대충 테이블이 객체가 되고 있는 그림
들어가며
이번 시간에는 Spring과 함께 많이 사용되는 ORM 기술인 JPA(와 그 구현체인 Hibernate)가 무엇인지, 순수 JDBC를 이용한 코드와의 차이와 함께 알아보겠습니다.
📣 해당 글은 Hibernate 6 버전 문서를 기반으로 하고 있습니다.
예제 프로젝트 설정
직접 해보실 분들을 위해서 예제 프로젝트의 설정을 남겨둡니다. 이 부분은 스킵하셔도 괜찮습니다.
- 예제 프로젝트는 Java 17, Gradle 프로젝트입니다.
- DB로 H2 데이터베이스를 사용합니다.
- 종속성으로 추가한 것은 Lombok, Hibernate, h2database입니다.
- Hibernate를 이용하기 위해서는 src/main/resources/META-INF 에 persistence.xml 이라는 설정 파일이 필요합니다.
build.gradle
plugins {
id 'java'
}
group = 'org.example'
version = '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
// Hibernate
implementation 'org.hibernate.orm:hibernate-core:6.4.2.Final'
// H2
runtimeOnly 'com.h2database:h2:2.2.224'
// Lombok
compileOnly("org.projectlombok:lombok:1.18.38")
annotationProcessor("org.projectlombok:lombok:1.18.38")
// Lombok Test
testCompileOnly("org.projectlombok:lombok:1.18.38")
testAnnotationProcessor("org.projectlombok:lombok:1.18.38")
testImplementation platform('org.junit:junit-bom:5.9.1')
testImplementation 'org.junit.jupiter:junit-jupiter'
}
test {
useJUnitPlatform()
}persistence.xml
<persistence xmlns="https://jakarta.ee/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://jakarta.ee/xml/ns/persistence https://jakarta.ee/xml/ns/persistence/persistence_3_0.xsd"
version="3.0">
<persistence-unit name="hello">
<class>org.example.domain.Member</class>
<properties>
<!-- H2 in-memory database -->
<property name="jakarta.persistence.jdbc.driver" value="org.h2.Driver"/>
<property name="jakarta.persistence.jdbc.url" value="jdbc:h2:tcp://localhost/~/test"/>
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/>
<!-- Credentials -->
<property name="jakarta.persistence.jdbc.user" value="sa"/>
<property name="jakarta.persistence.jdbc.password" value=""/>
<!-- display SQL in console -->
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="hibernate.highlight_sql" value="true"/>
<!-- JPA Options -->
<property name="hibernate.hbm2ddl.auto" value="create" />
</properties>
</persistence-unit>
</persistence>자신의 프로젝트 이름과 H2 데이터베이스 URL 등 설정 값에 유의하세요.
JDBC의 문제점과 ORM
웹 애플리케이션을 만들면서 데이터베이스와의 상호작용은 뗄래야 뗄 수 없습니다. 자바를 통해 데이터베이스에 접근하기 위해서는 JDBC API를 사용해야 합니다.
ORM에 대해 알아보기 전에, 우선 순수하게 JDBC를 이용해서 데이터베이스를 이용하는 코드를 살펴보겠습니다.
예제를 위해 정말 간단한 클래스와 테이블을 준비합니다.
