디스크 구조
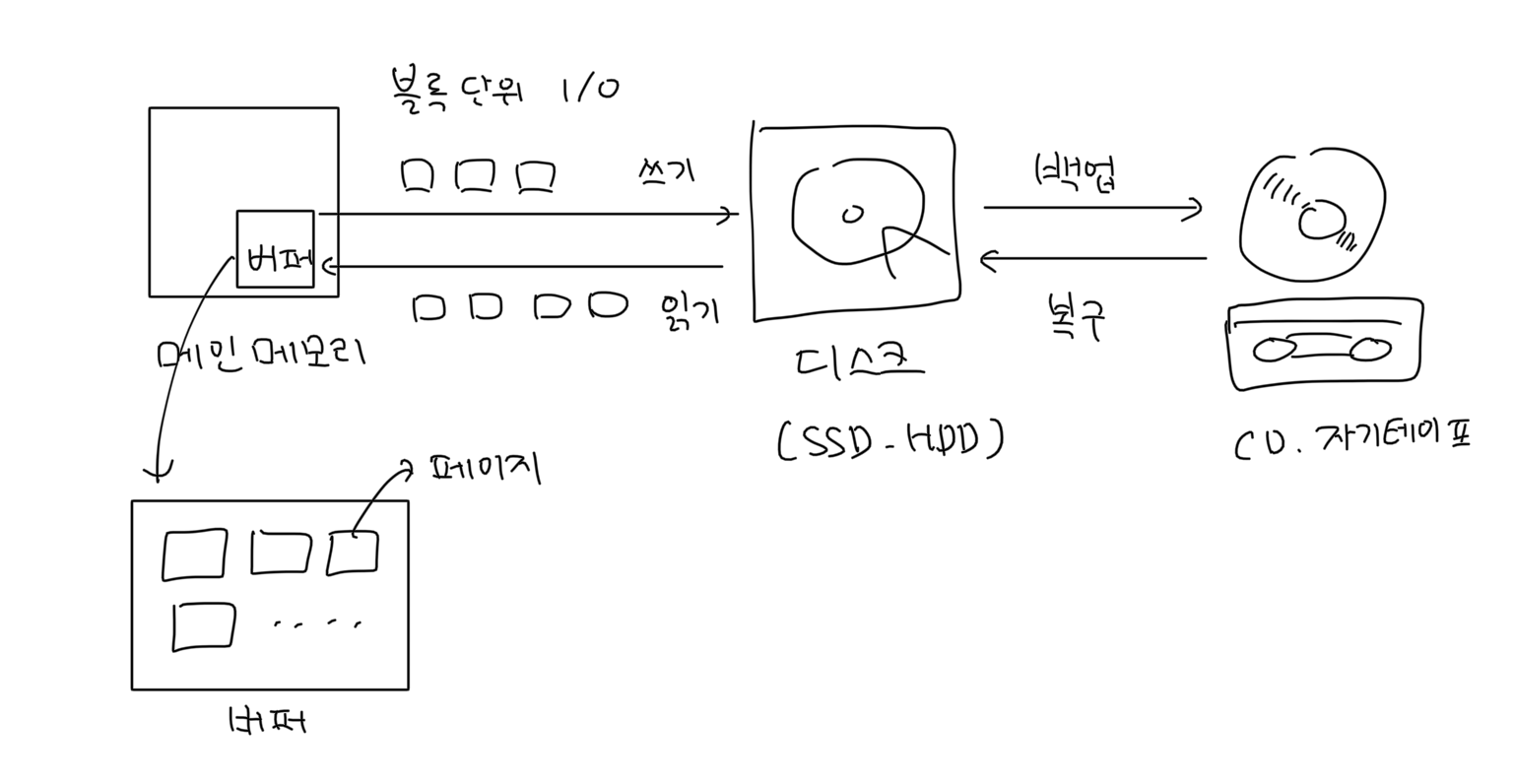
저장 공간은 크게 휘발성 저장 공간과 비휘발성 저장공간으로 나뉩니다. 휘발성 저장 공간인 메모리는 전원 공급이 차단되면 가지고 있는 데이터가 모두 사라지기 때문에, 데이터베이스는 전원 없이도 데이터를 저장할 수 있는 비휘발성 저장 공간인 디스크(예: SSD, HDD)에 데이터를 저장합니다. 일반적으로 디스크에 비해 메모리는 데이터 전송 속도가 빠르고 단위 데이터당 입출력 비용이 낮아서 상대적으로 가격이 비쌉니다. 이 외에도 CD나 자기 테이프와 같은 저장 장치는 가격이 매우 저렴해서 데이터 백업 또는 아카이빙 용도로 많이 사용됩니다.
디스크는 여러 블록으로 구성됩니다. 블록은 디스크 I/O 단위입니다. 블록이 메모리 위의 버퍼에 올라오면 페이지라고 부릅니다. 디스크에 있는 데이터 묶음은 블록이라고 부르고, 메모리 버퍼 위에 있는 데이터 묶음은 페이지라고 부릅니다.
블록 크기는 보통 4~16KB입니다. 블록 단위로 I/O가 이뤄지기 때문에 블록 크기가 작을 수록 한번에 읽을 수 있는 데이터양이 줄어들지만, 블록 크기가 크면 내가 필요하지 않는 데이터도 같이 읽어야 하기 때문에 낭비되는 메모리 공간이 생길 수 있습니다. 만약 블록 크기가 4KB일 때 1KB 파일을 읽으려고 하면 무조건 4KB를 모두 읽어야해서 나머지 3KB의 메모리 버퍼 공간이 낭비될 수 있습니다.
