
Structured 3D diffusion models
해당 파트에서는 baseline 논문인 Trellis의 개념을 설명합니다. 자세한 설명은 https://velog.io/@guts4/Structured-3D-Latents-for-Scalable-and-Versatile-3D-Generation2025-CVPR-Spotlight를 참조하시길 바랍니다. 간단히 설명하면 3D model을 grid 형태로 나눠서 각 voxel 별로 값을 예측하는 방법입니다. 크게 대략적인 구조를 예측하는 structure(ST) stage와 이를 기반으로 각 voxel의 geometry, texture와 같은 디테일한 latent를 예측하는 sparse-latent (SLAT) stage로 구성되어 있습니다.
Rectified Flow Inversion
Rectified Flow Inversion 방식을 이용해서 editing을 진행한 많은 연구들이 있었습니다. 하지만 1차 오일러 적분을 사용할 경우 수치 오차가 누적되어서, inversion 결과가 원본에서 벗어나는 경우가 나타납니다. RF-Solver는 이러한 현상을 방지하기 위해서 high-order Taylor expansion를 사용 했습니다.
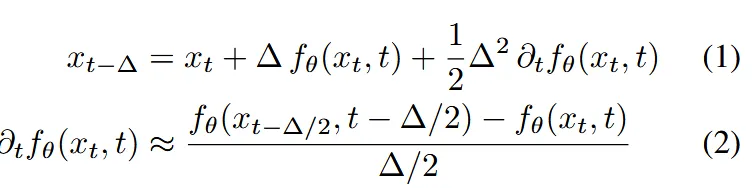
수식(1)에서 첫번째, 두번째 항이 일반적인 1차 오일러 적분을 활용한 inversion인데, 세번째 항이 추가되면서 RF-Solver의 2차 테일러 보정 오일러을 활용한 것입니다. 2차 적분을 직접 구할 수 없기 때문에 반스텝 뒤의 velocity field와 현재 스텝의 velocity field의 차이를 시간 간격으로 나눈 값으로 근사해서 사용합니다.
3D Inversion
Inversion 과정은 Trellis의 structure(ST) stage와 sparse-latent(SLAT) 과정에서 모두 진행됩니다. ST단계에서는 2차 taylor inversion 해서 모든 attention layer의 K/V token을 time step별로 에 저장해두고, SLAT 단계에서는 편집 제외 영역()만을 뽑아서 해당 특징을 정규화 한 뒤 2차 taylor inversion을 돌려서 에 저장해둡니다.
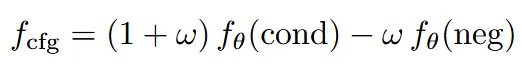
2개의 과정에서 time step이 [0.5, 1.0]일 때 classifier-free guidance(CFG)를 사용합니다. 이렇게 후반부에만 CFG를 사용할 경우 표현력이 좋아져서 보존하는 영역이 더 날카롭게 복원됩니다.
3D Editing
한마디로 inversion을 통해서 나온 latent와 K/V를 매 time step에서 사용해서, 더 정확하게 해당 영역을 보존할 수 있는 방식입니다.
Latent replacement
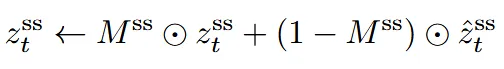
Structure (ST) 단계에서 latent replacement는 binary edit mask()를 기반으로 진행됩니다. 위의 수식처럼 매 step t에서 latent는 편집하고자 하는 영역이 아닌 곳()에서는 원본 3d asset에서 inversion을 통해서 얻은 step t에서의 latent()를 이용합니다. 마스크 영역에 생기는 seam(선)들을 제거하기 위해서 dilation과 gaussian falloff를 통해서 soft mask로 변환합니다.
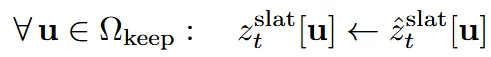
Sparse-latent (SLAT) 단계에서는 ST 결과를 기반으로 인덱스를 생성해서 이를 기반으로 recitified flow가 진행되기 때문에, 마스크 방식보다는 인덱스를 기반으로 정확하게 수정하는 영역을 위와 같이 영역으로 지정해서 수정하지 않는 영역은 덮어 씌우도록 설정했습니다.
Key-value replacement
Latent를 보존하는 것 뿐만아니라 attention mechanism에서 사용하는 Key & Value 값까지 덮어씌움으로써 완벽하게 원본을 보존하는 방식을 채택했습니다.
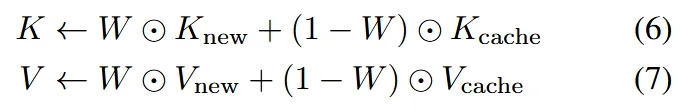
여기서도 캐시된 값과 새로운 값을 사용하는 유무는 binary masks(W)입니다.
Experiments

Ablation study
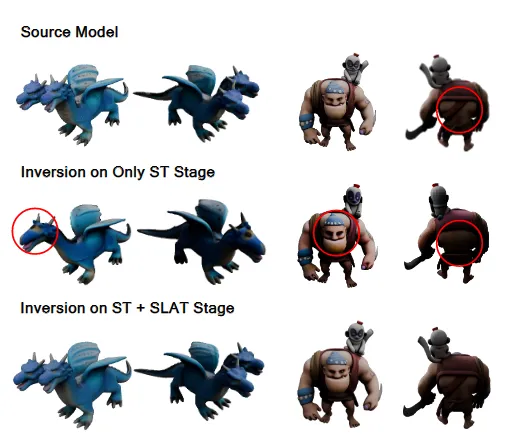
Inversion을 ST에서만 진행할 때, SLAT에서도 같이 진행할 때의 차이를 보여주는 결과입니다. 디테일한 부분(얼굴이 두개, 뒤에 끈)을 적용하기 위해서는 SLAT stage에서도 inversion을 진행해야 함을 보여줍니다.

3번째 줄이 KV의 attention을 보존하지 않고 latent replacement만 진행할 경우의 결과입니다. 확실히 전체적인 형태가 많이 망가지는 것을 확인할 수 잇습니다.
4번째 줄은 initial 값을 3d asset이 아닌 random gaussian noise에서 시작하는 경우입니다. 이 경우 새로운 부분이 생성되는 현상이 나타날 수 있습니다.