CREATE TABLE member (
member_id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(255)
);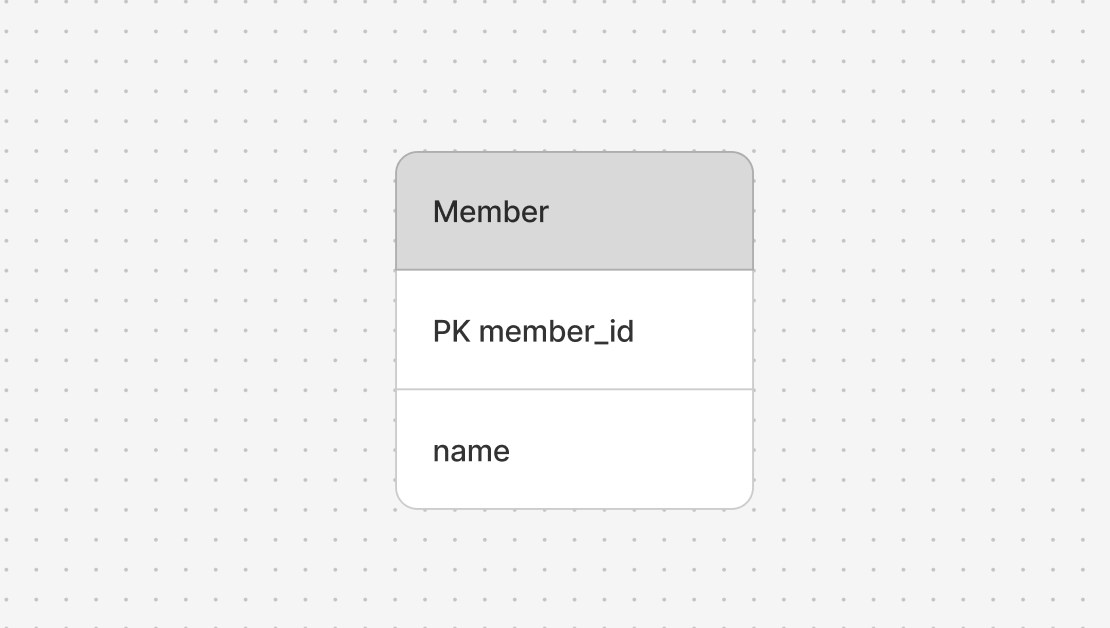
간단히 PK 값과 이름만 가지고 있습니다. 기본키는 데이터베이스에서 자동으로 넣도록 설정하였습니다. 이제 코딩을 해야하는데, 자바는 객체 지향 언어인만큼 해당 테이블과 매핑될 클래스가 필요합니다.
Member
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
public class Member {
private Long id;
private String name;
}이제 Member 데이터에 대한 CRUD 작업을 담당할 MemberRepository 인터페이스를 정의합니다.
MemberRepository
public interface MemberRepository {
void save(Member member);
List<Member> findAll();
}JDBC를 이용하는 MemberRepository 구현체를 구현합니다.
MemberJdbcRepository
public class MemberJdbcRepository implements MemberRepository {
static final String URL = "jdbc:h2:tcp://localhost/~/test";
static final String USERNAME = "sa";
static final String PASSWORD = "";
@Override
public void save(Member member) {
String sql = "INSERT INTO member (name) VALUES (?)";
try (
Connection conn = DriverManager.getConnection(URL, USERNAME, PASSWORD);
PreparedStatement pstmt = conn.prepareStatement(sql)
) {
pstmt.setString(1, member.getName());
pstmt.executeUpdate();
} catch (SQLException e) {
throw new RuntimeException("멤버 저장 실패", e);
}
}
@Override
public List<Member> findAll() {
String sql = "SELECT member_id, name FROM member";
List<Member> members = new ArrayList<>();
try (
Connection conn = DriverManager.getConnection(URL, USERNAME, PASSWORD);
PreparedStatement pstmt = conn.prepareStatement(sql);
ResultSet rs = pstmt.executeQuery();
) {
while (rs.next()) {
Long id = rs.getLong("member_id");
String name = rs.getString("name");
members.add(new Member(id, name));
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
return members;
}
}가능한 한 단순하게 준비하려고 했습니다. try-with-resource를 통해 JDBC와의 연결 리소스를 자동으로 닫도록 구현했습니다. JDBC의 자세한 사용법은 생략합니다
Main 클래스의 main() 메서드에서 다음과 같이 테스트해보았습니다.
