MoE (Mixture of Expert)
Stanford CS336 Language Modeling from Scratch | Spring 2025 | Lecture 4: Mixture of experts
- LLM 모델의 특정 계층을 여러 전문가(Expert)로 나눠서 소수의 전문가만 활성화시킴
- 라고 말하면 LLM 모델 안에 수학 전문가, 영어 전문가, 코딩 전문가 등이 있다고 머릿속에 떠오르지만
- 사실 그런 개념이 아니라 특정 신경망을 여러 개별 묶음으로 나누고 그중 특정 묶음만 활성화시키는 것
- 개별 FFN이 어떤 분야에 특화되어 있는지는 알 수 없음 (블랙박스처럼 결과만 보고 추측할 수 있을 뿐)
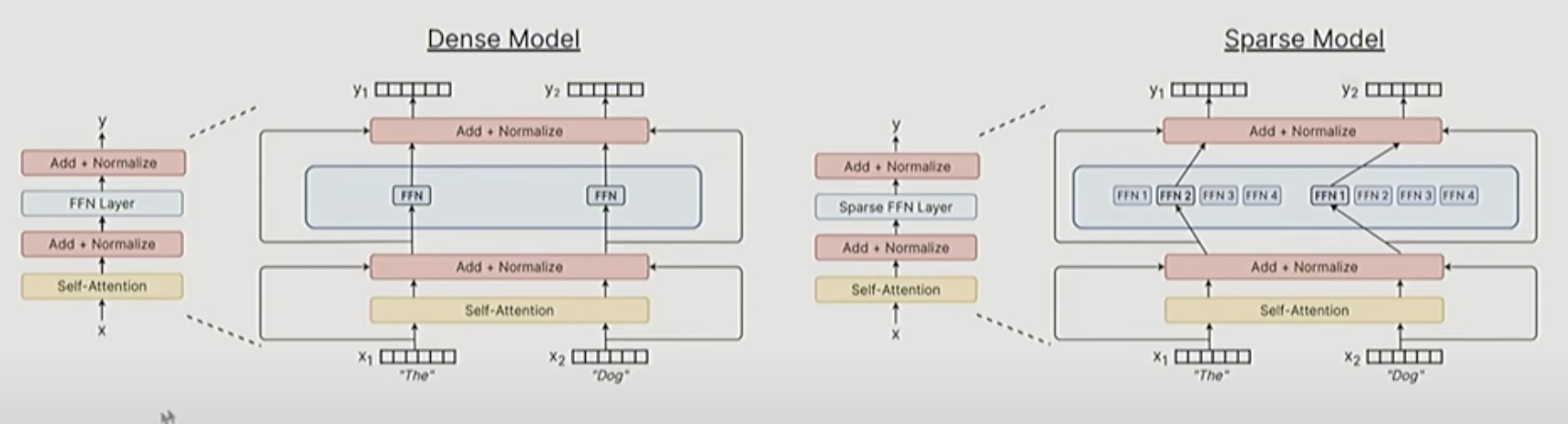
- Dense Model: 기존, Sparse Model: MoE
- 위 그림과 같이 원래는 한 종류의 FFN(항상 동일한 네트워크)만 거치는데, MoE는 여러 FFN 중에 특정 FFN만 활성화시킴
- 장점
- 파라미터 수를 늘려서 얻는 추론 성능 향상과 추론 시 드는 하드웨어 비용 절감
- 학습이 빠르고 오차가 감소한다고 함 (원리는 잘 모름)
