
들어가며
Elasticsearch는 다양한 유스케이스와 기능을 제공하기 때문에, 단박에 그 컨셉이 쉽게 와닿지 않을 수 있습니다. 이해를 돕기 위해서, 가장 핵심적인 요소를 몇 가지 추려 정리해보았습니다.
Elasticsearch란?
Elasticsearch는:
- Apache Lucene 기술을 기반으로 만들어졌습니다.
- 데이터 저장소입니다.
- 검색 엔진입니다.
- 분석 엔진입니다.
- 분산(Distributed) 시스템이며 확장(Scalable) 가능한 시스템입니다.
- 벡터 데이터베이스입니다.
- ELK에서 E를 담당하며, Elastic Stack에서 핵심 기술을 담당합니다.
뭐가 많지만, 결국 핵심은 Elasticsearch에 데이터를 어떻게 넣고 꺼내는지를 중심으로 이루어져 있다고 생각합니다. 따라서 거기서부터 시작하면, 이해가 좀 더 쉬울 것 같습니다.
Index
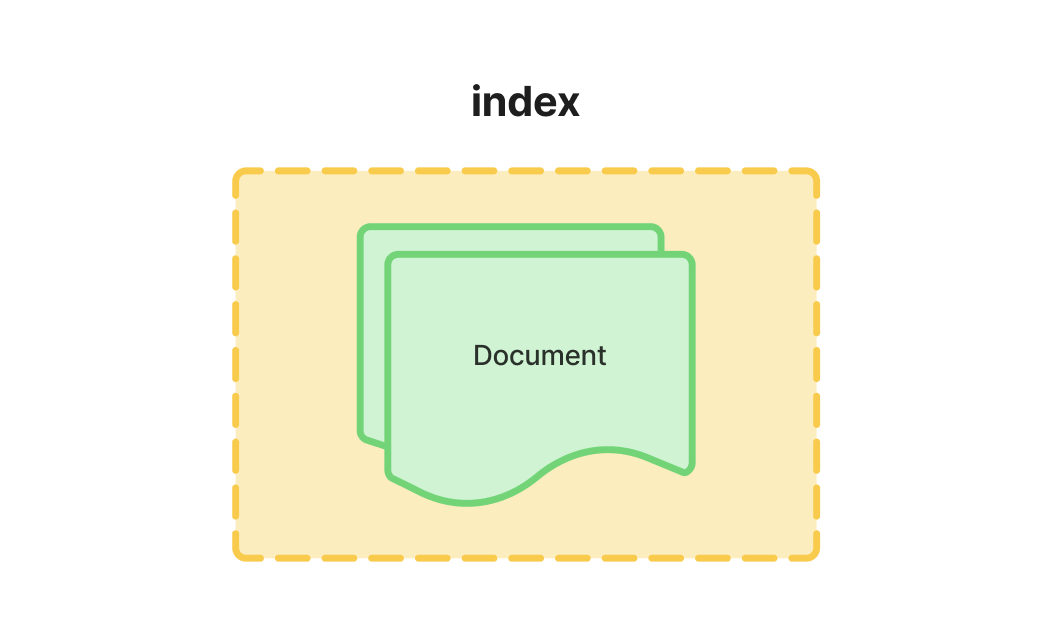
index(인덱스)는 저희가 주로 RDB에서 생각하는 인덱스와는 조금 다르게, Elasticsearch에서는 독자적인 특별한 의미를 가집니다. 정의는 다음과 같습니다:
index는 서로 유니크하게 식별 가능한 document의 모음입니다.
즉, RDB에서 Table처럼 하나의 데이터 모음을 구별하는 Elasticsearch의 가장 기본이 되는 요소입니다.
Document는 key-value 형태의 field로 구성된 데이터 구조체입니다. 각 document는 유니크한 ID를 가지며, 이는 직접 생성하거나 Elasticsearch가 자동 생성하게 할 수 있습니다.
