무어의 법칙
인텔 CPU의 트랜지스터 개수의 추이를 보고 생각해낸 것으로 트랜지스터 집적도가 2년마다 2배로 증가한다는 경향이다.
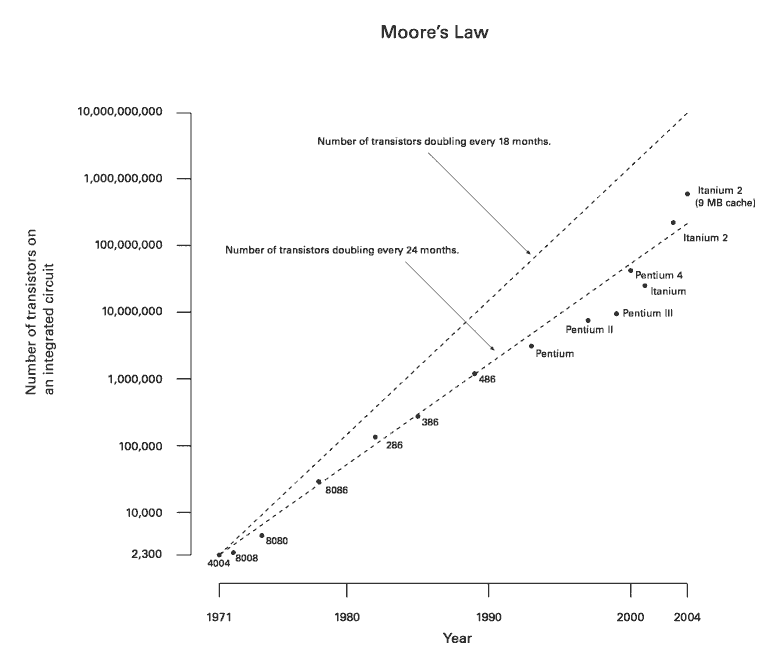
-
트랜지스터 집적도는 2년마다 2배 증가한다.
-
명령어 처리 단계에서의 병렬화에 한계가 왔다.
branch prediction,pipelining,out of order execution등이 존재하고, 이제 더 개선할 여지를 찾기 힘들다. -
클럭 속도는 그런 경향이 있었으나 없어졌고, 대신 코어 개수가 증가하고 있다. 클럭 속도를 너무 높이면 발열과 전력 소모가 심해지기 때문이다. 따라서 코어를 효율적으로 활용하는 것이 중요해졌다.
멀티코어 형태
CMP
Chip MultiProcessor. 1개의 CPU 칩 안에 여러 개의 코어가 존재하는 형태다. 코어끼리 캐시를 일부 공유하기도 한다. 가정용 PC에서 많이 쓰이는 구조다.

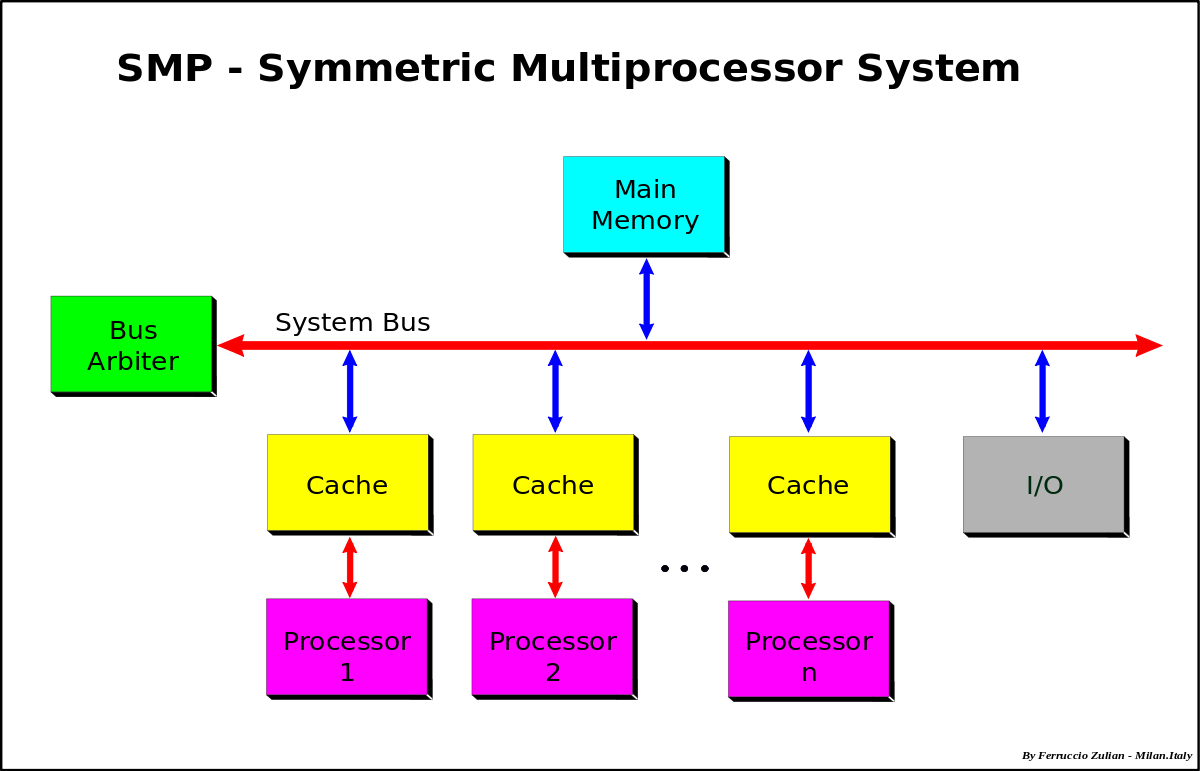
SMP
Symmetric MultiProcessor. 1개의 컴퓨터 안에 여러 개의 동일한 CPU 칩이 들어있는 형태다. 여러 개의 CPU가 하나의 메인 메모리를 공유하고, 하나의 운영체제에 의해 관리된다. 