Introduction & Word Vectors
CS224N Review
https://youtu.be/gqaHkPEZAew?si=Q9z7BKPoplxV0Oux
1. 강의 목표
- 단어의 vector embedding에 대해 이해하기
2. Word2vec Review
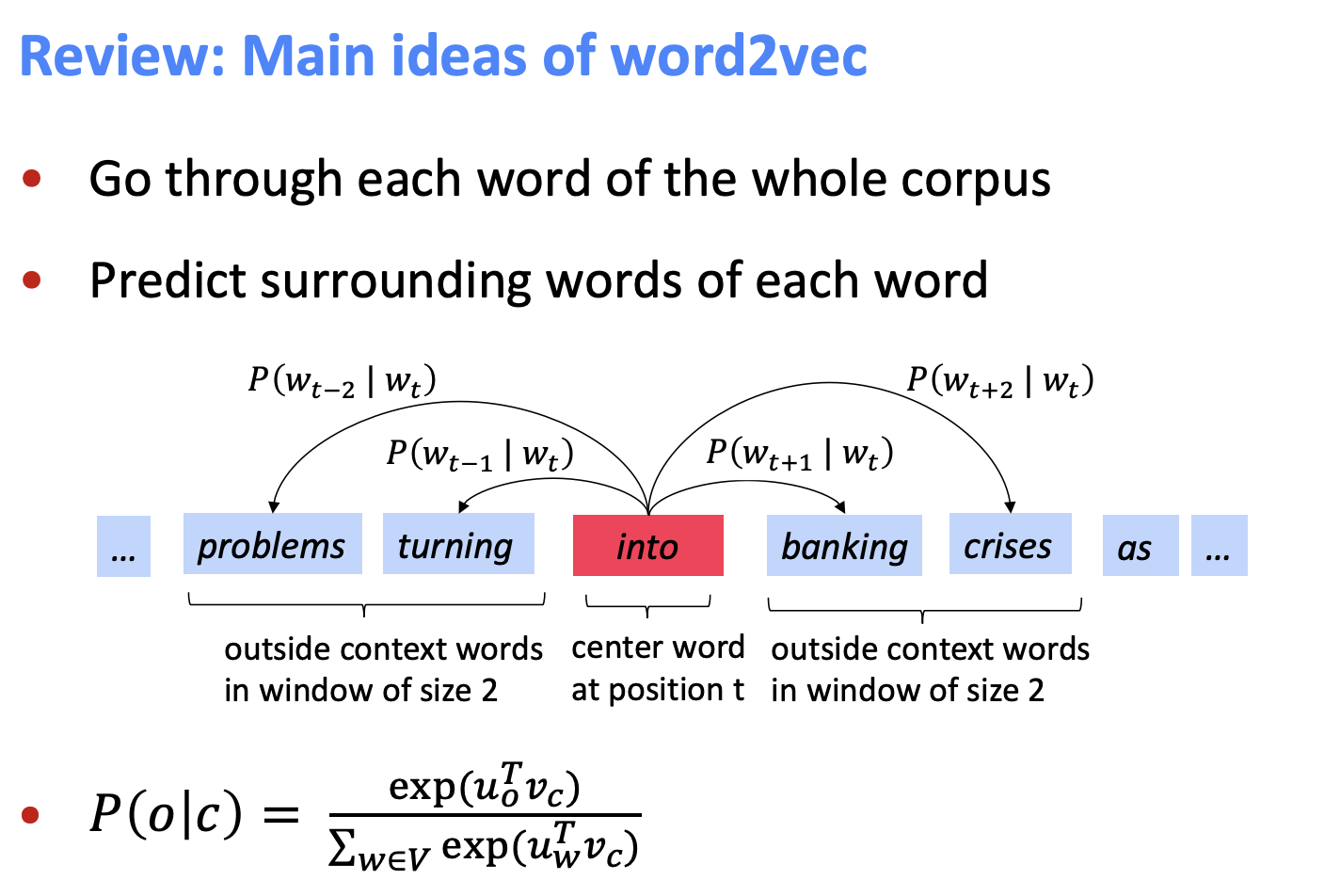
-
각 위치에 대해 어떤 단어가 있는지 예측하며 학습한다.
-
중심 단어에 대한 단어 벡터 & 문맥 단어들과의 내적을 통해 정의된 확률 분포를 사용한다.
-> 내적을 통한 scoring + softmax 함수를 통한 확률 분포 정의 가능 -
이런 간단한 알고리즘을 통해 단어 유사성 및 의미 있는 방향을 잘 포착하는 단어 벡터를 학습할 수 있다.
-
Bag of word의 단점
- 단어의 순서나 위치를 고려하지 않는 모델이다. (위치에 상관없이 단어의 확률 추정치는 동일)- crude model(조잡한 모델)
- BoW 사전에 없는 새로운 단어에 대해서는 확률을 부여하지 못한다.
