문제
Given an integer array nums and an integer k, return true if there are two distinct indices i and j in the array such that nums[i] == nums[j] and abs(i - j) <= k.
- Input : integer 배열
nums, 두 숫자 사이 거리k - Output :
i != j,nums[i] == nums[j],abs(i - j) <= k를 만족하는[i, j]가 존재하는가?
알고리즘 전략
-
전략 1. 이중 반복문 비교
i (0 <= i <= nums.length)번째 위치와i+j (1 <= j <= k)번째 위치와의 원소 비교- 원소가 같은 것이 있는 경우,
true를 반환 - Time complexity :
- Space complexity:
-
전략 2. 자료구조 Set 이용
0번째 부터k-1번째까지 Set에 넣음- 중복이 있을 경우,
true를 반환
- 중복이 있을 경우,
i (k <= i < nums.length)를 순회하면서i번째 원소를 Set에서 중복 확인, 중복이 있다면true를 반환i번째 원소를 Set에 넣고,i - k번째 원소를 Set에서 제거
- Time complexity :
- Space complexity:
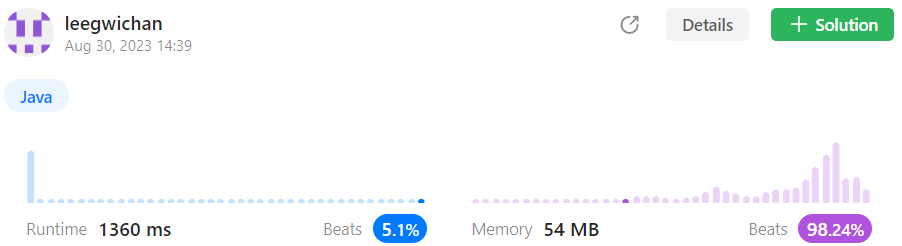
답안 1 (이중 반복문 이용)
- Time complexity :
- Space complexity:
class Solution {
public boolean containsNearbyDuplicate(int[] nums, int k) {
for (int i = 0; i < nums.length; i++) {
for (int j = i + 1; j < Math.min(i + k + 1, nums.length); j++) {
if (nums[i] == nums[j]) {
return true;
}
}
}
return false;
}
}
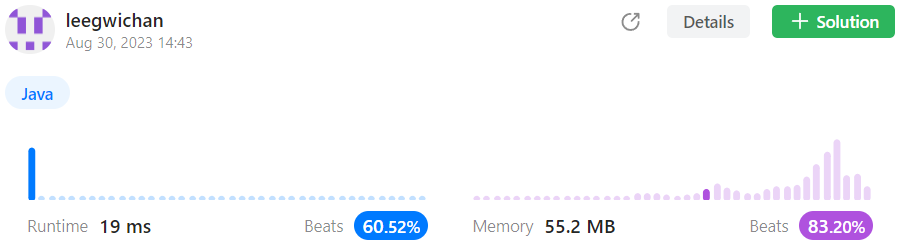
답안 2 (자료구조 Set 이용)
- Time complexity :
- Space complexity:
class Solution {
public boolean containsNearbyDuplicate(int[] nums, int k) {
Set<Integer> targets = new HashSet<>();
for (int i = 0; i < Math.min(k, nums.length); i++) {
if (targets.contains(nums[i])) {
return true;
}
targets.add(nums[i]);
}
for (int i = k; i < nums.length; i++) {
if (targets.contains(nums[i])) {
return true;
}
targets.add(nums[i]);
targets.remove(nums[i - k]);
}
return false;
}
}
다른 답안 분석 (자료구조 Map 이용)
-
기본 전략
- [letter - index]로 이루어진
Map을 사용함 - 만약 같은 문자일 때 이전에 입력한 index와 현재 위치의 index의 차이가
k보다 작은 경우true를 반환함
- [letter - index]로 이루어진
-
Set을 이용할 때와의 성능차이
- 위의 Set을 이용했을 때는 원소를 넣는 연산, 빼는 연산이 둘 다 필요했었다.
- Map의 방식 경우에는 넣는 연산 (업데이트 연산)만이 필요하기 때문에 시간이 더 단축되었다.
- Map은 key-value를 이용하고 Set은 value값만 이용하기 때문에 메모리는 더 많이 사용한다.
class Solution {
public boolean containsNearbyDuplicate(int[] nums, int k) {
Map<Integer, Integer> letterToIndex = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
Integer prev = letterToIndex.put(nums[i], i);
if (prev != null && i - prev <= k) {
return true;
}
}
return false;
}
}

장비를 정지합니다.