논문 링크
프로젝트 링크
Model
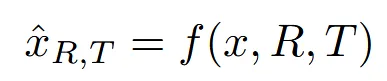
우리가 학습하고자 하는 모델(f)은 위와 같은 형태로 작동합니다.
3D RGB image(x)를 우리가 원하는 3D 카메라 정보인 rotation(R)과 translation(T)를 넣었을 때, 해당 시점의 이미지 를 생성하는 모델입니다.

Dalle-2와 Stable Diffusion에서 “a chair”라는 텍스트를 입력할 때 나오는 결과 이미지들입니다. 이처럼 diffusion모델들은 정면 이미지를 생성하도록 bias되어있는데, 이점이 결과의 퀄리티를 낮추는 요소라고 언급했습니다.
Learning to Control Camera Viewpoint
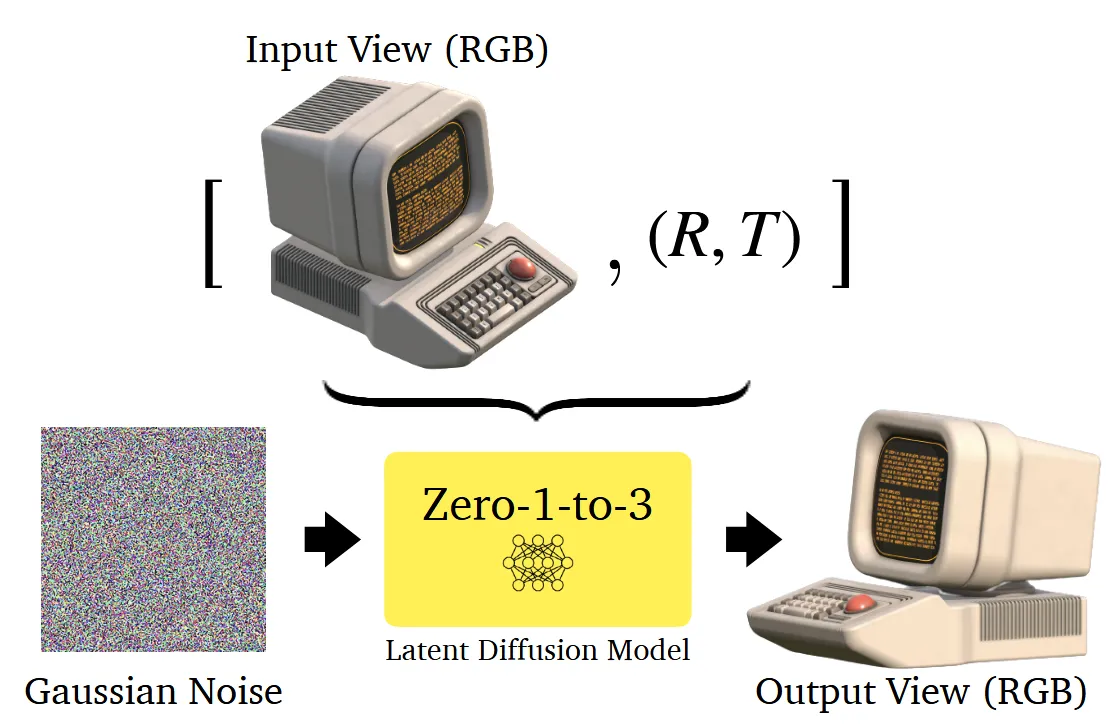
Diffusion모델을 위의 그림처럼 이미지와 카메라의 rotation과 translation 정보를 주었을 때, 해당 시점의 이미지를 생성하도록 fine-tuning 하는 과정을 원합니다.
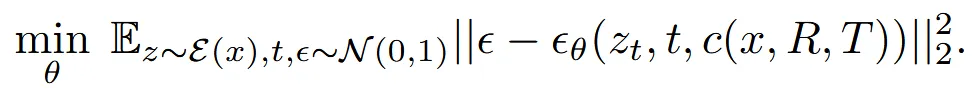
이처럼 fine-tuning으로 condition에 이미지 + rotation + translation을 주고 노이즈를 예측하는 형식으로 학습을 진행합니다.
View-Conditioned Diffusion
- 이미지를 CLIP 인코더를 활용해서 임베딩 생성
원래 Stable Diffusion에서 condition으로는 1개의 정보만 들어갈 수 있는데 지금 이미지, rotation, translaton 3가지 정보가 존재하기 때문에 이를 하나로 합치는 과정을 진행해야합니다. 이미지는 CLIP이미지 인코더를 통해서 임베딩 값을 얻고, 해당 값에 r과 t를 concate해서 하나의 값을 생성합니다. 이렇게 이미지 임베딩과 r과 t를 하나로 합친 값이 posed clip 값입니다.
