들어가며
최근 거의 공공제에 가까워지고 있는 제 개인정보가 또 공유되는 사태가 발생하였습니다. 관련 원인에 대해서 다루는 기사에서, 여러 원인 중 하나로 API 및 인증 구조를 짚었습니다. 사용자 테이블의 PK(Primary Key)를 1, 2, 3, ... 으로 자동 증가하는 값(Auto Increment)을 이용했으며, 엑세스 토큰 등의 서명에 해당 값을 사용했다는 부분이었습니다.
개인정보가 유출된게 괘씸했으나, 다른 한편으로는 제 프로젝트도 똑같은 방식을 이용하고 있다는 사실에 얼른 이를 개선해봐야겠다 생각이 들었습니다.
왜 문제가 되나?
제 프로젝트를 기준으로 문제를 구체적으로 정의하면 다음과 같습니다:
- JWT 엑세스/리프레시 토큰의 내용으로 User의 PK 값을 이용하고, 이를 기준으로 인증을 진행한다.
CustomUserDetailsService
@Service
@RequiredArgsConstructor
@Slf4j
public class CustomUserDetailsService implements UserDetailsService {
private final UserRepository userRepository;
@Override
public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {
try {
return CustomUserDetails.of(userRepository.findById(Integer.valueOf(username)).orElseThrow(() -> new UsernameNotFoundException("해당하는 ID의 유저가 존재하지 않습니다.")));
} catch (Exception e) {
log.debug("Username not found", e);