Main
public class Main {
public static void main(String[] args) {
MemberRepository memberRepository = new MemberJdbcRepository();
memberRepository.save(new Member(null, "박계현"));
List<Member> result = memberRepository.findAll();
for (Member member : result) {
System.out.println(member.getName());
}
}
}테스트 결과
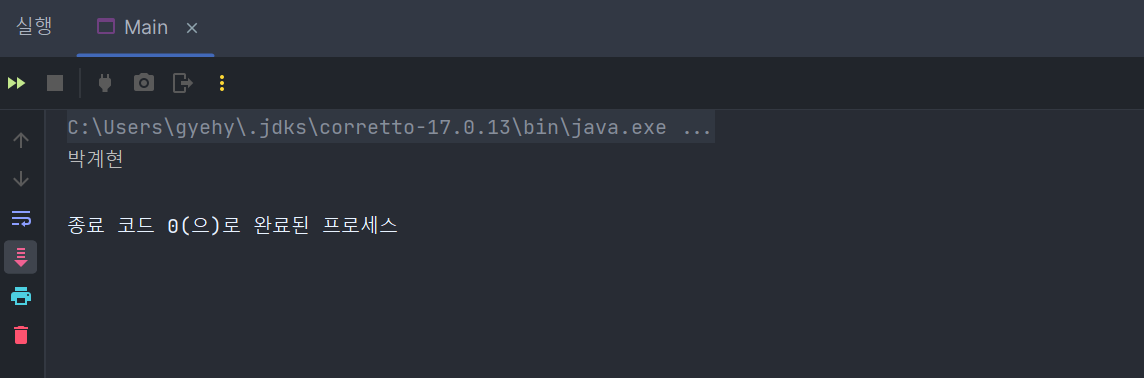
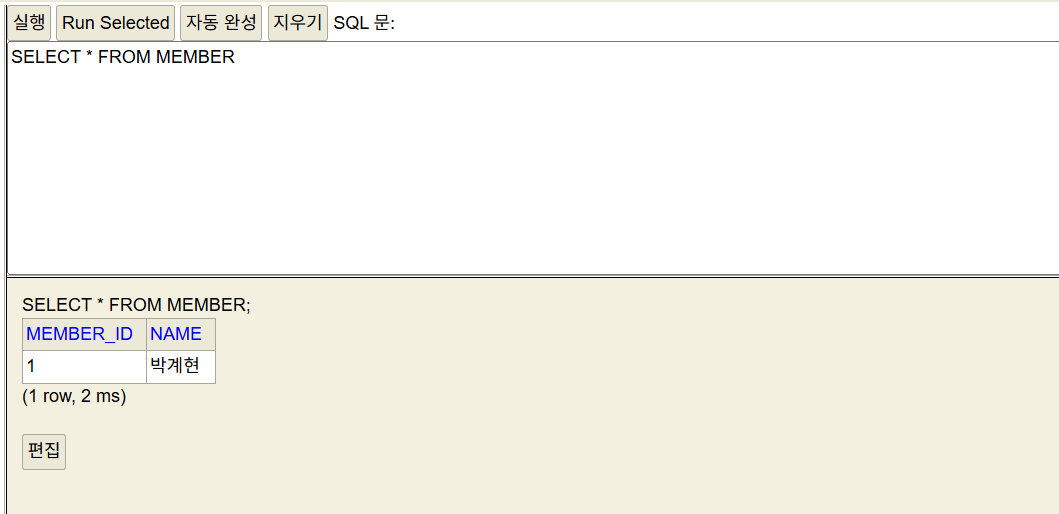
새 멤버를 데이터베이스에 insert 하고 조회까지 되는 것이 확인됩니다.
다시 코드를 살펴보면, JDBC를 사용하는 경우 반복되는 구조가 있습니다.