Elasticsearch에서 document는 대략 다음과 같이 생겼습니다:
{
"_index": "my-first-elasticsearch-index",
"_id": "DyFpo5EBxE8fzbb95DOa",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"email": "john@smith.com",
"first_name": "John",
"last_name": "Smith",
"info": {
"bio": "Eco-warrior and defender of the weak",
"age": 25,
"interests": [
"dolphins",
"whales"
]
},
"join_date": "2024/05/01"
}
}여기서 사용자가 제공한 실제 데이터는 _source 필드에 들어가며, 그외 다큐먼트의 정보를 담는 필드를 metadata fields라고 부릅니다. 다큐먼트는 인덱스에 저장되므로, RDB에서 하나의 Row의 위치 정도로 생각해볼 수 있겠습니다.
각 인덱스는 mapping(매핑)이라는 인덱스에 저장되는 다큐먼트의 각 필드별 데이터 타입, 인덱스 방식 및 저장 방식에 대한 정의(definition)를 갖습니다. index가 RDB의 table과 같다면, mapping은 schema처럼 생각해봐도 좋을 것 같습니다.
| Elasticsearch | RDB |
|---|---|
| index | table |
| document | row |
| mapping | schema |
완전한 1대1 매칭이라기 보단, 이해를 돕기 위한 비유라고 생각해주시면 좋을 것 같습니다.
Indexing
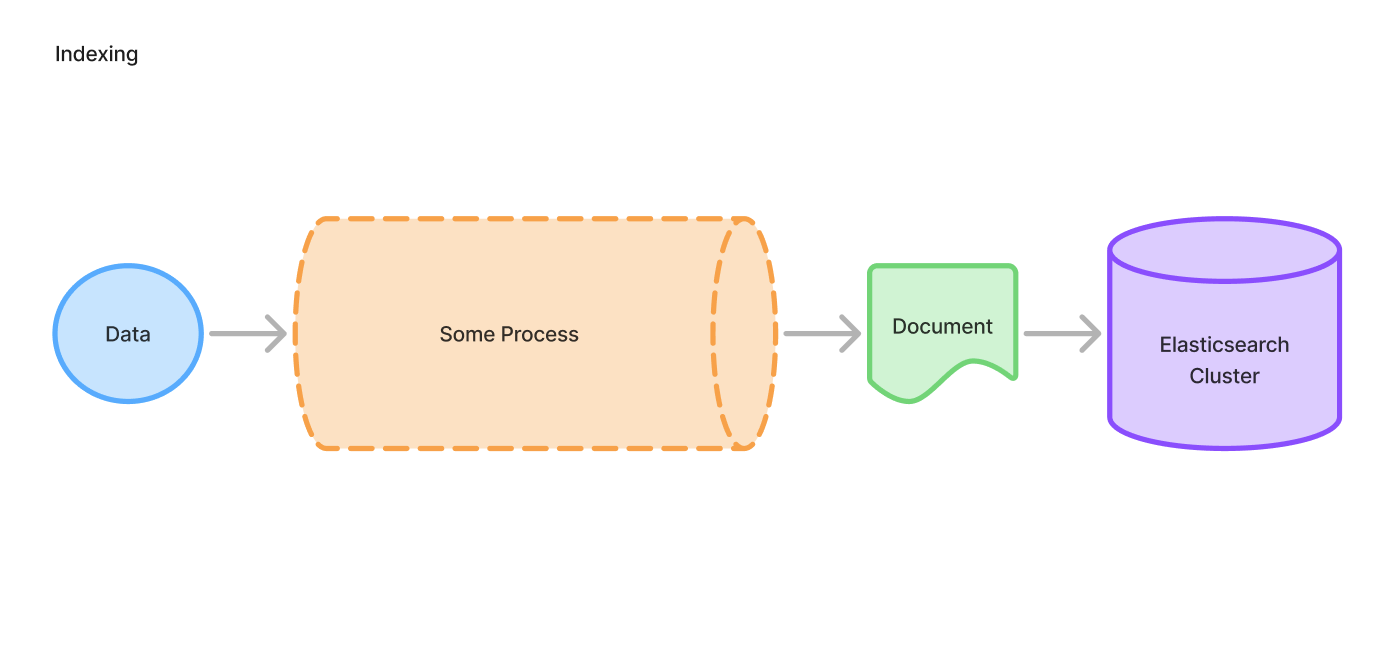
Elasticsearch에 입력되는 데이터는 일련의 절차를 거쳐서 준실시간(Near real-time)으로 검색 가능한(searchable) document가 되어 저장됩니다. 저장된 데이터는 분산 처리되어 고가용성 및 성능을 보장합니다.