throw new UsernameNotFoundException("Username not found");
}
}
}- API 또한
userId를 PathVariable로 사용하고, 응답 객체에도userId를 노출한다.
기존 /users/{userId} 응답
{
"userId": 123,
"username": "gyehyunbak"
}이와 같은 구조로 API를 공개하고, 보안 인증 처리를 진행할 경우 치명적인 단점이 하나 있습니다. 바로, 인증을 위한 토큰 서명에 사용한 키값이 탈취 당하면, 거의 모든 사용자의 데이터가 노출된다는 것입니다.
아래는 JWT(Json Web Token)을 만들어볼 수 있는 공식 사이트입니다.
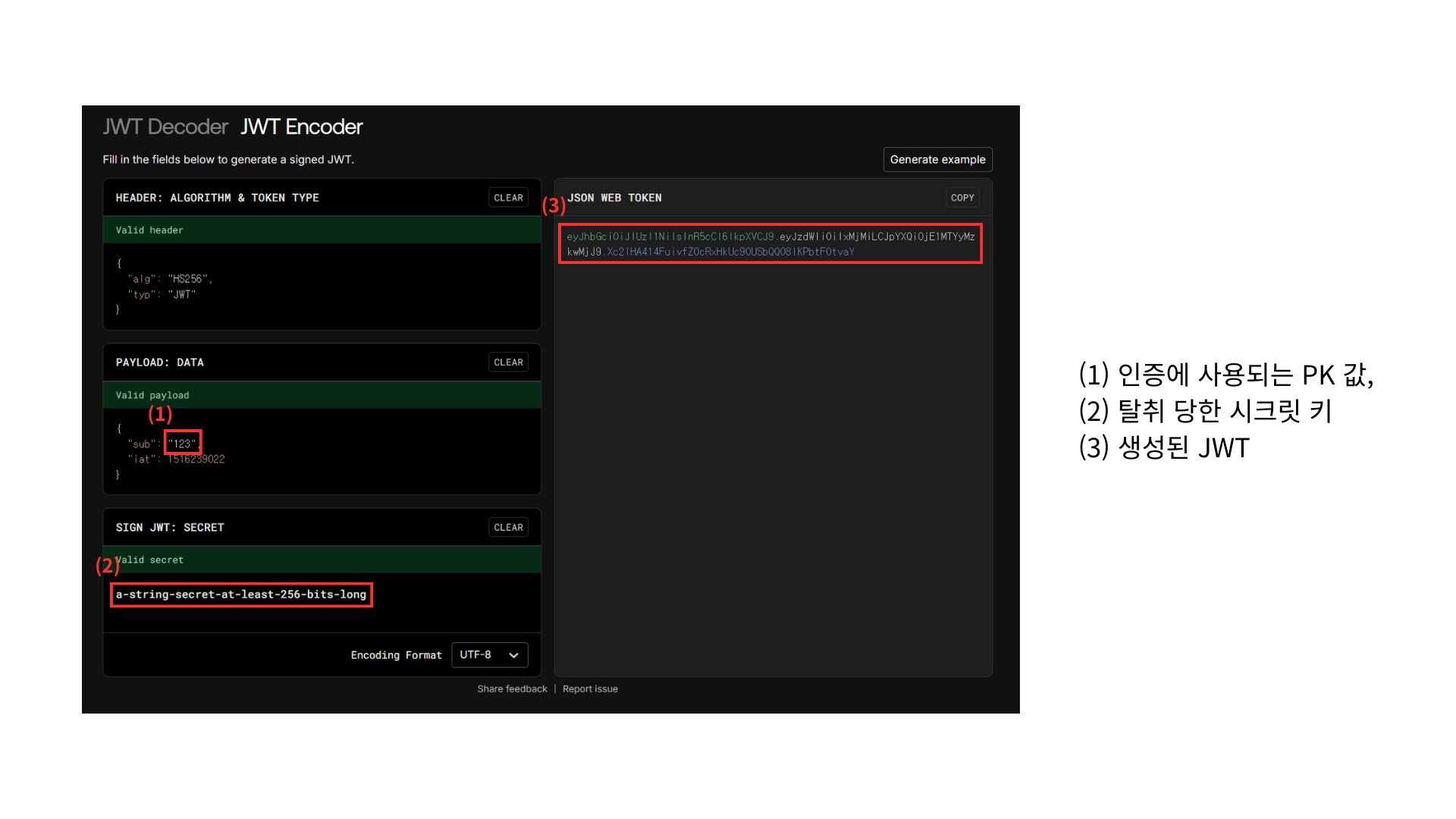
PK 값이 단순 증가값(Auto Increment)라면, 누군가의 ID가 1이면 다음 사람은 2라는 뜻입니다. 서명 키를 알고 있고, 또 내부 데이터 구조를 알고 있는 사람이 있다면, 저 1과 2를, 그리고 높은 확률로 그 뒤에 숫자들도 payload에 담아 서명하면, 실제 사용자에 해당하는 엑세스 토큰이 됩니다. 사용자가 천만 명 2천만 명 된다면, 적당히 1부터 20,000,000까지 모조리 토큰을 만들어서 내 정보 조회 API에 때려보면 DB에 접근 권한이 없어도 거의 모든 데이터를 쉽고 빠르게 얻을 수 있는 것입니다.
반대로 인증에 쓰이는 값이 난수라면 어떨까요?
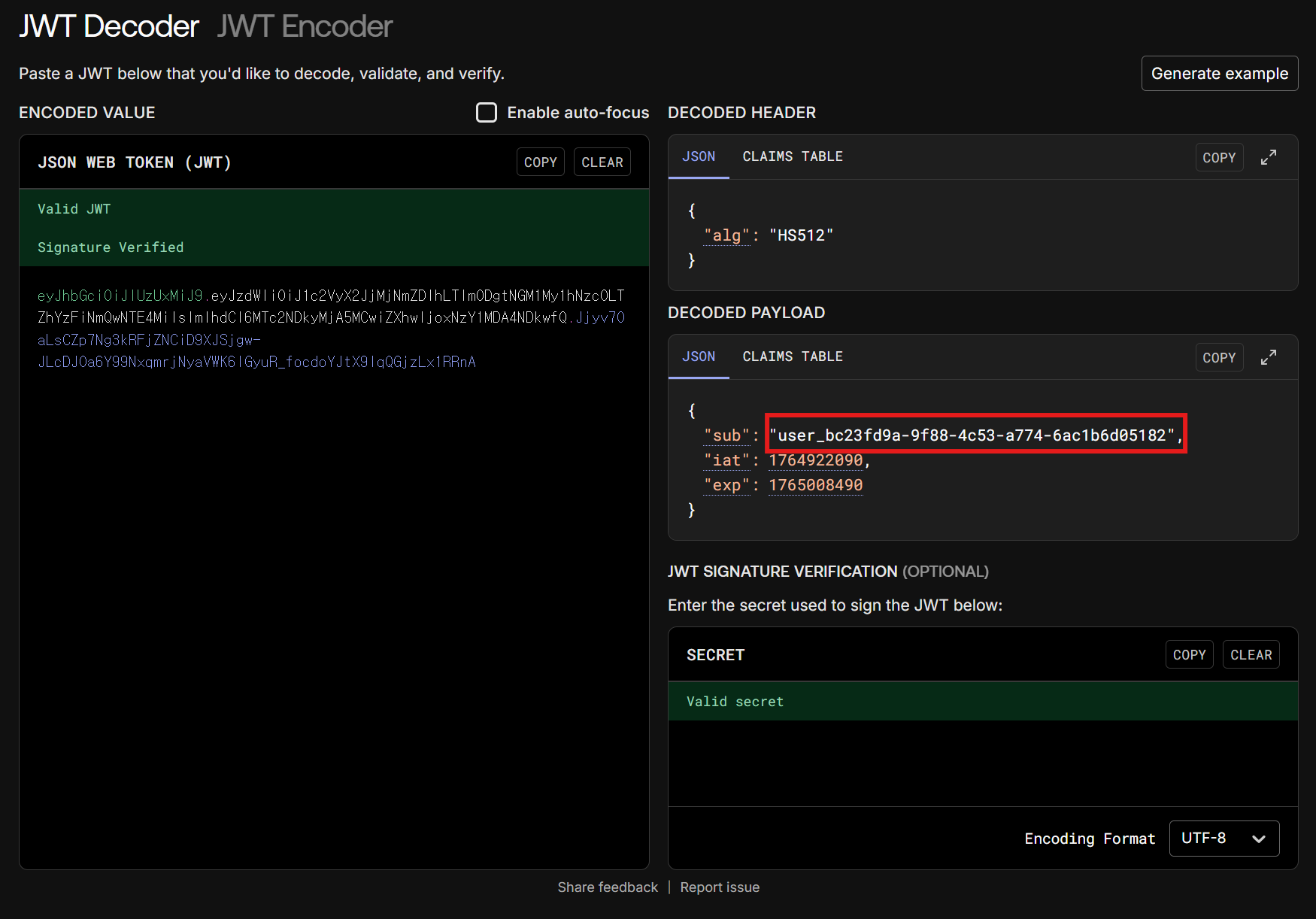
위처럼 난수를 서명과 인증에 사용하면 설령 서명 키값이 노출되었다고 해도, 특정 유저 ID를 알아낼 방법이 거의 없다시피 합니다. 어디서부터 어디까지 돌려봐야할까요? 000000000000000000000000 부터 zzzzzzzzzzzzzzzzzzzzzzzz 까지? 100% 안전하다고는 할 수 없지만, 아주 어려워질 것입니다.