- classifier-free guidance를 사용하는 방법
입력이미지와 denoised 이미지(중간과정)을 채널 차원에서 하나의 이미지로 결합해서 사용합니다. 이후 동일하게 condition값으로는 posed clip 값이 들어갑니다. condition은 중간중간 null vector로 변형함으로서 일반화 성능을 높이고, 스케일링을 통해서 condition 강도를 조절할 수 있습니다.
3D Reconstruction
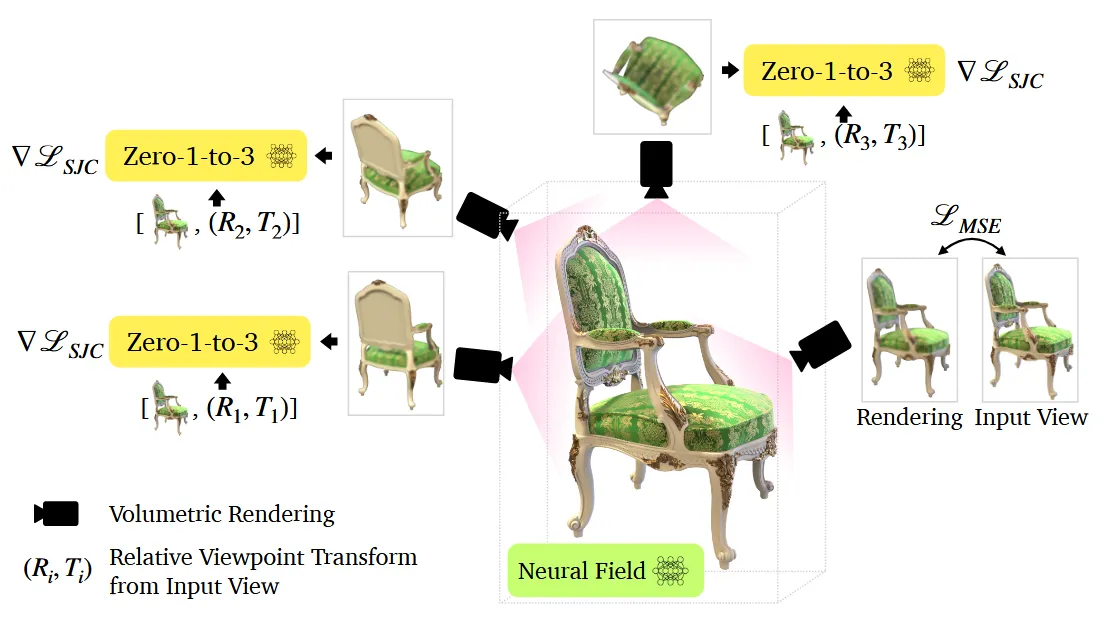
해당 사진에서 본것처럼 Score Jacobian Chaining(SJC) 방식을 사용해서 3D 표현을 학습합니다.
무작위 시점에서 이미지를 렌더링 한 후, 이미지에 노이즈를 더하고 노이즈를 예측하는 과정을 진행합니다. 