3. Optimization: Gradient Descent
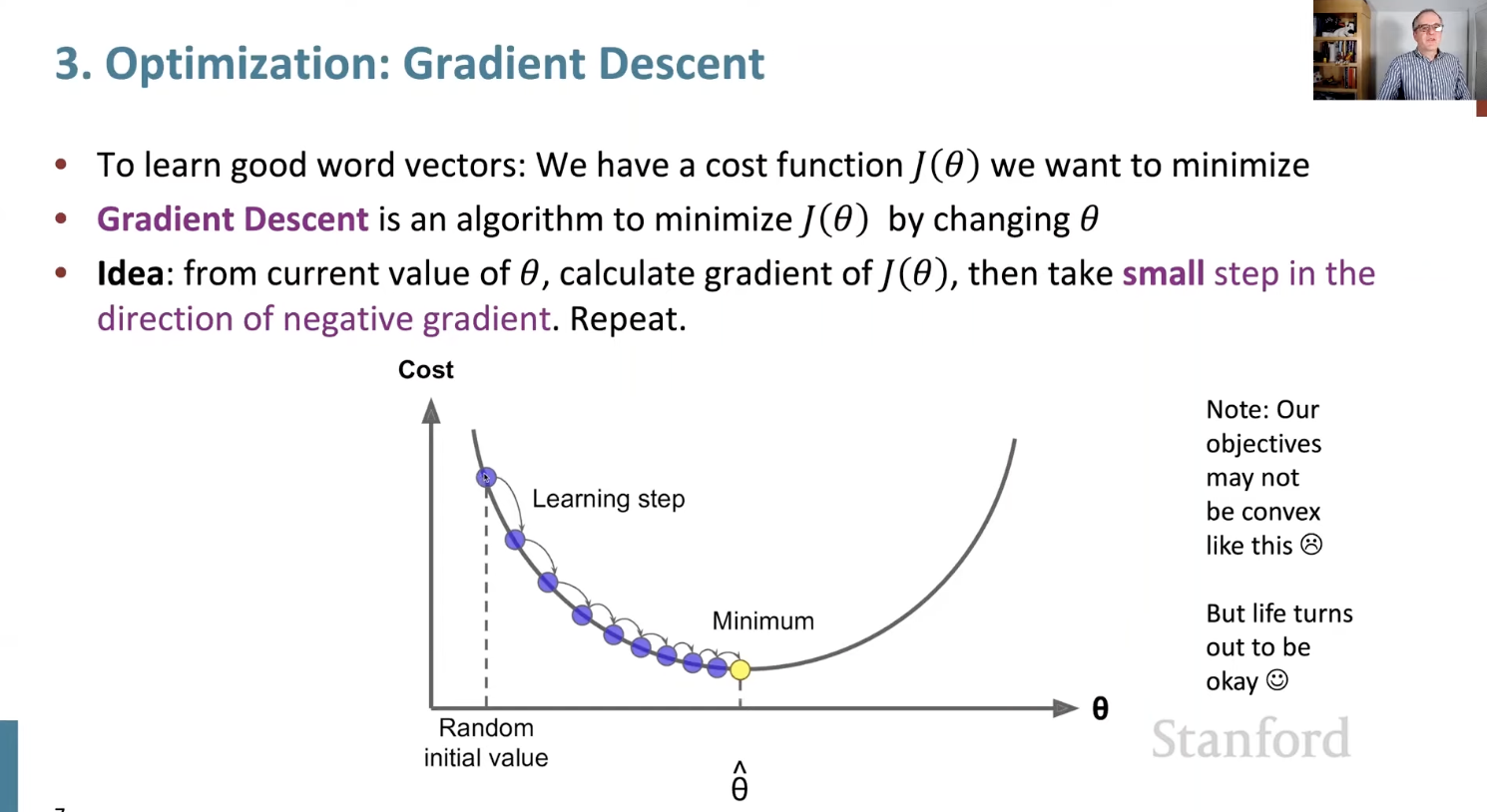
- 세타의 현재 값에서 세타의 기울기 j를 계산하는 것 -> 이를 통해 음의 기울기 방향으로 loss를 최소화 시킬 수 있다.
- step size가 작으면 시간이 오래 걸리고 낭비되는 계산이 많아진다.
- 반대로, step size가 크면 발산할 수 있으며 수렴이 어려울 수 있다.
- 하지만, 실제로 신경망은 non-convex하다. (이를 다루는 방법은 다음 강의 시간에 다룸)

간단한 Gradient Descent(GD)
- 파라미터는 벡터를 의미한다.
- 해당 파라미터에 대한 손실함수(J)의 편도함수를 계산하여 업데이트를 수행한다.
- 문제 : 손실함수가 전체 corpus의 모든 window에 대한 함수이다.(모든 중심 단어에 대해 손실함수를 계산한다)
-> 그러면, 손실함수를 구할때 전체 corpus를 반복해야 하므로, 수십억개의 corpus에 대해서는 손실함수를 계산하는 것이 비용이 어마무시하게 든다.... 최적화도 극도로 느리다. - 그래서, 아무도 사용하지 않는다 ! ㅎㅎ
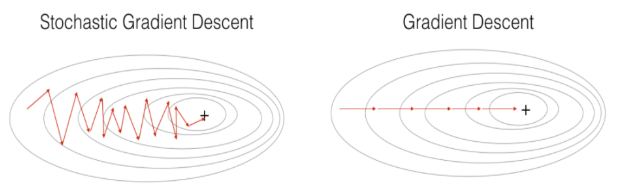
Stochastic Gradient Descent(SGD)
- 많은 계산량을 필요로 하는 경사하강법을 보완하기 위해 SGD를 사용한다.
- SGD는 손실함수(J)를 계산할 때, 전체 데이터 대신 일부의 데이터에 대해서만 손실함수를 계산한다.
- 계산량이 적고, 학습이 빠르다.
- local minimum에 빠지지 않을 수 있다. 하지만, 성능이 좋지 못 하다.
