Structured 3D Latents for Scalable and Versatile 3D Generation[2025 CVPR Spotlight]
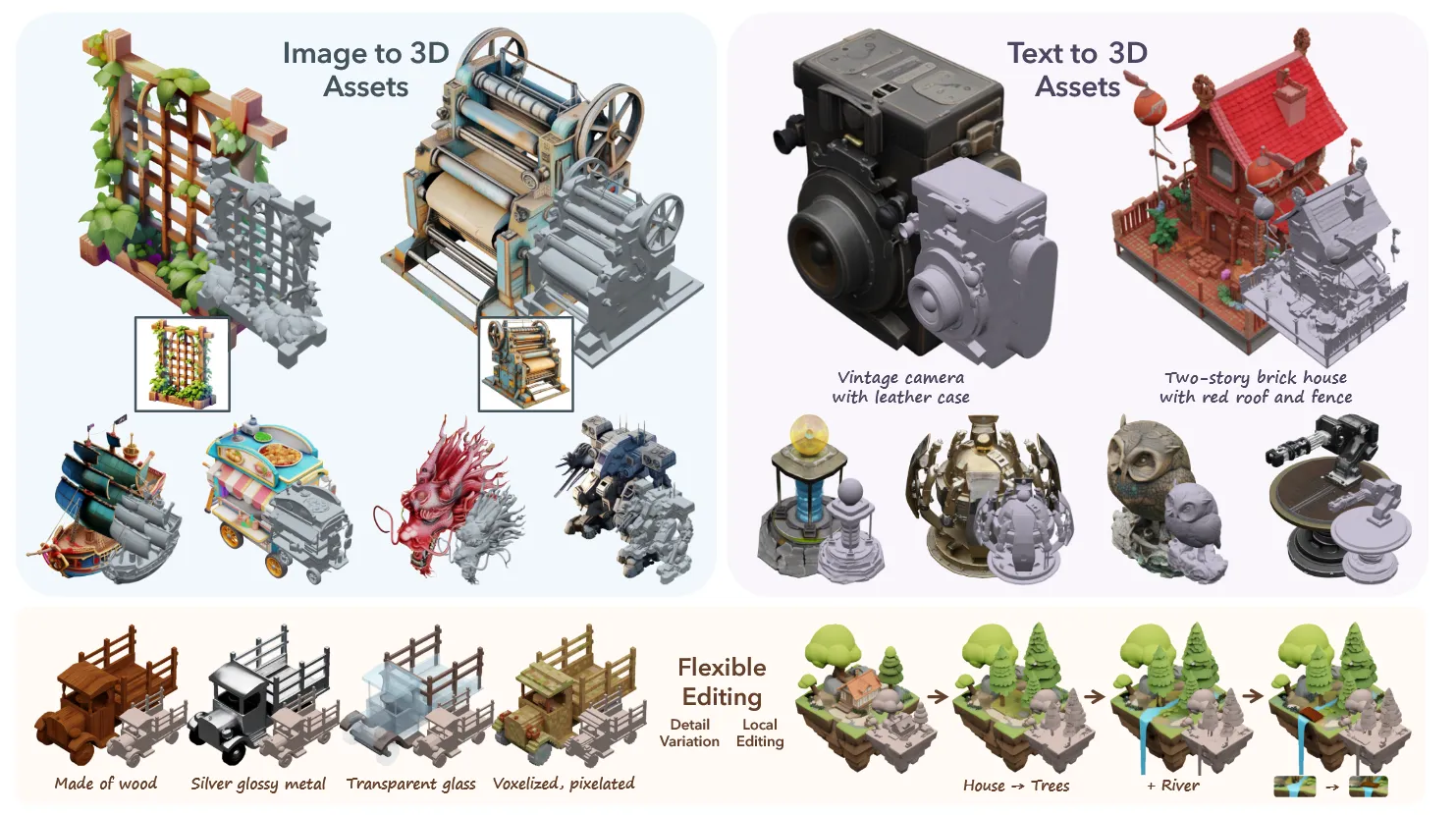
2025 CVPR Spotlight를 받은 마이크로소프트에서 만든 Trellis 논문입니다. 위의 그림에서 볼 수 있는 것처럼 Image, Text로부터 10초만에 3D를 생성할 수 있고, 아래 부분처럼 자연스러운 3D editing도 가능하다고 언급했습니다. 어떻게 이를 가능하게 했는지 한번 살펴보도록 하겠습니다.
