mPLUG: Effective and Efficient Vision-Language Learning by Cross-modal Skip-connections 논문리뷰
논문 링크
Introduction
정보 비대칭성
Text: 정보는 대부분 짧고 요약적(색상,질감, 배경과 같은 시각적 요소를 포함할 수 없다)
Image: 다양한 세부 정보를 포함
방법1
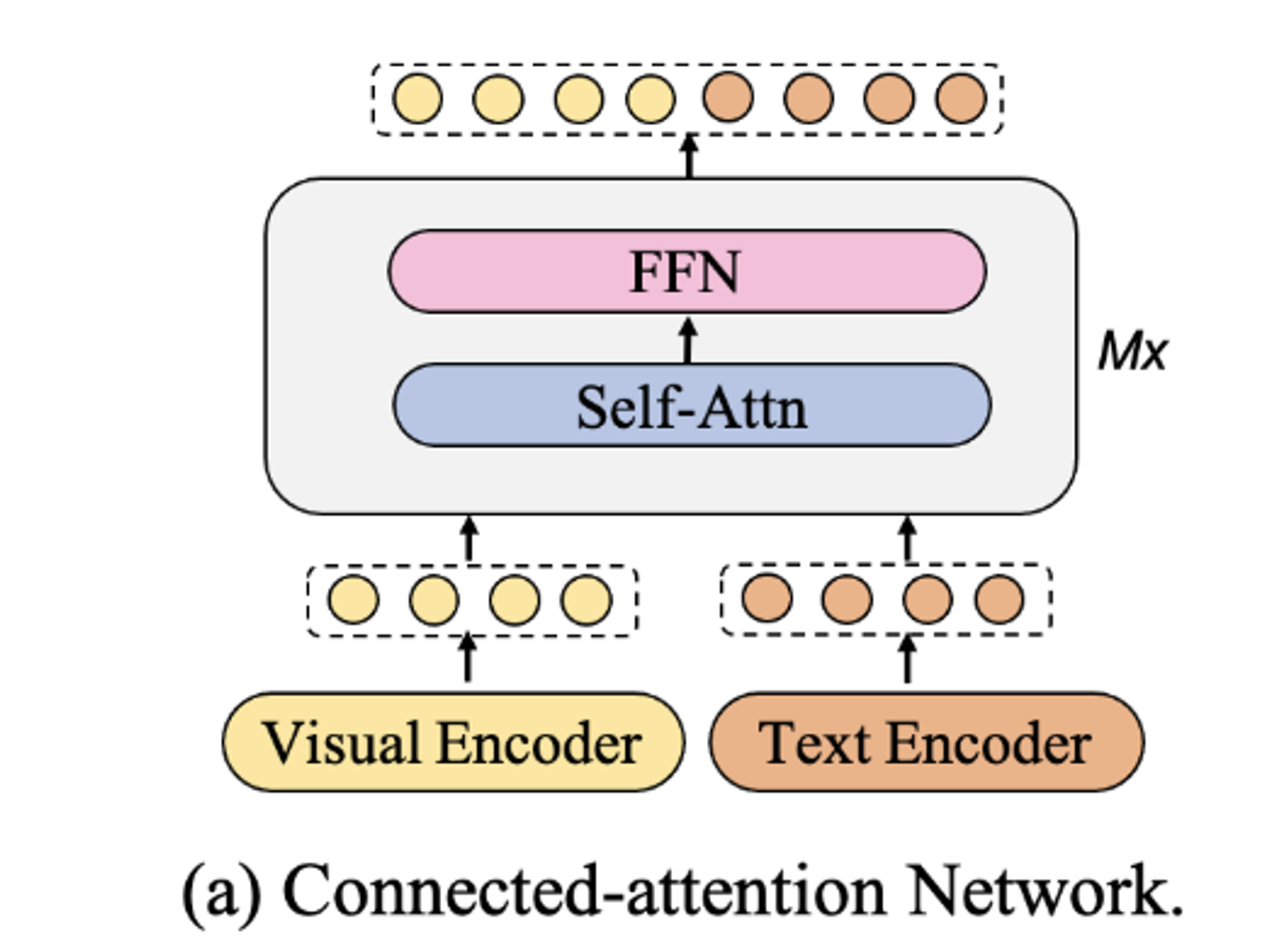
두 모달리티에대해서 동일한 Self-Attn으로 처리
→ 두 모달리티 간 정보 차이(길이 차이 등)가 있는 경우 정보 비대칭으로 인해 문제
방법2
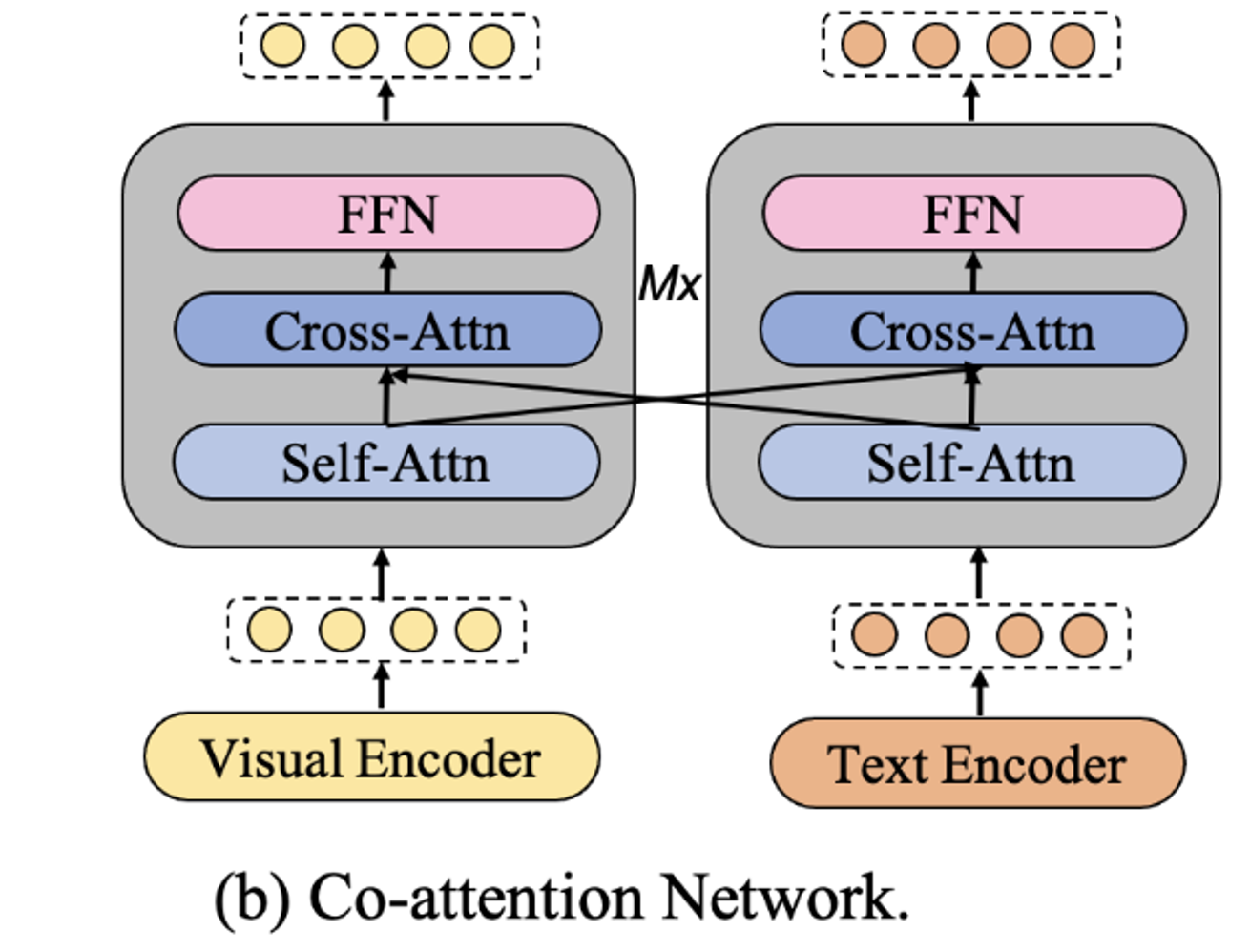
Cross-Att를 이용해서 정보 비대칭 문제 완화
