Random Forest
랜덤 포레스트를 이해하기 위해 필요한 bagging과 관련된 확률 이론을 정리해보겠습니다.
1 Bagging
Bootstrap
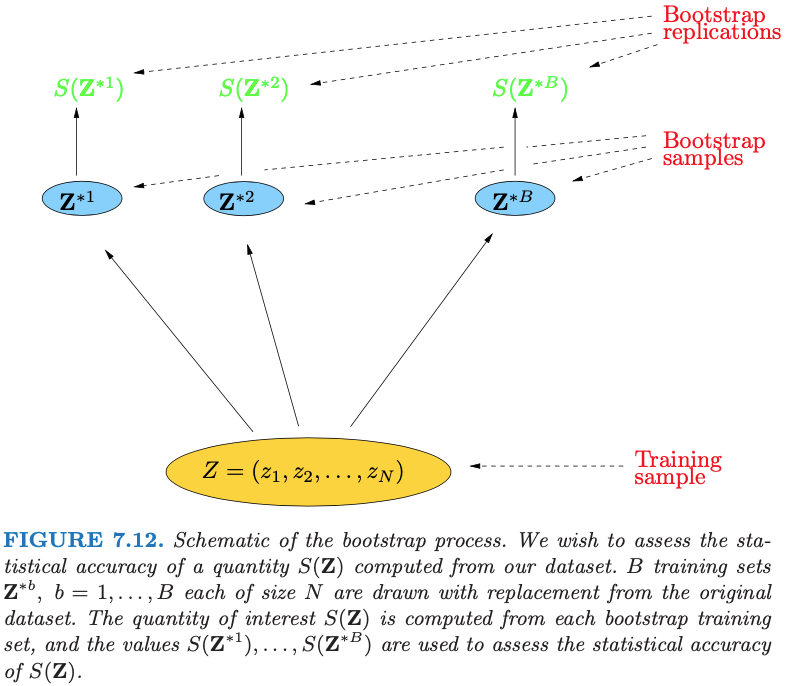
data point가 n개 있을 때, bootstrap은 n개의 크기를 가진 표본을 복원 추출하는 방법을 말합니다. Bootstrap을 통해 추출된 크기가 인 표본은 으로 표기 할 수 있습니다.
중요한 점은 개의 표본단위 를 정해진 어떤 값으로 생각하면 안 된다는 것입니다. 을 번째에 추출된 어떤 값으로 생각해야하며, 표본 에 속하는 각각의 표본 단위는 모두 확률 변수(random variable)입니다. 또한 각 표본 단위 은 모집단 와 같은 확률 분포입니다.
이를 동일 분포(identical distribution), 독립 분포(independent distribution)인 확률 변수(random variables)라고 말합니다.
- 동일 분포: 각 표본 단위들이 동일한 분포임을 뜻합니다. 모집단에서 추출한 표본 단위는 모집단의 분포를 그대로 가지고 있으므로, 하나의 표본에 존재하는 모든 표본 단위는 동일한 분포를 가지고 있습니다.
- 독립 분포: 각 표본 단위가 추출되는 것이 다른 표본 단위가 추출되는 확률에 영향을 끼치지 않는 특성을 뜻합니다. 이는 표본 추출이 '무작위 복원 추출'을 전제하기 때문입니다. 따라서 각 표본 단위들이 추출된 확률은 모두 동일합니다. 즉 입니다.
축약어로는 iid(identical and independent distribution)라고 하며, 다음과 같이 표기할 수 있습니다(는 모집단의 확률 변수를 나타냄)
이를 다른 말고 확률 표본(random sample)이라고도 합니다. 확률 표본이란 모집단에 속하는 모든 단위가 표본에 추출될 확률이 모두 동일하도록 추출되는 표본을 말합니다. 즉 의 표본에서 아래의 수식이 성립됩니다.
1.1 What's the Bagging?
Bagging은 Bootstrap aggregating의 약자 Bootstrap은 모집단에서 복원 추출한 sample들을 뜻합니다. 배깅 방법은 uniform 확률 분포에서 독립적이면서 랜덤 복원 추출로 선택된 data들을 이용합니다.
학습 데이터가 대응 되는 반응 변수가 일때, bagging은 번 만큼 반복 시행됩니다.
For :
1. Sample, with replacement, training examples from ; call these
2. Train a classification or regression tree on
학습이 완료된 후 unseen sampels 에 대한 prediction은 모든 개별적인 tree의 결과를 averaging 하여 나타냅니다.
bagging은 identical distribution 조건을 마족하지만, independence distribution 조건을 만족시키지 못합니다. 예를들어, tree estimator를 만들 때, 어느 tree에서나 중요하게 사용되는 feature가 있다고 생각해봅시다. 사람의 성별을 예측하는 문제에서는 '키'와 같은 변수가 되겠습니다. 이 경우 어느 tree에서나 '키' 변수는 첫번째 split 기준으로 선택될 것입니다. 그 결과 대부분의 tree의 prediction 결과는 비슷해질 것입니다. 다시 말해 각 tree의 prediction 값이 correlated(not independent) 됩니다.