Method
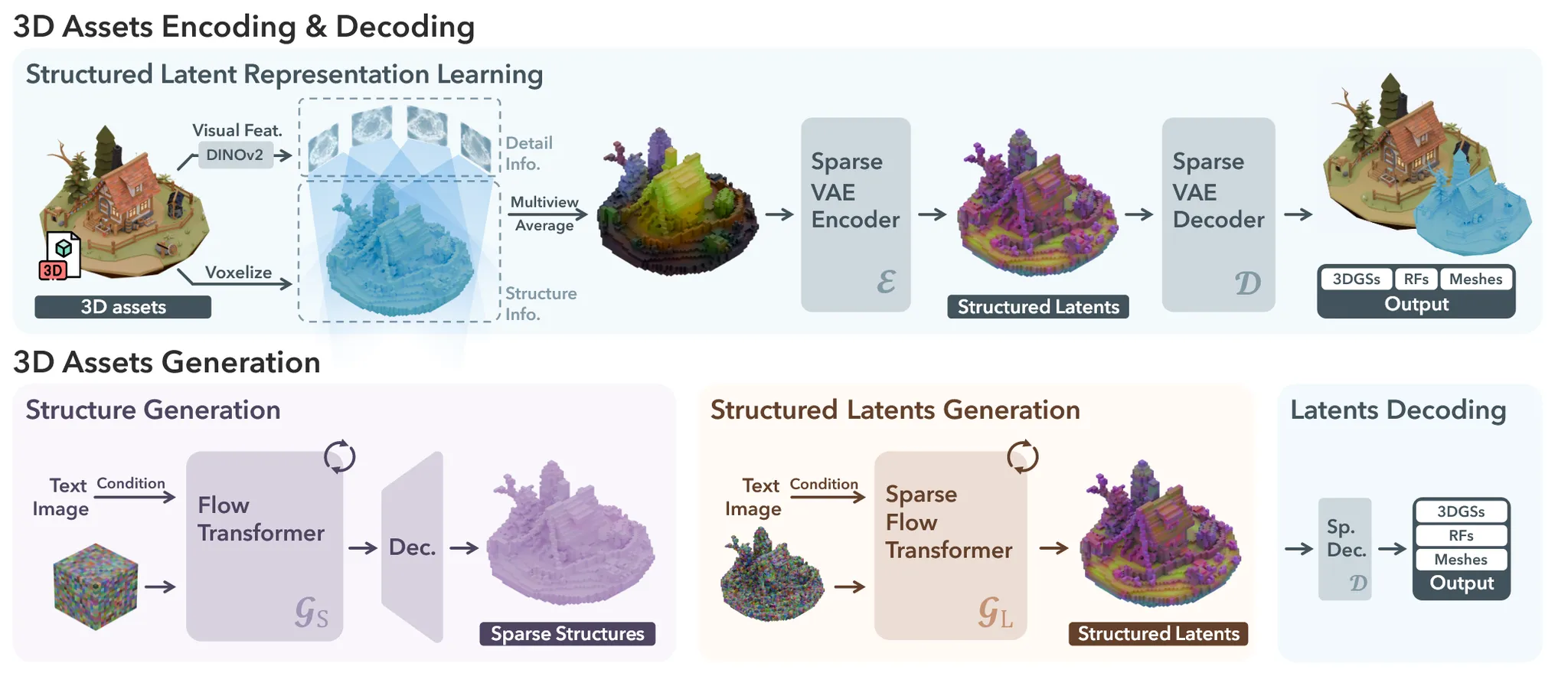
Image나 Text가 들어왔을 때 다양한 형태(NeRF, 3D GS, asset)로의 변환이 가능한 모델인 Trellis의 아키텍처는 위와 같습니다.
