PostgreSQL 설치
Windows
https://www.postgresql.org/download/ 에 접속해서 자신의 운영체제에 맞는 버전을 다운받아 실행한다. 데이터베이스 관리자 비밀번호만 설정하고, 나머지는 모두 기본값으로 설정한 후 Next를 눌러 설치를 완료한다.

macOS
여기(postgresapp.com)에 접속해서 최신 버전으로 다운로드 받고 Postgres.app 파일을 Application 폴더에 옮기기만 하면 끝난다. 설치 후 SQL Shell에서 아래 쿼리를 입력해 정상적으로 설치됐는지 테스트할 수 있다.
select version();
select current_date;
select current_time;
select current_timestamp;
select 2+2;환경 변수 설정 (선택)
콘솔에서 경로를 입력하지 않고 바로 psql을 실행할 수 있도록 환경변수를 설정할 수 있다. 아니면 환경변수를 설정하지 않고 직접 PostgreSQL 폴더에 들어가서 psql을 실행시켜도 된다.
Windows
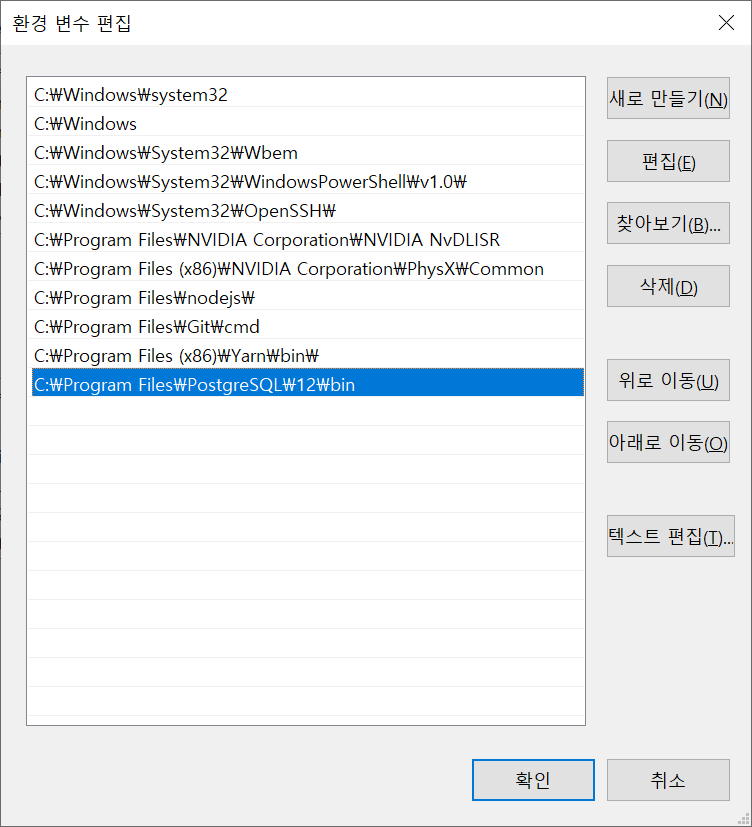
제어판 ➞ 시스템 ➞ 고급 시스템 설정 ➞ 환경변수 ➞ 시스템 변수의 Path 클릭 후 편집 ➞ 새로 만들기 후 PostgreSQL 설치 주소 입력 및 확인
C:\Program Files\PostgreSQL\12\bin (기본 설치 주소)
macOS
그런 거 안 해줘도 된다. 다운 받은 앱을 실행하기만 하면 데이터베이스를 켤 수 있다.
