파일 구조
힙
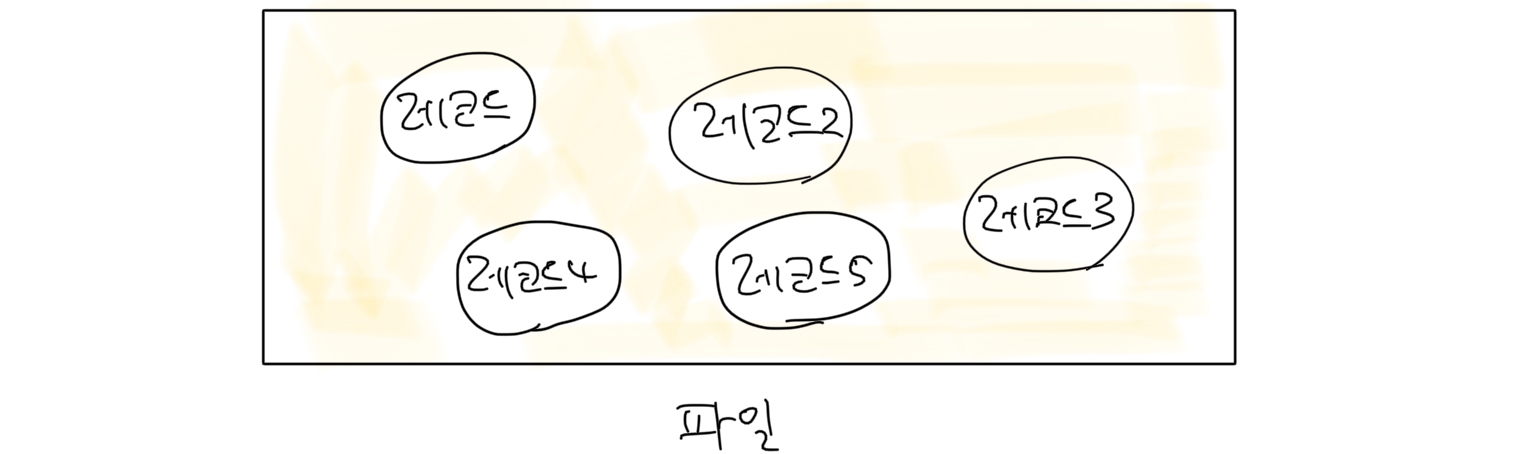
힙(Heap)은 번역하면 더미라는 뜻으로서, 레코드가 파일의 빈 공간에 아무런 순서 없이 저장된 구조입니다. 보통 레코드가 한번 저장되면 위치가 변하지 않기 때문에 어느 파일에 어느 정도의 빈 공간이 있는지 확인할 수 있도록 빈 공간에 대한 정보를 따로 관리하기도 합니다.
순차 접근
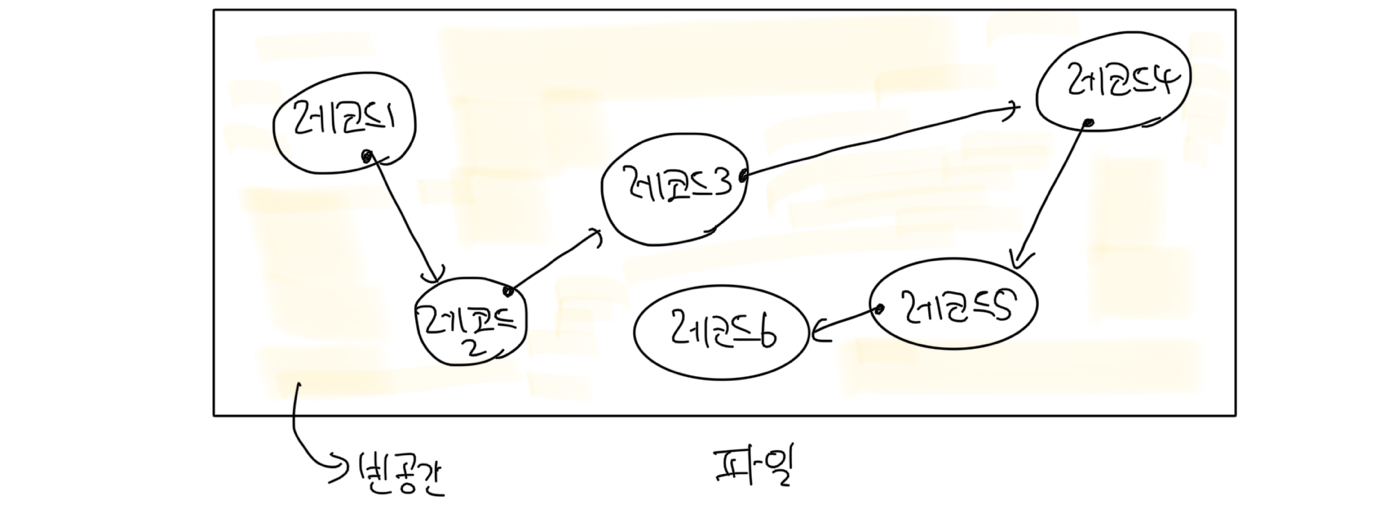
특정 컬럼을 기준으로 레코드가 정렬되어 저장된 구조입니다. 각 레코드는 포인터로 연결돼서 연결 리스트처럼 관리되기에 장단점은 연결 리스트의 장단점이랑 비슷합니다. 항상 레코드에 순차적으로 접근해야 하기 때문에 모든 레코드에 접근할 땐 유리하지만, 특정 레코드만 검색하고 싶을 땐 불리합니다.