캐시는 CPU마다 존재하고 직접적으론 접근할 수 없고, 메인 메모리를 통해 다른 CPU의 캐시에 간접적으로 접근할 수는 있다. 기업용 서버에서 많이 쓰이는 구조다.
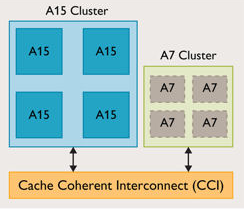
Heterogeneous Chip
Asymmetric CPU. 대표적으로 ARM의 big.LITTLE 형태의 모바일 CPU가 존재하는데 구조는 아래와 같다. 여기서 A15가 성능이 좋지만 발열과 전력 소모가 높은 프로세서고, A7이 성능은 낮지만 발열과 전력 소모가 적은 프로세서다. 이처럼 CPU의 각 코어 성능이 서로 다른 경우를 의미한다.
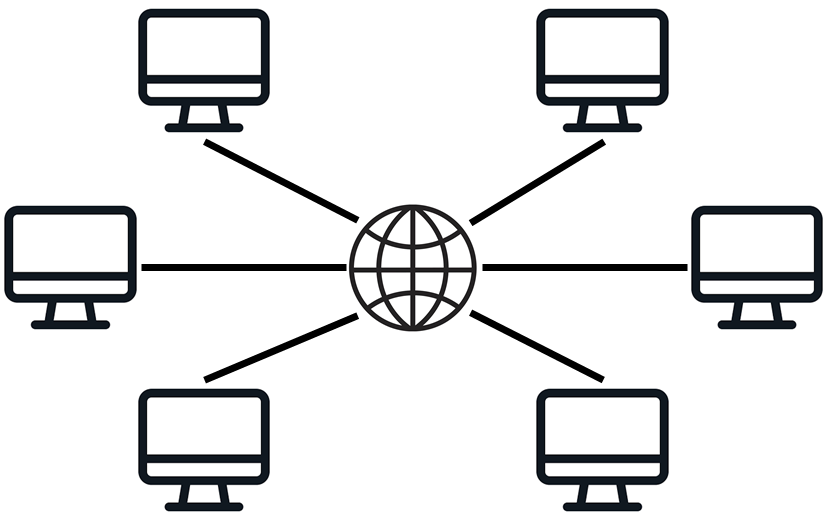
Cluster
여러 개의 PC를 네트워크를 통해 하나로 묶은 단위다. PC끼리 메인 메모리를 직접적으로 공유하진 않는다.
GPU
하나의 그래픽카드에는 몇 천 개의 코어가 존재한다. 따라서 행렬 계산과 같은 특정 상황에서 CPU보다 좋은 성능을 보여줄 수 있다. 하지만 GPU는 지원하는 명령의 범위가 좁기 때문에 범용적인 면에선 CPU보다 성능이 떨어진다. 따라서 CPU와 GPU를 적절히 섞어서 사용하면 병렬처리의 효율을 높일 수 있다.