→ 긴 시각적 시퀀스에서는 계산 비효율성
mPLUG
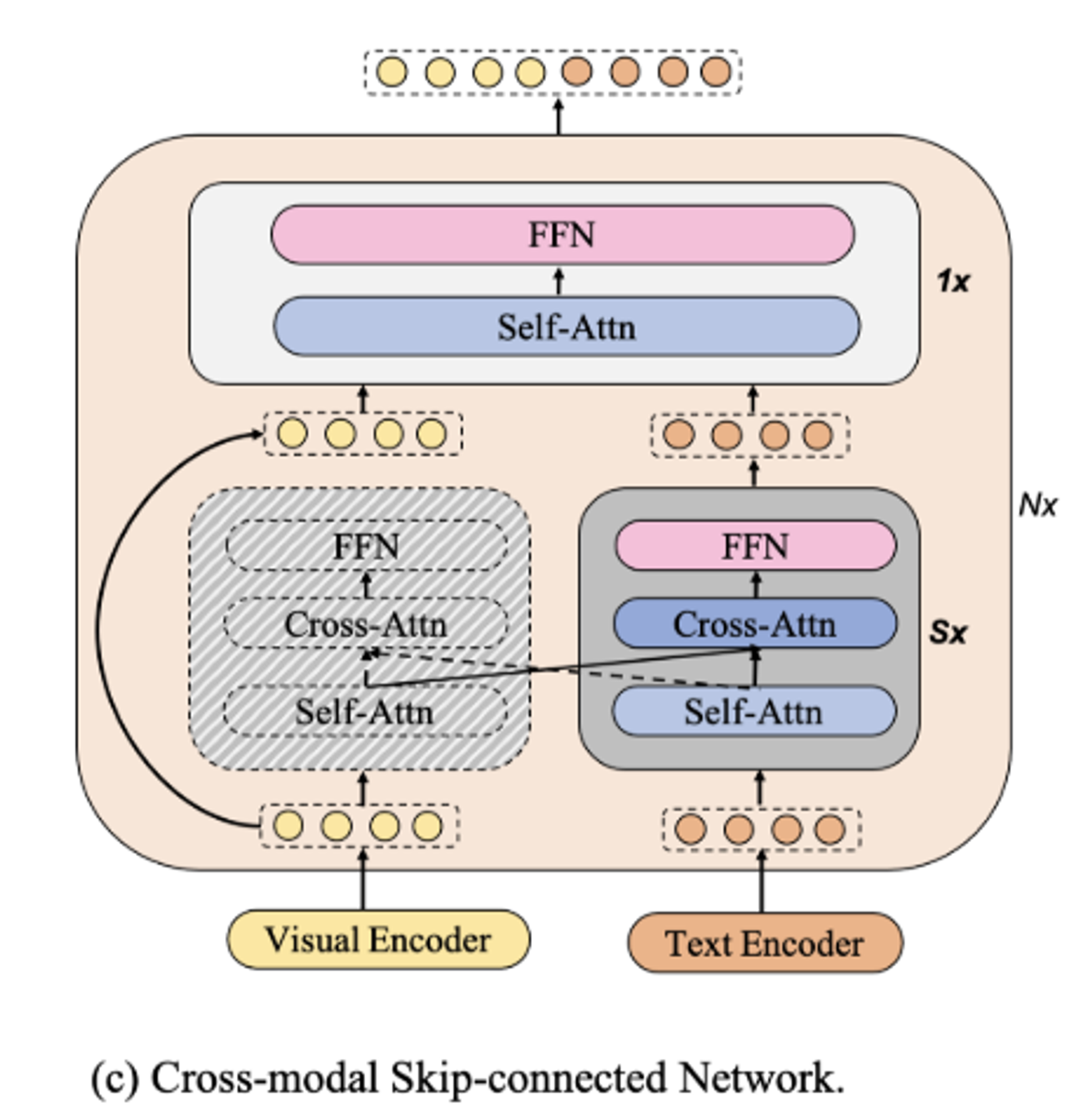
비대칭성을 해소하기 위해 초반에 Text에 대해서만 학습을 진행
→ 결론적으로 성능과 속도를 모두 잡게 모델구조 설계
Contributions
- 효율적, 효과적인 통합된 vision-language model
- 새로운 비대칭적 구조 + cross-modal skip-connections
→ 정보 불균형과 계산 비효율성 해결 - 다양한 vision-language task에서 SOTA
mPLUG
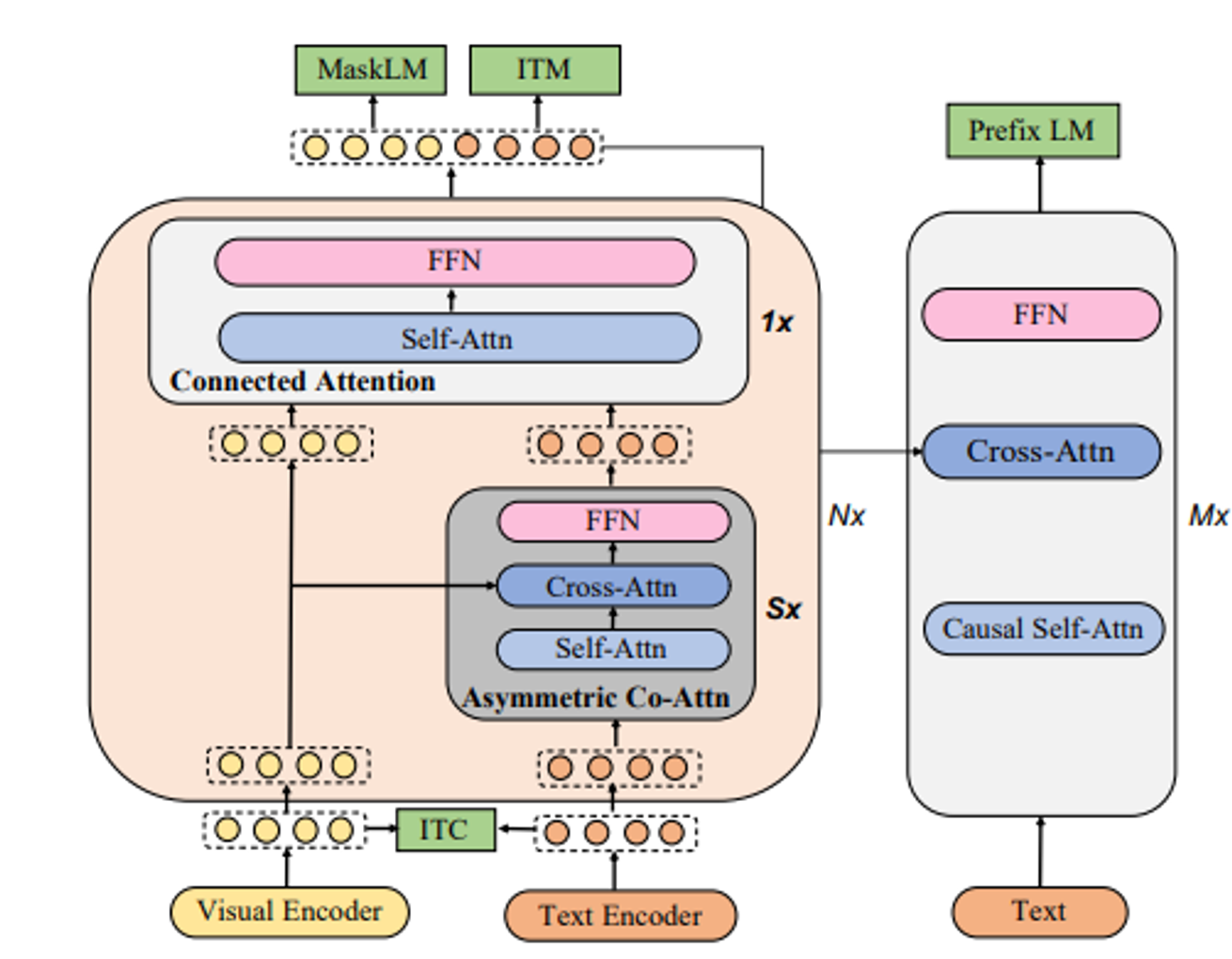