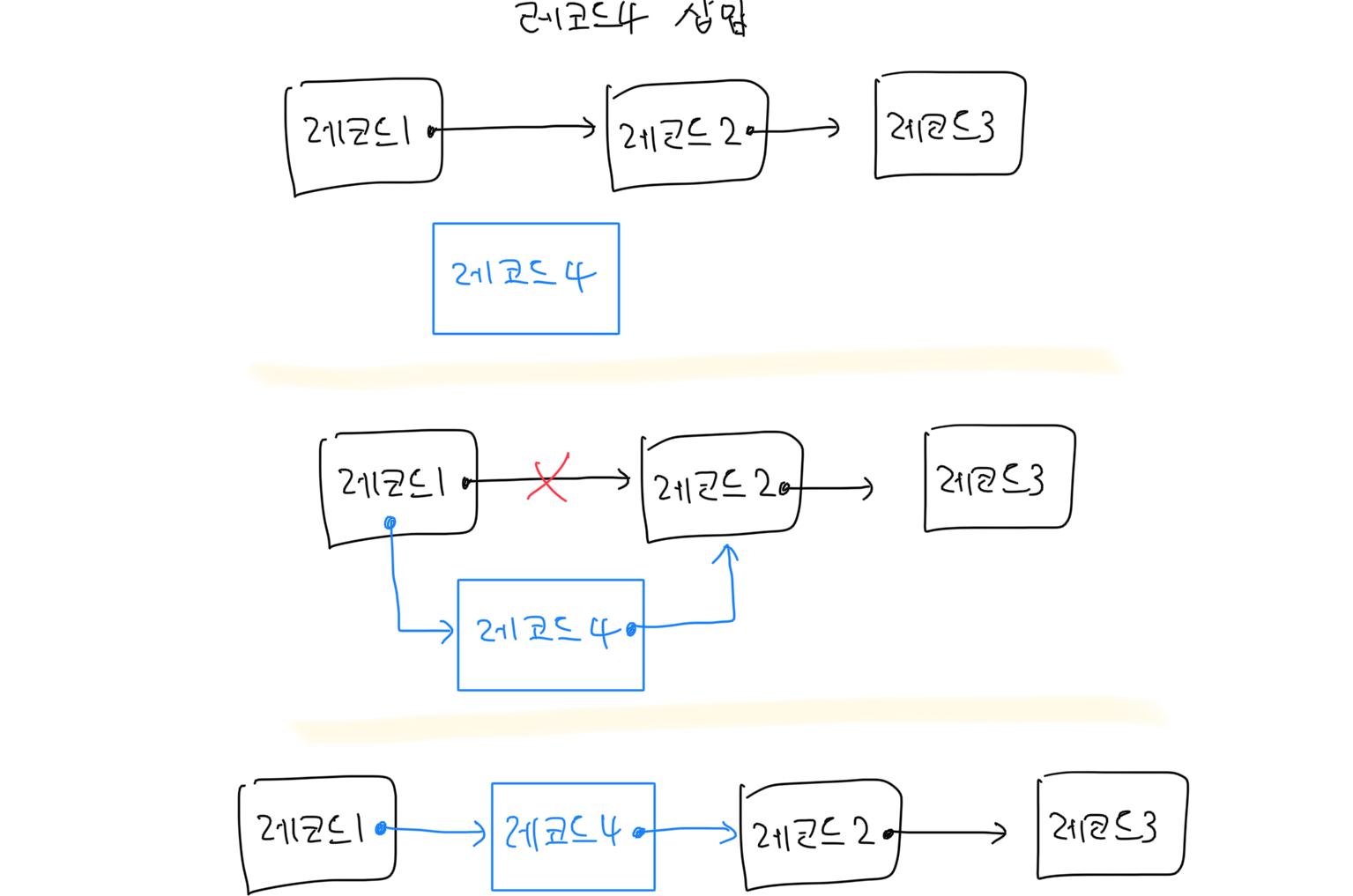
레코드4 삽입
레코드2 삭제
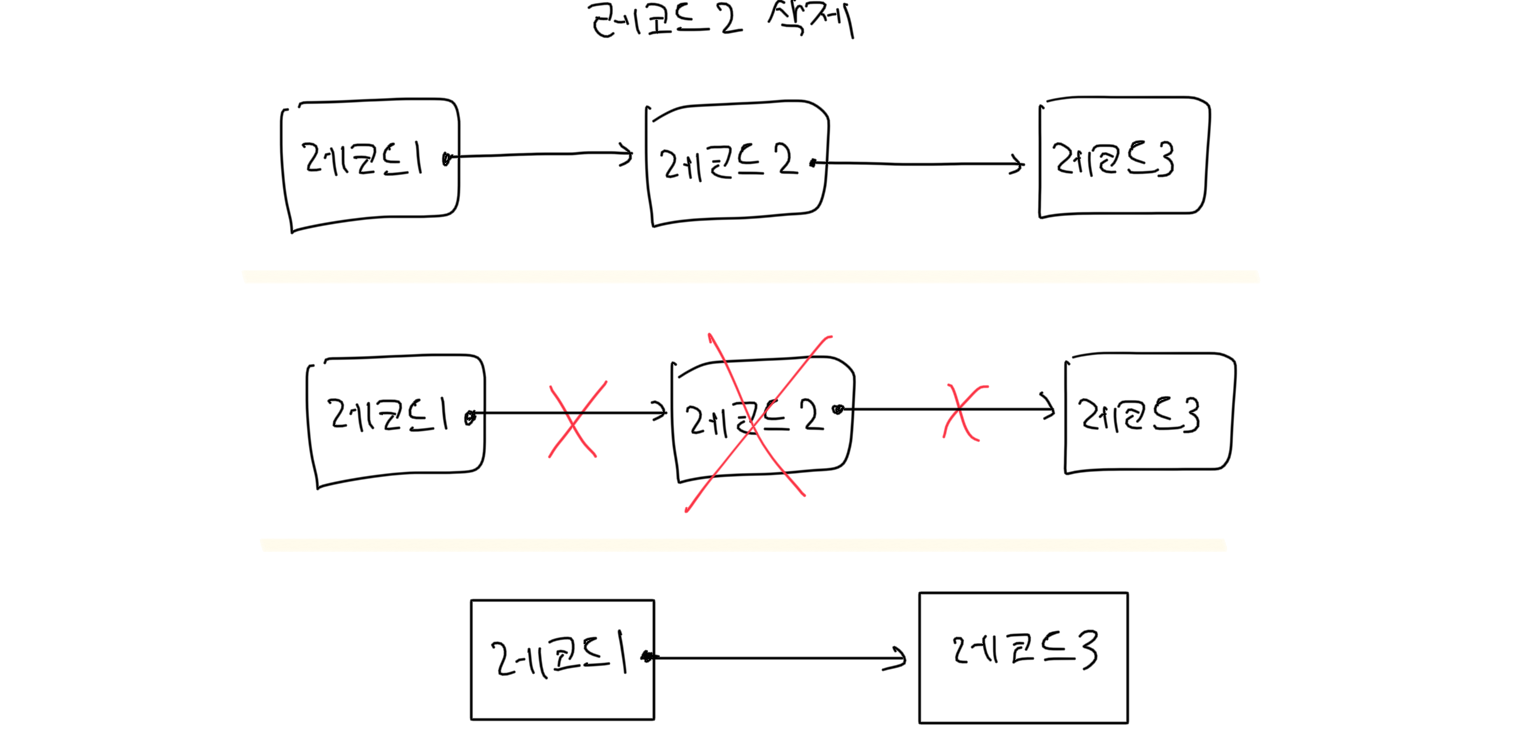
순차 접근에서 레코드 삽입·삭제는 기존 단방향 연결 리스트와 동일합니다. 레코드 삽입도 단방향 연결 리스트에서 노드 삽입하듯이 이뤄집니다. 만약 파일이 저장된 블록에 자리가 없다면 다른 블록(overflow block)에 저장하고 레코드끼리 포인터로 연결합니다. 작업 유형 당 시간복잡도는 아래 표와 같습니다.
| 작업 | 시간복잡도 |
|---|---|
| 삽입 | O(n) |
| 검색 | O(n) |
| 수정 | O(n) |
| 삭제 | O(n) |
순차 접근 방식은 연결 리스트 형태로 관리되어, 여러 번의 삽입·삭제가 이뤄지면서 다른 블록(overflow block)에도 레코드가 저장되면 나면 블록 빈 공간 사용 효율이 떨어집니다. 그래서 주기적으로 파일 구조를 재구성해줘야 하는 단점이 있습니다.