이렇게 어떤 데이터를 Elasticsearch cluster에 추가하는 과정을 indexing(인덱싱)이라고 부릅니다. 앞서 말했듯이 RDB의 인덱싱과는 많이 다른 개념이기 때문에 주의해야 합니다. (cluster에 대한 자세한 설명은 여기서 생략합니다. 지금은 단순히, Elasticsearch 저장소에 검색 가능한 상태로 잘 저장되었다 라고 봐주시면 됩니다)
앞서 말한 일련의 절차에 대해 이해하기 위해서 Elasticsearch의 가장 핵심 기능인 Full-text search의 절차를 알아보겠습니다.
Full-text search
Elasticsearch의 Full-text search에 대해서 이야기하기 전에 그냥 Full-text search에 대해 알아보겠습니다.
Lexical search라고도 불리는 full-text search(전문 검색)란, 텍스트 데이터 안에서 특정 단어나 문구를 찾아내는 검색 방식입니다.
RDB를 사용해서 검색을 구현하면 다음과 같이 할 수 있습니다:
LIKE '%keyword%'이렇게 하면 keyword와 일치하는 값을 찾아서 데이터를 반환할 수 있습니다. 다만, 이 방식으로 우리가 아는 ‘검색’을 구현하려고 하면 몇 가지 문제점이 있습니다:
- 검색 성능 문제: RDB의 인덱스는 앞자리부터 생성됩니다. 따라서 와일드카드
%가 앞쪽에 붙은 쿼리에 대해서는 인덱스를 활용하지 못하고, 반드시 full-table scan을 실시합니다. - 검색 품질 문제: “나이키” 검색하면 큰 문제가 되지 않습니다. 하지만 “나이키 운동화” 검색하면 문제가 달라집니다. RDB에서는 반드시 “나이키 운동화” 전체가 포함된 데이터를 찾습니다. 사용자는 “나이키”이면서 “운동화”인 여러 결과를 찾고 싶어할 것입니다. 연관된 순서로.
Full-text search는 이러한 문제를 역색인(Inverted index)라는 것으로 해결합니다. 전통적인 색인(index) 방식은 ID에서 데이터(ID→Data)를 향합니다. ID로 데이터를 찾는 경우가 매우 많기 때문입니다. 반대로 역색인은 검색 대상이 되는 각 “키워드(토큰)”에서부터 문서를 찾는 방식(Token→문서)입니다.
