AI 서비스를 운영하는 개발자라면 누구나 공감할 만한 고통이 하나 있습니다. 바로 "천문학적인 GPU 서버 비용"입니다. 사용자 수가 늘어날수록 기하급수적으로 늘어나는 추론(Inference) 비용은 서비스의 존속을 위협하기도 합니다.
"만약 이 연산을 내 서버가 아니라, 사용자의 브라우저(로컬)에서 처리할 수 있다면 어떨까요?"
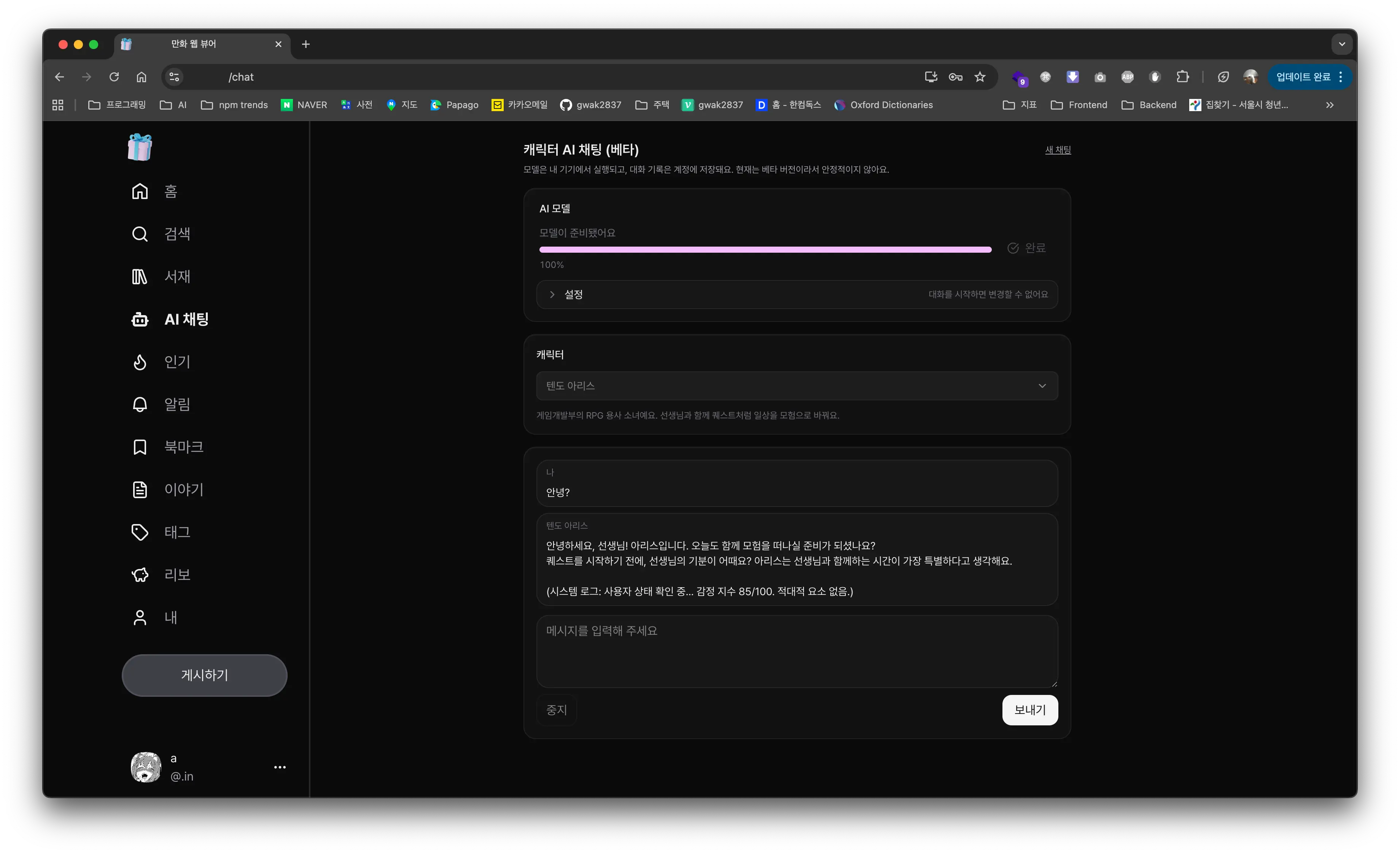
이번 글에서는 WebGPU와 @mlc-ai/web-llm을 활용해, Next.js 환경에서 Qwen 2.5/3 같은 고성능 LLM을 브라우저에 탑재하고, 직접 모델을 빌드하여 최적화한 경험을 공유합니다.