Structured Latent Representation
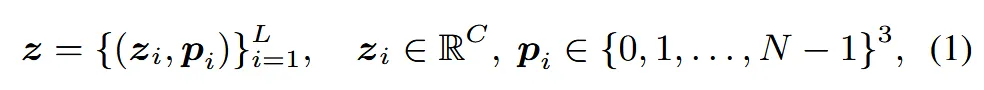
3D asset O의 기하학적인 정보와 형태 정보를 모두 저장하는 encoder를 만들기 위해서 3D grid 형태로 나눈 뒤 각 격자를 latent representation으로 변환합니다.
조금 더 자세히 설명해드리자면 3D asset을 3D grid로 나눈 뒤, 표면과 교차하는 voxel만을 L개 선택합니다. L개의 voxel들은 각각 어떤 grid에 속하는지에 대한 인덱스 와 encoder를 통과한 후 latent 값인 를 갖도록 변환됩니다(encoder는 아래 단락에서 설명). 인덱스는 0~N-1까지 총 N개의 grid중에서 어떤 grid에 속하는지를 나타내고, latent 값은 기하학적인 정보와 형태 정보를 모두 저장하고 있습니다.
당연히 표면과 교차하는 voxel의 개수 L은 3d model마다 다른 값이 나올 것이고, L이 평균적으로 20K개 나오기 때문에 논문에서 N의 값을 64개로 설정했습니다.
Structured Latents Encoding and Decoding
위에서 각 voxel들이 latent로 변환되는 과정을 자세히 설명해드리도록 하겠습니다.
Visual feature aggregation
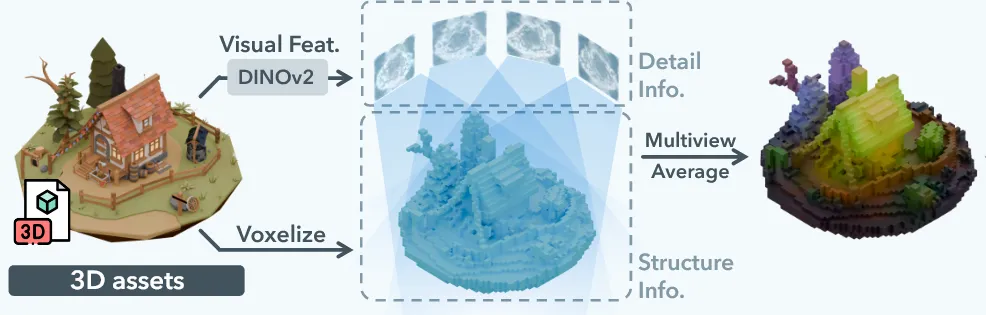
우선 3D asset을 voxelized feature 로 변환하는 방법에 대해서 설명해드리겠습니다. 여기서 말하는 는 이전에 설명드린 active voxels로 L개의 voxel들입니다. 를 추출하기 위해서 랜덤한 카메라 뷰에서 렌더링한 이미지를 DINOv2를 이용해서 feature를 추출한 다음, 이를 평균내서 구합니다. 의 해상도는 structured latents z의 해상도와 동일하게 이고, 각각의 는 기하학적인 정보와 외양 정보를 담고 있습니다.