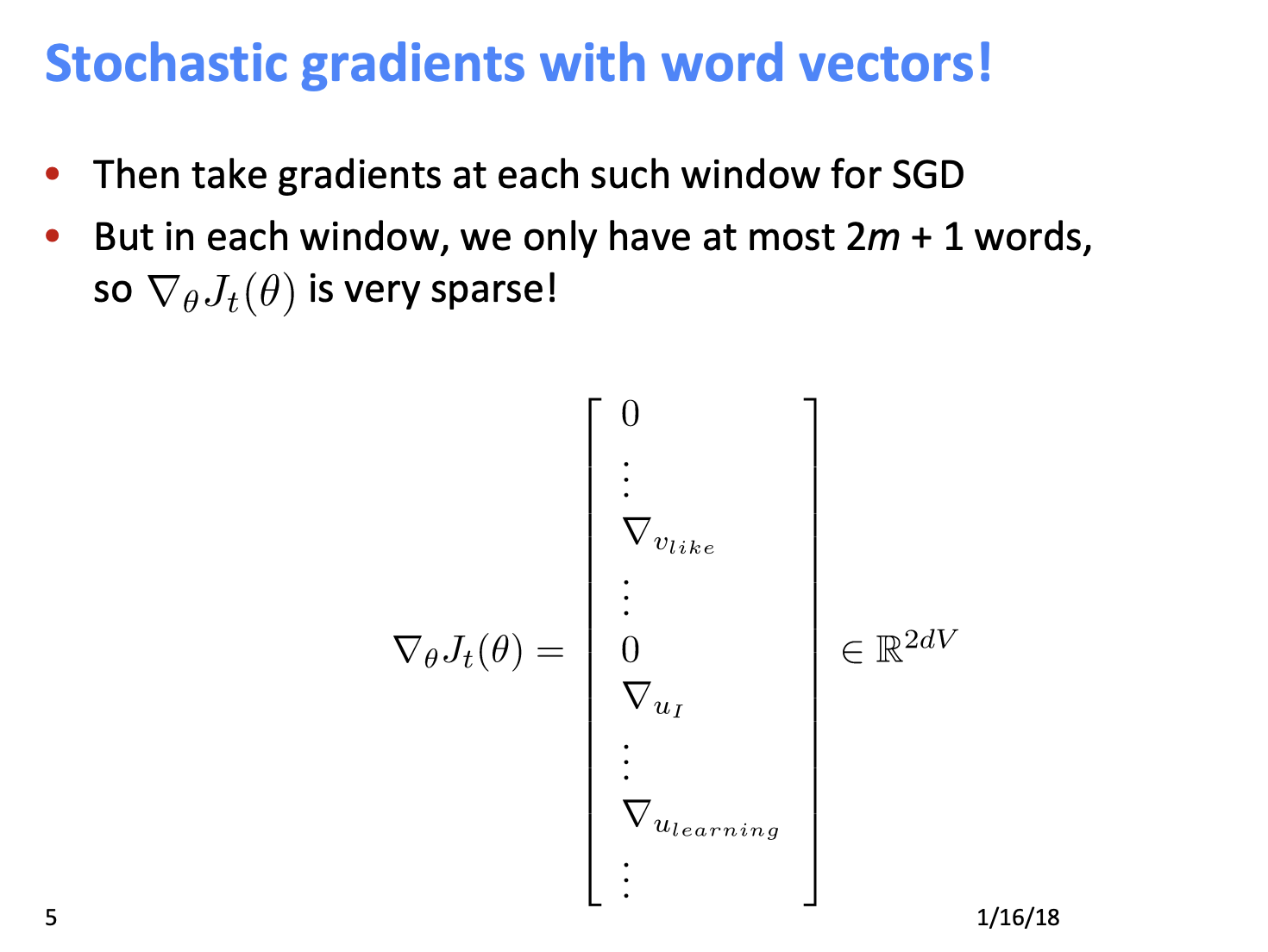

- 하나의 window로 SGD를 수행하는 경우, 실제로 window에서는 거의 파라미터를 볼 수가 없다. (sparse 하다!)
- 예를 들어 5개 단어 정도의 window를 가진 경우는 최대 11개의 고유한 단어 유형들만 사용된다.
- 그래서 우리는 11개 단어에 대한 gradient를 갖게 되고 나머지 10,000개에 대해서는 gradient 정보가 없다.
=> "몇 단어에 대한 파라미터만 업데이트 할 수는 없을까..?" => Negative Sampling !

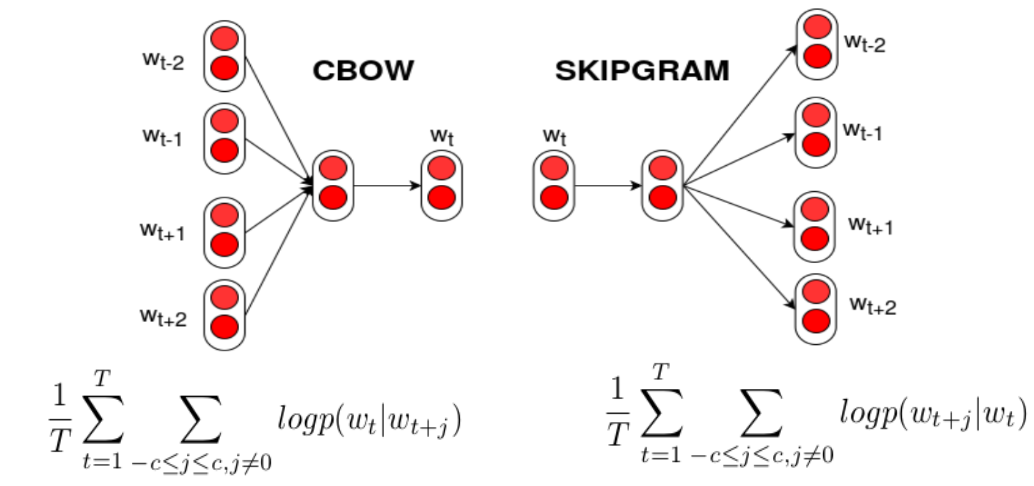
- 2013년 Mikolov 논문에서 word2vec을 소개할때 여러 알고리즘을 소개했다.
- Skip-gram
-> 중간 단어를 보고 주위 context 단어들을 예측하는 방식 - Continuous Bag of Words(CBOW)
-> context 단어들을 통해 중간 단어를 예측하는 방식


Negative Sampling(SGNS)
- 학습을 진행할때 지금까지 설명한 모든 방식은 단순하지만 상대적으로 계산 비용이 많이 드는 naive softmax 방법이었다. (비효율적)
- softmax를 통해 확률값을 구할 때 Dictionary에 있는 모든 단어들에 대한 확률값을 구해야 했기 때문이다. (만약 10만개 voca가 있으면, softmax의 분모를 계산하려면 10만번의 내적이 필요..)
- 그래서, softmax를 사용할 때 전체 단어를 대상으로 구하지 않고 무작위로 일부 단어만 뽑아서 활용하는 방식을 Negative Sampling이라 한다.
Negative Sampling의 과정
1. 단어 쌍 생성: 먼저 주어진 문맥 내의 실제 단어 쌍(양성 샘플)을 생성한다.
2. 음성 샘플 생성: 문맥에 존재하지 않는 단어들을 무작위로 선택하여 음성 샘플을 생성한다. 이때, 음성 샘플의 개수는 일반적으로 양성 샘플 개수보다 훨씬 많다.
3. 라벨링 : 양성 샘플은 1로 라벨링, 음성 샘플은 0으로 라벨링하여
3. 손실 계산: 양성 샘플에 대해서는 높은 점수를, 음성 샘플에 대해서는 낮은 점수를 주는 방향으로 손실 함수를 최적화한다.
4. 모델 업데이트: 손실 함수를 기반으로 모델의 가중치를 업데이트한다.
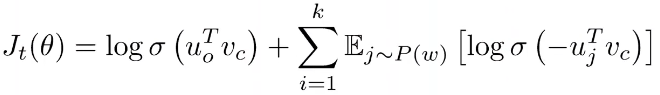
- 여기서 왼쪽 log는 양성 샘플의 loss를 의미, 오른쪽은 음성 샘플의 loss를 의미한다.
