
Introduction & Word Vectors
CS224N Review
https://youtu.be/rmVRLeJRkl4?si=xuPoE4f5k5XoO2XA
1. The course
이 강의의 3가지 목표
1. NLP의 최신 딥러닝 방법 알아보기
2. 인간의 언어에 대한 big picture 이해하기 + 인간이 쉽게 언어를 이해하는 것 처럼 보이지만, 실제로 이해하기 어려운 이유 알아보기
3. pytorch에서 NLP 구축해보기
2. Human language and word meaning
Q. 어떻게 컴퓨터가 인간의 언어로 전달되는 정보를 이해할 수 있게 만드는가 ?
Definition: meaning
- the idea that is represented by a word, phrase, etc.(단어나 구절로 표현되는 것)
- the idea that a person wants to express by using words, signs, etc.(사람들이 단어나 신호를 통해 표현하고 싶은 것)
- the idea that is expressed in a wor of writing, art, etc.(글쓰기, 예술 같은 것들로 표현되는 것)
사전적으로 "meaning(의미)"란 ? 위와 같이 단어나 어떤 것들로 표현을 통해 전달하고자 하는 idea를 의미한다.
Commonest linguistic way of thinking of meaning:
signifier(symbol) <=> signified(idea or thing)
사람들은 idea를 표현할 때 symbol로 표현한다. 즉, symbol을 통해서 그 속의 idea를 이해한다. 이것을 denotational semantics(표시적 의미)라고도 말한다.
