멀티코어 성능을 올리는 방법은 팀플을 효율적으로 진행하기 위한 방법과 비슷하다. 병렬처리 성능에 영향을 미치는 요소는 다음과 같다.
병렬처리 오버헤드
- 스레드를 실행하는 비용
- 스레드끼리 데이터를 주고 받는 비용
- 데이터의 일관성(synchronizing)을 유지하는 비용
이 같은 오버헤드가 많으면 병렬처리의 성능이 낮아진다. 일반적으로 한 작업의 크기(granularity)가 클수록 오버헤드가 적어진다.
암달의 법칙
멀티코어 프로그램의 성능 향상은 다음과 같다.
p : 병렬처리 가능한 부분의 비율
n : 프로세서 개수
프로세서 개수가 무한하다면 최대 성능 향상은 다음과 같다.
p : 병렬처리 가능한 부분의 비율
Scalability
프로세서 수에 따른 성능 향상을 의미한다. 프로세서 수와 성능 향상이 정비례하면 좋은 확장성(scalability)을 가진 것이고, 그래프가 log 또는 상수 함수의 형태라면 나쁜 확장성을 가졌다는 뜻이다.
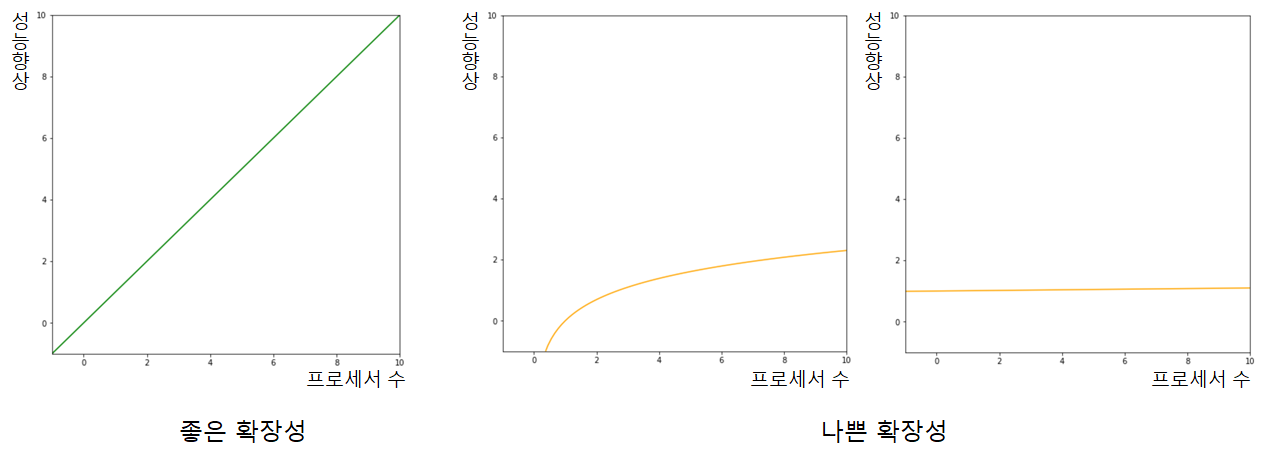
엄밀히 말하면 프로세서 수가 많아질수록 프로세서 간 데이터 교환에 따른 오버헤드도 증가해 실제론 1차함수보다 약간 낮아진 그래프 형태를 띤다.
Granularity
한 작업의 크기를 의미한다. 즉, 계산과 데이터 교환(communication)의 비율을 의미한다. 데이터 교환 비율이 계산 비율보다 많으면 작업의 크기가 작다(fine)고 하고, 계산 비율이 데이터 교환 비율보다 많으면 작업의 크기가 크다(coarse)고 한다.
작업의 크기가 작을수록(fine) 적절한 작업 분배(load balancing)가 쉬워지지만, 데이터 교환 오버헤드가 증가한다. 그리고 작업의 크기가 클수록(coarse) 데이터 교환 오버헤드가 감소하지만, 작업이 비효율적으로 분배될 수 있다. 일반적으로 최대한 작업의 크기를 크게 잡고, 작업 분배를 개선하는 방향으로 나아간다.