UUID는 128비트로 총 2^128 가지 (340,282,366,920,938,463,463,374,607,431,768,211,456 가지) 경우의 수를 가집니다. UUID가 겹칠 확률은 0.00000000006%로 이는 인간이 매년 하늘에서 떨어지는 운석에 맞을 확률과 같다고 합니다. 출처
왜 그냥 PK를 난수로 만들지 않는가?
그럼 그냥 PK를 정수 Auto Increment로 하지말고 UUID로 하면 간단히 해결되지 않을까요? 해결되긴 하는데 심각한 성능 문제가 동반됩니다. 이는 데이터베이스로 사용하는 MySQL의 스토리지 엔진인 InnoDB의 동작과 관련이 있습니다.
InnoDB는 데이터를 실제 하드디스크 혹은 SSD에 쓰고/읽는 역할을 합니다. 특히 데이터를 저장할 때 클러스터드 인덱스(Clustered Index)라는 방식을 사용합니다.
클러스터드 인덱스(Clustered Index)란 테이블의 데이터를 PK(Primary Key) 값에 대한 인덱스의 리프 노드에 각 행에 대응하는 실제 값을 저장하는 방식입니다. PK 기준의 인덱스이기 때문에 PK를 기준으로 정렬된 B+ Tree 구조를 항상 유지합니다.
UUID와 클러스터드 인덱스의 궁합 문제
PK가 1, 2, 3, 4, ... 처럼 순차 증가한다면 새로운 레코드(데이터)는 항상 B+Tree의 맨 끝에 추가됩니다. 이는 일반 입력 중에는 디스크 페이지 split(페이지 중간에 데이터가 들어가 페이지가 꽉 차서 페이지가 나뉘는 현상) 발생이 거의 없도록 하고, 캐싱 효율도 좋습니다. 이 때문에 PK의 Auto Increment 옵션은 MySQL INSERT 성능 최적화 등에 꼭 등장합니다.