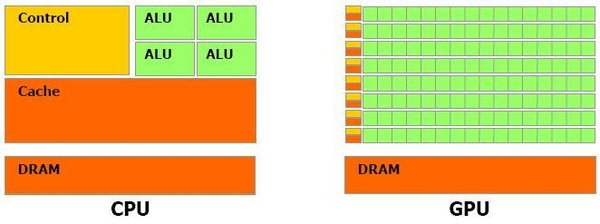
위 그림과 같이 CPU는 연산을 수행하는 ALU의 수가 상대적으로 적은 대신 지원하는 명령어의 범위가 넓고, GPU는 ALU 개수가 많은 대신 지원하는 명령어 범위가 좁다.
멀티코어 컴퓨터 분류
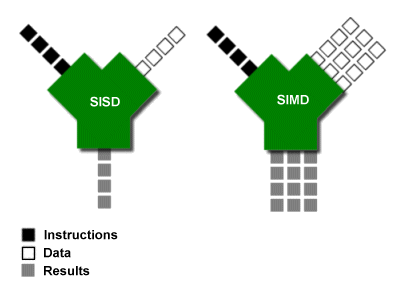
SISD
Single Instruction, Single Data. 가장 간단한 형태의 컴퓨터로서 가장 먼저 등장했으며 명령어가 한 프로세서에서 순차적으로 실행되는 컴퓨터다.
SIMD
Single Instruction, Multiple Data. 여러 개의 프로세서가 존재하지만, 모든 프로세서가 동일한 시점에 동일한 명령어를 실행하는 형태의 컴퓨터다. 대표적으로 그래픽카드가 있으며 그래픽카드는 모니터의 모든 픽셀 값을 계산하기 위해 동일한 시점에 같은 명령어를 각 픽셀에 대해 수행한다.
MISD
Multiple Instruction, Single Data. 같은 데이터에 대해 동시에 여러 명령어를 처리하는 컴퓨터다.
MIMD
Multiple Instruction, Multiple Data. 여러 개의 프로세서에서 서로 다른 명령어가 실행되는 컴퓨터의 형태다. 병렬처리 컴퓨터의 일반적인 형태이고, 슈퍼컴퓨터도 이 형태에 속한다.
멀티코어 프로그램 개발 단계
1. Decomposition
처리할 작업을 일정 단위로 분할한다. 병렬처리가 가능한 부분과 불가능한 부분을 구분해 성능을 얼마나 높일 수 있는지 예상한다.

위와 같은 상황에선 프로세서 1개로 100초가 걸릴 일을 프로세서 5개로 60초 만에 처리할 수 있다. 프로세서가 5개로 늘어났으니 성능도 5배 증가할 것으로 예상할 수 있지만, 병렬처리 가능한 부분이 제한되어 있기 때문에 암달의 법칙에 의해 1.67배까지만 성능 향상을 기대할 수 있다.
Domain Decomposition
처리할 데이터를 프로세서 수만큼 분할한다. 그럼 프로세서가 일정 부분의 데이터를 처리한다. 예를 들어 1~100까지의 데이터가 있고 4개의 프로세서가 있으면, 데이터를 1~25, 26~50, 51~75, 76~100과 같이 나누고 각 프로세서에게 할당하는 것이다.
Functional Decomposition
데이터를 처리하는 과정을 프로세서 수만큼 분할한다. 그 과정은 병렬처리가 가능해야 한다. 예를 들어
2. Assignment
분할한 작업을 특정 프로세서에게 할당하는 과정으로 작업 분배(load balancing)와 연관이 있다. 작업을 각 프로세서에게 균형있게 할당해 프로세서 간 데이터 교환 횟수를 줄이는데 목적이 있다. 작업 분배는 프로그래밍 시점(static) 또는 프로그램이 시작된 시점(dynamic)에 이뤄질 수 있다.
3. Orchestration
작업을 처리하면서 프로세서끼리 데이터를 주고 받는 형식과 데이터 일관성을 유지하는 방법을 정의하는 단계다. 메모리 지역성을 잘 활용하게끔 데이터 구조를 잘 설계하는 것이 중요하다.
4. Mapping
CPU 스케줄링으로서 비슷한 데이터에 접근하는 스레드를 동일한 프로세서에게 할당해서 메모리 지역성(locality)을 높이는 방법을 사용한다.