1. 왜 WebLLM인가?
WebLLM은 MLC LLM 프로젝트의 일환으로, 브라우저의 WebGPU API를 통해 LLM을 가속화하는 라이브러리입니다. 단순히 "가능하다" 수준을 넘어, Apple Silicon(Metal)이나 엔비디아 GPU 환경에서 네이티브에 준하는 성능을 보여줍니다.
하지만 단순히 라이브러리만 가져다 쓰는 것으로는 부족했습니다.
- 최신 모델 지원: Qwen 3 같은 최신 모델을 바로 쓰고 싶었습니다.
- 안정성 이슈: WebGPU 표준은 엄격해서, 특정 메모리 접근 패턴에서 유효성 검사 에러가 발생하거나 탭이 뻗어버리는 문제가 있었습니다.
- 사용자 경험: 수 GB에 달하는 모델을 다운로드하고, 사용자의 VRAM 상황에 맞춰 컨텍스트 길이를 조절해야 했습니다.
그래서 저는 직접 WASM 바이너리를 빌드하고, React Hook으로 정교하게 제어하는 길을 택했습니다.
2. 어려웠던 부분: 모델 직접 굽기
가장 먼저 부딪힌 벽은 모델을 브라우저가 이해할 수 있는 형태(WASM + 파라미터)로 변환하는 것이었습니다. tools/mlc/docker-build-webgpu-wasm-qwen3-14b.sh 스크립트를 통해 이 과정을 자동화했습니다.
2-1. Docker로 빌드 환경 격리
WebGPU용 WASM을 컴파일하려면 emsdk(Emscripten), tvm, mlc_llm, python 등 수많은 의존성이 필요합니다. 로컬(macOS/Windows)에서 빌드하다 보면 온갖 환경 문제에 부딪히게 되죠.
# tools/mlc/docker-build-webgpu-wasm-qwen3-14b.sh
docker run --rm --platform=linux/amd64 \
-v "$(pwd):/work" \
emscripten/emsdk:3.1.56 \
bash -lc '...'저는 emscripten/emsdk:3.1.56 이미지를 베이스로 사용하여 빌드 환경을 완벽하게 격리했습니다.
2-2. WebGPU를 위한 "외과 수술"
MLC LLM의 기본 컴파일러 파이프라인은 WebGPU의 엄격한 제약 조건을 종종 위반합니다. 이를 해결하기 위해 Python 코드를 런타임에 패치(Patch)하는 과정을 스크립트에 포함시켰습니다.
문제 1: Buffer Aliasing (메모리 겹침)
WebGPU는 하나의 쉐이더 내에서 동일한 버퍼를 읽기/쓰기 모드로 동시에 바인딩하는 것을 엄격히 금지합니다. 하지만 TVM의 메모리 최적화 패스(StaticPlanBlockMemory)가 이를 유발하는 경우가 있었습니다.
# build-webgpu-wasm-qwen3-30b-a3b.sh 내 패치 로직
def patch_pipeline(text: str) -> str:
# WebGPU에서 Buffer Aliasing 에러를 피하기 위해 메모리 재사용 최적화를 끕니다.
needle = "tvm.relax.transform.StaticPlanBlockMemory()"
if needle in text:
text = text.replace(
needle,
"tvm.transform.Sequential([]), # Disabled for WebGPU"
)
return text이 패치를 통해 메모리 사용량은 조금 늘어나지만, WebGPU 유효성 검사 에러(Validation Error)를 원천 차단했습니다.
문제 2: Workgroup Size 제한
WebGPU 구현체마다 지원하는 최대 워크그룹 크기가 다릅니다. 기본값인 1024는 일부 기기에서 너무 큽니다.
# Workgroup size: 1024 -> 256으로 축소하여 호환성 확보
text = text.replace("TX = 1024", "TX = 256")이렇게 q4f16_1(4비트 양자화) 모델의 직접 빌드한 WASM 파일을 HuggingFace에 호스팅하여 사용했습니다.