Visual Encoder: Visual Transformer(ViT) → 여기서 사용하는 CLS토큰은 이미지 전체를 요약하는 추가 토큰(vcls)
Text Encoder: Transformer → 여기서 사용하는 → 동일하게 텍스트 전체를 요약하는 토큰(lcls)
cross-modal skip-connected network
- N개의 skip-connected fusion block으로 구성
- 각각의 block에는 S개의 Asymmetric Co-Att 존재
Asymmetric Co-Att
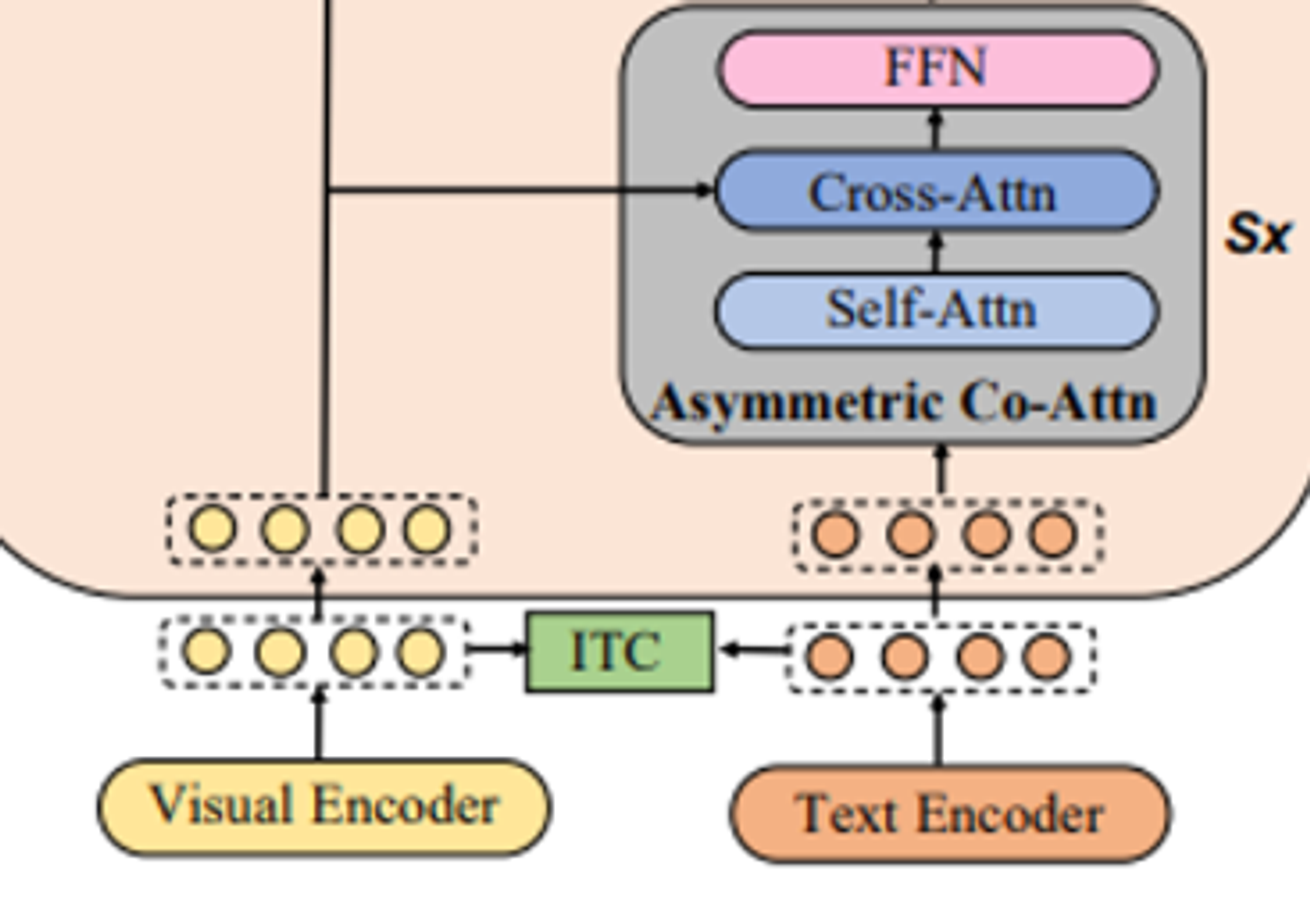
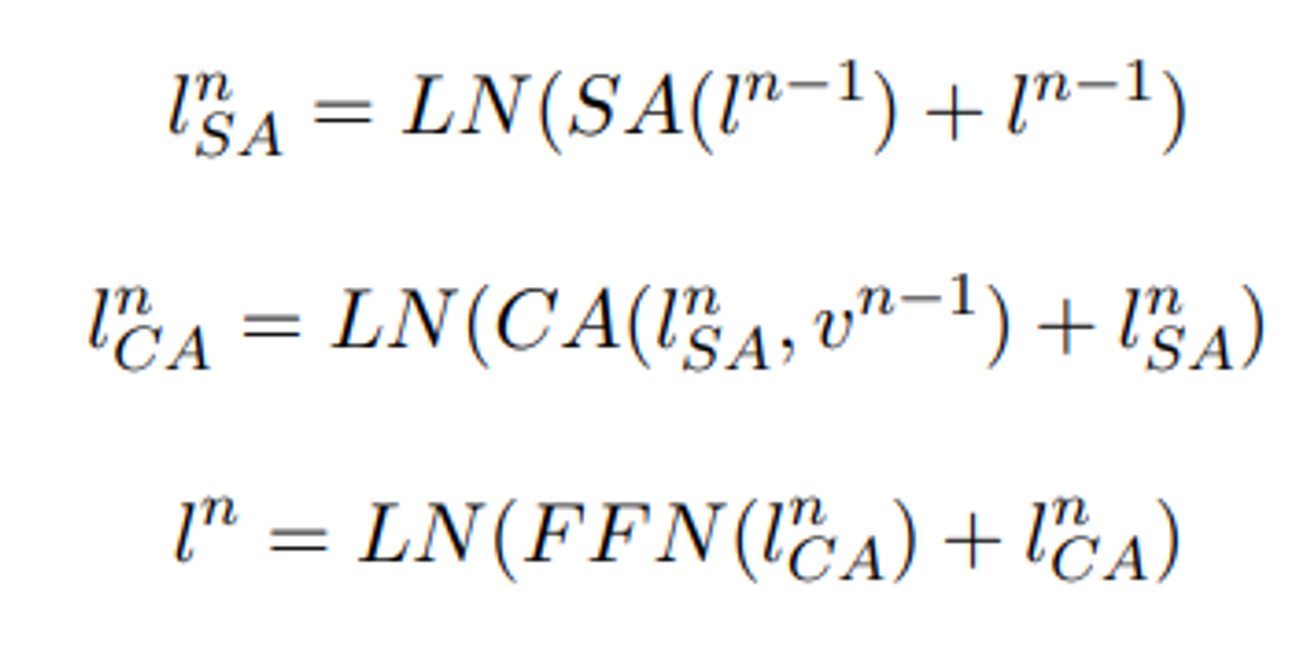
- text feature들은 Self-Att를 통과
- Visual feature와 Cross-Att를 통과