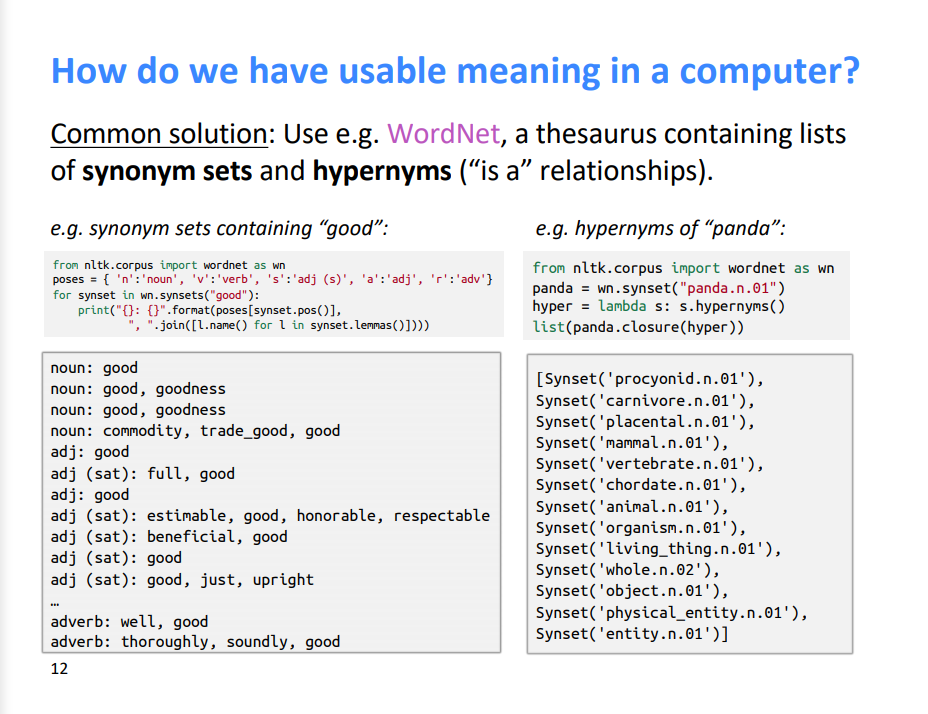
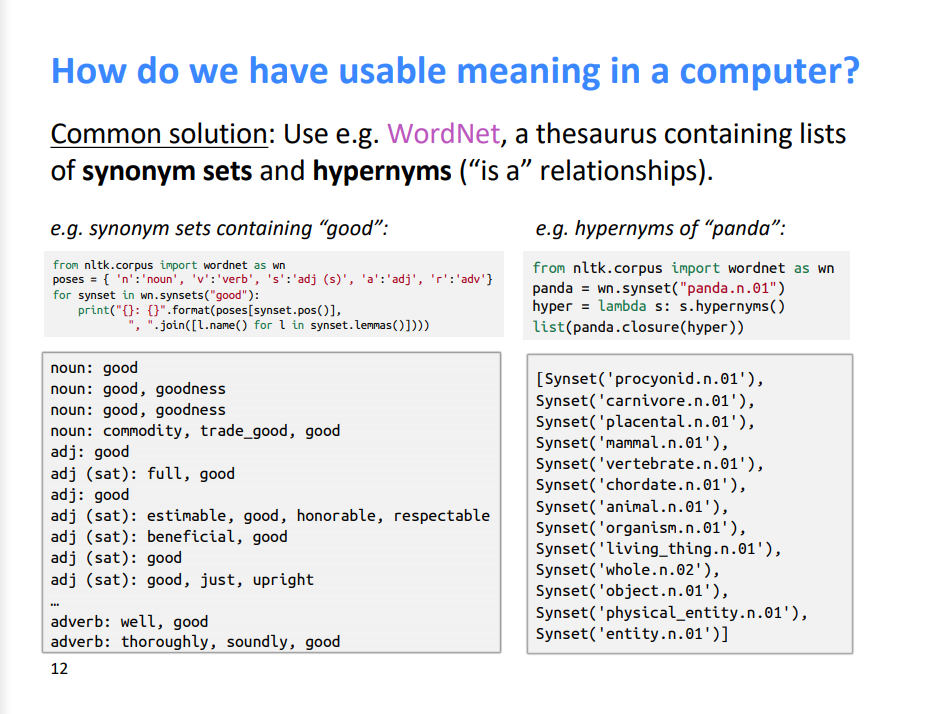
컴퓨터가 의미를 인식할 때 WordNet을 사용한다. WordNet은 해당 단어의 동일한 의미를 가질 수 있는 동의어 단어 세트와 상위어 세트로 구성되어 있다.
그래서 WordNet에서는 "proficient"와 "good"이 뉘앙스는 달라도 동의어로 나열된다.
또한, 최신 용어를 포함하여 존재하지 않는 단어가 존재한다. 이러한 용어들을 계속 업데이트 하는 것은 현실적으로 불가능하다.

전통적인 NLP에서 단어들은 localist한 vector representation으로 정의된다. (one-hot vector)
그래서 vocabulary의 크기는 50만개.. 그 이상이 된다.

"Seattle motel", "Seattle hotel"이 비슷한 의미를 갖고 있어도 개별 단어로 간주가 된다.(orthogonal하다. = 두 특성이 독립된다) 그래서 단어 사이의 관계 및 유사성을 갖지 못 한다.

Distributional semantics(분포 의미론)이란 ? 한 단어의 의미는 가까이에 자주 나타나는 단어에 의해 부여된다는 개념을 갖고 있다.
w 라는 단어가 텍스트에 등장할 때, 그 문맥은 근처에 나타나는 단어 집합을 의미한다. 그래서 여러 맥락을 활용해서 단어 w의 representation을 구축할 수 있다.
그래서 단어의 표현이 여러 차원에 걸쳐서 퍼져 있기 때문에, 이러한 표현은 localist한 표현이 아니라 distributed 표현이라 할 수 있다.

실제로 벡터 표현을 시각화 해봤을 때도, 비슷한 단어들 끼리 뭉쳐있는 것을 볼 수 있다.