HDD 구조
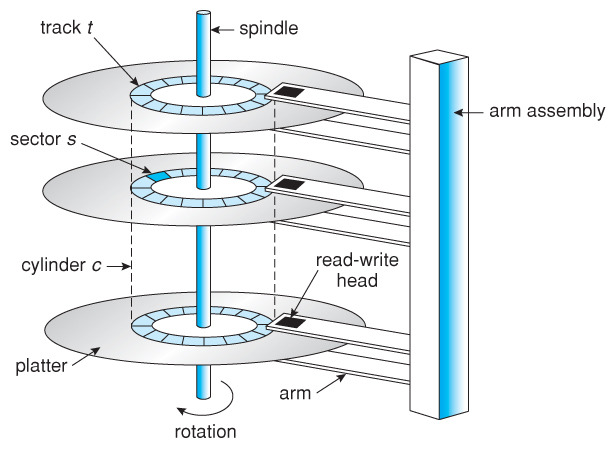
- Platter = track + ... + track = Track 50K ~ 100K개 = 12.5 ~ 100GB
- Track = sector + ... + sector = Sector 500 ~ 2000개 = 256KB ~ 1MB
- Sector = 512 bytes
- Head: 데이터를 자기적으로 읽거나 쓰는 장치
HDD 처리 시간
- Seek time: Head를 특정 track에 위치시키는 시간
- Rotational latency: 특정 sector를 찾기 위해 디스크 원판을 돌리는 시간
- Data transfer time: Head를 통해 자기적으로 저장된 데이터를 읽는 시간
Seek time과 rotational latency는 디스크 헤드의 기계적인 움직임이 필요하기 때문에 상대적으로 시간이 오래 걸리지만, data transfer time은 전기적인 동작이기 때문에 상대적으로 짧습니다.
그리고 만약 동일한 track 위에 데이터를 모아서 저장한다면 해당 데이터에 접근할 때 seek time이 줄어들 수 있어 데이터 전송 속도가 빨라질 수 있습니다.
레코드 구조