SQL Shell 명령어
windows
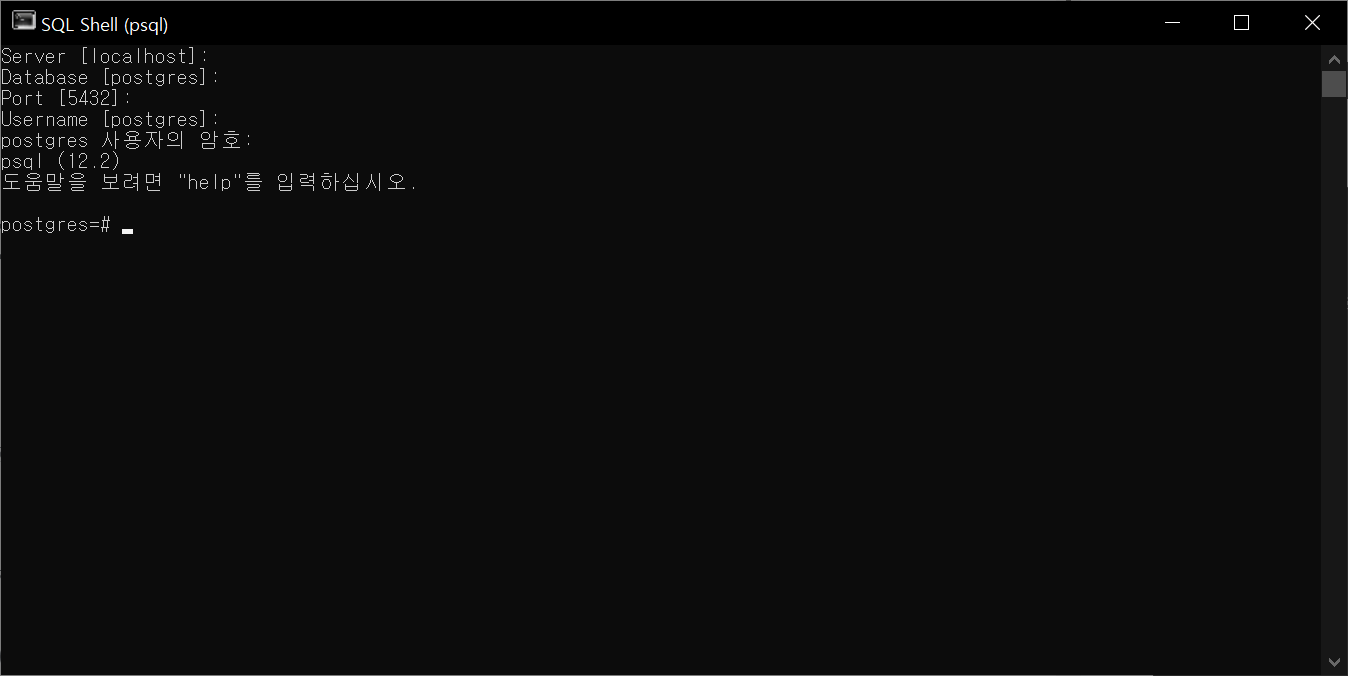
SQL Shell(psql)을 실행하면 호스트, 데이터베이스 이름, 포트, 사용자 이름 및 암호를 입력하는 창이 뜬다. 설치 시 설정한 값으로 입력하면 SQL문 또는 아래의 특수 명령어를 입력할 수 있다.
macOS
Postgres.app을 설치했다면 기본적으로 데이터베이스와 사용자 권한이 컴퓨터 사용자 이름과 동일하게 생성된다. (비밀번호도 사용자 이름이다.)
-
\c 데이터베이스이름 사용자이름
해당 데이터베이스를 해당 사용자(role) 권한으로 접속 -
\dg,\du
모든 사용자(role) 이름 출력 -
\l
모든 데이터베이스 목록 출력 -
\dn
현재 접속한 데이터베이스의 모든 스키마 목록 출력 -
\d,\dt
현재 접속한 데이터베이스의 모든 테이블 목록 출력 -
\d 테이블이름
인덱스, 제약 조건, 컬럼 정보(자료형, nullable, 기본값) 등 해당 테이블의 정보 출력 -
\di
현재 접속한 데이터베이스의 모든 인덱스 목록을 출력 -
\df
현재 접속한 데이터베이스의 모든 사용자 정의 함수 목록을 출력
데이터베이스
PostgreSQL엔 여러 데이터베이스가 존재하고, 한 데이터베이스엔 여러 테이블이 존재하고, 한 테이블엔 여러 레코드와 컬럼이 존재하고, 한 레코드엔 여러 필드가 존재한다. 필드는 테이블의 특정 행과 열이 교차하는 곳을 말한다. 물리적으로 테이블 컬럼은 순서를 가지고 저장되지만 레코드는 순서없이 저장된다.
기본 데이터베이스를 포함해서 모든 데이터베이스를 삭제하면 데이터베이스를 다시 생성하는데 힘들 수 있으니 컴퓨터 사용자 이름을 가진 데이터베이스는 삭제하지 않는 것을 권장한다. 실수로 삭제했을 때 복구할 수 있는 방법은 다음(postgresapp.com)과 같다.