3. Word2vec introduction
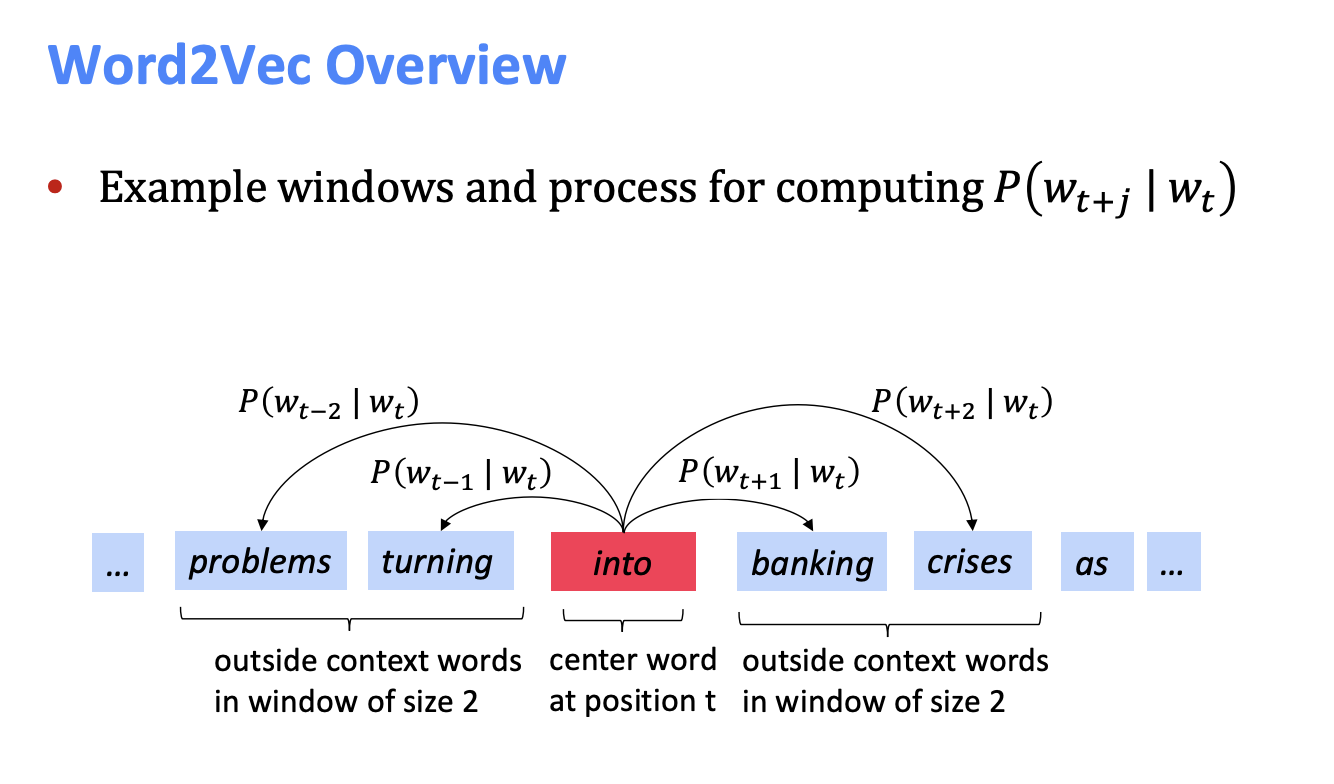
Word2vec
아이디어 : 고정적인 크기의 문맥에서 주변 단어들을 보고 특정 단어를 맞춘다.
모델은 학습이 되면서 특정 단어를 맞추기 위해 확률을 최대화한 벡터 조정을 수행한다.