Sparse VAE for structured latents
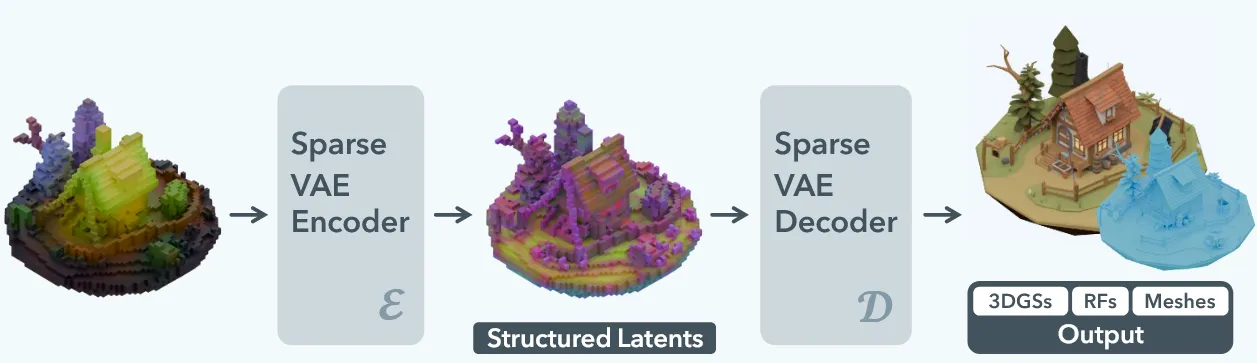
위와 같이 voxelized feature를 구한 뒤, transformer-based VAE architecture를 이용한 Encoder-Decoder 구조를 사용해서 structured latents를 구합니다.
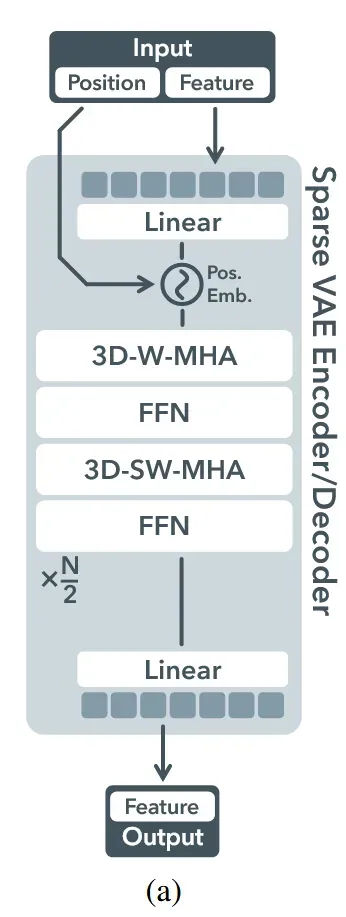
Encoder-Dcoder 구조는 transformer와 동일한 것을 그림을 통해서 확인할 수 있습니다. 희귀한 voxel들을 다루기 위해서 입력 voxel에 positional encoding을 추가하고, local information을 다루기 위해서 shifted window attention도 추가했습니다. 학습은 reconstruction loss와 에 대한 KL-penalty를 함께 두어서 end-to-end로 진행합니다.
사진을 통해서 Encoder-Decoder 구조를 조금 더 자세히 설명하면, Linear layer를 통해서 position Encoding의 결과 크기와 동일하게 변환한 뒤 2개를 합치고, 이를 각 블록에 통과시킵니다. 블록들 중 3D-W-MHA는 Window Multi-Head Attention으로 voxel 좌표를 기준으로 WxWxW 비중첩 3D 창들로 분할해서 해당 창 영역들끼리 self-attention을 진행해서 연산량을 줄이면서 지역적인 정보를 유지할 수 있도록 합니다. 이후 3D-SW-MHA 블록은 3D-W-MHA를 한번 더 진행하되 Shifted 즉 다른 이웃들과 묶이도록 창 배치를 이동시키는 것입니다.
Decoding into versatile formats
3D Gaussians, Radiance Fields, and meshes를 최종 결과로 얻기 위해서 Decoder를 3개를 만듭니다. 3개의 Decoder는 마지막 output layer를 제외하고는 동일한 아키텍처를 사용합니다. 학습할 때는 각 출력에 맞는 loss를 사용합니다.