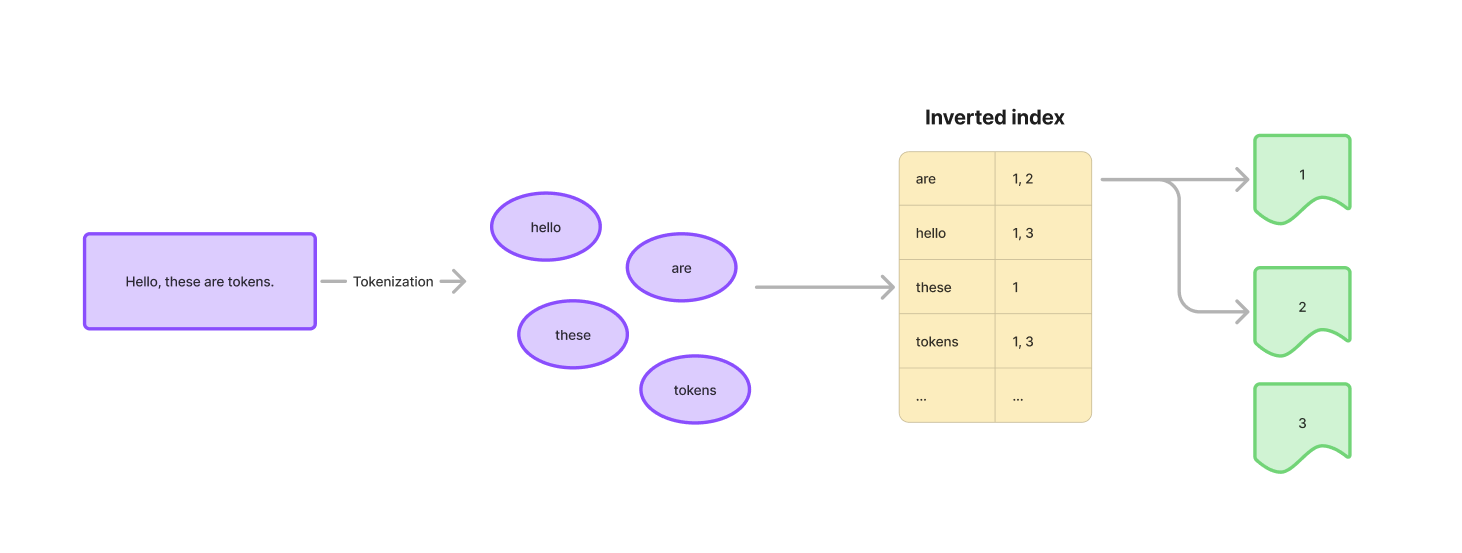
입력되는 문장을 의미를 가지는 최소 단위인 토큰(Token)으로 나눠서 이를 키(Key)로 저장합니다. 각 토큰은 해당 토큰을 포함하는 문서를 가리키는 값(+정확한 위치, 빈도 등 메타데이터)를 값(Value)로 가집니다.
이제 누군가 “hello tokens”를 검색하면 “hello”와 “tokens”를 포함하는 모든 문서를, 둘 다 포함하는 문서를 우선으로 하여 반환하게 됩니다.
Elasticsearch의 Full-text search
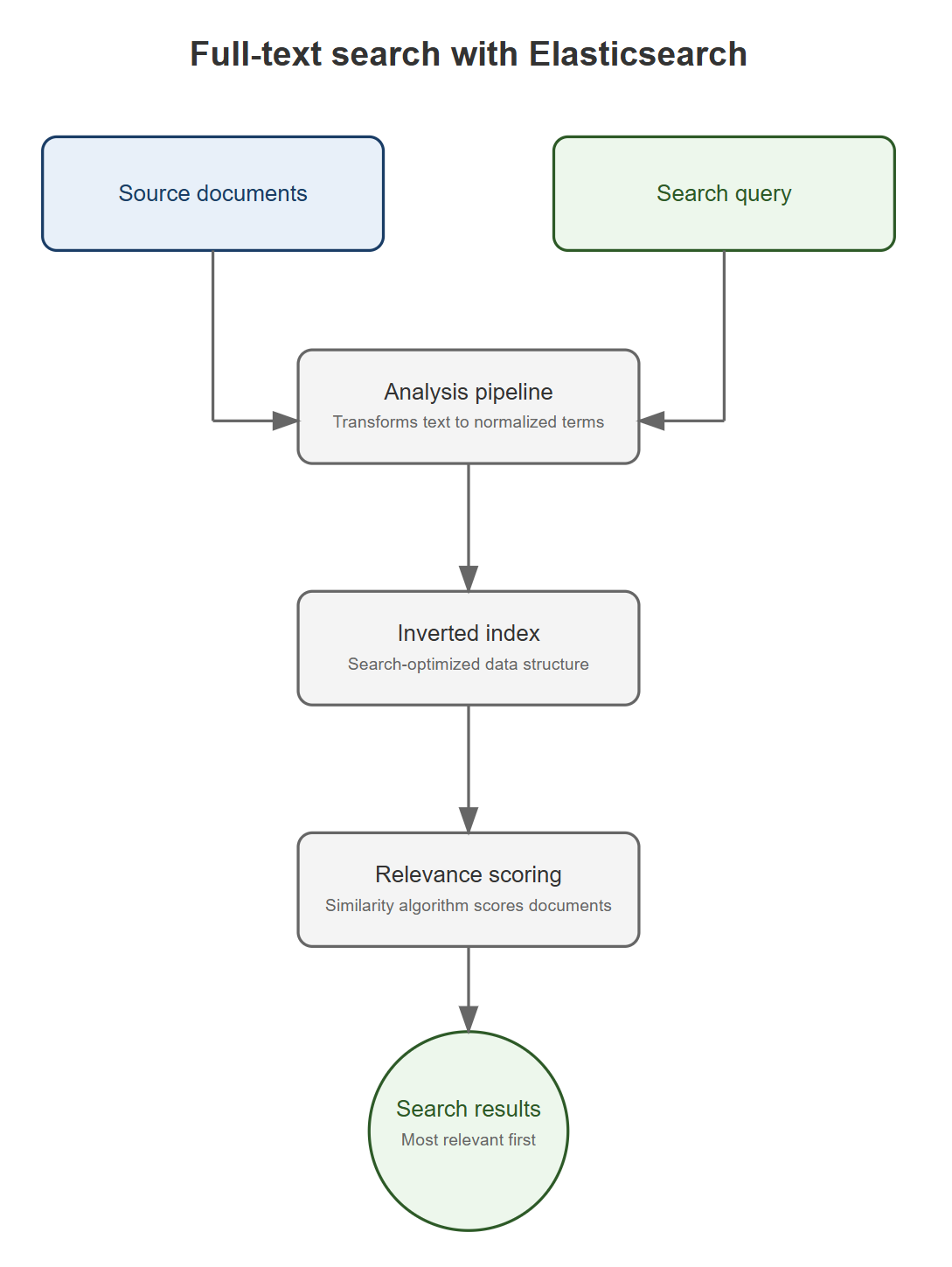
Elasticsearch에서는 Full-text search를 위한 저장과 검색에 대한 이런 과정이 다음과 같이 구성되어 있습니다:
저장
- Analysis pipeline: 인덱스의
text필드의 값에 대해 각종 전처리(HTML 태그 제거, 형태소 분석)와 토큰화를 진행하여 역인덱스를 생성할 수 있게 준비합니다. 이 파이프라인은 여러 개의 Text Analyzer로 이루어져 있습니다.- 인덱스에
text필드가 없다면 이 과정은 생략됩니다.
- 인덱스에
- Inverted index: 앞의 과정으로 만들어진 토큰들로 역인덱스를 생성합니다.
- Elasticsearch의 inverted index는 토큰에 대한 각 다큐먼트에 대한 주소뿐만 아니라 추가적인 정보가 포함되며, Dictionary와 Posting list라는 두 가지 컴포넌트로 구성됩니다(자세한 설명은 여기 참조).
검색
- 검색을 위해 제공된 쿼리가 우선 Analysis 과정을 거칩니다.
- Relevance scoring: 검색 결과와 검색 쿼리가 얼마나 비슷한지(Similarity)를 주어진 알고리즘에 따라 평가합니다.
_score라는 필드로 그 점수를 확인할 수 있습니다. - 결과 반환: 가장 연관 있는(relevant,
_score가 높은) 결과를 우선으로 반환합니다.