- 데이터베이스 = 파일 + ... + 파일
- 파일 = 테이블 + ... + 테이블
- 테이블 = 레코드 + ... + 레코드
- 레코드 = 필드 + ... + 필드
- 레코드 << 블록
일반적으로 한 파일엔 여러 종류의 테이블이 들어갈 수 있고, 동일한 테이블의 레코드일지라도 개별 레코드 크기는 다를 수 있습니다. 그리고 레코드 크기는 블록 크기에 비해 충분히 작다고 가정합니다.
고정 길이
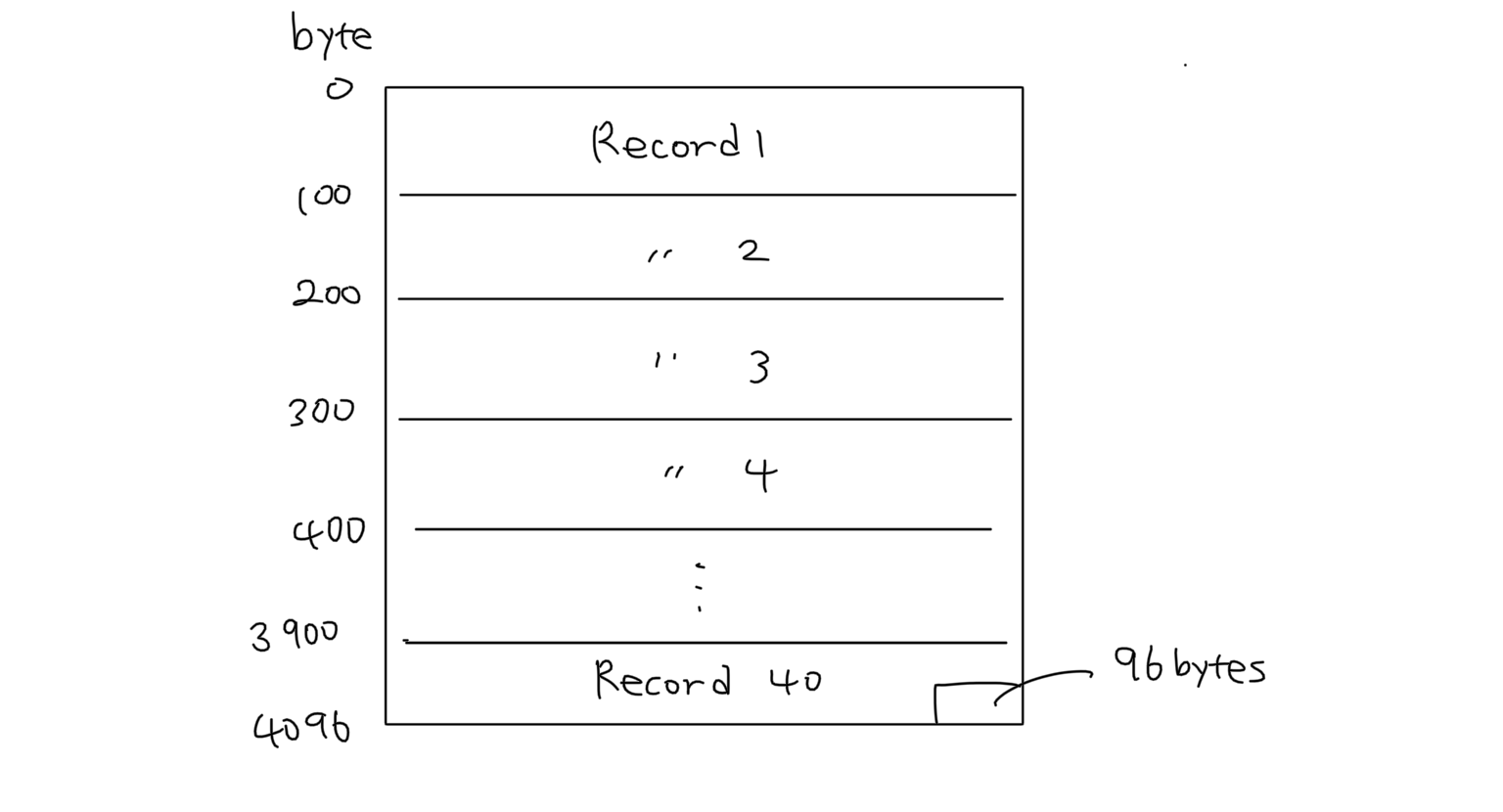
특정 테이블의 레코드 크기는 모두 동일하다고 가정한 경우입니다. 위 그림과 같이 한 블록의 크기가 4KB라고 가정했을 때 레코드 크기가 100 bytes인 경우 한 블록에 최대 40개의 레코드를 저장할 수 있습니다. 나머지 96 bytes는 비어있는 공간으로서 굳이 하나의 레코드를 쪼개서 블록을 꽉 채우지 않고 여유공간을 조금 남겨 놓는 것이 나중에 CRUD 작업을 수행할 때 좋다고 합니다.
가변 길이
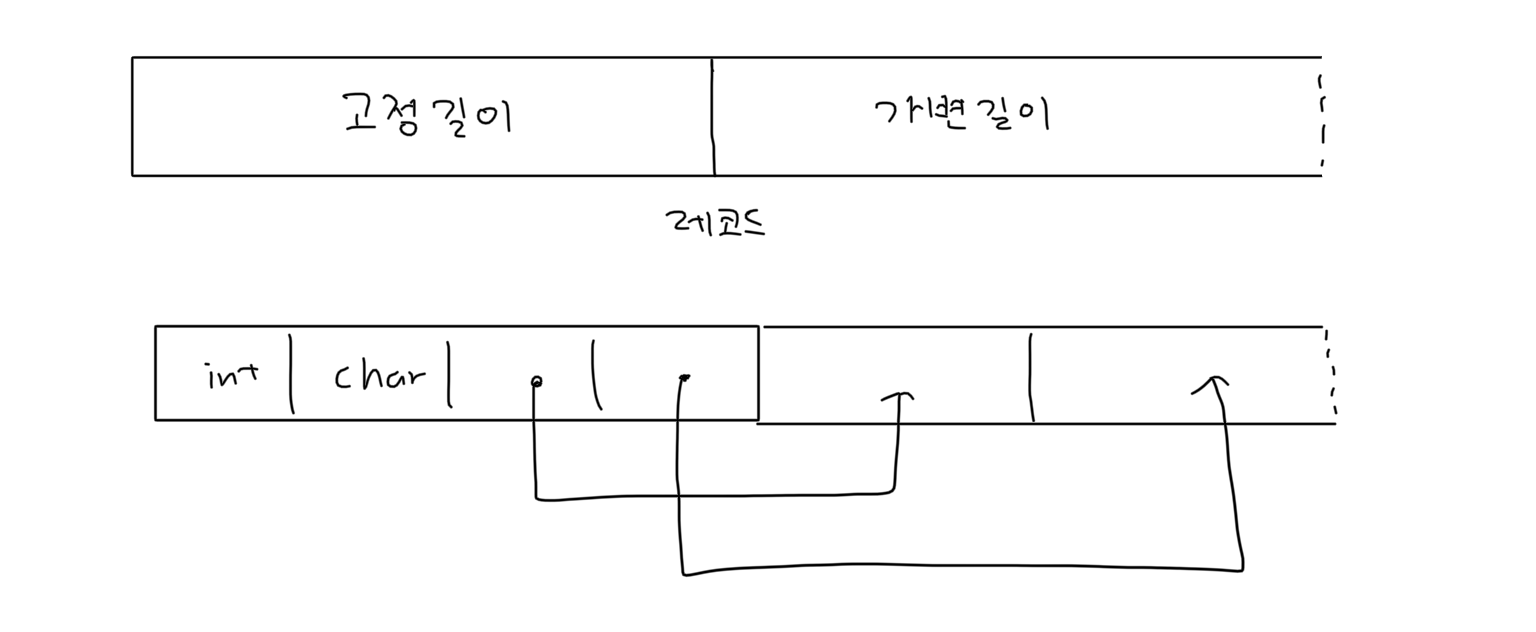
레코드 안에는 여러 필드가 존재하는데 문자열 자료형의 경우 동일한 테이블의 레코드일지라도 각 필드 길이가 달라질 수 있습니다. 그래서 일반적으론 가변 길이 레코드가 많이 사용됩니다.