- 그래서 왼쪽 log항에서는 중심 단어 𝑤와 실제 문맥 단어 𝑐가 함께 나타날 확률을 최대화하고, 오른쪽에서는 네거티브 샘플 𝑤𝑖가 중심 단어 𝑤와 함께 나타나지 않을 확률을 최대화한다.
- 이를 통해 중심 단어와 실제 문맥 단어의 내적을 크게 만들고, 중심 단어와 무작위로 선택된 음성 샘플들의 내적을 작게 만들어 모델을 학습시킬 수 있다.
window based co-occurrence matrix
[example]
I like deep learning
I like NLP
I enjoy flying
에 대한 window 크기가 1일때의 co-occurrence matrix는 다음과 같다.
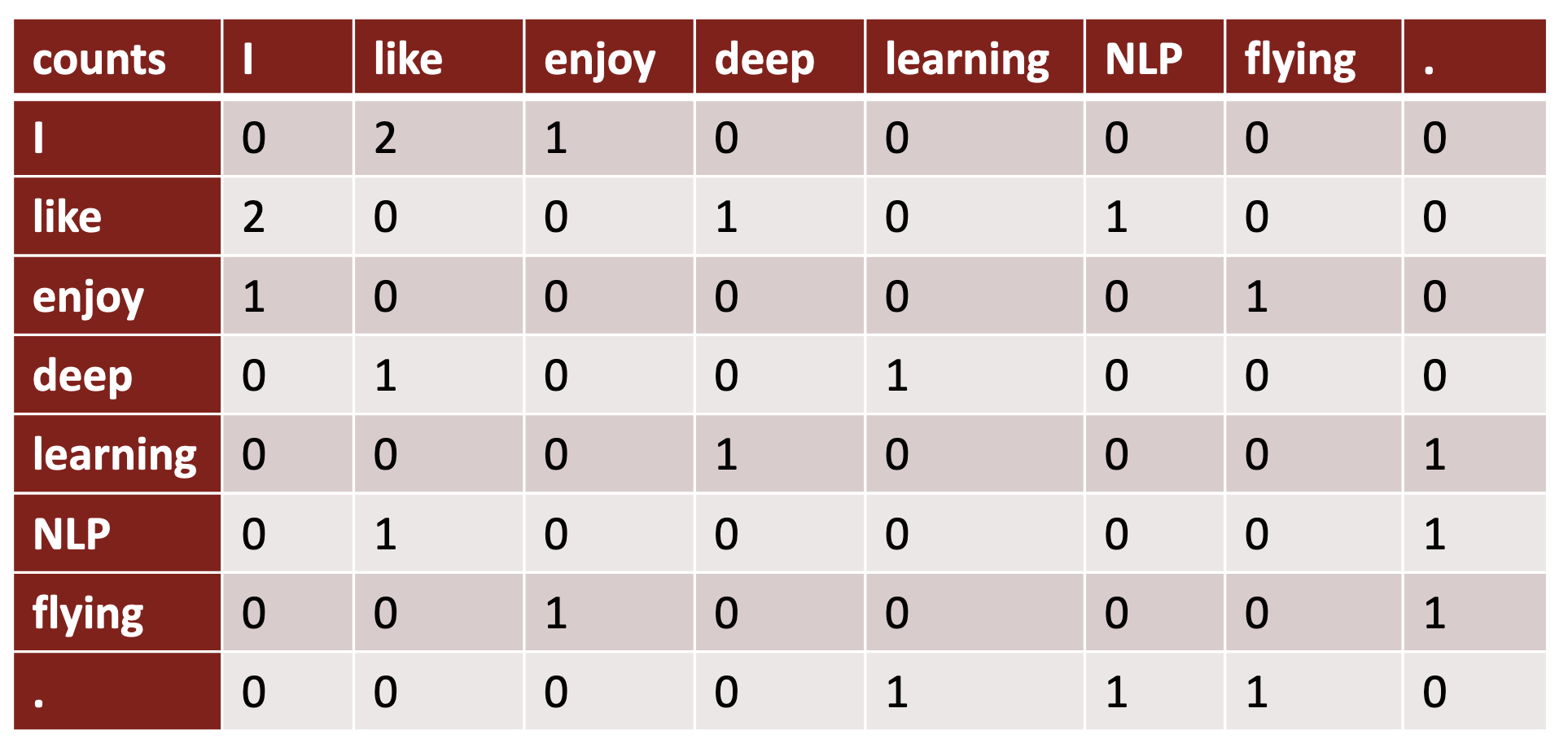
-> 단어가 유사한 의미와 사용법을 갖는 한, 그 단어가 어느 정도 유사한 벡터를 가질 것이라는 것을 확인할 수 있다. ex) 주어로서 "I"와 "You"가 비슷한 벡터를 가질 것이다.

하지만, 여러가지 문제가 존재한다.
1. 규모가 크지만, Sparse하다.
2. 차원이 높다.