1. 생성
create database 데이터베이스이름;2. 삭제
drop database 데이터베이스이름;자료형
| 예약어 | 설명 |
|---|---|
| char(n) | 고정 길이 문자열 |
| varchar(n) | 가변 길이 문자열 |
| int2 | 2 bytes 정수형 |
| int | 4 bytes 정수형 |
| int8 | 8 bytes 정수형 |
| float4 | 4 bytes 실수형 |
| float8 | 8 bytes 실수형 |
| bool | 참/거짓 자료형 |
| date | 년-월-일 |
| time | 시-분-초 |
| timetz | 시-분-초 + 시간대 |
| timestamp | 년-월-일-시-분-초 |
| timestamptz | 년-월-일-시-분-초 + 시간대 |
자주 사용하는 자료형은 위와 같다. 모든 자료형 목록은 여기(postgresql.org)서 확인할 수 있다. 위 표에서 사용된 n은 자연수다.
테이블
테이블(표)은 레코드(행)와 컬럼(열)으로 이루어져 있다. PostgreSQL은 기본적으로 식별자에 대해 대소문자를 구별하지 않지만, 큰따옴표를 사용해 대소문자 구분을 명시할 수 있다.
1줄 주석은 --를 사용한다.
1. 생성
create table 테이블이름 (
컬럼이름 자료형 조건,
...
);
create table champion (
id int primary key generated always as identity,
name varchar(15) unique not null,
kill int not null default 0 check (k >= 0),
death int not null default 0 check (death >= 0),
assist int not null default 0 check (assist >= 0),
cs int not null default 0 check (cs >= 0)
);id | name | kill | death | assist | cs |
|---|
위와 같은 SQL문으로 테이블의 틀을 생성할 수 있다. not null은 각각의 컬럼(column)은 비어있을 수 없다는 것을 의미하고, check로 kill, death, assist, cs 컬럼은 0 이상이어야 한다는 조건을 설정할 수 있다.
기본키로 설정한 항목은 따로 명시하지 않아도 not null과 unique 설정이 적용된다. 즉, id를 primary key로 설정했으니 그 컬럼은 테이블의 다른 레코드값과 중복되지 않아야 하며 비어있을 수 없다. 그리고 generated always as identity을 사용해서 id를 따로 명시해서 삽입하지 않아도 1부터 자동으로 증가하게 설정했다.
외래키 옵션
- 기본값 : 해당 외래키가 참조하는 (다른 테이블의) 레코드는 삭제할 수 없다.
on delete set null: 해당 외래키가 참조하는 레코드가 삭제되면 외래키 값을 null로 설정한다.on delete cascade: 해당 외래키가 참조하는 레코드가 삭제되면 현재 테이블의 레코드도 삭제한다.
2. 삭제
drop table 테이블이름;해당 테이블과 그 테이블의 모든 레코드가 삭제된다. 해당 명령은 되돌릴 수 없으니 주의해서 사용해야 한다.
레코드
레코드(record)는 테이블의 각 행을 의미한다.
1-1. 추가
insert into 테이블이름 values (값, ...);
insert into champion values (default, 'Sona', 2, 5, 10, 12);
insert into champion values (default, 'Ezreal', 4, 2, 1, 93);
insert into champion values (default, 'Ahri', 2, 3, 2, 80);
insert into champion values (default, 'Yasuo', 0, 7, 1, 40);id | name | kill | death | assist | cs |
|---|---|---|---|---|---|
| 1 | Sona | 2 | 5 | 10 | 12 |
| 2 | Ezreal | 4 | 2 | 1 | 93 |
| 3 | Ahri | 2 | 3 | 2 | 80 |
| 4 | Yasuo | 0 | 7 | 1 | 40 |
레코드 필드값이 문자열인 경우 작은따옴표로 감싼다. 큰따옴표는 식별자의 대소문자 구분에 사용한다. 여기선 1-2와 다르게 컬럼 이름을 명시하지 않았기 때문에 값을 나열하는 순서는 테이블 컬럼의 순서를 따라야 한다.
1-2. 일부 추가
insert into 테이블이름 (컬럼이름, ...) values (값, ...);지정한 컬럼에만 값을 넣고 나머지 컬럼에는 default 값 또는 null 값을 넣은 레코드를 해당 테이블에 추가한다.
2. 수정
update 테이블이름 set 컬럼1=바꿀값1, 컬럼2=바꿀값2, ... where 조건문;
update champion set victory = True where k >= 2;
update champion set victory = False where k < 2;id | name | kill | death | assist | cs | victory |
|---|---|---|---|---|---|---|
| 1 | Sona | 2 | 5 | 10 | 12 | t |
| 2 | Ezreal | 4 | 2 | 1 | 93 | t |
| 3 | Ahri | 2 | 3 | 2 | 80 | t |
| 4 | Yasuo | 0 | 7 | 1 | 40 | f |
champion 테이블에서 kill이 2 이상인 레코드의 victory 값은 t로 설정하고, 2 미만인 레코드의 victory 값은 f로 설정하는 SQL 문장이다.