노이즈를 예측하는 과정에서 posed CLIP 정보가 제공되고 최종적으로 생성된 이미지와 해당 시점의 원본 이미지와 MSE Loss를 이용해서 학습을 진행합니다.
Results
Novel view synthesis


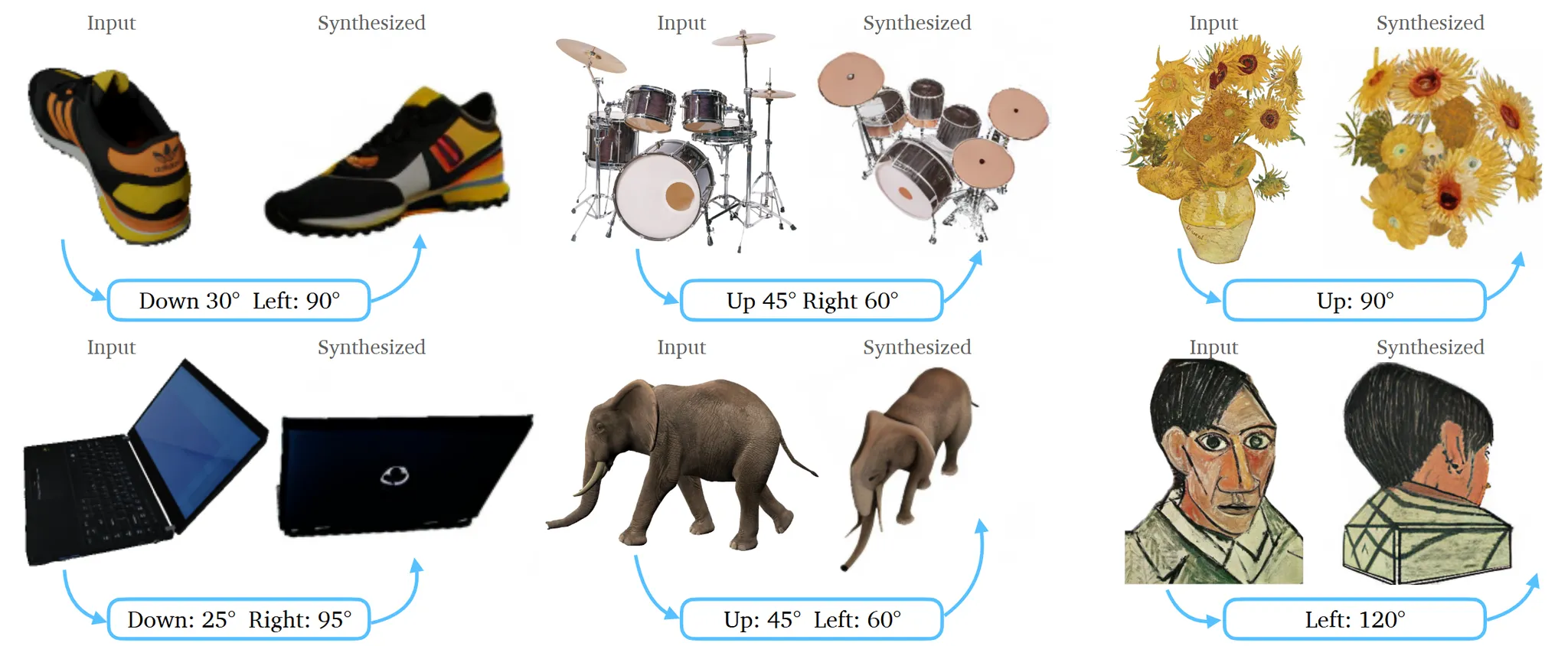
서로다른 모델들과 비교한 결과입니다. SJC-I는 기존에 text가 condition으로 들어가는데 이를 image가 condition으로 들어가도록 대체한 모델입니다.

2번째 사진을 제외하곤 아이폰으로 찍은 사진이고, 2번째 사진은 인터넷에서 돌아다니는 사진을 가져온 것입니다.
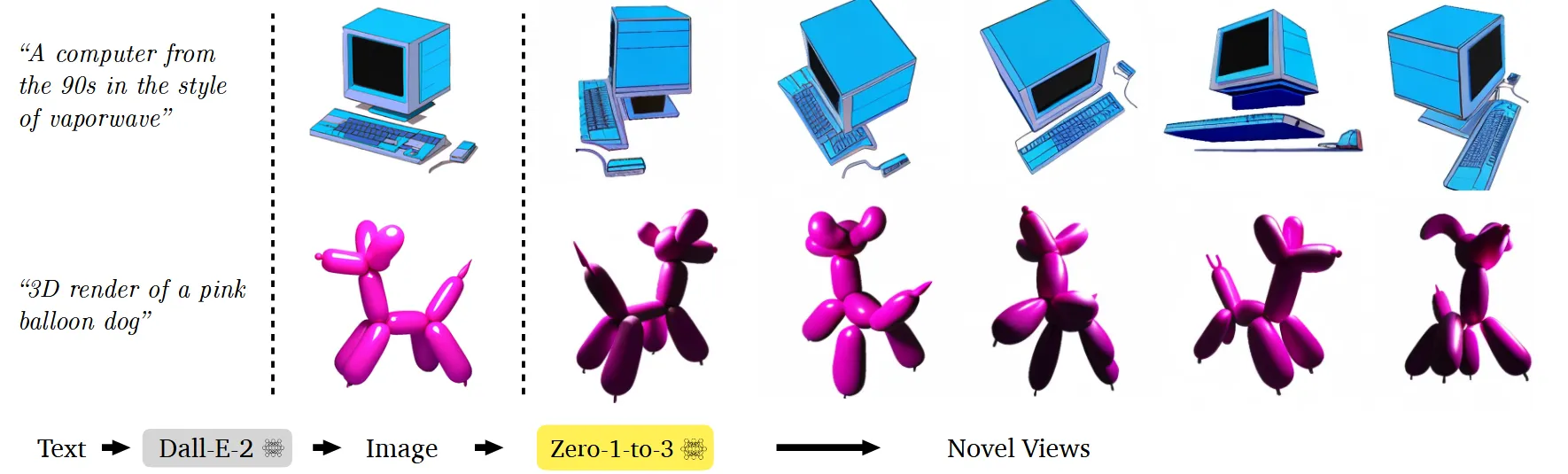
Dall-E로 생성한 이미지를 새로운 시점에서 본 이미지로 변환한 결과입니다.
3D Reconstructions