3D Gaussian
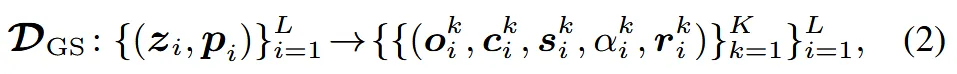
3D GS Decoder의 loss는 위와 같습니다. 각각의 latent 는 K개의 gaussain으로 변환되는데 이때 각 gaussian은 위의 수식과 같이 (o: offset, c: color, s:scale, : opacity, r: rotation)으로 이루어져있습니다. 최종적으로 L개의 voxel들이 존재하기 때문에 L X K개의 gaussian이 존재하고, 각 gaussian의 중심점 로 voxel에서 약간의 offset만큼만 변환되도록 설계 됐습니다. Reconstruction loss는 렌더링된 이미지와 실제 이미지 사이의 L1, D-SSIM, LPIPS로 구성되어 있습니다.
Radiance Fields
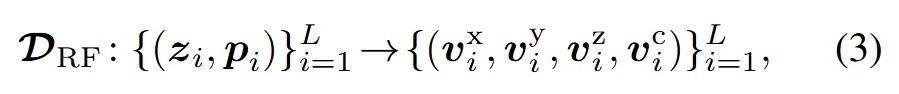
Radiance field는 각 voxel이 3D grid() 안에서 σ,R,G,B 4가지 값을 예측하기 때문에 총 2048개의 파라미터를 사용합니다. 메모리 사용량이 너무 많기 때문에 CP-decomposition을 써서 더 적은 파라미터로 예측할 수 있도록 합니다. x,y,z는 8, σ,R,G,B를 포함하는 c는 4차원으로 나타내서 총 28차원을 rank (=R=16)으로 곱해 448이라는 파라미터를 사용해 기존 2048에 비해서 훨씬 메모리를 절약하는 방식이 CP-decomposition입니다. Reconstruction loss는 3D GS와 동일합니다.
Meshes
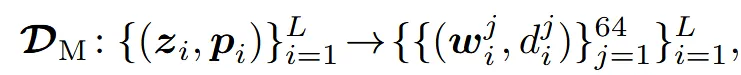
는 FlexiCubes에서 사용한 flexible 파라미터이고, 는 signed distance value입니다. 참고로 FlexiCubes는 Marching cubes 대신에 SDF값을 이용해서 mesh를 생성하는 방법으로 품질을 개선한 방식입니다. 마지막 결과에 upsampling block을 추가해서 최종적인 output의 해상도를 으로 설정했습니다. Loss로는 렌더링된 depth(normal)과 실제 값과의 L1 loss를 진행합니다.
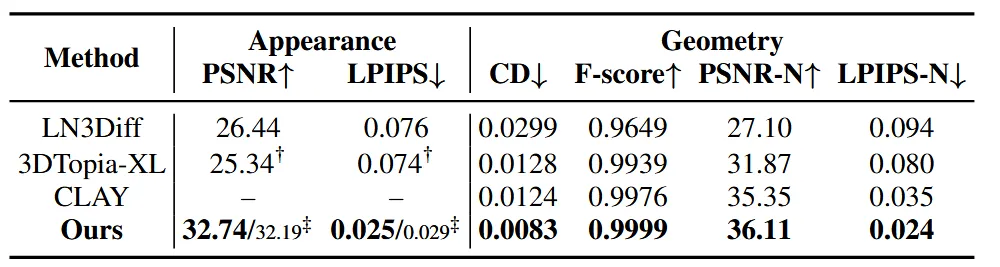
실제로 학습할 때는 Gaussian의 학습 방법을 채택했고, 결과적으로 geometry가 생성되는 결과는 위와 같이 Ours의 결과가 가장 좋은 것을 확인할 수 있습니다.
Structured Latents Generation
)
위의 아키텍처처럼 rectified flow 모델을 사용했기 때문에 간략히 해당 모델을 언급하도록 하겠습니다.