- DB와의 연결을 만들고
- 직접 작성한 SQL을 전달하고
- 결과를 받아와 클래스로 매핑하는
구조를 가지고 있습니다. 이런 방식으로도 무리 없이 개발을 할 수 있지만, 많은 선배 개발자 분들이 이러한 구조에서 불편해한 문제점이 몇 가지 있습니다.
첫째, SQL과 자바 코드의 결합
String sql = "SELECT member_id, name FROM member";위에서 볼 수 있듯이 데이터 접근을 위해 필요한 모든 SQL을 개발자가 작성을 합니다. SQL과 자바 코드가 강하게 결합되어 있습니다. 이러한 SQL 직접 작성이 필요한 경우도 있지만, 이러한 코드가 많아지면, 필드 이름 변경 등 데이터베이스에서 변화가 생기면 이를 반영하기 위해 수정해야할 부분이 아주 많아집니다. 심지어 SQL은 문자열이기 때문에 컴파일 타임에 잡을 수도 없습니다(...). 한 군데라도 놓치면 운영 중에 버그가 발생하게 됩니다.
둘째, 객체-관계 불일치 문제(패러다임 불일치)
while (rs.next()) {
Long id = rs.getLong("member_id");
String name = rs.getString("name");
members.add(new Member(id, name));
}또 다른 문제는, 자바에서의 객체와 관계형 데이터베이스에서의 테이블(엔티티)이 서로 다르다는 것입니다. 이거는 두 가지를 의미합니다. 첫째는 데이터베이스에서 가져온 테이블 엔티티를 매번 코드에서 정의한 클래스에 매핑을 해줘야하는데, 이게 양이 꽤 많습니다.
둘째로 연관 관계가 들어갔을 때 모양이 완전히 달라집니다.
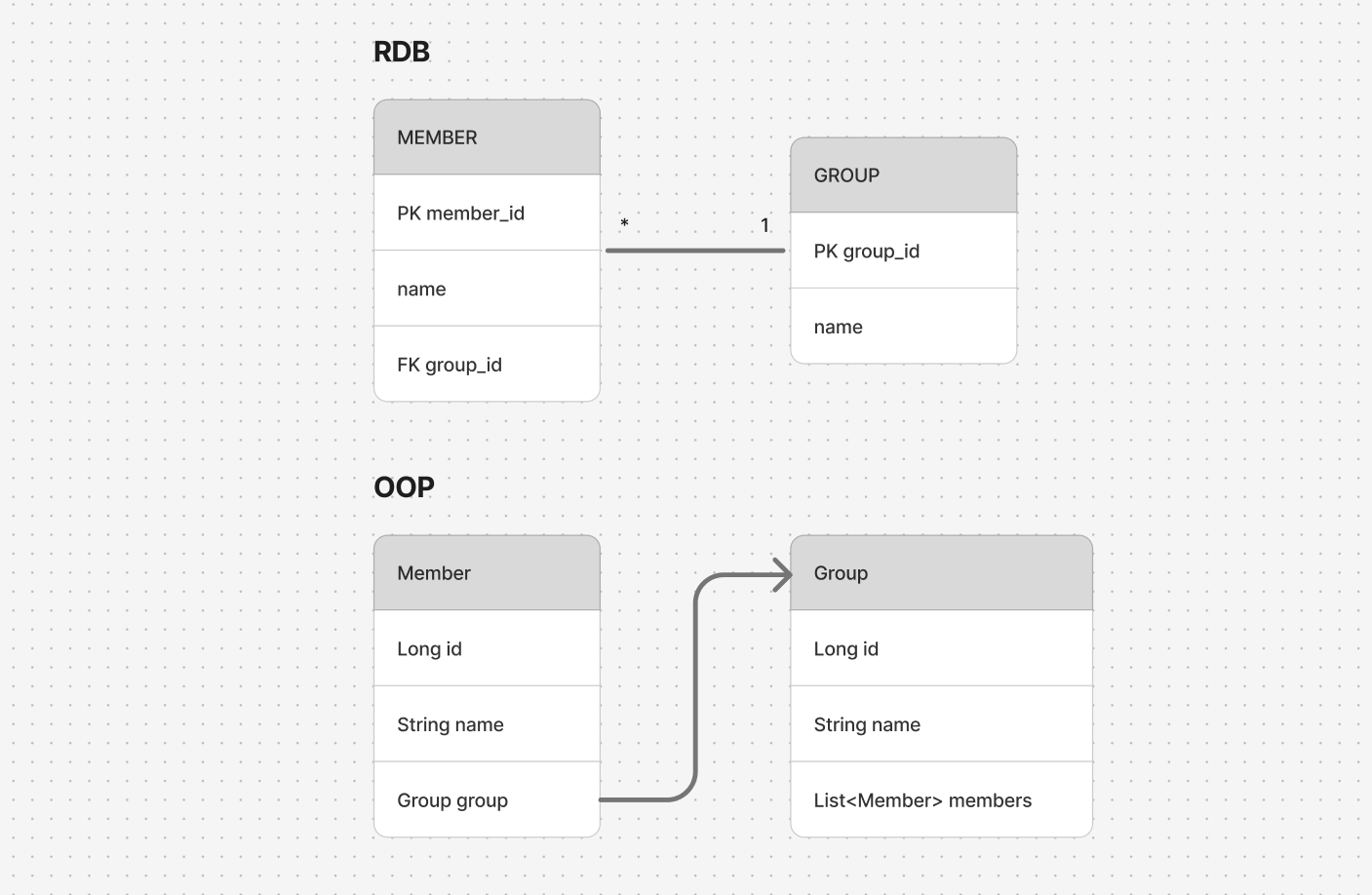
RDB는 연관 관계가 외래키와 테이블 조인으로 구현되어 있으며, 객체 지향 프로그래밍에서는 참조를 통해 구현합니다. JDBC만 이용을 하면 객체 설계를 RDB의 구조에 어느정도 따라야합니다.