idea : 중요한 정보들을 저차원에 저장한다 ! (dense하게 만들기)
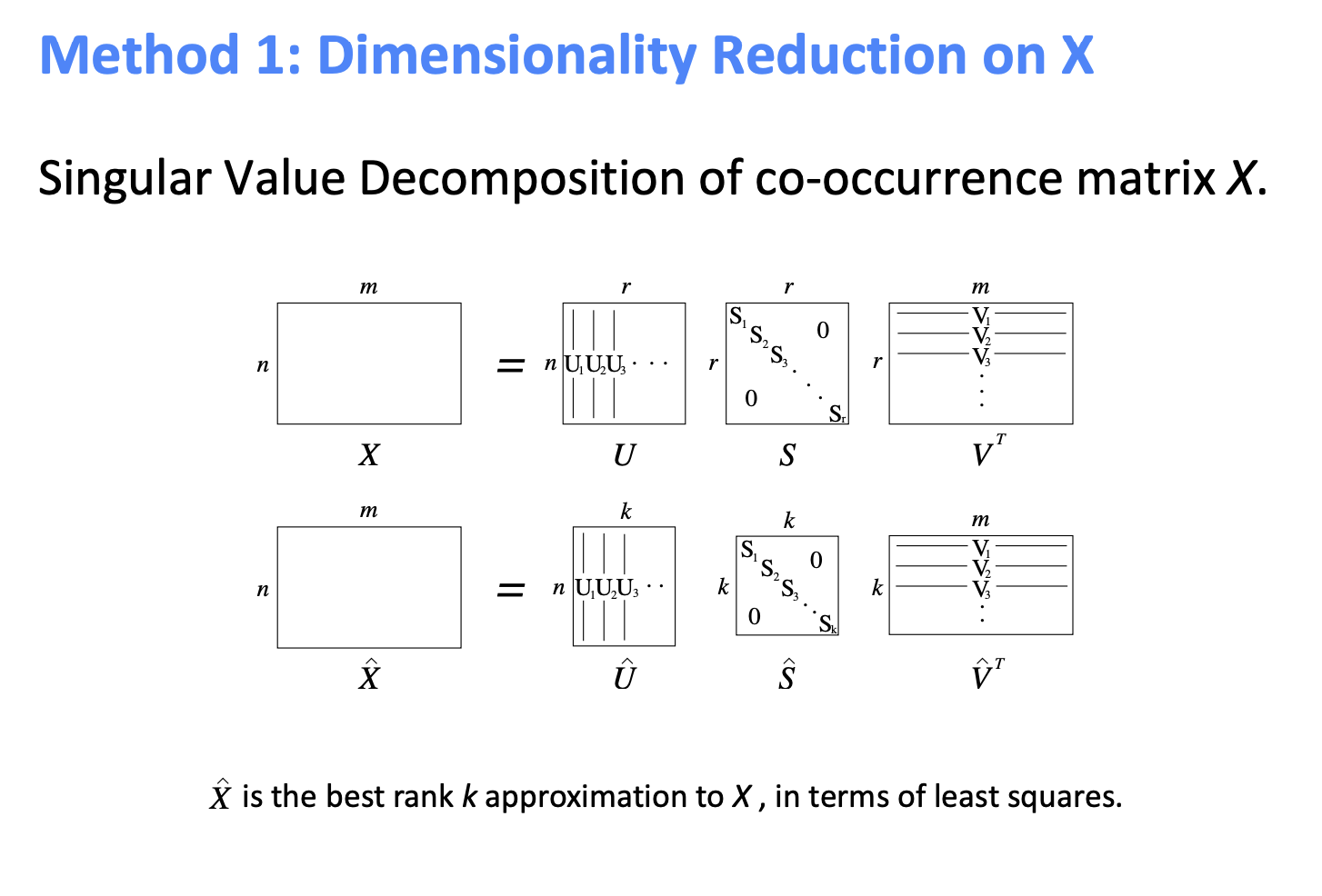
singular value decomposition(SVD)
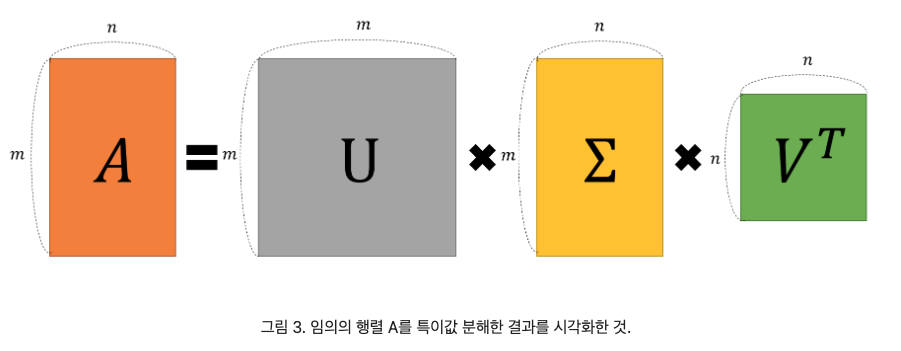
- 저차원으로 만드는 방법..
- 선형대수학을 활용해서 큰 행렬 x를 3개의 행렬들로 분해하여 차원을 줄일 수 있다.
- 시그마의 노란색 부분은 빈 공간이기 때문에 무시된다.
- V의 노란색 부분도 무시된다. => 그래서 행렬의 많은 부분을 삭제할 수 있다 !
- 수식적인 자세한 설명은 여기 참고
- 하지만, 일반적인 SVD는 잘 동작하기 않기 때문에 scaling을 활용해준다. 'the','he','has'와 같은 경우는 중요성에 비해 많은 빈도로 출현하게 되는데, 이러한 것들의 영향을 줄이기 위해 log를 취해주거나 count의 max값을 정해주거나 단어를 버릴 수도 있다.
-> 실제로 이런 것들을 적용한 SVD를 COALS라는 이름의 모델로 발표하기도 했다.
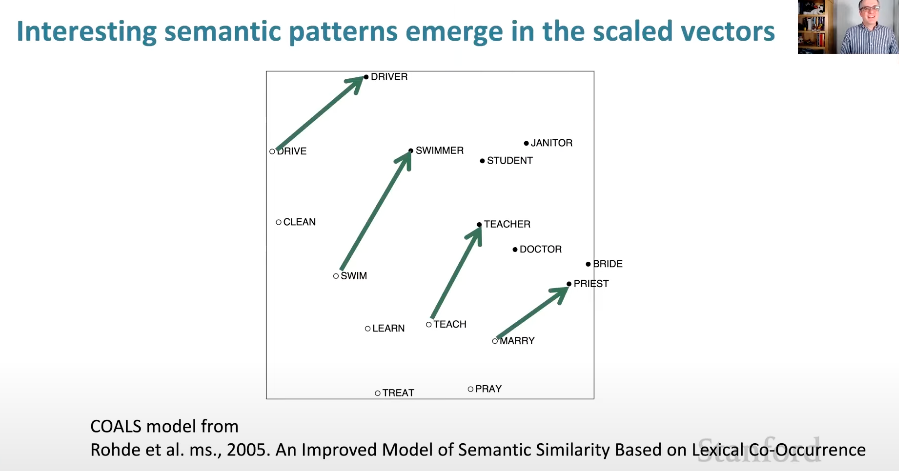
- 실제로 COALS 모델을 적용한 word vector를 보면, 비슷한 linear components를 가진다. (의미 구성 요소가 선형적으로 관측된다.)