4. Word2vec objective function gradients
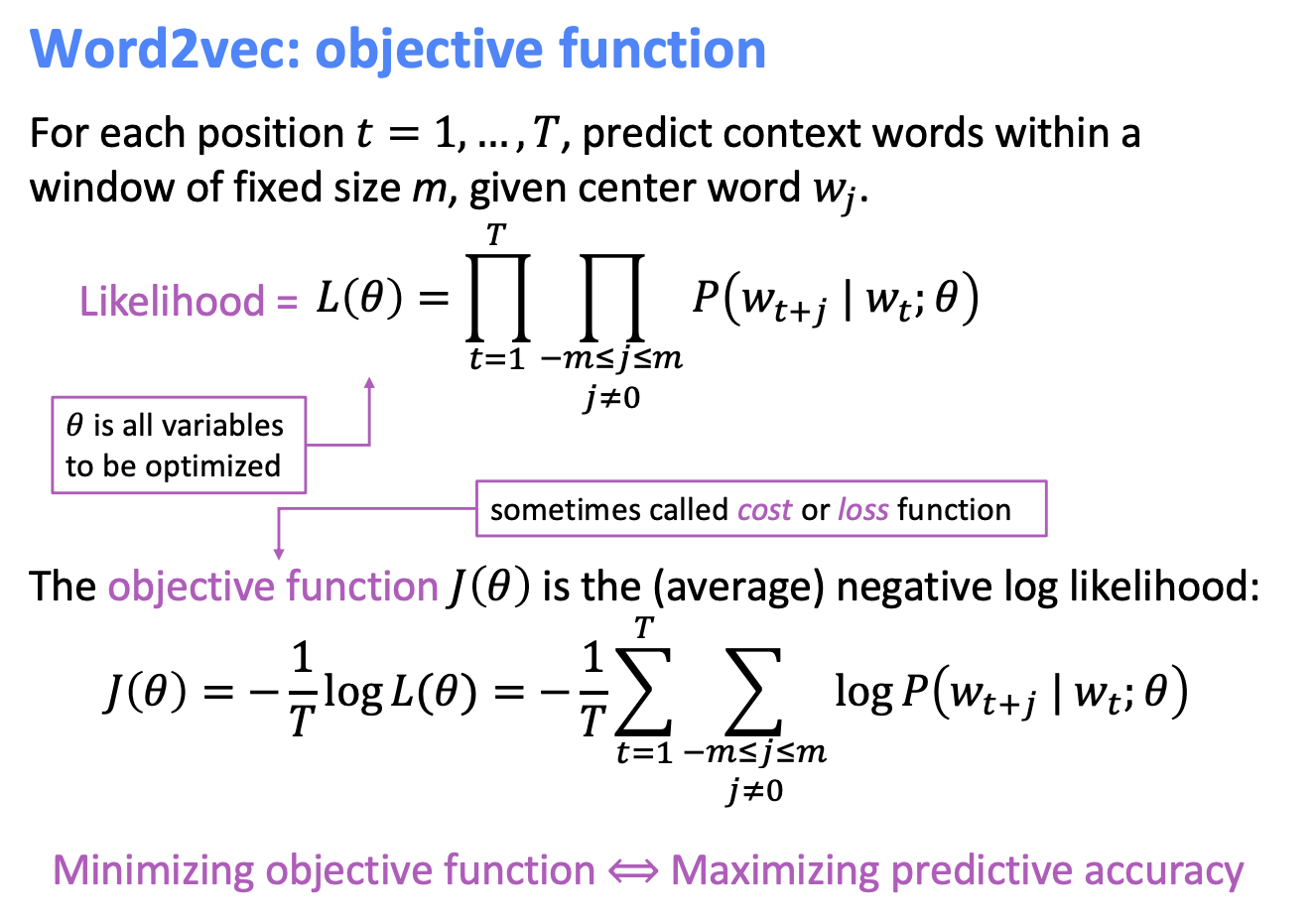

중심 단어(c)가 주어졌을 때, 주변단어(O)가 나타날 확률을 최대로 하는 function을 수행한다.
objective function엔 -(마이너스)를 붙여 최소화 하는 학습을 수행한다.