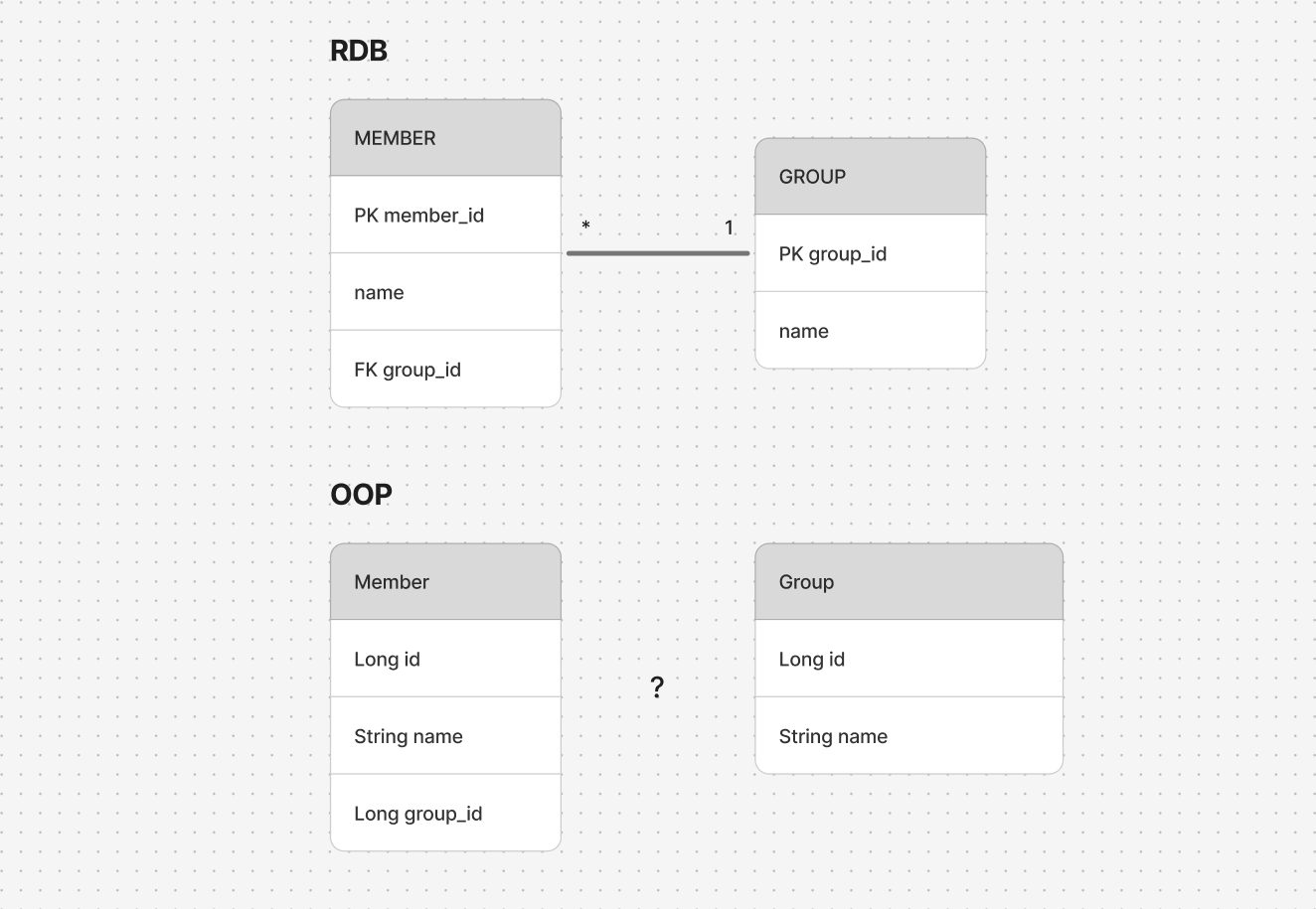
결국 객체가 RDB 테이블처럼 외래 키를 가지고 있게 됩니다. 비즈니스 로직을 작성하는 입장에서는 해당 객체가 객체로서의 기능이 많이 모자라게 되고, 객체에 대한 신뢰가 떨어지게 되며, 객체 지향과는 별 상관없는 코드를 작성하게 될 가능성이 있습니다.
ORM
위 두 가지가 가장 크게 와닿는 문제인 것 같습니다. 이 외에는 비즈니스 로직과 관련 없는 코드가 많아진다(리소스 관리 등) 정도인 것 같습니다(이 부분은 Spring의 JDBC Template으로 어느정도 해결 가능합니다). 이러한 문제점도 프로젝트의 종류에 따라 무시할 수 있는 수준일 수 있습니다.
하지만 이러한 문제가 무시하기 힘들고, 뭔가 해결책이 필요한 경우에 놓여있다면, 그걸 위해 등장한 것이 ORM(Object Relational Mapping) 기술입니다.
ORM은 말그대로 위에서 본 객체와 관계(Entity) 사이 매핑을 위한 기술입니다.