- 최종적으로 FFN을 통과
위의 사진처럼 3가지 과정에서는 모든 과정에서 Resiudal 방식이 적용된다
LN: Layer Normalization
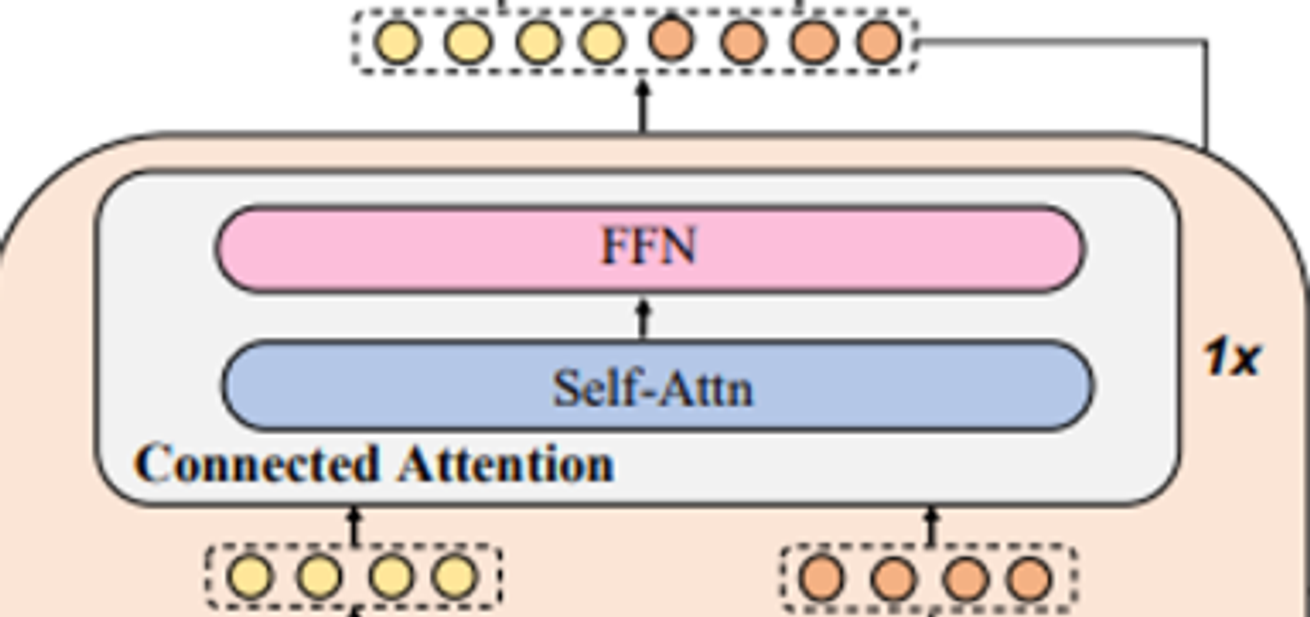
Connected-attention layer
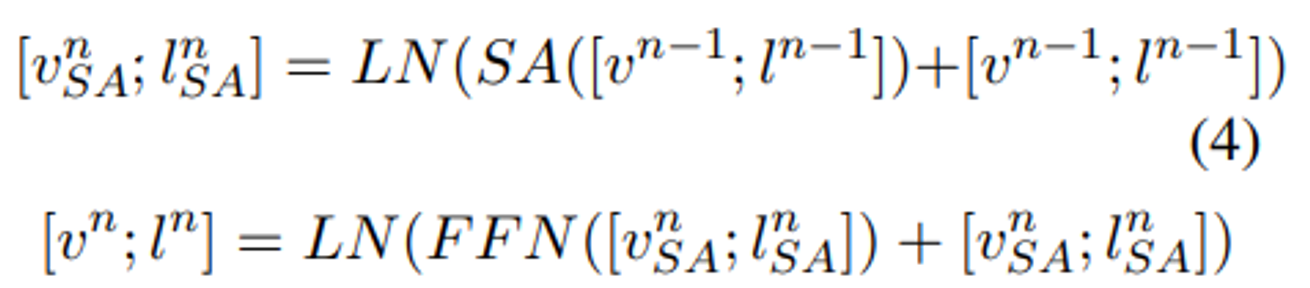
Pretraining Tasks
4개의 pret-training tasks
- understanding tasks
- Image-Text Contrastive Learning(ITC): 이미지와 문장이 교차 모달 표현에서 서로 일치하는지 여부를 예측하는 것을 목표