가변 길이 레코드는 위 그림과 같이 왼쪽에 고정 길이 필드를 모아 놓고, varchar와 같은 가변 길이 필드는 포인터와 데이터 길이로 관리하여 실제 문자열 데이터는 레코드 오른쪽 부분에 저장합니다.
CREATE TABLE test (
id int PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
creation_date timestamptz NOT NULL DEFAULT NOW(),
name varchar(64) NOT NULL,
age int NOT NULL,
address varchar(64) NOT NULL
);
INSERT INTO test (name, age, address) VALUES ('이름이름', 23, '주소주소주소');
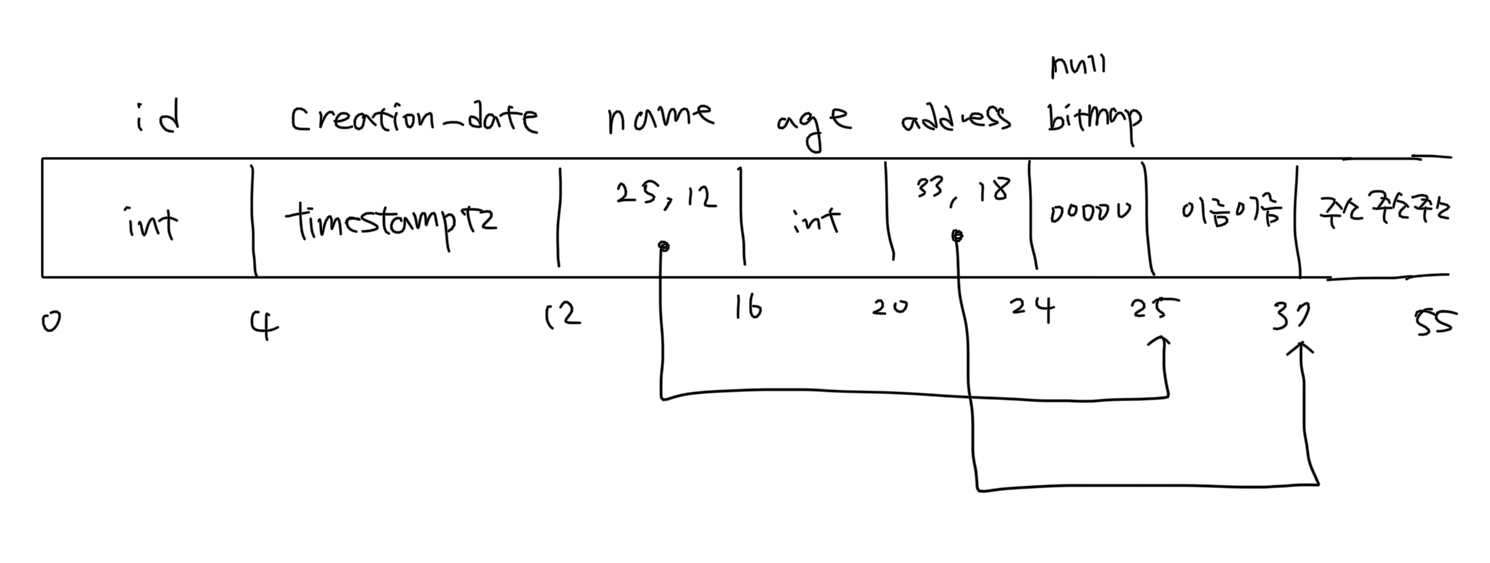
예를 들어 위와 같은 구조를 가진 test 테이블에 레코드를 삽입했을 때 해당 레코드의 물리적인 모습은 위 그림과 같습니다. (포인터는 4 bytes로 관리되고 한글은 UTF-8로 처리된다고 가정합니다.)
블록 구조
일반적으로 디스크 블록의 크기는 4KB ~ 16KB 입니다.
고정 길이 레코드
고정 길이 레코드 방식은 레코드 크기가 모두 동일하기 때문에 레코드를 읽거나 수정하는 작업, 새로운 레코드를 저장하는 과정은 간단합니다. 하지만 레코드 삭제가 까다롭고, nullable 값의 공간 낭비, varchar 같은 문자열 자료형의 관리가 어렵다는 단점이 있습니다.