PostgreSQL에선 t, true, True가 모두 동일하고, f, false, False도 동일하다.
3. 삭제
delete from 테이블이름 where 조건문;해당 테이블에서 조건에 맞는 레코드를 삭제한다. 만약 where 절을 생략할 경우 해당 테이블의 모든 레코드가 삭제되니 주의해야 한다.
컬럼
컬럼(column)은 테이블의 각 열을 의미한다. 속성(attribute)이라고 하기도 한다.
1. 추가
alter table 테이블명 add 컬럼명 자료형 제약조건;
alter table champions add victory boolean;
alter table champions add new_column char(10);id | champ_name | k | death | assist | cs | victory | new_column |
|---|---|---|---|---|---|---|---|
| 1 | Sona | 2 | 5 | 10 | 12 | - | - |
| 2 | Ezreal | 4 | 2 | 1 | 93 | - | - |
| 3 | Ahri | 2 | 3 | 2 | 80 | - | - |
| 4 | Yasuo | 0 | 7 | 1 | 40 | - | - |
기존 테이블에 새로운 컬럼을 추가하는 명령어다. 위 명령어를 사용하면 기존 champion 테이블에 자료형이 boolean인 victory 항목을 추가할 수 있다. 따라서 기존 표는 위와 같이 바뀐다. 그리고 새롭게 추가된 컬럼은 테이블의 마지막 컬럼이 되고 컬럼의 위치를 지정할 순 없으며 해당 컬럼의 모든 entry 값은 null로 초기화된다.
2. 수정
// 제약 조건 설정/삭제
alter table 테이블명 alter column 컬럼명 set 제약조건;
alter table 테이블명 alter column 컬럼명 drop 제약조건;
// 컬럼 이름 변경
alter table 테이블명 rename column 컬럼명 to 새로운이름;
// 컬럼 자료형 변경
alter table 테이블명 alter column 컬럼명 type 자료형;
// check 조건 추가/삭제
alter table 테이블명 add constraint 제약조건이름 check (조건);
alter table 테이블명 drop constraint 제약조건이름;
alter table champions alter column death set not null;
alter table champions alter column death set default 0;
alter table champions alter column death drop not null;
alter table champions alter column death drop default;3. 삭제
alter table 테이블명 drop column 컬럼명;
alter table champions drop column new_column;id | champ_name | k | death | assist | cs | victory |
|---|---|---|---|---|---|---|
| 1 | Sona | 2 | 5 | 10 | 12 | - |
| 2 | Ezreal | 4 | 2 | 1 | 93 | - |
| 3 | Ahri | 2 | 3 | 2 | 80 | - |
| 4 | Yasuo | 0 | 7 | 1 | 40 | - |
drop column은 해당 테이블에서 필요 없는 컬럼을 삭제할 수 있으며, 해당 컬럼의 모든 데이터도 함께 삭제된다.
한 번에 하나의 컬럼만 삭제 가능하며, 한번 삭제된 컬럼은 복구가 불가능하다. 기본키로 설정된 컬럼도 삭제할 수 있고, 컬럼 삭제 후 최소 하나 이상의 컬럼이 테이블에 존재해야 한다.
레코드 검색
select 컬럼명 from 테이블명 where 조건;SQL 검색문의 일반적인 형태는 위와 같고, 검색하기 전 테이블 상태는 레코드 → 수정에 있는 테이블과 같다. 모든 검색 요청은 기존 테이블의 값이나 레코드 순서를 수정하지 않고 단지 읽기만 할 뿐이다.
검색: select ... from ... where ...
select id, champ_name, death from champion_info where death >= 4;id | champ_name | death |
|---|---|---|
| 1 | Sona | 5 |
| 4 | Yasuo | 7 |
champion_info 테이블에서 death가 4 이상인 레코드 중 id, champ_name, death 값을 검색하는 SQL 문장이다.
검색: *
select * from champion_info where assist = 1;id | champ_name | k | death | assist | cs | victory |
|---|---|---|---|---|---|---|
| 2 | Ezreal | 4 | 2 | 1 | 93 | t |
| 4 | Yasuo | 0 | 7 | 1 | 40 | f |
champion_info 테이블에서 assist가 1인 레코드의 모든 컬럼을 검색하는 SQL 문장이다. *을 사용해 모든 컬럼을 검색하도록 지정할 수 있다.