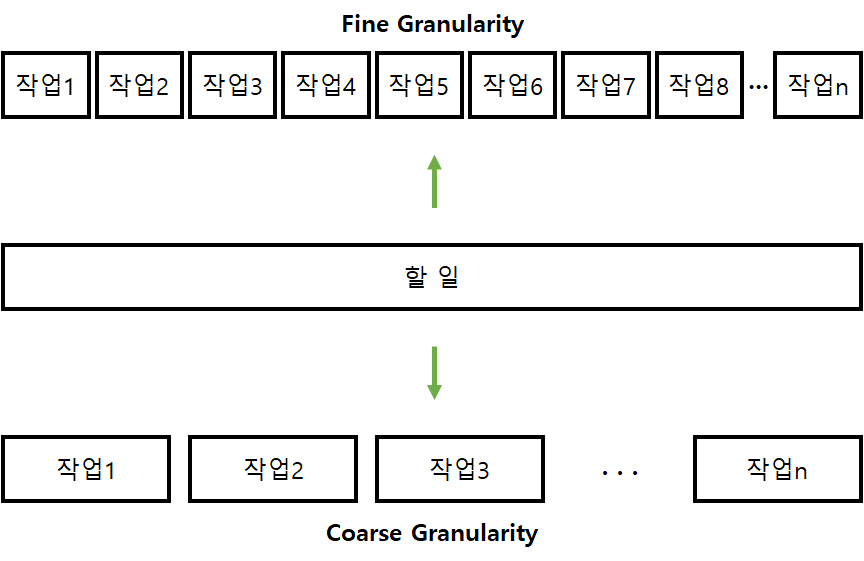
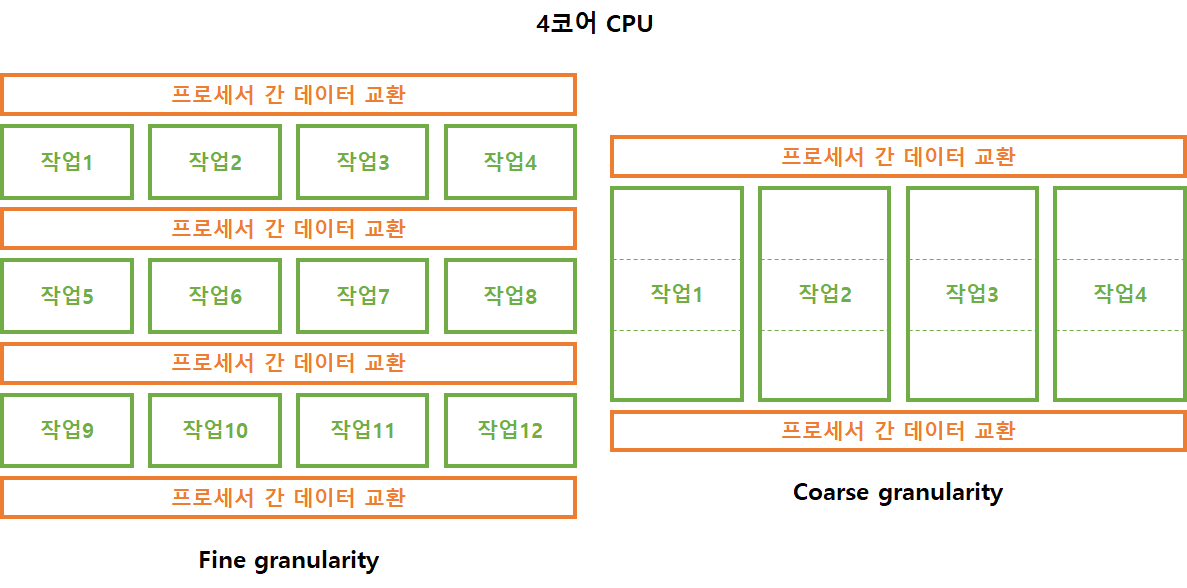
- Fine Granularity ➞ 적절한 작업 분배, 데이터 교환 오버헤드↑
- Coarse Granularity ➞ 비효율적인 작업 분배, 데이터 교환 오버헤드↓
Locality
지역성은 캐시를 적절히 활용해 성능을 높이는 방법으로서 멀티코어 컴퓨팅 뿐만 아니라 다른 분야에서도 쓰이는 기술이다. 지역성은 최근에 사용한 데이터이거나 그 데이터 근처에 있는 데이터엔 빠르게 접근할 수 있다는 캐시의 특성에 기반한다. 전자를 시간 지역성, 후자를 공간 지역성이라고 한다.