레코드 삭제 방법 1
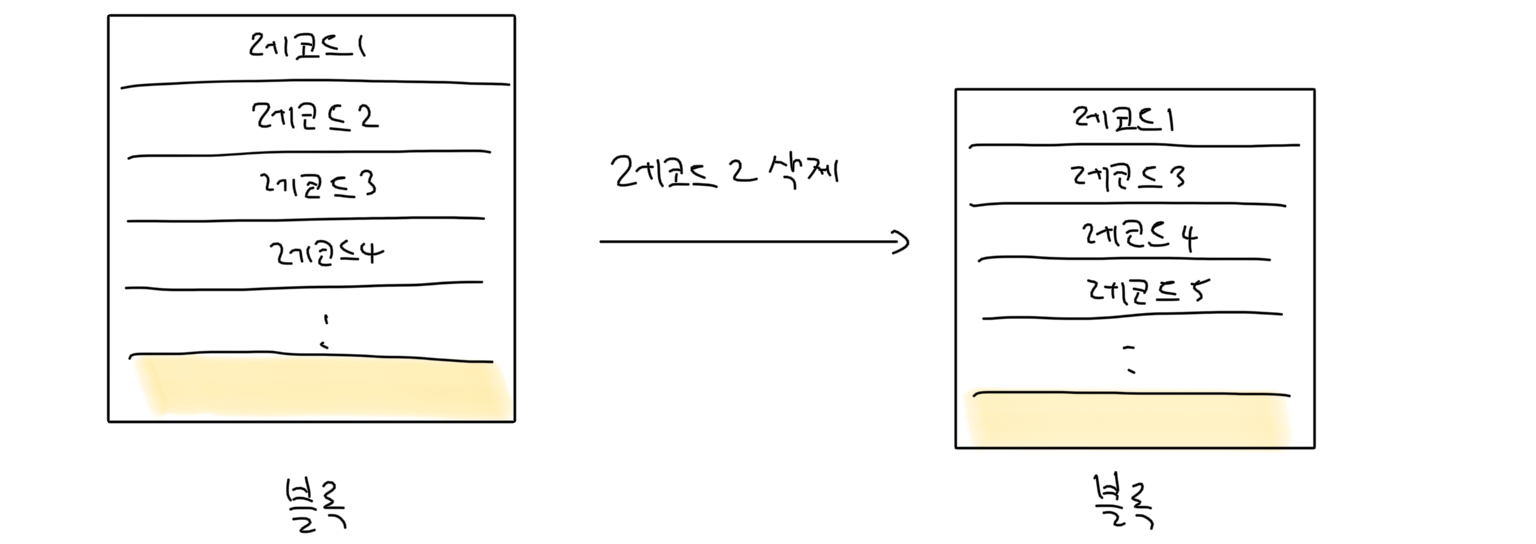
중간에 있는 레코드를 지웠을 때 그 뒤에 있는 레코드를 앞으로 한칸씩 당기는 방식입니다. 빈 공간이 어디 있는지 찾기 쉽고 남아있는 레코드를 관리하기 수월하지만, 삭제한 레코드 뒤에 있는 모든 레코드를 앞으로 한칸씩 당겨야하기 때문에 해당 레코드를 모두 조회하느라 연산이 많이 발생할 수 있다는 단점이 있습니다.
레코드 삭제 방법 2
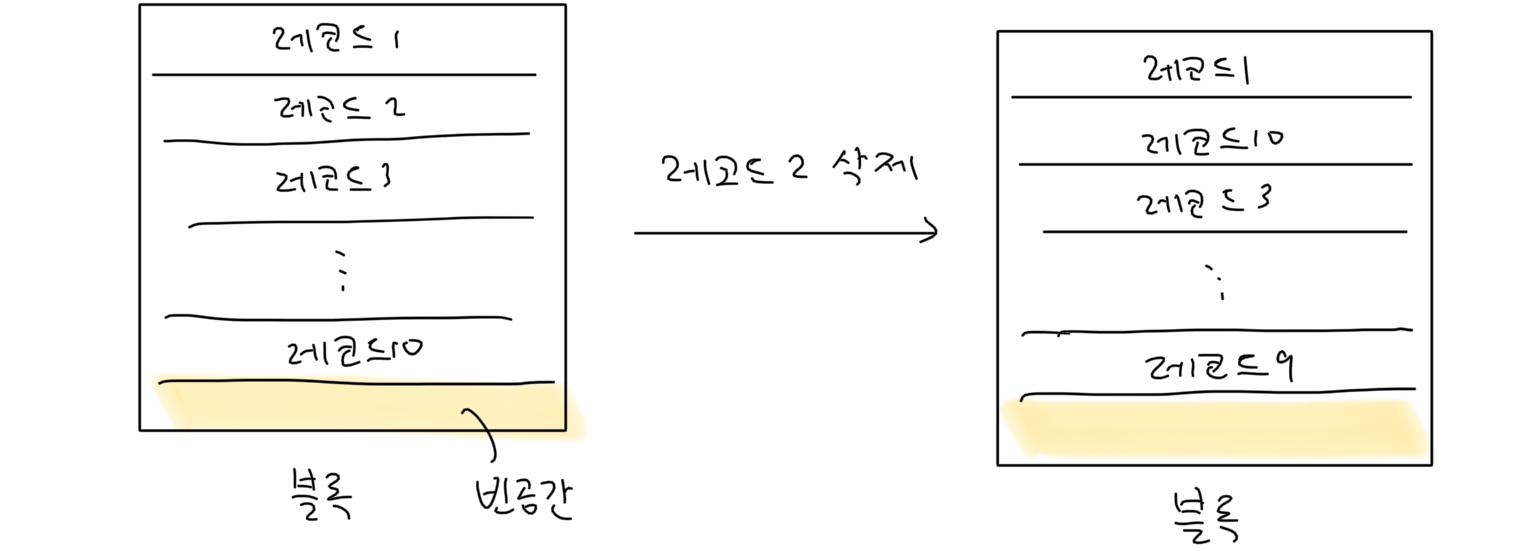
중간에 있는 레코드를 삭제했을 때 제일 뒤에 있는 레코드를 삭제한 자리로 이동시키는 방식입니다. 이 방법은 빈 공간이 어디인지 찾기 쉽지만, 남아 있는 레코드 순서가 유지되지 않는다는 단점이 있습니다.