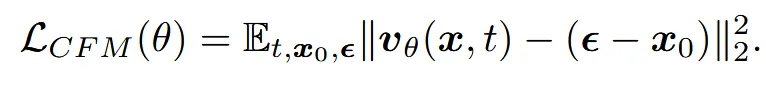
해당 모델의 forward 과정은 linear interpolation 과정으로 데이터 샘플 에서부터 timestep t만큼의 노이즈를 추가하는 것이고, backward process는 t시점에서의 vector field를 예측하는 것입니다.
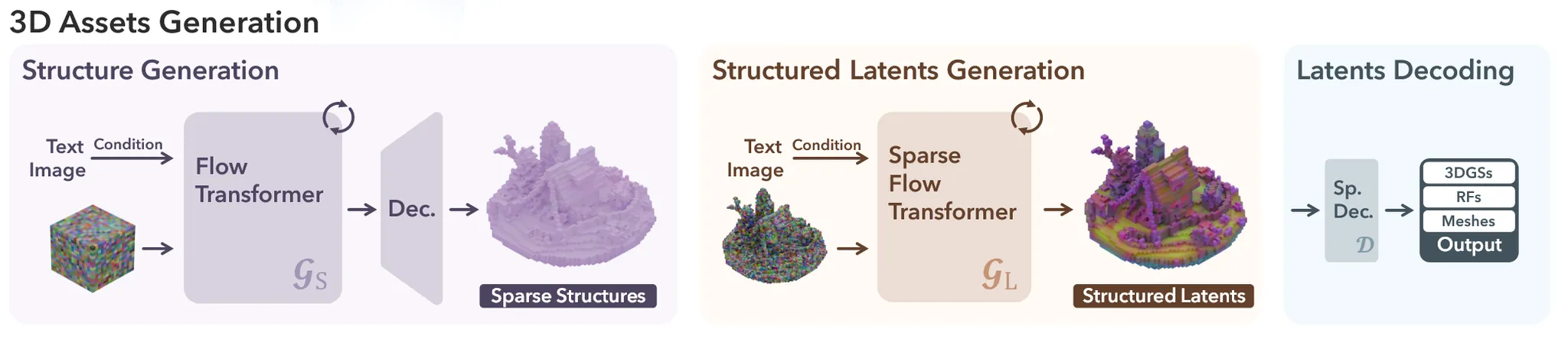
Sparse structure generation
첫번째로 모델은 보라색처럼 sparse structure를 생성합니다. 의 차원을 갖는 binary(0,1) Voxel grid는 해당 값이 1이면 voxel이 존재, 0이면 존재하지 않도록 구성되어 있습니다. 을 한번에 계산하면 계산량이 너무 많기 때문에 VAE를 통해서 의 차원을 갖는 low-resolution에서 계산을 진행합니다.
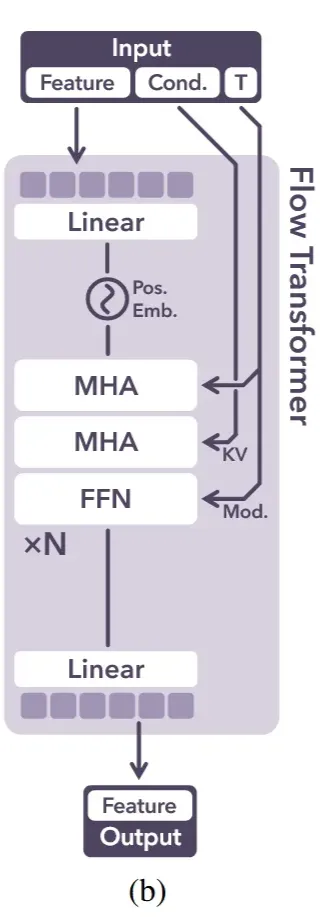
위의 사진과 같이 입력으로 dense noisy grid가 positional encoding을 거쳐서 transformer에 들어가서 denoising 됩니다. Timestep 정보는 adaptive layer normalization (adaLN)과 gating mechanism를 사용해서 포함됩니다. Condition(text, image)는 cross attention layer에 key와 value로 들어갑니다. Text의 경우는 CLIP을, Image의 경우는 DINOv2를 사용합니다. 최종적으로 denoising된 feature grid S는 decoder를 통과해서 discrete grid O를 생성합니다.