메모리는 여러 단계로 나눠져 있다. 가격과 용량, 성능을 모두 고려하려면 빠르지만 비싼 메모리는 조금 사용하고 느리지만 싼 메모리는 많이 사용하는 것이 좋다. 따라서 메모리에는 계층 구조가 존재한다.
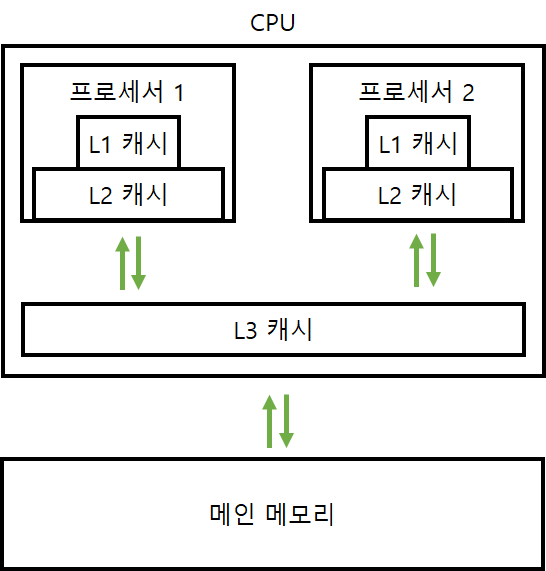
위 그림과 같이 멀티 프로세서는 각 프로세서마다 있는 캐시와, 프로세서끼리 공유하는 캐시가 있다. 병렬처리를 하다 보면 다른 프로세서가 처리한 데이터를 불러올 일이 생기는데 여기서 많은 오버헤드가 생긴다. 따라서 최대한 자기 프로세서 안에서 작업을 처리하고 꼭 필요할 때만 다른 프로세서와 데이터를 교환(communication)해야 병렬처리 성능을 높일 수 있다. 다른 프로세서와 데이터를 교환할 때마다 오버헤드가 발생하기 때문이다.
Load Balance
처리할 각 작업을 프로세서에게 효율적으로 할당하는 것을 의미한다. 프로그램 실행 도중 노는 프로세서가 없도록 해야 병렬처리의 성능이 높아지기 때문에 프로세서에게 작업을 적절하게 할당하는 것이 중요하다. 작업 할당 효율이 안 좋을수록 병렬처리 확장성이 낮아진다.
또한 작업 간 선후관계가 있을 수도 있으니(집을 만들 땐 벽을 쌓고 지붕을 올려야 함) 작업의 순서도 고려해야 한다.
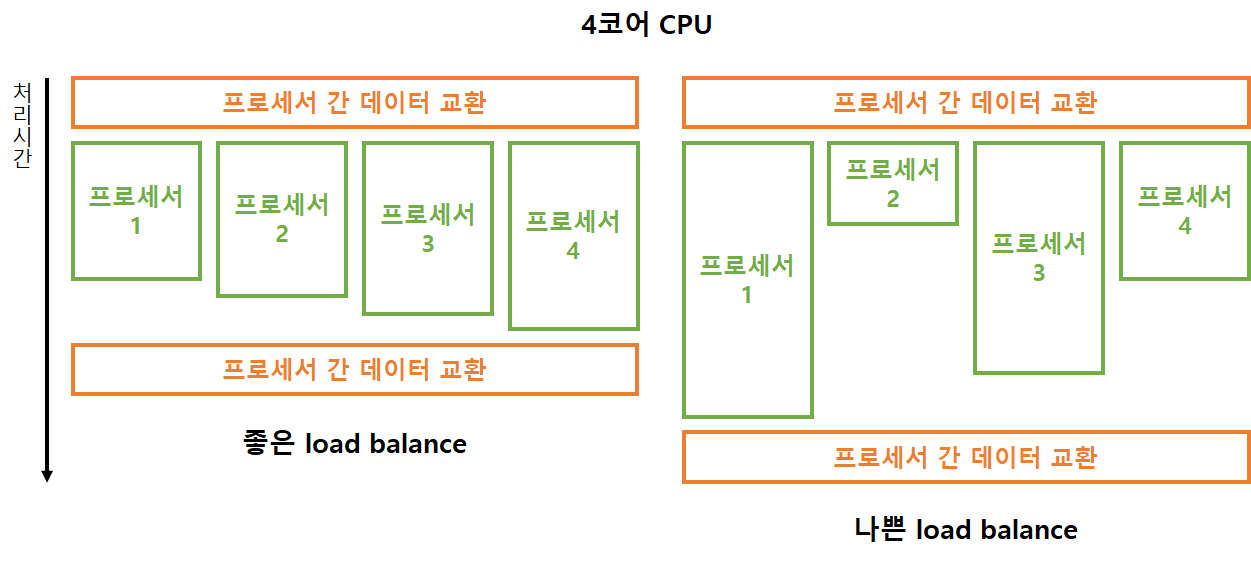
Static load balancing
정적 작업 할당이란 프로그램이 시작되기 전에 미리 작업의 양을 계획하고 각 프로세서에게 할당하는 것이다. 경우에 따라 작업을 다 끝내고 쉬고 있는 프로세서가 생길 수 있다. 이런 경우가 많아질 경우 병렬처리 성능이 떨어진다. 여기서 정적이란 프로그램이 시작되기 전(프로그래밍, 컴파일 시)을 의미한다. 아래와 같은 장단점이 있다.