레코드 삭제 방법 3
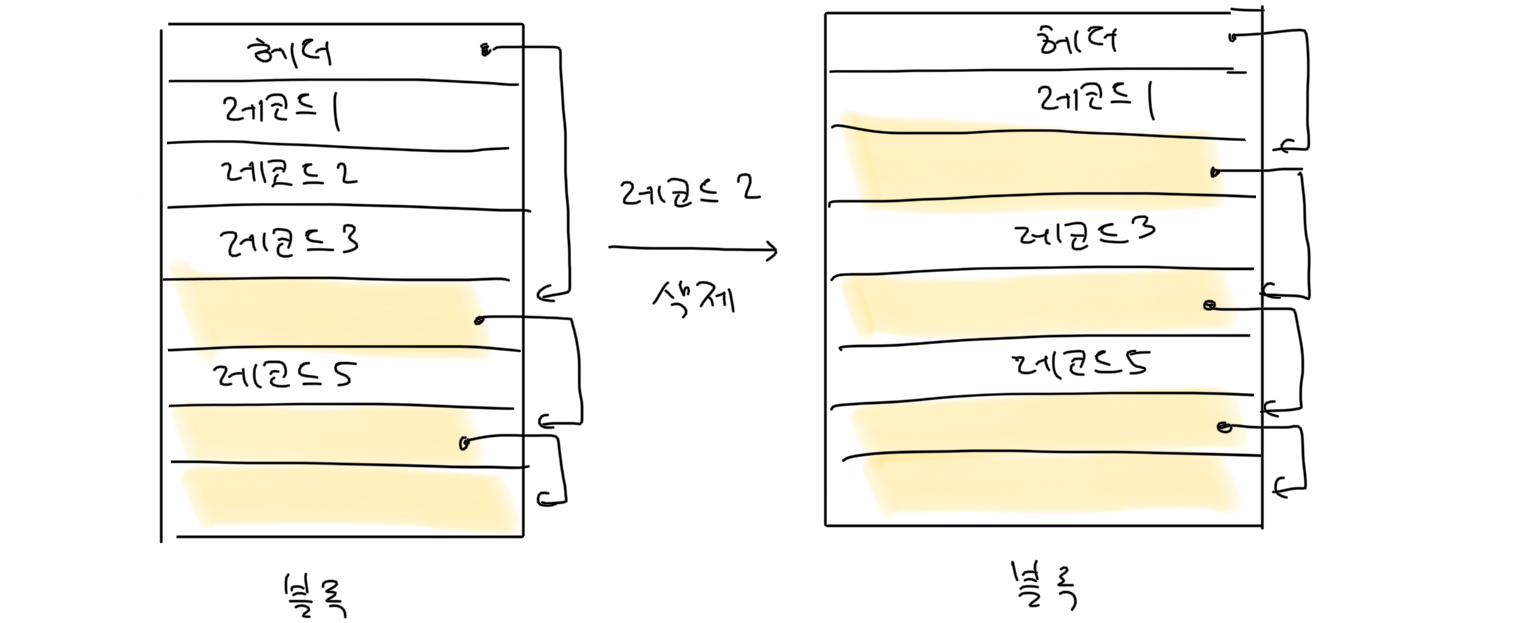
비어 있는 레코드를 연결 리스트 형태로 관리하는 방식입니다. 헤더가 하나의 레코드 공간을 차지한다는 단점이 있지만 삭제 시 연산량이 적다는 장점이 있습니다.
가변 길이 레코드
가변 길이 레코드로 이루어진 블록은 레코드 슬롯과 레코드 데이터로 이루어져 있습니다.
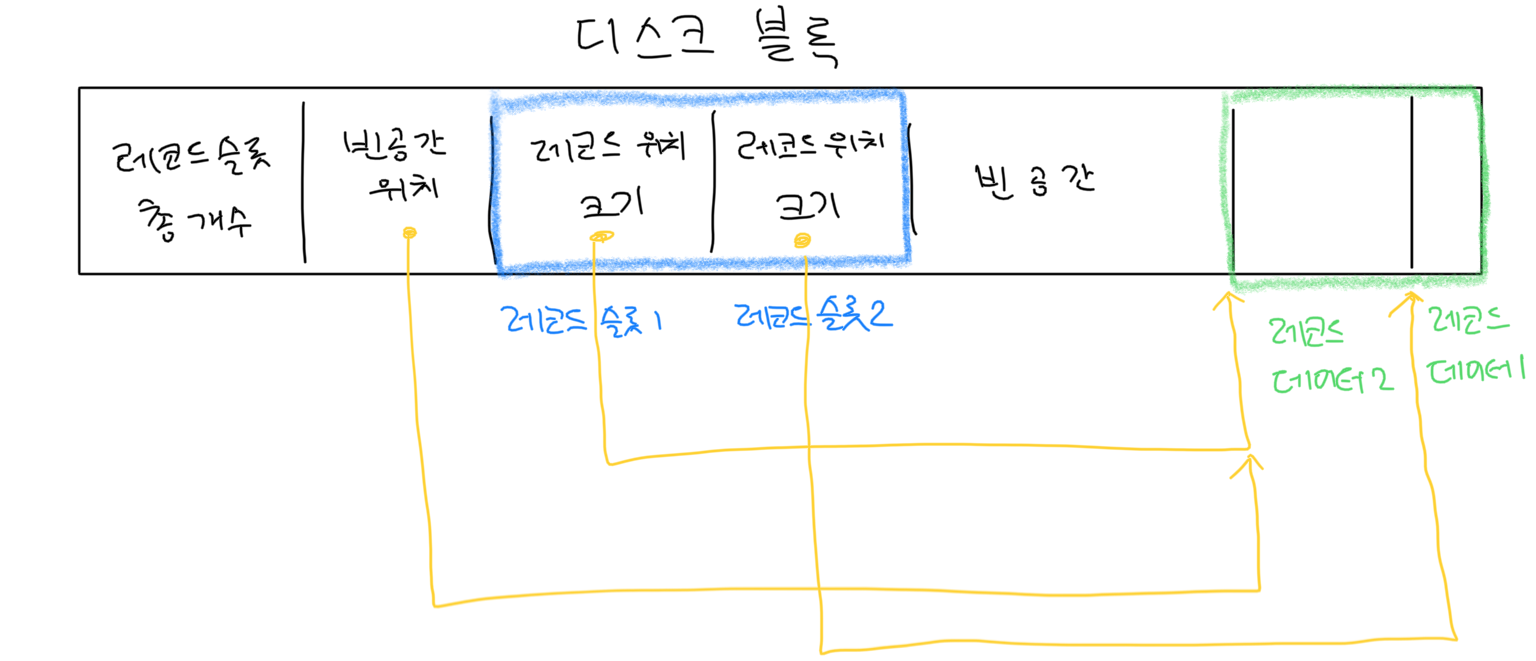
위 그림에서 블록 오른쪽에 보이는 레코드 데이터는 물리적으로 빈 공간이 없이 붙어있어서 블록 공간을 효율적으로 사용할 수 있습니다. 만약 레코드 데이터가 삭제되면 빈자리를 메우기 위해 옆에 있는 레코드를 한 칸씩 옮깁니다. 보통 같은 테이블 내 레코드를 동일한 블록에 위치시키는데 이러면 적은 I/O 요청으로 여러 레코드를 불러올 수 있다는 장점이 있습니다.
위 그림에서 왼쪽에 보이는 레코드 슬롯은 레코드 위치와 레코드 크기 정보를 담고 있고, 이 외에도 레코드 슬롯의 개수와 빈 공간의 위치 정보를 가지고 있습니다. 그리고 슬롯과 레코드 모두 삽입·삭제가 가능하기 때문에 슬롯은 왼쪽에서 오른쪽으로, 레코드는 오른쪽에서 왼쪽으로 사이에 빈 공간 없이 쌓여 나갑니다. 그리고 가운데의 남는 공간이 free space 입니다.
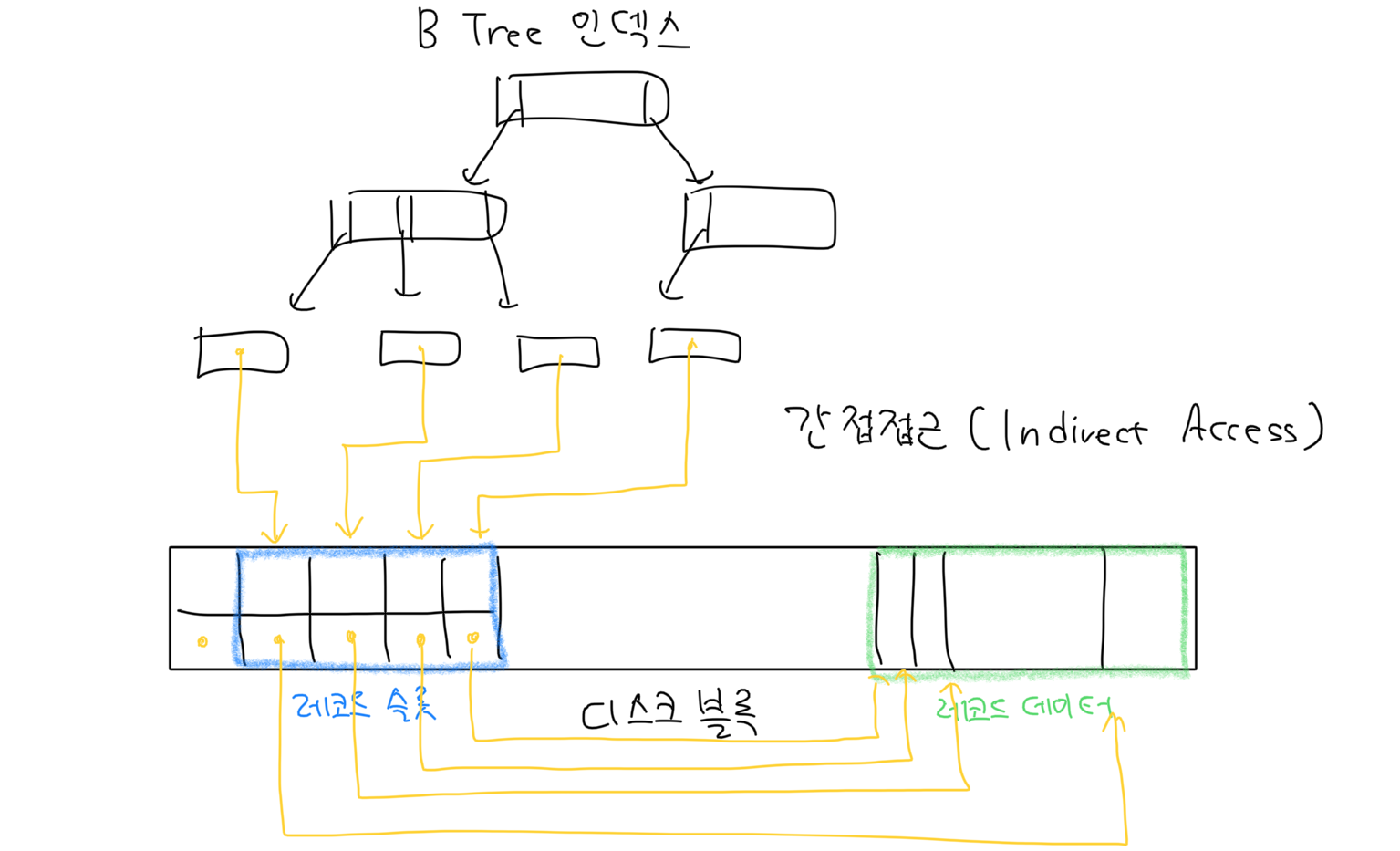