- Image-Text Matching(ITM): 이미지와 텍스트가 서로 매치되는지 여부를 예측하는 것을 목표
- Masked Language Modeling(MLM): BERT처럼 token의 15%를 mask처리해서 model이 해당 mask를 예측하도록 훈련
- generation task
- Prefix Language Modeling(Prefix LM): 주어진 이미지와 텍스트 프리픽스를 기반으로 후속 텍스트를 순차적으로 예측하여 캡션을 생성하는 작업
Distributed Learning on a Large Scale
memory
- static memory: parameters, optimizer states, gradients …
- ZeRO technique(data-parallel group_
- runtime memory: intermediate variables(activation values)
- gradient check pointing(reduce runtime memory)
computation time
- BF16 precision training(new data type)
Experiments
Data
- in-domain: MS COCO, Visual Genome
- web out-domain: Conceptual Captions, Conceptual 12M, SBU Catpions
총 14M images with texts
Setup
- 텍스트 인코더: BERTbase 모델의 첫 6개 층으로 초기화
- 비주얼 인코더: CLIP-ViT, ViT-B/16 기본 아키텍처, ViT-L/14 대형 아키텍처 사용
- 크로스-모달 스킵-연결 네트워크: BERTbase 모델의 마지막 6개 층으로 초기화
- 디코더: 12층 Transformer
VQA(Visual Quesion Answering)
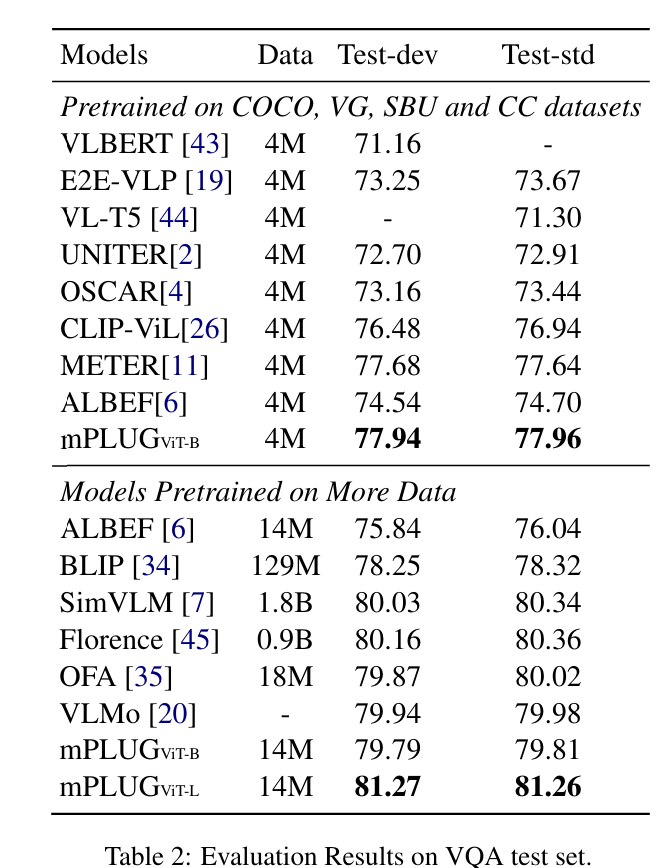
논문을 읽는 이유가 VQA에 관련된 부분을 찾다보니 이부분에 대해서만 분석해두고 나머지 부분은 논문을 참조
open-vocab generation
기존 VQA는 closed-vocab generation 즉 정해진 카테고리 중에서 하나를 선택하는 형식이지만, mPLUG는 답변 생성 작업으로 진행
입력데이터
- 이미지
- 질문
- 객체 라벨(Object labels): Object detector를 사용하지 않고, ViT를 사용하여 이미지 패치에서 시각적 특징 추출
- OCR 토큰: 이미지에서 추출된 텍스트(ex. 간판의 글자, 책의 제목)
open-vocab generation vs closed-vocab generation
closed-vocab generation
- 가능한 답변 목록: ["red", "blue", "green"]
- 모델의 출력: "red"
open-vocab generation
- 모델의 출력: "The car is red.”
- 위의 정보를 기반으로 ‘red’라는 category 선택
생성된 텍스트를 기반으로 category중 하나를 선택하게 하는거같은데 이부분에 대해서는 논문에서 언급하지 않았다.