- 개별 FFN 단위를 여러 GPU에 올려서 병렬 처리할 수 있음
- 단점
- 어떤 FFN으로 보낼 것인가 → 간단한 Routing 알고리즘 사용
- 원래 MoE는 학습이 불안정하고 구조 설계가 난해해 잘 쓰이진 않는 기술이었음
- 하지만 올해 출시한 DeepSeek에서 MoE 기술을 고도화시킴
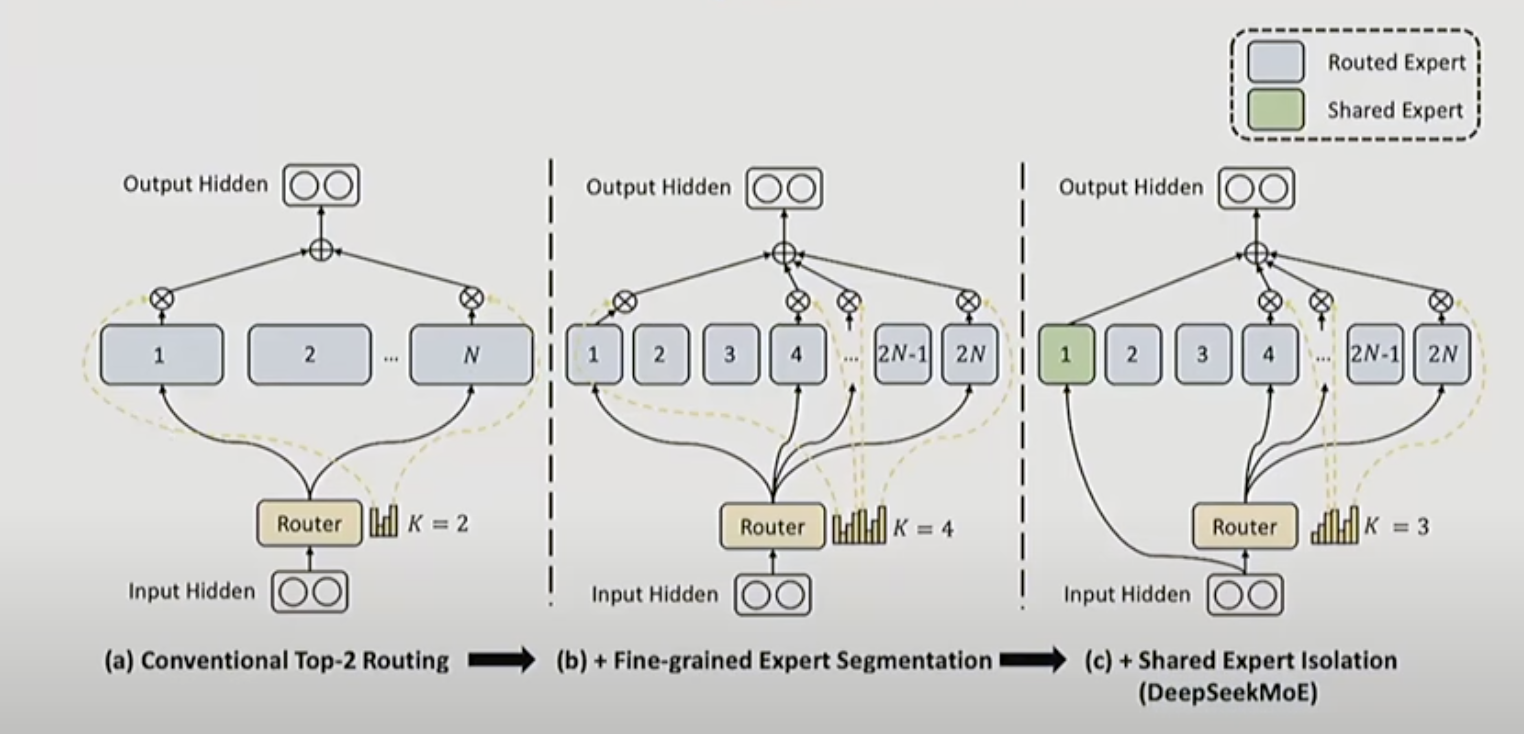
- 선택되는 FFN 개수를 늘릴 수도 있고, 추론 시 특정 FFN을 공유(Shared Expert)하여 항상 거치도록 할 수도 있고 FFN 크기를 줄일 수도 있음
- 전문가를 너무 많이 선택하거나 너무 많이 공유해도 성능이 떨어짐
- DeepSeek V3: 256개 중에 8개 선택, 1개 공유, 기존 대비 1/14 크기
- 주의할 점
- 만약 항상 특정 FFN만 활성화되면? 나머지 FFN은 죽은 거나 마찬가지
- 라우팅이 여러 FFN에 균일하게 갈 수 있도록 해당 로직을 오차 함수에 추가
- 만약 항상 특정 FFN만 활성화되면? 나머지 FFN은 죽은 거나 마찬가지

이유와 방법을 알려주는 메모장 겸 블로그 (Frontend, AI, 경제, 책)