하나의 레코드 슬롯은 하나의 레코드 데이터를 가리키고 있는데 만약 외부에서 레코드 데이터에 접근할 일이 있으면 레코드 슬롯을 거쳐서 레코드 데이터에 접근해야 합니다. 이를 간접 접근(Indirect access)라고 합니다. 왜 간접 접근을 하냐면 레코드 데이터 삭제 시 레코드 데이터는 빈 자리를 메우기 위해 한칸씩 이동하는데, 이러면 외부에서(예: 인덱스 등) 레코드를 가리키는 포인터 주소를 전부 일일이 수정해줘야 하는 번거로움이 생깁니다. 반면 레코드 데이터 위치가 변경돼도 이를 레코드 슬롯에만 반영하면 레코드 데이터 위치가 변경되는 것에 상관없이 외부에서 레코드 데이터에 항상 정확하게 접근할 수 있어 일반적으로 DBMS는 간접 접근 방식을 사용합니다.
레코드 삽입
만약 새로운 레코드가 추가되면 레코드 데이터는 free space 오른쪽에 쌓이고, 데이터 위치와 크기 정보가 담긴 레코드 슬롯은 free space 왼쪽에 쌓입니다.
레코드 읽기
레코드의 크기가 일정하지 않고, 삽입·삭제 시마다 레코드 데이터의 위치가 변경되기 때문에 레코드 접근은 레코드 슬롯을 통해 간접적으로 접근합니다. 레코드 데이터를 읽는 과정은 아래와 같습니다.
- 디스크에 있는 블록이 메모리에 있는 버퍼로 복사됩니다.
- 버퍼에 있는 페이지(블록)의 레코드 슬롯에 접근합니다.
- 레코드 슬롯에 있는 레코드 데이터 위치를 통해 레코드 데이터에 접근합니다.
레코드 수정
레코드 수정 시 레코드 길이가 달라질 수 있습니다. 이 경우엔 길이가 달라진 만큼 레코드 데이터를 빈 자리가 없게끔 이동시키고 레코드 슬롯의 레코드 크기 값도 갱신해줍니다.
레코드 삭제