Near real-time search
Document는 indexing된 이후 준실시간(Near real-time)으로 조회가 가능합니다. 이것을 가능하게 하는 것은 Elasticsearch가 기반하고 있는 Apache Lucene 엔진의 Segment라는 것 덕분입니다. Lucene은 Elasticsearch의 실제 데이터 입출력(Disk I/O) 및 검색을 담당하고 있습니다.
Segment는 Lucene의 storaging과 indexing의 기본 단위입니다. RDB의 storaging 기본 단위가 Page인 것과 유사합니다. Segment는, inverted index와 비슷한…데 정확히 같지는 않습니다. 일단, Lucene의 index는 Elasticsearch의 index와 조금 다른데, “Segment의 모임 + commit point” 라고 합니다.
제가 이해하기로 이 commit point라는 개념은 특정 Index가 변화하는 상태를 관리하기 위한 컴포넌트로, MySQL의 redo log나 checkpoint 등의 역할과 비슷한 느낌인 것 같습니다. commit point는 내부적으로 IndexCommit이라는 객체로 구현되어 있는데, 각 IndexCommit은 관련된 Segment와 파일 및 기타 정보를 담고 있습니다.
Changes to the content of an index are made visible only after the writer who made that change commits by writing a new segments file (
segments_N). This point in time, when the action of writing of a new segments file to the directory is completed, is an index commit.Each index commit point has a unique segments file associated with it. The segments file associated with a later index commit point would have a larger N.
— 출처
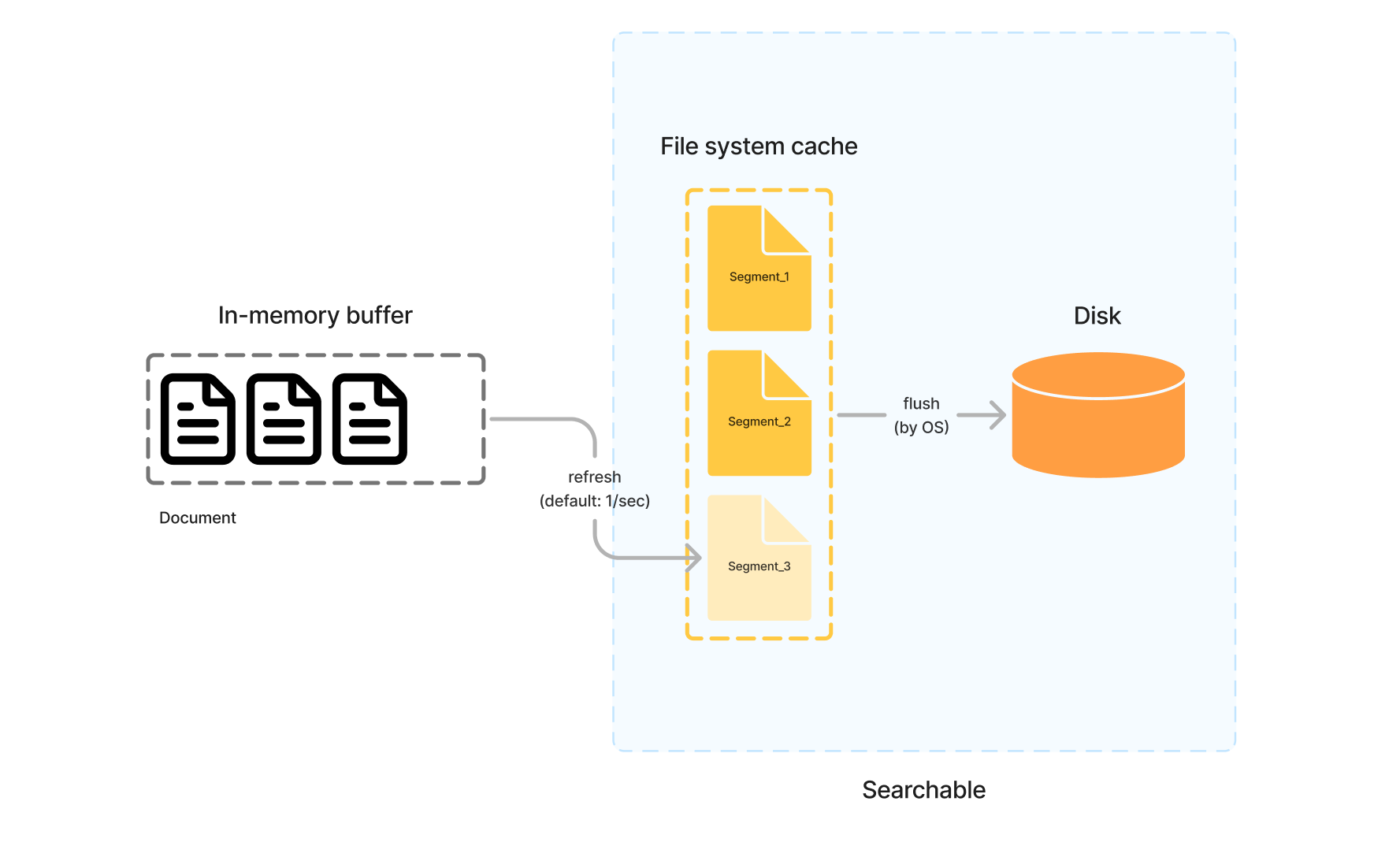
준실시간에 대해 다시 얘기하자면, 새로운 다큐먼트들은 Segment로 저장되기 위해서 우선 In-memory index buffer에 저장되었다가, 작은 Segment로 구성되어 Disk에 기록되기 전에 주기적으로(기본 1초) file system 캐시에 저장되는데, 이 시점부터 다큐먼트는 검색 가능(Searchable)하게 됩니다. 이렇게 Documents가 Segment로 저장하는 것을 refresh한다라고 부릅니다.
이 refresh는 기본 1초를 주기로 다큐먼트를 벌크 처리하기 때문에, 즉시처리 되지 않아 Elasticsearch를 준실시간(Near real-time)이라고 부릅니다.