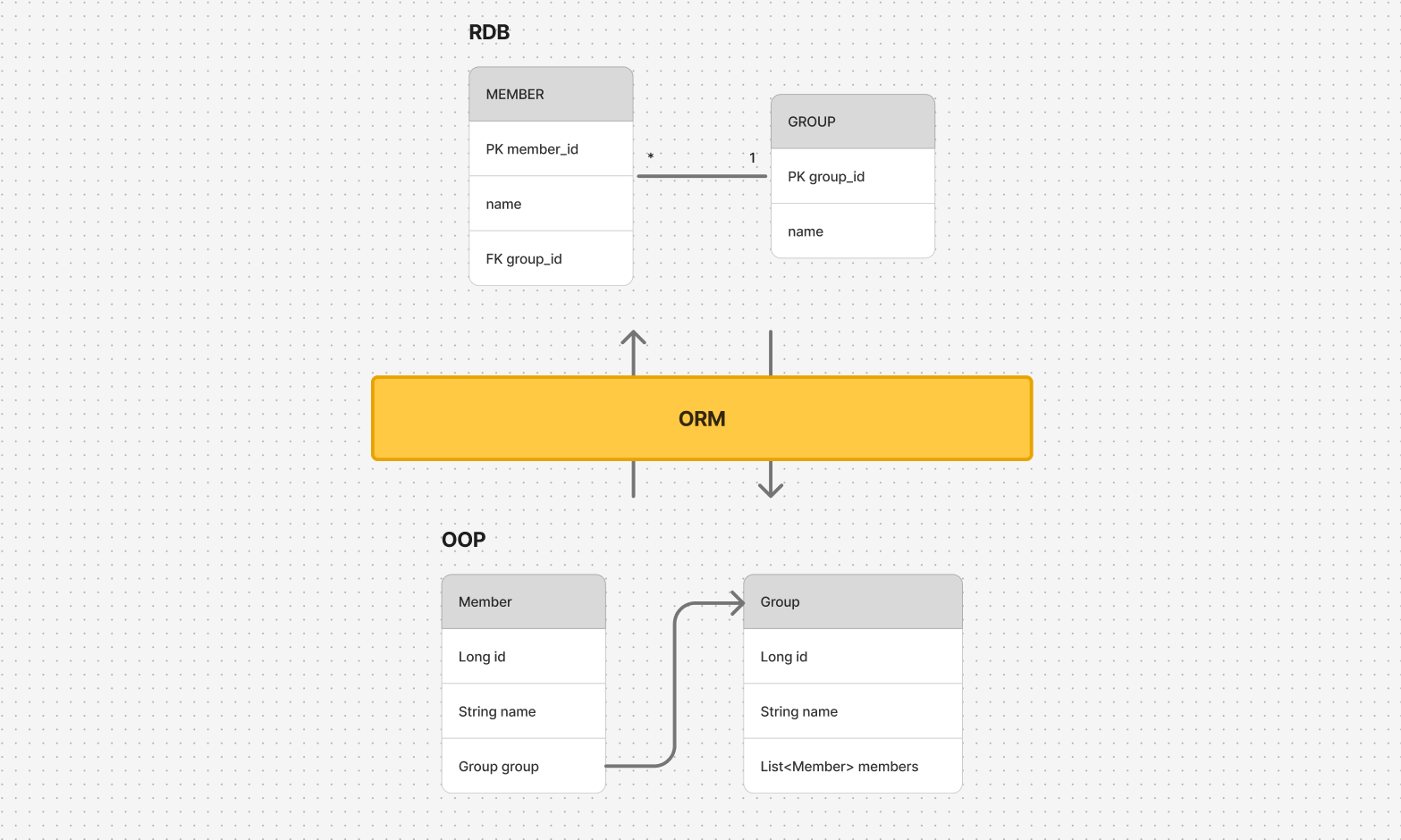
즉, 위 작업을 해줄 수 있는 기술입니다. 객체는 객체대로, 관계형 데이터베이스는 관계형 데이터베이스대로 설계할 수 있도록 해줍니다. 이후 ORM을 이용해 위 예제를 다시 작성하는 것을 보여드리겠습니다.