레코드 삭제 시 레코드 데이터는 빈 자리를 메우기 위해 한칸씩 옮기지만, 외부에서 해당 슬롯의 주소를 참조하고 있을 수 있기 때문에 레코드 슬롯은 그대로 두고 레코드 슬롯에 레코드가 삭제됐다는 표시만 남깁니다. 그리고 새로운 레코드 슬롯은 삭제된 레코드 슬롯 자리를 덮어 쓸 수 있습니다.
대용량 데이터
데이터 중에선 이미지나 동영상과 같이 한 블록에 모두 저장할 수 없는 데이터도 있습니다. 이러한 데이터를 대용량 데이터(Large object)라고 부르는데 종류는 아래와 같습니다.
- Binary Large Object = BLOB = 이미지, 동영상 등
- Character Large Object = CLOB = 문서 등
대용량 데이터를 컬럼으로 가지는 테이블의 레코드는 개별 레코드 크기가 디스크 블록 크기를 넘을 수 있습니다. 그래서 데이터베이스에 바로 저장하기 보다 아래와 같이 다른 방식으로 대용량 데이터를 관리합니다.
대용량 데이터 관리 방식 1
대용량 데이터 관리를 OS의 파일 시스템에 맡깁니다. 하지만 OS에서 해당 파일이 없어지면 데이터베이스에 따로 알려주지 않는 이상 없어진 사실을 모르기 때문에 Not found 오류가 발생할 수 있습니다.
대용량 데이터 관리 방식 2
대용량 데이터를 OS의 파일 시스템에 저장하지만 해당 데이터의 읽기·쓰기는 DBMS가 관리합니다.
대용량 데이터 관리 방식 3
대용량 데이터를 레코드에 저장할 수 있도록 충분히 작은 조각으로 나눠서 관리합니다. 여러 데이터 조각은 보통 B+Tree 인덱싱을 통해 관리되는데, 데이터의 특정 범위만 접근하는 것이 용이하고 새로운 데이터의 삽입/삭제가 용이하다는 장점이 있습니다.

잘 읽었습니다!
혹시 참고하신 자료가 뭔지 알 수 있을까요??