하지만 UUID는 "고르게 분포된 난수"입니다. 즉, 새로 들어오는 값이 B+Tree의 아무 위치에나 들어갈 수 있다는 뜻입니다. 중간에 자꾸 넣다보면 페이지 split이 자주 발생하고, 기존 데이터를 재배치하면서 디스크 I/O가 폭증합니다.
또한 PK 인덱스 크기가 증가되는 것도 큰 문제가 됩니다. 인덱스가 커지면 메모리에 담을 수 있는 양이 줄어들고, 그러면 결론적으로 더 많은 페이지를 읽어야 합니다. 이런 문제 때문에 PK는 가능한 한 작은 값을 선택하도록 권장됩니다.
해결책: PK는 두고 UUID 기반 공개 ID를 따로 만들기
테이블의 PK를 Auto Increment로 유지하고, 대신 외부 노출용 난수 ID를 추가하여, 이를 통해서만 상호작용 할 수 있도록 개선하면, 두 가지 문제를 모두 해결할 수 있습니다. 난수 ID에 들어가는 유니크 인덱스 추가에 대한 오버헤드는 여전히 존재합니다만, 성능에 가장 큰 영향을 주는 PK는 지킬 수 있습니다.
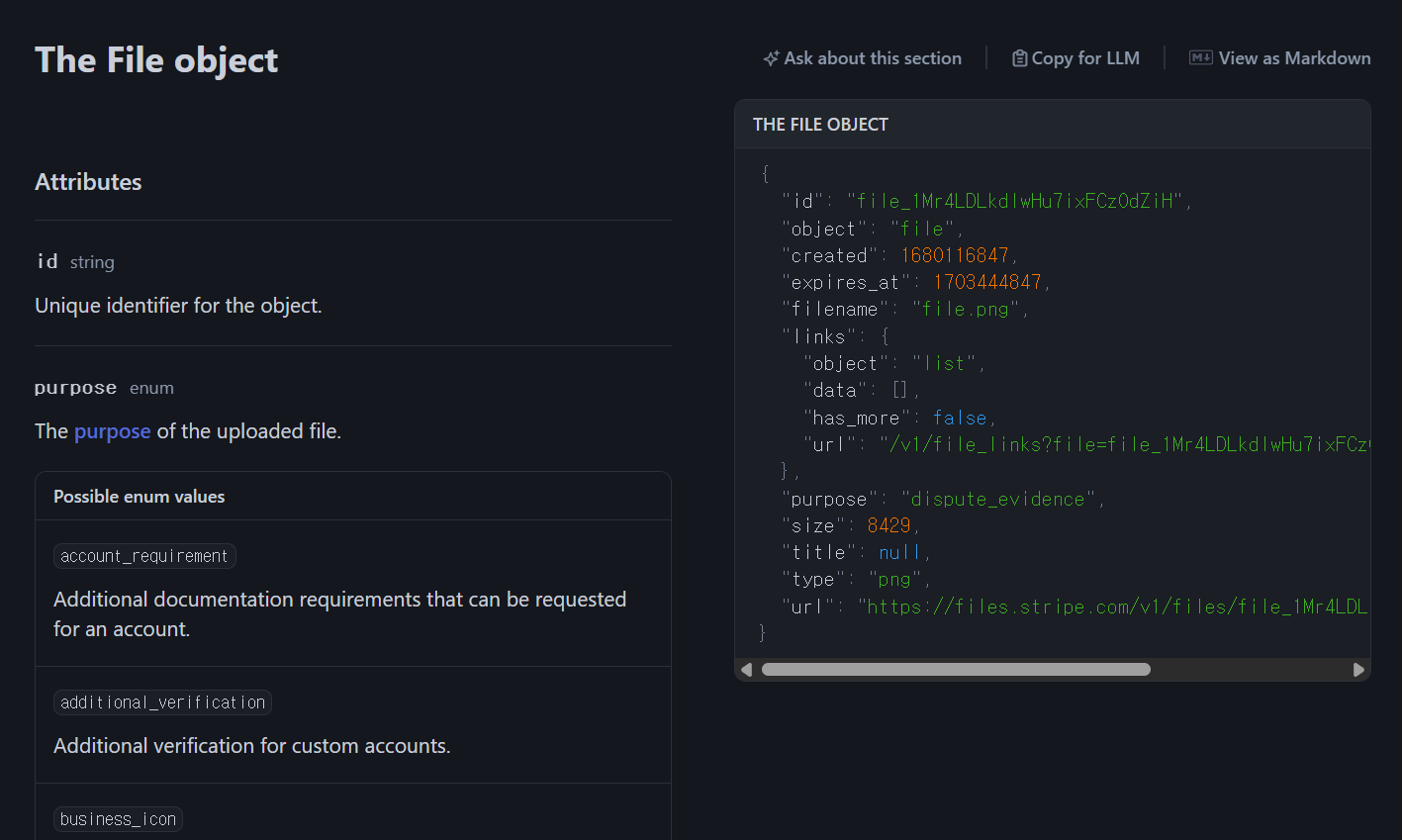
위는 API 설계의 좋은 예시로 자주 언급되는 Stripe의 API 명세서 예시입니다. 보시면 "id" 필드에 "file_1Mr4LD..." 처럼 접두사 + 난수로 표현되어 있는 것을 확인할 수 있습니다. 이러한 형식을 차용하여 user_ 접두사와 UUID를 합쳐 public_id라는 칼럼을 추가하도록 해주었습니다.
User
// 진짜 PK
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "user_id")
private Integer id;
// 외부 공개용 ID
@Column(nullable = false, unique = true, updatable = false)
private String publicId;