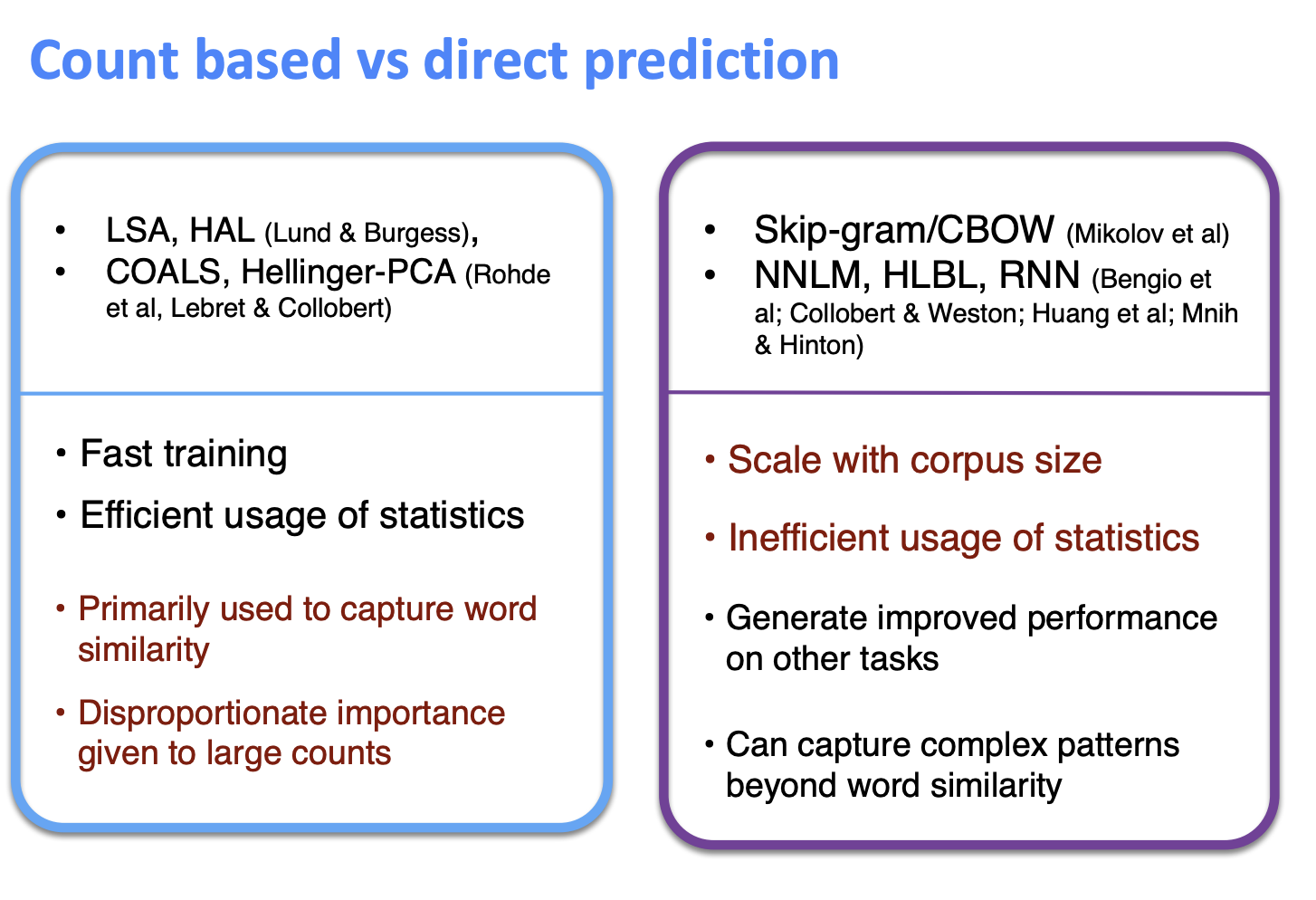
- count based Method는 많은 수의 불균형이 존재해서 성능이 좋지 않았다.
- 신경망 모델의 경우 gradient를 업데이트 하는 과정에서 co-occurence matrix를 비효율적으로 사용한다, 하지만 큰 corpus로 확장하는 것이 더 쉽고 더 복잡한 패턴의 학습을 가능하게 했다.

Glove
- 의미 구성 요소에 대한 속성을 얻기 위해서 동시 발생 확률의 비율로 표현되어야 한다.
- 그저 count하는 것이 아니라, global한 co-occurence를 활용하여 단어 벡터를 학습하여, 국소적 정보의 한계를 극복하고, sparse한 데이터의 문제를 완하하며, 의미적 유사성을 더 잘 반영할 수 있었다.