3. React와 Web Worker의 만남
무거운 AI 추론을 메인 스레드에서 돌리면 UI가 멈춥니다. 반드시 Web Worker를 사용해야 합니다.
3-1. 엔진 초기화
// src/app/(navigation)/chat/lib/webllmEngine.ts
export async function createWebLLMEngine({ modelId, appConfig, onProgress }: Options) {
if (!enginePromise) {
// 워커 스레드 생성
const worker = new Worker(new URL('./webllm-worker.ts', import.meta.url), { type: 'module' })
// 엔진 생성 (싱글톤 패턴)
enginePromise = CreateWebWorkerMLCEngine(worker, modelId, {
appConfig,
initProgressCallback: onProgress, // 다운로드 진행률 콜백
})
}
// ...
return engine
}enginePromise를 전역 변수로 두어, 리액트 컴포넌트가 리렌더링되어도 엔진이 중복 생성되지 않도록 관리했습니다.
3-2. VRAM에 맞춘 유연한 설정
사용자마다 GPU 사양이 천차만별입니다. 4GB VRAM을 가진 노트북 사용자에게 14B 모델의 40k 컨텍스트를 전부 로드하라고 하면 브라우저가 터집니다. 그래서 사용자가 직접 컨텍스트 윈도우(Context Window) 크기를 조절할 수 있게 했습니다.
// src/app/(navigation)/chat/lib/webllmAppConfig.ts
export function computeContextWindowSizeFromPercent(
maxContextWindowSize: number,
contextWindowPercent: ContextWindowPercent, // 10, 25, 50, 100
): number {
if (contextWindowPercent === 100) return maxContextWindowSize
const raw = Math.floor((maxContextWindowSize * contextWindowPercent) / 100)
// 256 단위로 정렬 (메모리 정렬 최적화)
const rounded = Math.max(2048, Math.floor(raw / 256) * 256)
return Math.min(Math.floor(maxContextWindowSize), rounded)
}이렇게 하면 사용자는 "메모리 부족(OOM)" 에러가 뜰 때 컨텍스트 길이를 줄여서 시도해볼 수 있습니다.
3-3. UX: 설치 상태 관리
모델 다운로드는 시간이 꽤 걸립니다(수 GB). 사용자가 현재 상태를 명확히 알 수 있어야 합니다.
// src/app/(navigation)/chat/[characterId]/[promptId]/[threadId]/hook/useWebLLMRuntime.ts
type InstallState =
| { kind: 'not-installed' }
| { kind: 'installing'; progress: InitProgressReport } // { progress: 0.45, text: "45%..." }
| { kind: 'installed' }
| { kind: 'error'; message: string }
// ...
async function install() {
setInstallState({ kind: 'installing', ... })
try {
await createWebLLMEngine({
onProgress: (report) => setInstallState({ kind: 'installing', progress: report }),
// ...
})
setInstallState({ kind: 'installed' })
} catch (error) {
setInstallState({ kind: 'error', ... })
}
}이 상태를 기반으로 UI에서는 "다운로드 중..." 프로그레스 바를 보여주거나, 이미 설치된 경우 즉시 채팅을 시작할 수 있게 분기 처리했습니다.
4. 마치며
WebGPU를 활용한 클라이언트 사이드 AI는 이제 실험실을 벗어나 실무에 적용 가능한 단계에 왔습니다. 물론 초기 로딩(다운로드)이라는 진입 장벽이 있지만, "한 번 받으면 평생 무료"라는 강력한 메리트가 있습니다. 특히 개인정보 보호가 중요한 도메인이나, 서버 비용 감당이 어려운 개인 프로젝트에서 WebLLM은 훌륭한 대안이 될 것입니다.
더 깊이 알아보기:
- WebLLM 공식 문서: LLM을 로컬 기기에서 실행할 수 있게 도와주는 프레임워크 (JS/Kotlin/Swift 지원)
- WebGPU 지원 현황: 브라우저에서 GPU 연산을 활용할 수 있는 표준
- MLC 공식 문서: 상용 LLM 파일(safetensor 등)을 브라우저 실행 환경에 최적화하여 컴파일하는 도구
- 테스트 로컬 환경: Apple M4 Pro 칩, 48GB 통합 메모리