Structured latents generation
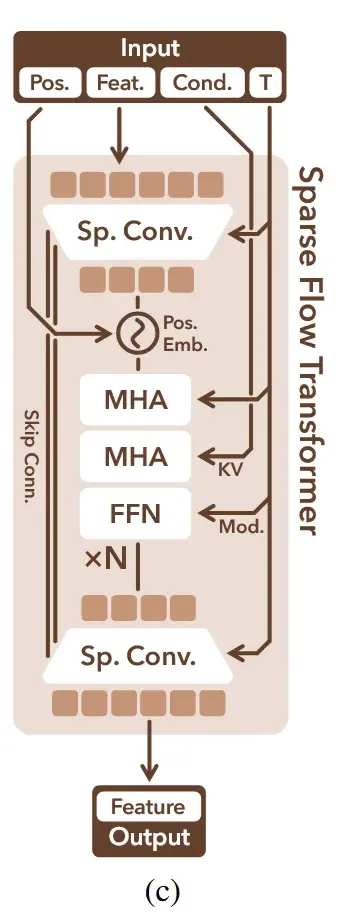
이전에 생성한 sparse structure의 active voxel index 를 이용해서 time step t시점에서의 denoising을 진행하는 과정은 위의 그림과 같습니다. 이전처럼 condition과 timestep은 동일하게 포함되고, 단지 여기에 active voxel index의 값만 positinal encoding을 통해서 추가적인 정보로 사용된다고 보시면 됩니다. 위의 그림에서 Feat는 t시점의 토큰 상태이고, sparse strucutre를 통해서 L만큼의 가우시안 노이즈 토큰을 생성해서 이로부터 디노이징 한다고 생각하시면 됩니다. Sparse convolution의 첫번째 downsample은 인접한 2x2x2 지역을 하나의 voxel로 묶고, 두번째 upsample은 원래의 크기로 복원하기 위해서 학습 가중치를 이용합니다.
3D Editing with Structured Latents
Stage1에서 structure를 생성하고, Stage2에서 latent를 생성하기 때문에 이를 분리해서 다양한 테스크를 진행할 수 있습니다.
Detail variation
Stage1을 통해서 나온 structure를 고정하고, Stage2에서 condition(text, image)를 바꾸면 형상은 유지되면서 디테일한 질감과 같은 부분만 달라집니다.
Region-specific editing
Repaint라는 논문에서 제시한 방식을 사용하면 mask 안의 영역만을 수정할 수 있습니다. 자세하 내용은 Repaint 논문을 참조해야겠지만 inpaint에서 사용한 방식인 나머지 영역은 그대로 두고, 마스크 안의 영역만 노이즈를 추가해서 다시 생성하는 과정을 진행하면 충분히 원하는 부분만을 수정할 수 있게 됩니다.
Experiments


Applications

Method의 마지막 부분에서 설명한 tuning-free editing 전략이 흥미로웠고 해당 부분의 실험 결과들을 한번 확인해보록 하겠습니다.
(a)부분은 대략적인 mesh가 주어졌을 때 2번째 단계에서 다양한 text prompt를 적용한 결과들이고, (b)는 Repaint 방식을 통해서 마스크 부분만을 수정할 수 있는 과정을 보여줍니다.
Appendix
Mesh Decoder 부분에서 shape만 예측한다고 설명됐는데, 실제로는 color와 normal map도 예측한다고 A.2 training details에 나와있습니다.
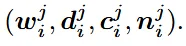
따라서 최종적인 출력은 기존의 w와 d에 이어서 c와 n도 추가된 것을 알 수 있습니다.