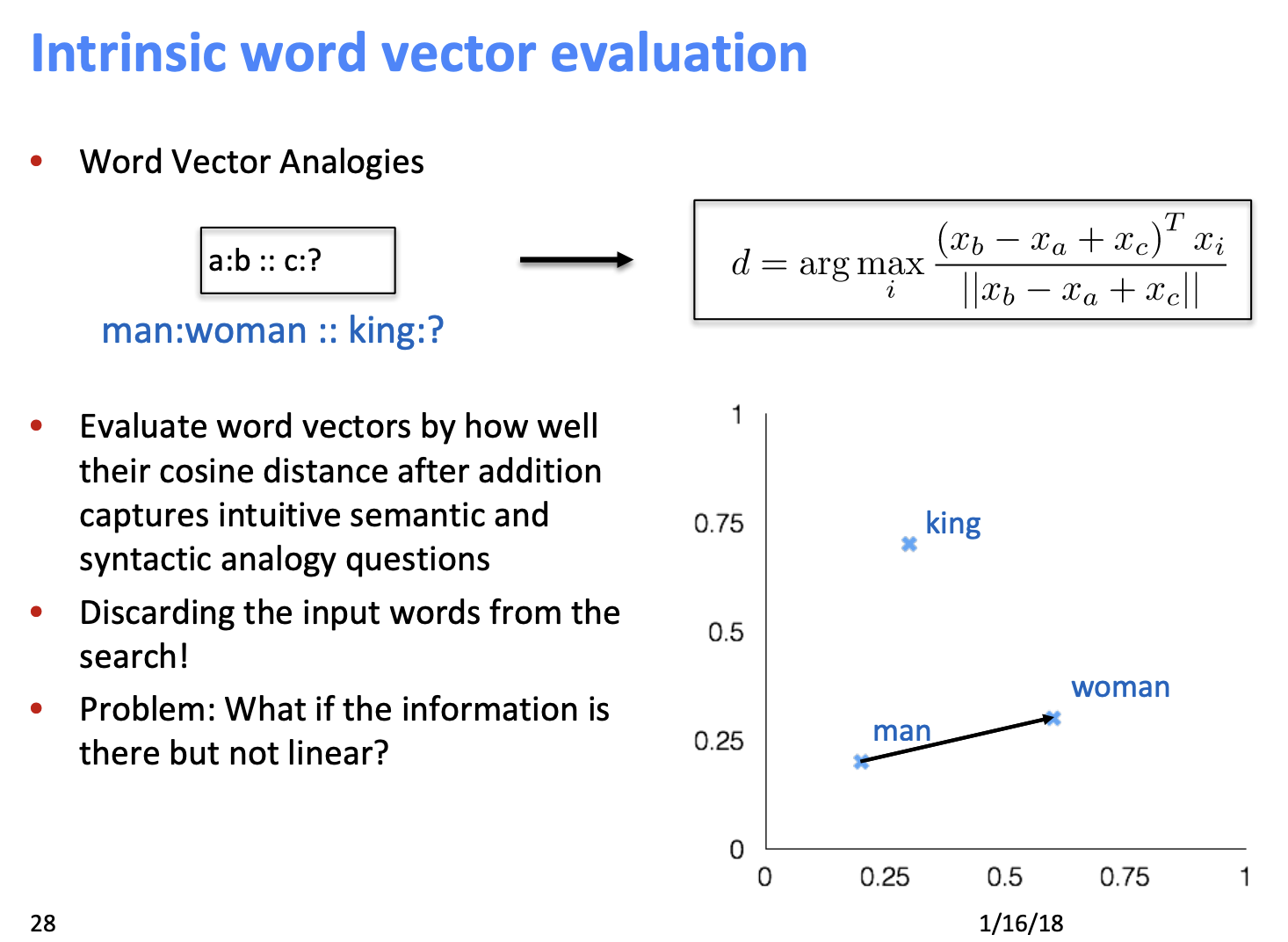
- 단어 벡터 공간에서 선형 의미 components를 어떻게 더하고 뺄 수 있는 것일까 ? (king - man + woman = queen 이게 어떻게 가능할까?)
[다른 블로그 글 참고]
우리는 앞서 word embedding을 학습시킬 때, 중심단어 C와 주변단어들 O를 활용했다. king의 주변어 royal, family, emperor 등이 예상되고 이런 단어는 마찬가지로 queen의 주변단어로 자주 등장할 것이다. 하지만 king과 queen을 구분할 수 있는 주변단어 O가 몇가지 있을 수 있는데, 아마 다음과 같은 문장들로부터 파생 될것이다. "the king was a man", "the queen was a woman" 또한 king은 man과 가까운 단어 he랑도 자주 등잘할 것이다. "he will be a man", "he will be a king", "he will be a uncle" 이처럼 중심어 king은 man, he, uncle과 문법적 그리고 의미적으로 woman, she보다 주변 단어 O가 비슷하다는 이야기이다. (물론 "she is the wife of the king"과 같은 문장이 나올 수 있으나 상대적으로 생각해야 한다.) 결과적으로, word embedding은 위에서 설명한 의미적 문법적 정보를 단어의 동반출현 빈도를 통해 상대적으로 학습한다. 아래 그림에 나오는 "royalty"와 같은 class정보는 이러한 단어의 동반 출현빈도에 따라 자동을 구분된 것이다.