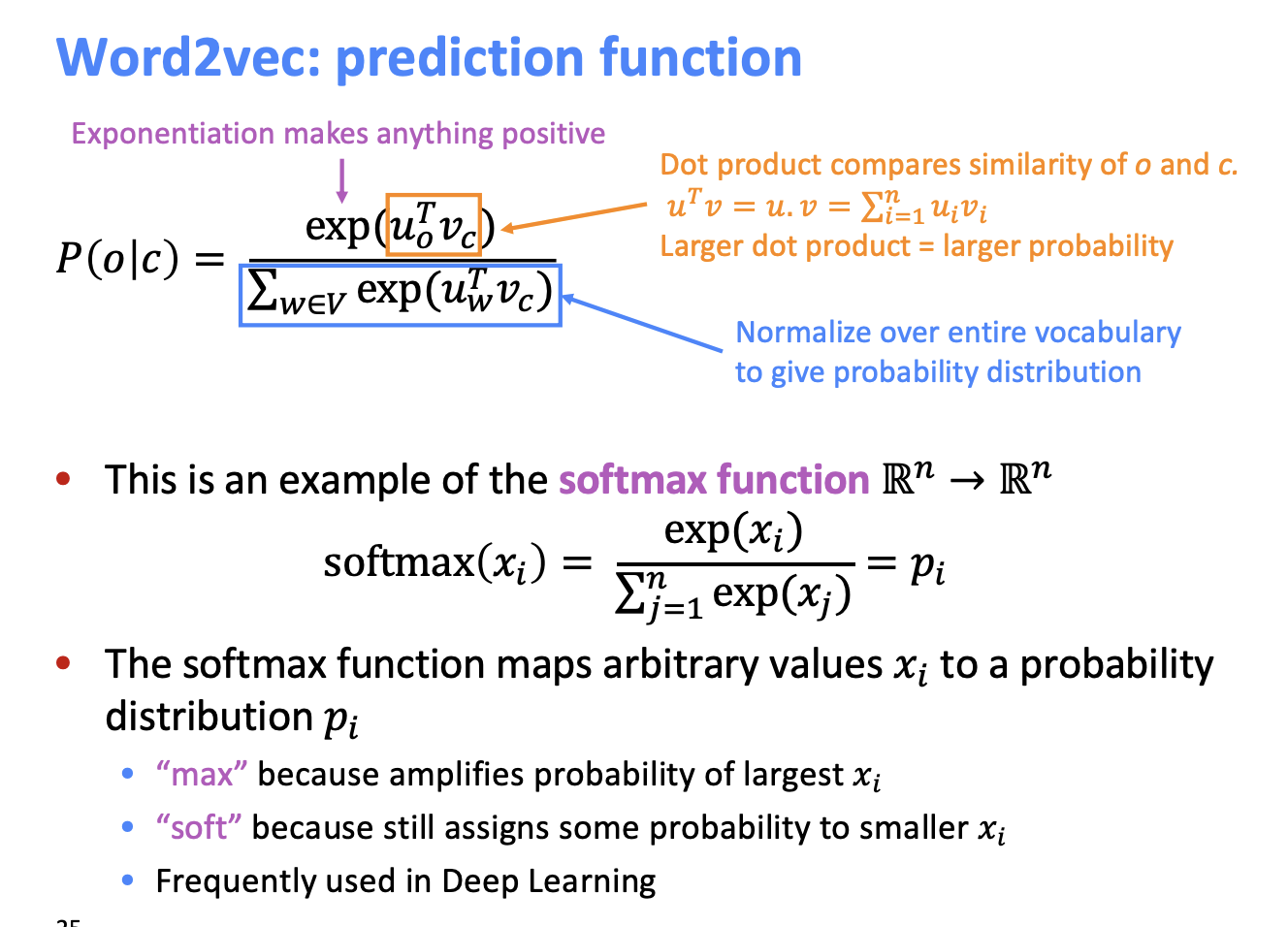
벡터 사이의 유사성을 측정하는 자연스러운 방법은 2가지 벡터를 내적하는 방법이다.
따라서, 두 가지 단어를 내적을 취해서 내적이 크면 두 단어가 비슷하다고 볼 수 있다.
추가로, 확률 분포를 취해준다. softmax를 통해서 0~1 사이의 값으로 변환시켜준다.
이러한 objective function을 사용하여 도함수를 계산하고 그레디언트가 어디에 있는지 계산할 수 있다.