// User 엔티티 생성 함수
public static User create(String username, String email, String oauthProvider, String oauthId) {
return User.builder()
.username(username)
.email(email)
.oauthProvider(oauthProvider)
.oauthId(oauthId)
.publicId("user_" + UUID.randomUUID())
.build();
}AuthService
private String getAccessToken(HttpServletResponse response, User user) {
String accessToken = jwtUtil.createAccessToken(user.getPublicId());
String refreshToken = jwtUtil.createRefreshToken(user.getPublicId());
storeRefreshTokenInCookie(response, refreshToken);
return accessToken;
}JWT 발급에도 해당 public_id를 사용하도록 수정하였습니다.
수정된 CustomUserDetailsService
@Service
@RequiredArgsConstructor
@Slf4j
public class CustomUserDetailsService implements UserDetailsService {
private final UserRepository userRepository;
@Override
public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {
try {
return CustomUserDetails.of(userRepository.findByPublicId(username).orElseThrow(() -> new UsernameNotFoundException("해당하는 ID의 유저가 존재하지 않습니다.")));
} catch (Exception e) {
log.debug("Username not found", e);
throw new UsernameNotFoundException("Username not found");
}
}
}토큰으로 User 데이터를 검증해 불러오는 부분을 findById() 에서 findByPublicId()로 수정하였습니다.
수정된 응답
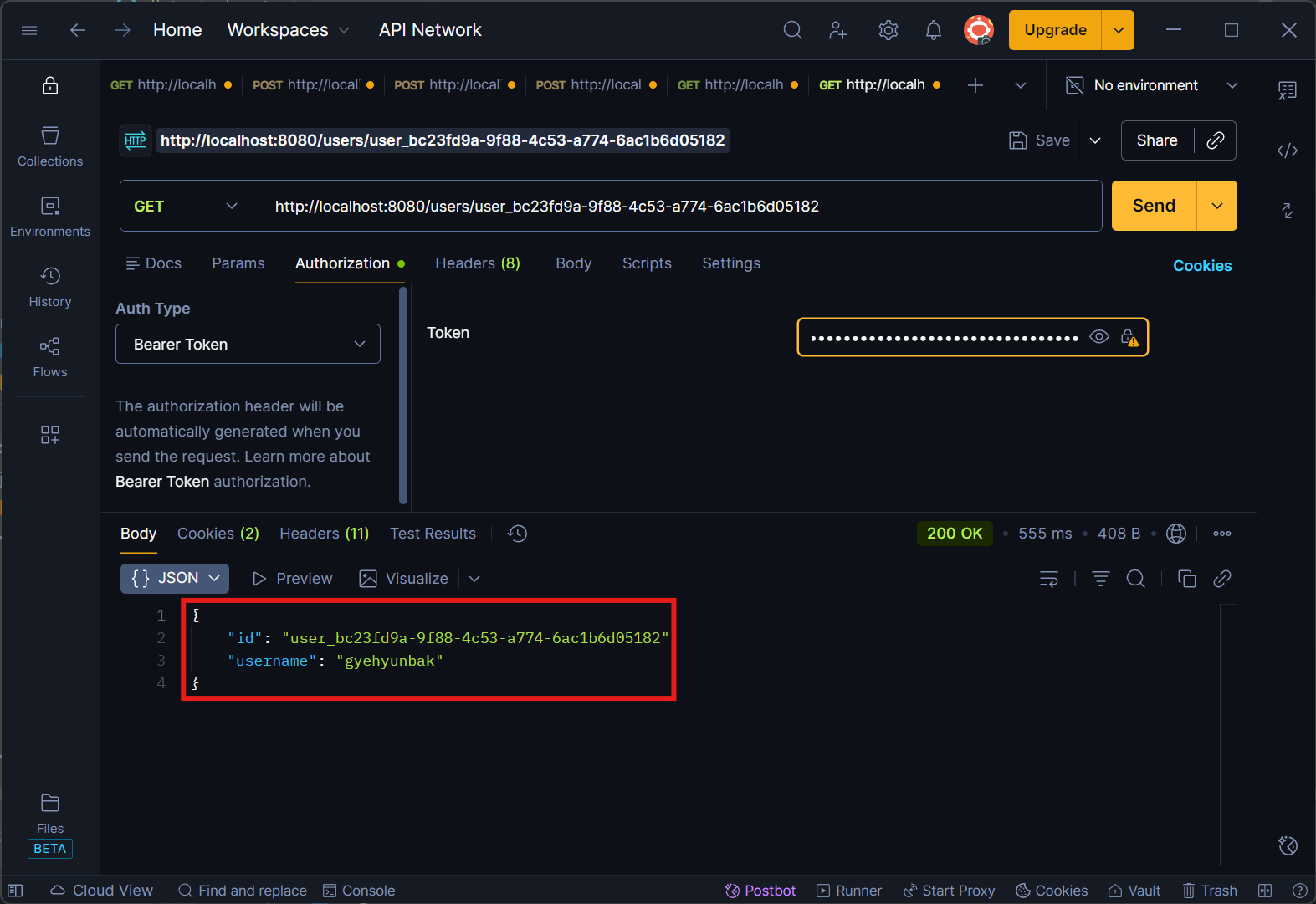
난수 ID로 조회를 요청하며, 동시에 응답 데이터에도 난수 ID를 반환하도록 수정되었습니다.
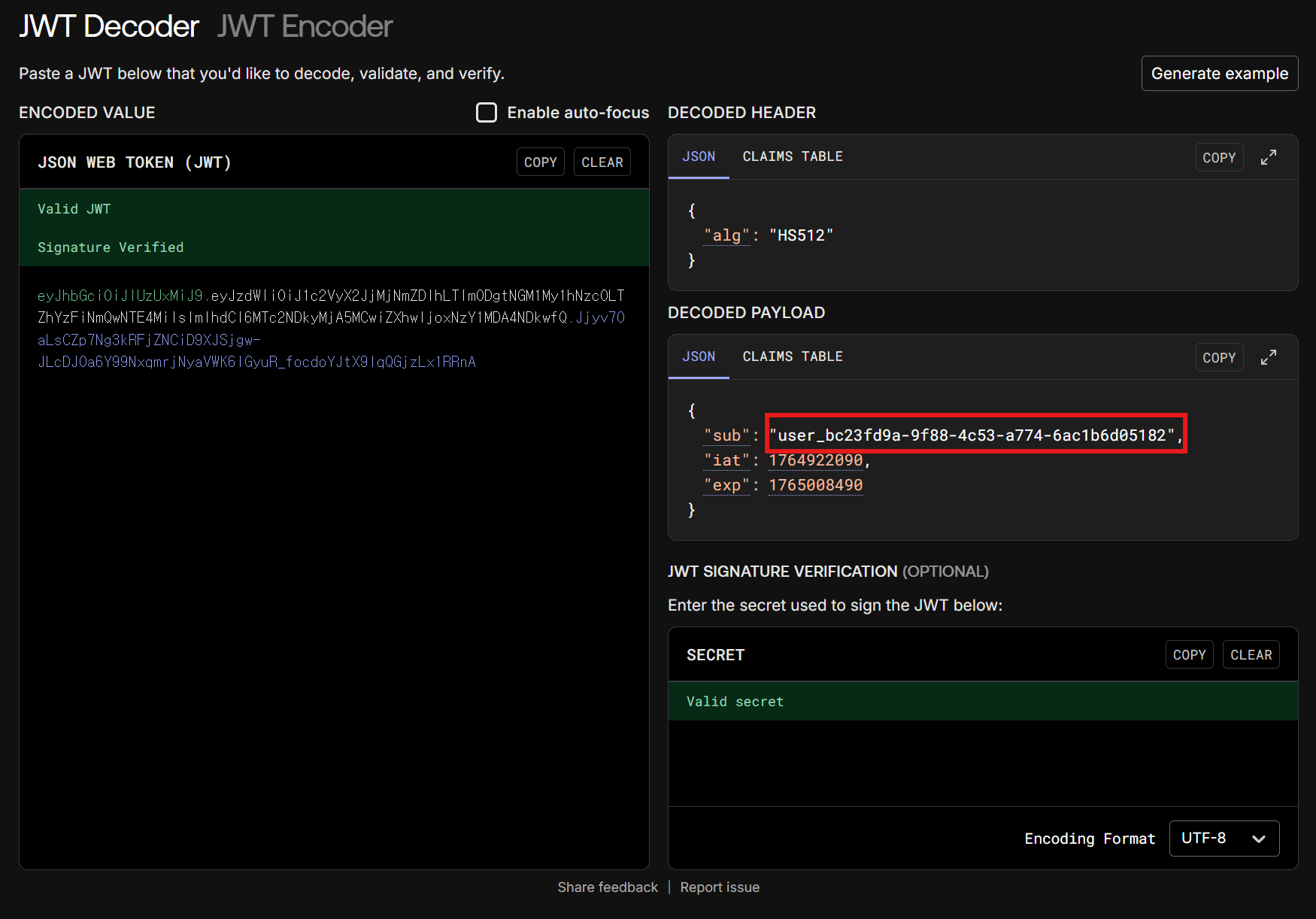
AccessToken 내에도 난수 ID가 적용되었습니다. 이제 토큰 키 값이 탈취되어도 순식간에 대량 유출로는 이어지지 않을 것입니다.
NanoID를 통해 가독성 높이기
현재 publicId 생성에 이용하는 UUID v4는 충돌면에서 안정적이지만 36자(36byte)나 된다는 단점을 가지고 있습니다. 때문에 URL에 포함하거나 로그에 찍힐 때 사람이 읽기 굉장히 어렵게 만듭니다.
NanoID는 UUID v4와 비슷한 고유 식별자 생성기로 UUID v4 보다 짧은 21자(21byte) 길이를 기본으로 가지면서도 비슷한 충돌 안정성을 보장합니다. (다만, 21자보다 줄이게 되면 위험!)
기존 UUID v4:
http://localhost:8080/users/user_bc23fd9a-9f88-4c53-a774-6ac1b6d05182
NanoID 적용 후:
http://localhost:8080/users/user_V1StGXR8_Z5jdHi6B-myT또한 NanoID는 URL 친화적인 고유 식별자 생성을 목적으로 하기 때문에 URL-Safe한 문자만 사용합니다. 식별자 길이가 너무 길다는 현재 문제에 잘 들어맞는 솔루션이기 때문에 publicId 생성을 NanoID로 변경해보았습니다.
의존성 추가
build.gradle
// nanoid
implementation 'com.aventrix.jnanoid:jnanoid:2.0.0'기존 코드 변경
기존 User.java
public static User create(String username, String email, String oauthProvider, String oauthId) {
return User.builder()
.username(username)
.email(email)
.oauthProvider(oauthProvider)
.oauthId(oauthId)
.publicId("user_" + UUID.randomUUID())
.build();
}수정된 User.java
public static User create(String username, String email, String oauthProvider, String oauthId) {
return User.builder()
.username(username)
.email(email)
.oauthProvider(oauthProvider)
.oauthId(oauthId)
.publicId("user_" + NanoIdUtils.randomNanoId())
.build();
}UUID.randomUUID() 부분을 NanoIdUtils.randomNanoId() 로 변경하였습니다. 기본값인 21자 NanoID가 생성되어 적용됩니다.