출처: https://eda-ai-lab.tistory.com/122 [TEAM EDA:티스토리]

그 결과 "frog"의 가장 가까운 단어들을 검색해보았을 때, 실제로도 다음과 같은 결과를 낼 수 있었다.

- word vector를 어떻게 평가할지 ?
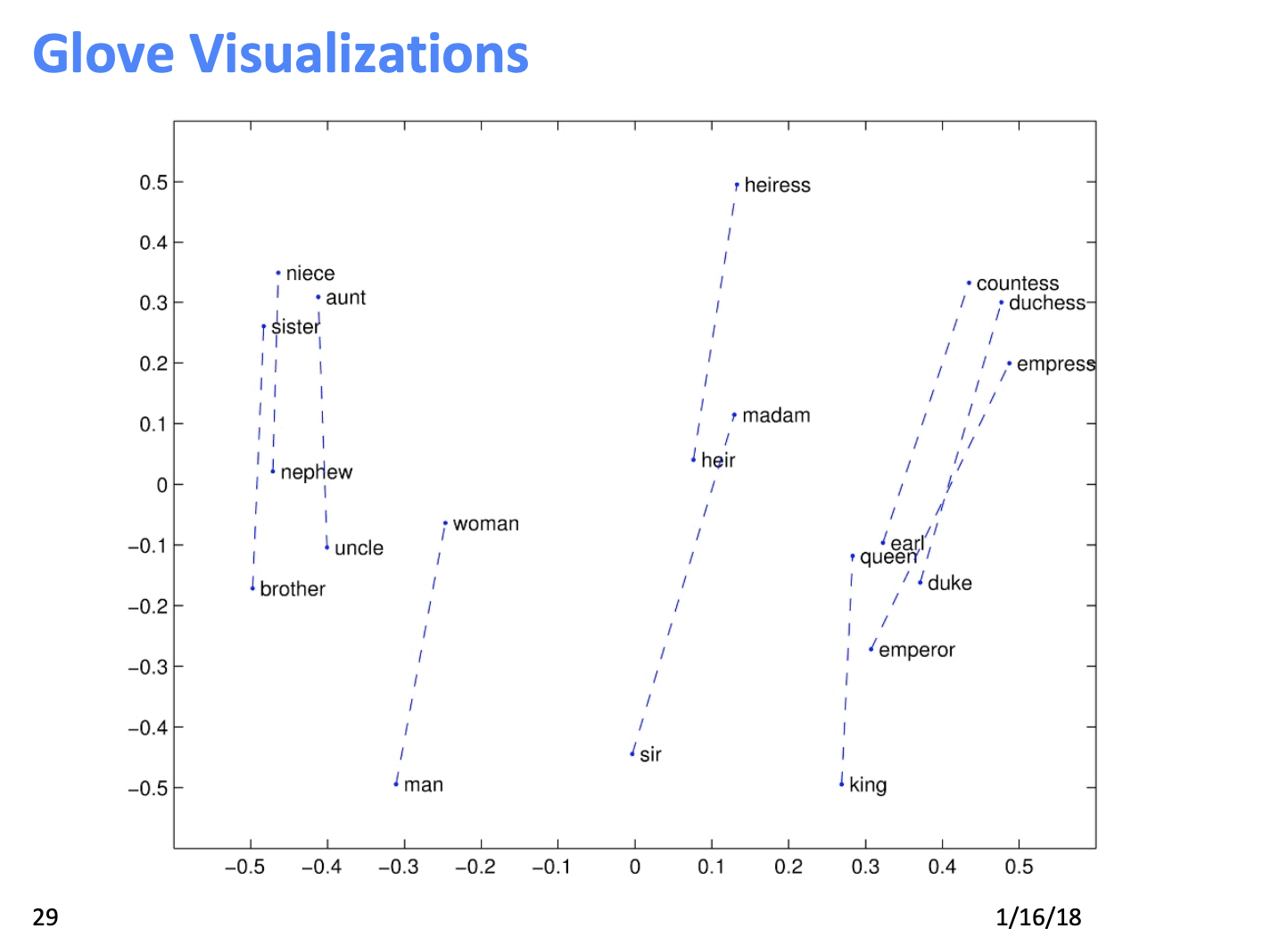
Glove의 시각화 결과
Glove를 다른 여러 model과 비교한 결과
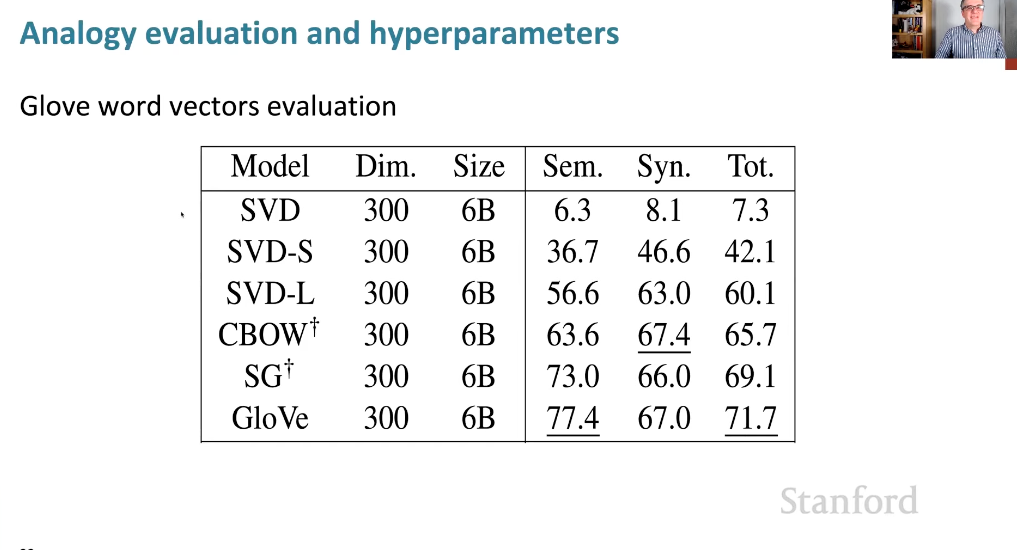
- 일반적인 SVD를 사용하면 성능이 7점으로 엄청 저조하다. 하지만, 이를 스케일링하면(SVD-S, SVD-L) 성능이 많이 향상되었다는 것을 볼 수 있다. SVD-L은 COALS 모델이라 할 수 있다.
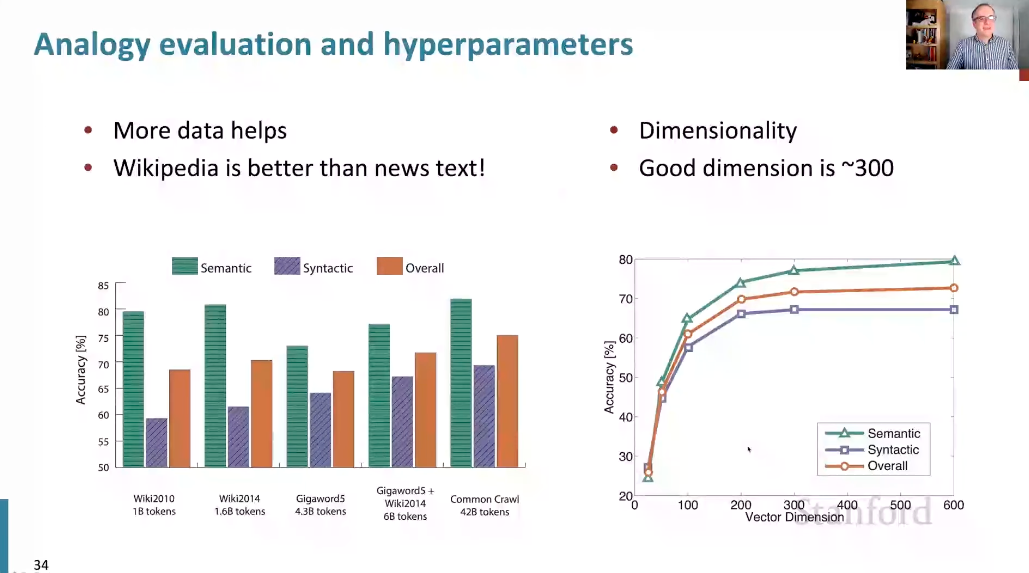
-
Glove가 더 우수하고 통계를 보다 효율적으로 사용했다고 생각했으나... 실제로는 더 나은 데이터가 있었기 때문일 것이라고 생각한다.
-
다양한 데이터 하위 집한에 대해 Glove를 훈련시켜 의미론적, 구문론적 및 전반적인 성능을 살펴봤다.
-
Wiki에서 학습시켰을때는 Semantic(의미론적 유추)에 대해 좋은 결과를 얻을 수 있었다. 다른 데이터들에 대해서는 그렇지 못 했다.
-
하지만, 데이터를 늘려서 420억개의 데이터를 사용하면 또 성능을 높일 수 있었다. (Common Crawl 42B tokens)
-
오른쪽 그래프는 벡터 차원에 따른 성능 결과이다. dimension의 경우 ~300일 때 가장 성능이 좋았다.