다중 테이블 클러스터링
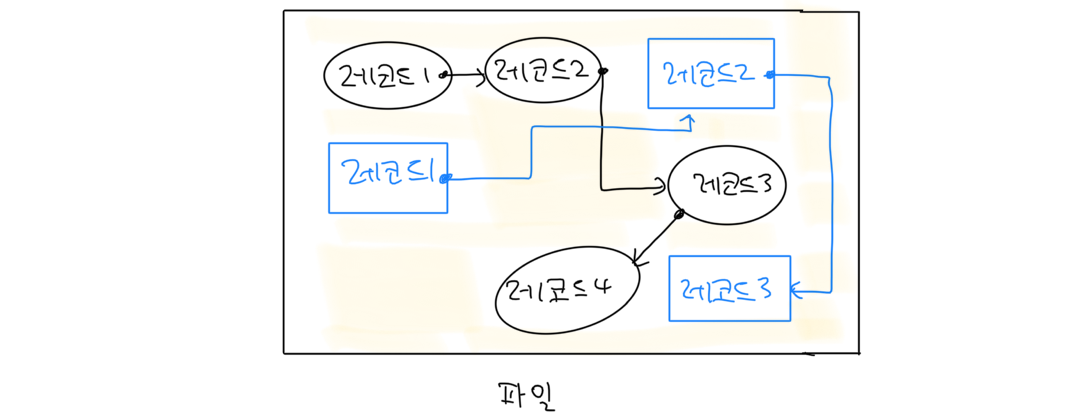
여러 테이블의 레코드를 한 파일에 저장하는 구조입니다. 논리적으로 밀접한 연관이 있는 테이블을 하나의 테이블에 저장하면 각 테이블에 접근할 때마다 발생하던 디스크 I/O 횟수를 줄일 수 있습니다. 이렇게 서로 관련된 레코드를 한 파일에 저장하여 특정 SQL 연산 성능을 높일 수 있습니다.
예를 들어 join 연산은 여러 테이블을 합치는 과정인데 대상 테이블의 모든 레코드가 동일한 블록 내에 있으면 1번의 블록 I/O를 통해 결과를 얻을 수 있습니다. 또는 외래키 필드와 해당 필드가 가리키는 레코드를 한 파일에 모아두면, 레코드가 한 파일에 모여있기 때문에 외래키 join 검색에 유리할 수 있습니다.
또는 인덱스를 걸어놨을 때 좋음?
하지만 한 파일에 여러 테이블의 레코드가 섞여 있기 때문에, 하나의 테이블에 대한 연산 시 각 레코드의 종류를 판단해야 하기 때문에 검색 성능이 낮아진다는 단점이 있습니다. 그걸 방지하기 위해 위 그림과 같이 동일한 테이블 레코드끼리 단방향 연결 리스트로 연결하기도 합니다.
B+Tree
레코드 삽입·삭제 시에도 순서가 유지됩니다.
해싱
특정 레코드의 기본키를 해싱한 값을 기반으로 디스크 블록 내 레코드 위치를 특정합니다.
메타 데이터
데이터베이스엔 방대한 데이터가 저장됩니다. 근데 만약 특정 테이블의 총 레코드 개수를 알고 싶다고 모든 레코드에 접근하며 디스크 I/O를 발생시키엔 비용이 크기 때문에 이러한 데이터는 따로 관리하는 것이 좋습니다. 또는 데이터베이스엔 데이터 자료형이나 제약 조건 등 실질 데이터와 직접 관련이 없는 데이터도 존재합니다. 그래서 데이터베이스는 저장된 데이터의 정보인 메타 데이터를 따로 관리합니다.
데이터와 마찬가지로 메타 데이터 또한 테이블로 관리되어 SQL로 메타 데이터에 접근할 수 있고, 메타 데이터 테이블은 특정 SQL 연산을 수행하기 전에 메모리에 먼저 적재됩니다. 메타 데이터의 종류는 아래와 같습니다.
- 테이블 이름
- 컬럼 이름, 자료형, 크기, 제약 조건
- 뷰 이름, 정의
- 사용자 정보, 비밀번호, 권한
- 데이터베이스 통계 및 로그 자료 (레코드 개수, 연산 횟수 등)
- 테이블 물리적 저장 구조
- 인덱스 이름, 정의