이 주기를 사용자가 조절하거나, refresh API를 통해 원하는 시점에 강제로 진행할 수도 있습니다.
마지막으로 file system cache에 있는 데이터를 Disk에 실제로 쓰는(write) 작업을 flush라고 부릅니다. 이건 OS가 알아서 해줍니다.
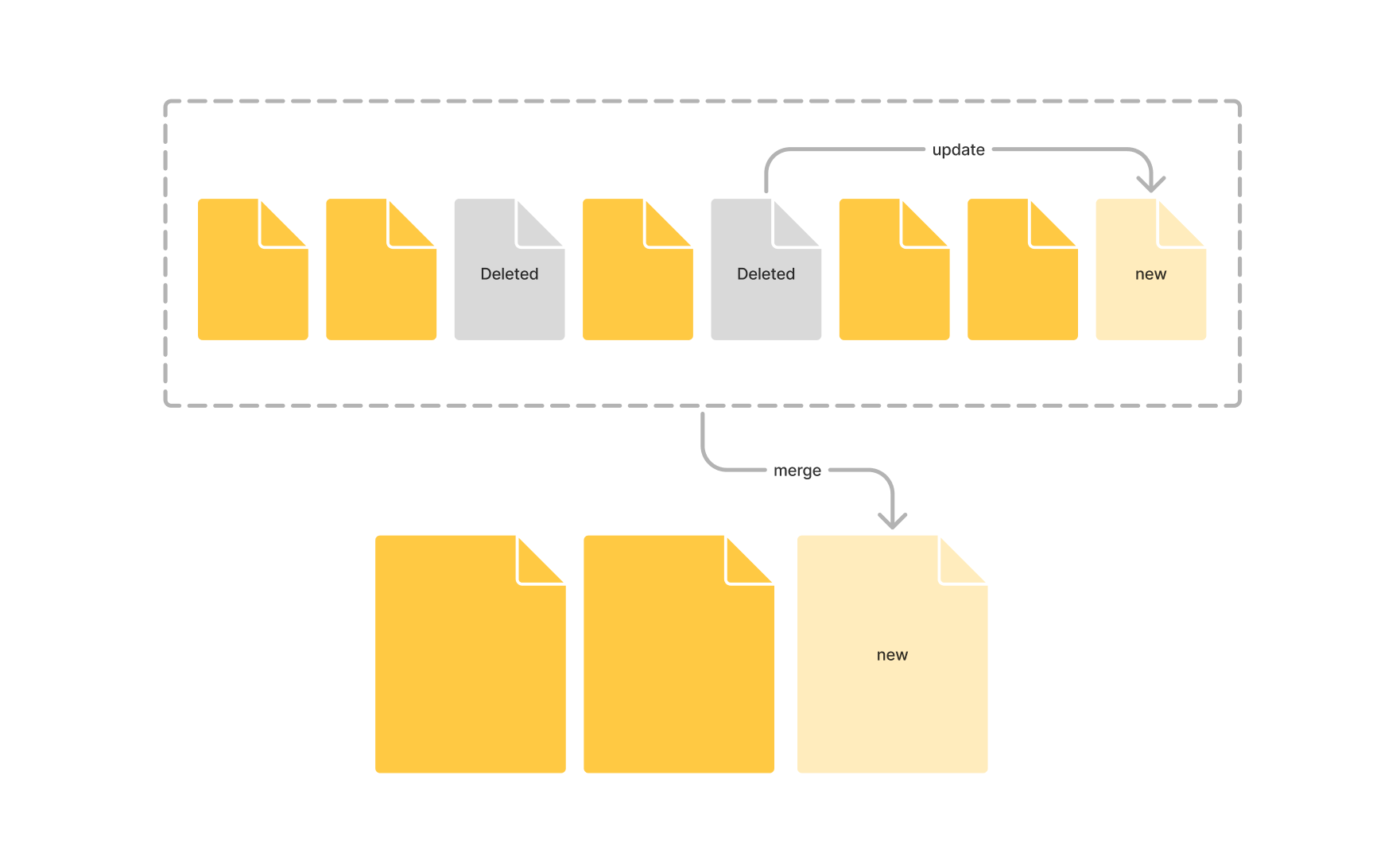
세그먼트는 업데이트나 삭제되지 않고 오직 “생성”만 됩니다. 그래서 세그먼트를 Immutable(불변)하다고 합니다. 기존 세그먼트에 변화가 생기면 commit point를 통해 기존 세그먼트를 삭제되었다 표시(플래그)만하고, 새로운 세그먼트를 생성합니다. 이렇게 하면 세그먼트가 너무 많이 생성되면 데이터 파편화가 생기는데, 이를 위해 Lucene 엔진은 주기적으로 삭제된 세그먼트는 빼고, 유효한 작은 세그먼트들을 모아 더 큰 세그먼트로 만드는 merge 작업을 합니다. 이 merge 작업은 전체 프로세스와는 별개로 알아서 진행됩니다.
마치며
굉장히 오랜만에 블로그네요! 사실 2025년 회고도 그렇고 이것저것 쓰려고 했는데, 12월에 냅다 취업이 되어버리고 난 이후로 좀 놀고 싶기도 했고, 적응하느라 정신이 없었습니다ㅋㅋㅋ. 위 내용은 마침 회사에서 스터디겸 기술 공유를 할 일이 있어서, 이렇게 된 김에 블로그 쓴다는 마음으로 제대로 써보려고 했습니다ㅎㅎㅎ. 앞으로는 블로그를 더 많이 써보려고 합니다!
오타 오류 모두 환영합니다! 감사합니다.