장점
작업의 양과 처리 시간을 미리 정확하게 예측할 수 있을 때 최고의 병렬처리 효율을 낼 수 있다.
단점
그 예측이 어긋나면 놀고 있는 프로세서가 생길 수 있고, 이런 경우가 많아질수록 병렬처리 성능이 떨어진다. 그리고 각 프로세서의 성능이 다를 경우(e.g. ARM big.LITTLE) 프로그래밍 시점에서 각 작업이 어떤 프로세서에게 할당될지 알 수 없기 때문에(운영체제에 의해 자동으로 결정됨) 작업을 균형있게 할당하기 어려워진다.
Dynamic load balancing
동적 작업 할당이란 프로그렘이 시작된 후 작업을 유동적으로 프로세스에게 할당하는 것이다. 쉬고 있는 프로세서가 있으면 그 프로세서에게 우선적으로 작업을 할당한다. 여기서 '동적'이란 프로그램이 시작한 후(runtime, execution time)를 의미한다.
작업을 큐에 두고, 작업을 마친 프로세서는 작업 큐 또는 아주 바쁜 다른 프로세서로부터 작업을 받아온다.
장점
각 프로세서가 쉬고 있는 시간을 줄여 병렬처리 성능을 올릴 수 있다. 프로세서 성능이 다른 CPU 환경일 땐 동적 작업 할당을 사용하는 것이 좋다.
단점
단점은 쉬고 있는 프로세서를 찾는 과정, 얼만큼의 작업을 할당할지 결정하는 과정에서 약간의 오버헤드가 생긴다. 그리고 프로세서가 아주 많이 있을 때 하나의 작업 큐만 있다면 작업 큐가 병목이 될 수 있다.
Communication
비용
정보를 교환하면 작업 처리가 지연될 수 있다. 일반적으로 정보를 보낼 때 한번에 최대한 많이 보내야 latency가 낮아져 효율적인 정보 교환이 가능해진다.
latency
한 프로세서가 보낸 메시지가 다른 프로세서에게 도달하는데 걸리는 시간이다. 엄밀히 말하면 0 byte의 메시지를 보내는데 걸리는 시간이다.
bandwidth
시간당 전송할 수 있는 데이터의 양을 말한다.
종류
-
broadcast: 한 프로세서가 모든 프로세서에게 데이터를 보내는 방식 -
reduce: 한 프로세서가 모든 프로세서로부터 데이터를 받는 방식 -
scatter: 한 프로세서가 몇 개의 프로세서에게 데이터를 보내는 방식 -
gather: 한 프로세서가 몇 개의 프로세서로부터 데이터를 받는 방식 -
point to point: 한 프로세서가 다른 한 프로세서와 데이터를 주고 받는 방식 -
all to all: 모든 프로세서끼리 데이터를 주고 받는 방식
MPI
Message Passing Interface.
reduce
모든 프로세서로부터 데이터를 종합해서 하나의 프로세서에게 반환한다. MPI_REDUCE를 사용히고, 이 함수는 모든 프로세서가 데이터를 보내야 함수가 반환된다. reduce 작업은 여러 작업이 가능하며, add를 사용해 적분을 병렬처리할 수도 있다. 또는 MPI_REDUCE를 사용해 알고리즘의 복잡도를 줄일 수도 있다.
synchronous
메시지를 보내고 수신지로부터 응답이 올 때까지 기다리는 형태다.
asynchronous
메시지를 보냄. 끝.