이를 볼 때, bagging은 iid 확률 변수들의 sequence(bootstrap samples)를 받아 tree estimator를 통해 id 확률 변수로 변환하는 과정이라고 생각해볼 수 있습니다.
1.2 Advantages of Bagging
bagging은 모델의 variance을 줄여서(bias는 상승시키지 않으면서) 모델의 성능을 끌어 올릴 수 있습니다. 이는 하나의 tree의 분산이 높아 학습 데이터의 이상치에 지나치게 sensitive 하더라도, 다수의 tree의 결과를 averaging 하면, 이상치에 강건(variance 낮음)한 모델을 만들 수 있다는 것을 의미합니다. 그러나 이는 각 tree가 correlated 되지 않을 것을 전제로 합니다..
Bagging succeeds in smoothing out this variance and hence reducing the test error.Bagging can dramatically reduce the variance of unstable procedures like trees, leading to improved prediction. A simple argument shows why bagging helps under squared-error loss, in short because averaging reduces variance and leaves bias unchanged.
1.3 Why bagging reduce variance??
bootstrapping method is better when the training samples are sparase, and the subspace method is better when the classes are compact and the boundaries are smooth.
2 Random subspace method
2.1 What's the Random subspace method?
Random subspace method(이하 RSM)는 bagging과 유사하지만, features(attributes, predictors, independent variables)를 랜덤 복원 추출한다는 점에서 차이가 있습니다.
RSM는 feature bagging 또는 attribute bagging이라고도 불립니다. RSM은 앙상블 방법에 활용된 각 classifiers(estimators) 간의 correlation을 낮추는 역할을 합니다.
In the random subspace method, in each pass all the training points are projected onto a randomly chosen coordinate subspace in which a classifier is derived. The combined classifier is called a random forest
2 From Bagging to Random Forests
2.1 Advatages of random forest over single tree
- bagging: it is better when the training samples are sparse
- Random subspace method: it is better when the classes are compact and the boundaries are smooth.
The subsampling method is preferable when the training set is very sparse relative to dimensionality, especially
when coupled with a close-to-vanishing maximum Fisher’s ratio (0.3 or below), and when the class boundary is highly nonlinear.
-
Same Bias, but with lower variance over single decision Tree
-
decorrelate trees: Use a random subset of features in each step of growing each tree.
-
train dataset의 feature가 1개만 존재한다면, random forest는 사실상 bagging 알고리즘과 같다(random subspace method를 사용할 수 없기 때문)
3 Appendix
- bayes error: 이론적으로 달성할 수 있는 최소의 오차(irreducible error, 더 이상 줄일 수 없는 오차)
3.1 추정량(estimator)과 추정치(estimate)
대학생들의 한 달 평균 용돈을 알기 위하여 100명의 대학생을 단순 무작위로 추출하여 조사한 결과, 표본 평균 만원 이었습니다. 따라서 모집단의 모수 를 30만원 일것이라고 추정 하였습니다.
이 때 표본 통계량 를 구하는 공식 는 추정량(estimator)라고 하고, 이에 따른 구체적인 수치 만원은 추정치(estimate)가 됩니다. 정리 하면 아래와 같습니다.
- 추정량(estimator): 표본에 포함된 자료를 이용하여 추정치를 계산할 수 있는 법칙, 공식 또는 알고리즘
- 추정치(estimate): 추정량을 이용하여 계산된 구체적인 수치값
3.2 불편성(bias)
아래 공식을 만족하는 추정량을 불편 추정량(unbiased estimator)라고 합니다.
참고로 표본의 통계치들은 확률 변수임을 반드시 기억해야 하겠습니다. 모수에서 크기가 인 표본을 뽑게되면, 뽑을 때마다 표본의 통계치들을 달라질 것입니다. 따라서 표본 통계량 가 확률 변수이고 그에 상응하는 표본 분포(sample distribution)을 가지므로, 기대값을 구할 수 있는 것입니다.
Reference
- Random forest
- Random subspace method
- A Data Complexity Analysis of Comparative
Advantages of Decision Forest Constructors - Understanding the Effect of Bagging on Variance and Bias visually
- 좋은 추정량(estimator)의 조건 - unbiased, efficiency, consistency
- 모집단 평균의 추정
- 확률표본, 통계량, 모수, 표본평균의 분포
- Why the trees generated via bagging are identically distributed?