5. Optimization basics
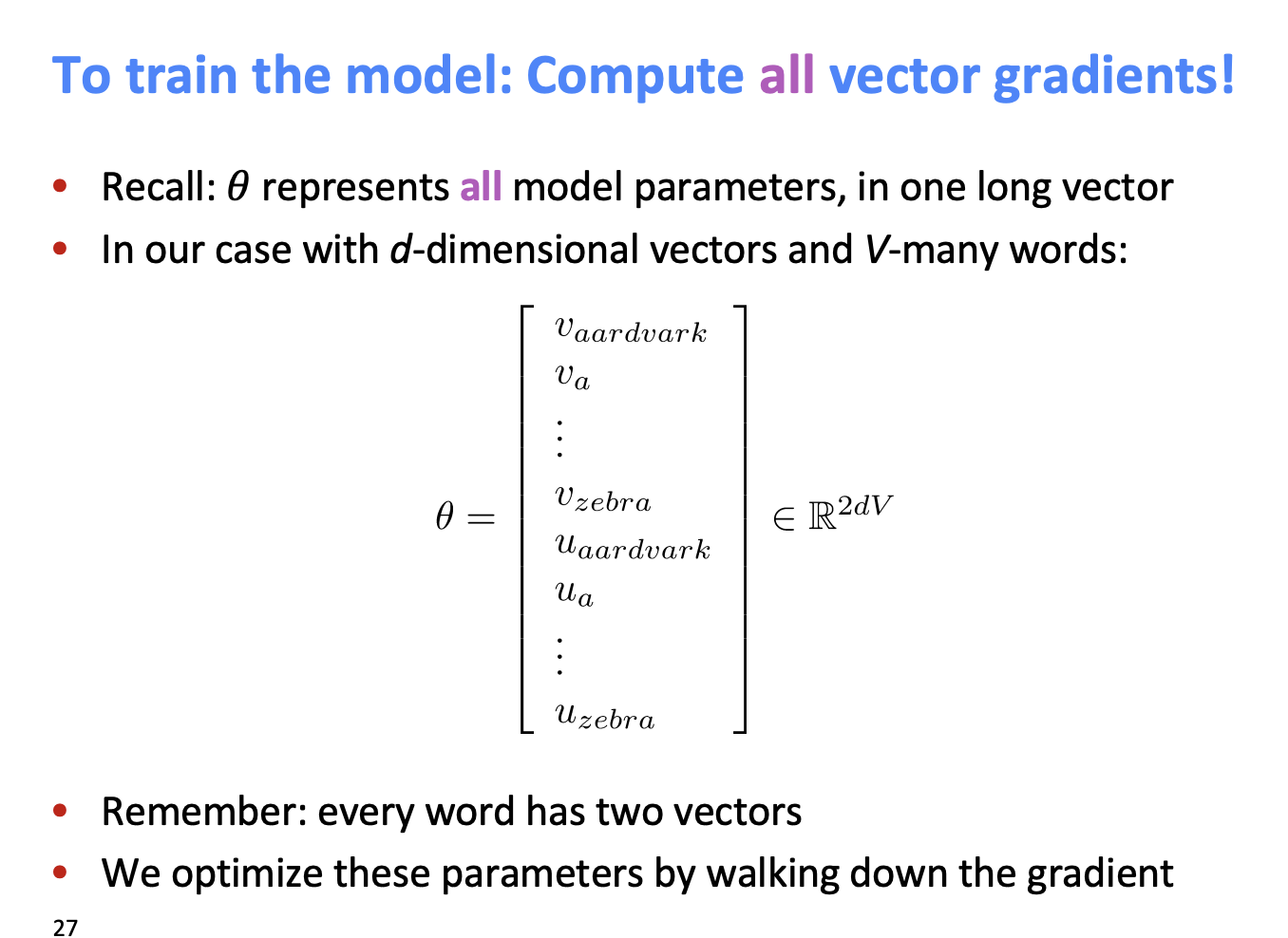
그렇다면, 이 목적함수를 사용하여 loss를 최소화 하는 방법은 무엇일까 ?
모든 vector gradient를 계산하면 된다.

기댓값과 실제 값 사이의 차이를 계산하여 학습에 반영한다.
6. Q&A
- 단어가 두 가지 다른 의미가 여러가지 다른 의미를 갖고 있다면, 그것을 여전히 동일한 단어의 벡터로 나타낼 수 있는가 ?
=> 다음 수업에서 설명, 하지만, 보통은 이렇게만 해도 잘 작동이 되는 것으로 나타남. - 반의어의 문맥들이 비슷한 경우가 있을 것 같은데, 그러면 반의어 의미 단어가 서로 가깝다는 것이 아닌가 ?
- 반의어는 일반적으로 매우 유사한 주제에서 발생하기 때문에, 실제로 동일한 맥락에서 반의어가 발생함. 그래서 그들의 벡터는 매우 유사하다 !
- 학습시킬때 벡터 초기화 어떻게 하는지 ?
- 학습시킬때 초기화는 무작위 작은 벡터로 수행하면 됨.
기타
- 교수님 검색해보니 Glove 개발자였다,,, 진짜 신기하군