결과
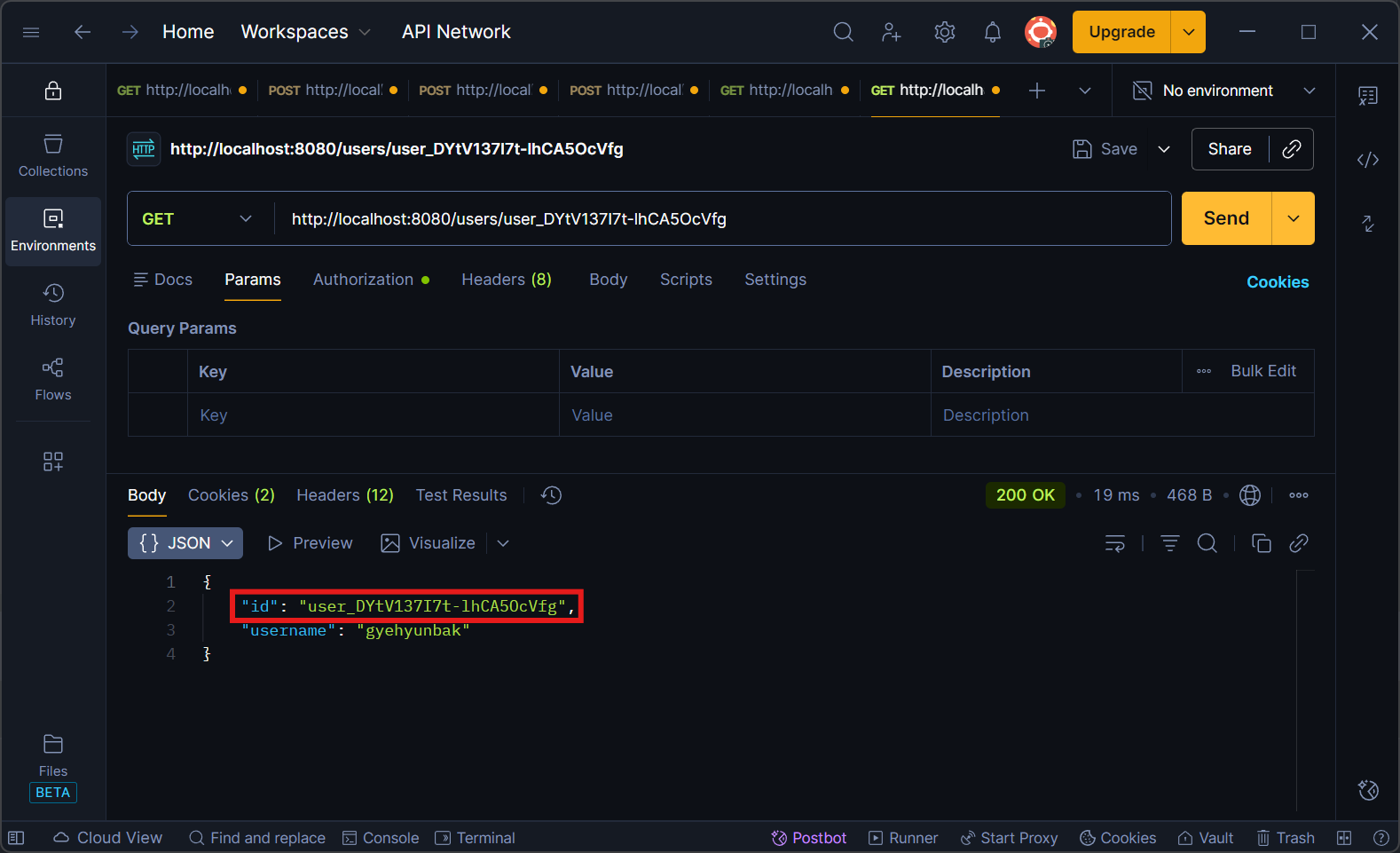
전보다 훨씬 짧아져서 보기 편해졌습니다.
Auto-Increment vs UUID vs 이중ID(Auto-Increment + Random Public ID) 성능 비교
MySQL
PostgreSQL
마치며
해당 코드를 여기에서 확인하실 수 있습니다.
참고 자료