검색: order by
select * from champion_info where victory = True order by cs desc;id | champ_name | k | death | assist | cs | victory |
|---|---|---|---|---|---|---|
| 2 | Ezreal | 4 | 2 | 1 | 93 | t |
| 3 | Ahri | 2 | 3 | 2 | 80 | t |
| 1 | Sona | 2 | 5 | 10 | 12 | t |
champion_info 테이블에서 victory가 True인 레코드의 모든 컬럼을 검색하고, order by cs desc는 그 결과를 cs의 내림차순으로 정렬하라는 뜻이다.
검색: group by
select victory, avg(kill_), avg(death), avg(assist), sum(cs)
from champion_info
group by victory
order by victory desc;| victory | avg | avg | avg | sum |
|---|---|---|---|---|
| t | 2.666... | 3.333... | 4.333... | 185 |
| f | 0 | 7 | 1 | 40 |
group by는 집계 함수(count, sum, avg, max, min 등)와 함께 사용하는 구문이다.
위 SQL 문장은 victory의 값이 t인 레코드끼리 모아 kill, death, assist의 평균과 cs의 합을 계산해 한 레코드에 저장하고, f인 레코드끼리 모아 동일하게 계산해 한 레코드에 저장한 후 victory 값의 내림차순으로 반환하는 문장이다. 즉, victory의 값이 t인 이즈리얼, 아리, 소나의 KDA의 평균과 cs 총합을 한 레코드에 담고, victory의 값이 f인 야스오에 대해서도 동일하게 계산한 후 한 레코드에 담은 후 victory 값의 내림차순으로 반환한다. 이 과정을 모든 victory 값의 종류에 대해 반복하지만, 여기서 victory는 t, f밖에 없으므로 2번만 진행한다.
avg(kill_) average_kill를 활용해 kill_의 평균을 구한 column 이름을 avg에서 average_kill로 바꿀 수도 있다.
검색: group by ... having ...
select victory, avg(k), avg(death), avg(assist), sum(cs)
from champion_info
group by victory
having sum(cs) > 100;| victory | avg | avg | avg | sum |
|---|---|---|---|---|
| t | 2.666... | 3.333... | 4.333... | 185 |
where 절에는 집계 함수를 사용할 수 없다. 그래서 집계 함수를 사용해 검색 조건을 정할 수 있는 having이 존재한다. 이 절은 group by 결과물을 한 번 더 필터링하는 용도로 사용된다. 즉, where 절을 통해 테이블의 레코드를 필터링하고, 그 레코드를 group by로 처리한 결과에 having 절을 통해 한 번 더 필터링하는 과정으로 진행된다.
위 SQL 문장은 '검색: group by'의 결과에서 having 절을 통해 cs의 합이 100을 초과하는 레코드만 반환한 것이다.
검색: limit
select * from champion_info order by cs desc limit 3;id | champ_name | k | death | assist | cs | victory |
|---|---|---|---|---|---|---|
| 2 | Ezreal | 4 | 2 | 1 | 93 | t |
| 3 | Ahri | 2 | 3 | 2 | 80 | t |
| 4 | Yasuo | 0 | 7 | 1 | 40 | f |
champion_info 테이블의 모든 레코드와 column을 검색하고, 그 결과를 cs의 내림차순으로 정렬한 후 위에서부터 레코드를 3개 이하로만 검색하겠다는 뜻이다.
검색: limit offset
select * from champion_info order by cs desc limit 3 offset 1;id | champ_name | k | death | assist | cs | victory |
|---|---|---|---|---|---|---|
| 3 | Ahri | 2 | 3 | 2 | 80 | t |
| 4 | Yasuo | 0 | 7 | 1 | 40 | f |
champion_info 테이블의 모든 레코드와 column을 검색하고, 그 결과를 cs의 내림차순으로 정렬한 후 위에서 2번째 레코드부터 3개 이하로 불러오라는 뜻이다. offset은 0부터 시작하기 때문에 offset 1은 2번째 레코드를 의미한다.
인덱스 테이블 생성
create index 인덱스_테이블명 on 테이블명 (컬럼명, ...);
create index test2_info_index on test2 (info NULLS FIRST);
create index test3_desc_index on test3 (id DESC NULLS LAST);사실 PostgreSQL은 테이블을 생성할 때 해당 테이블의 기본키와 unique 속성을 가진 컬럼에 대해서 자동으로 인덱스 테이블이 생성된다. 그래서 unique 속성을 가진 column에 대해서 인덱스 테이블을 생성할 필요는 없다. 생성하면 중복된 인덱스 테이블을 가지게 되어 공간만 낭비할 뿐이다.

잘 봤습니다~