JPA와 Hibernate
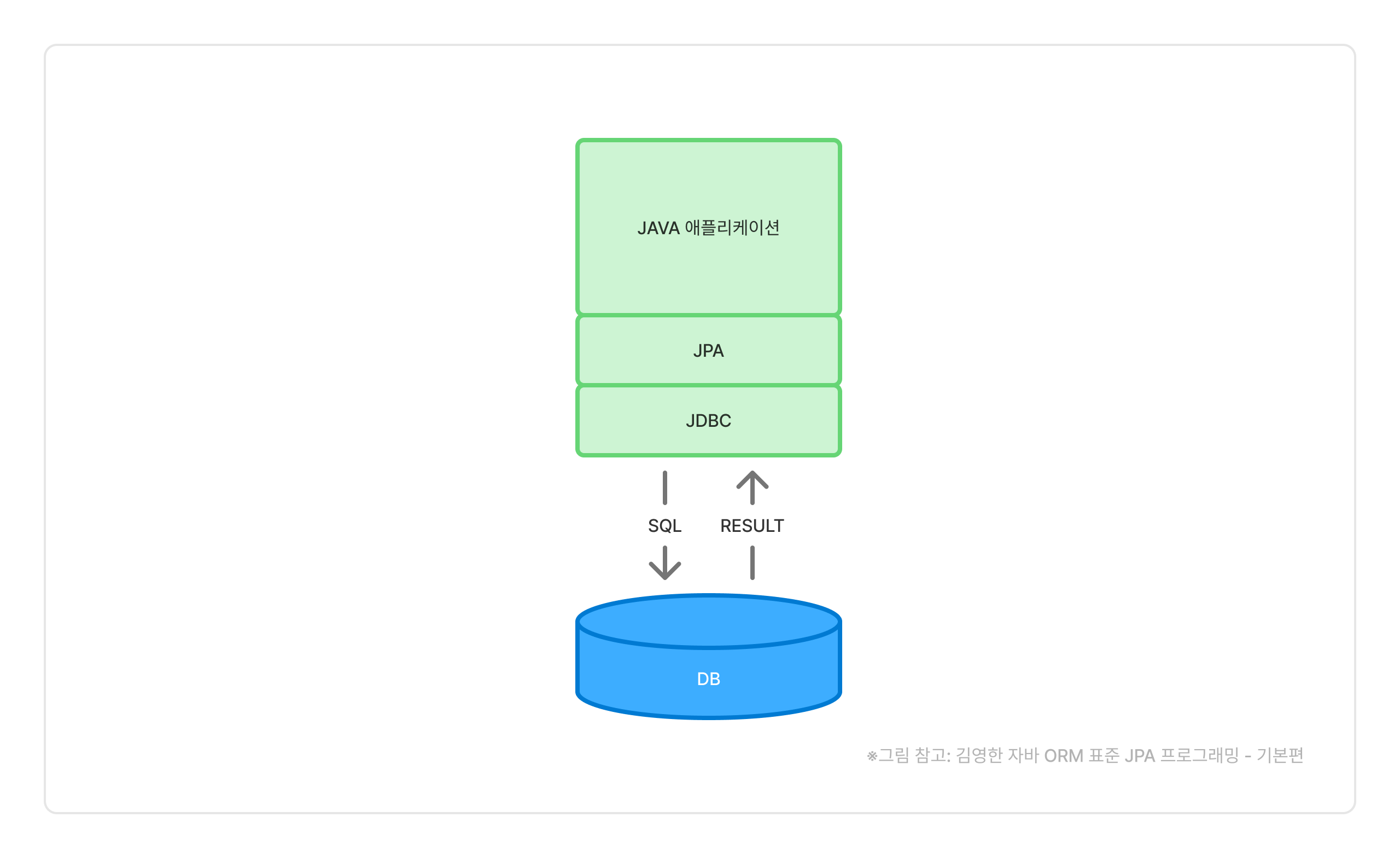
ORM은 하나의 기법이고 이를 자바에서 사용하기 위해 마련한 표준 API가 바로 JPA(Java/Jakarta Persistence API)입니다. JPA는 내부적으로 JDBC API를 사용해서 데이터베이스와 통신합니다. 그러니 우리가 쓴 자바 애플리케이션과 JDBC 사이 들어온 하나의 추상 레이어라고 생각할 수 있습니다.
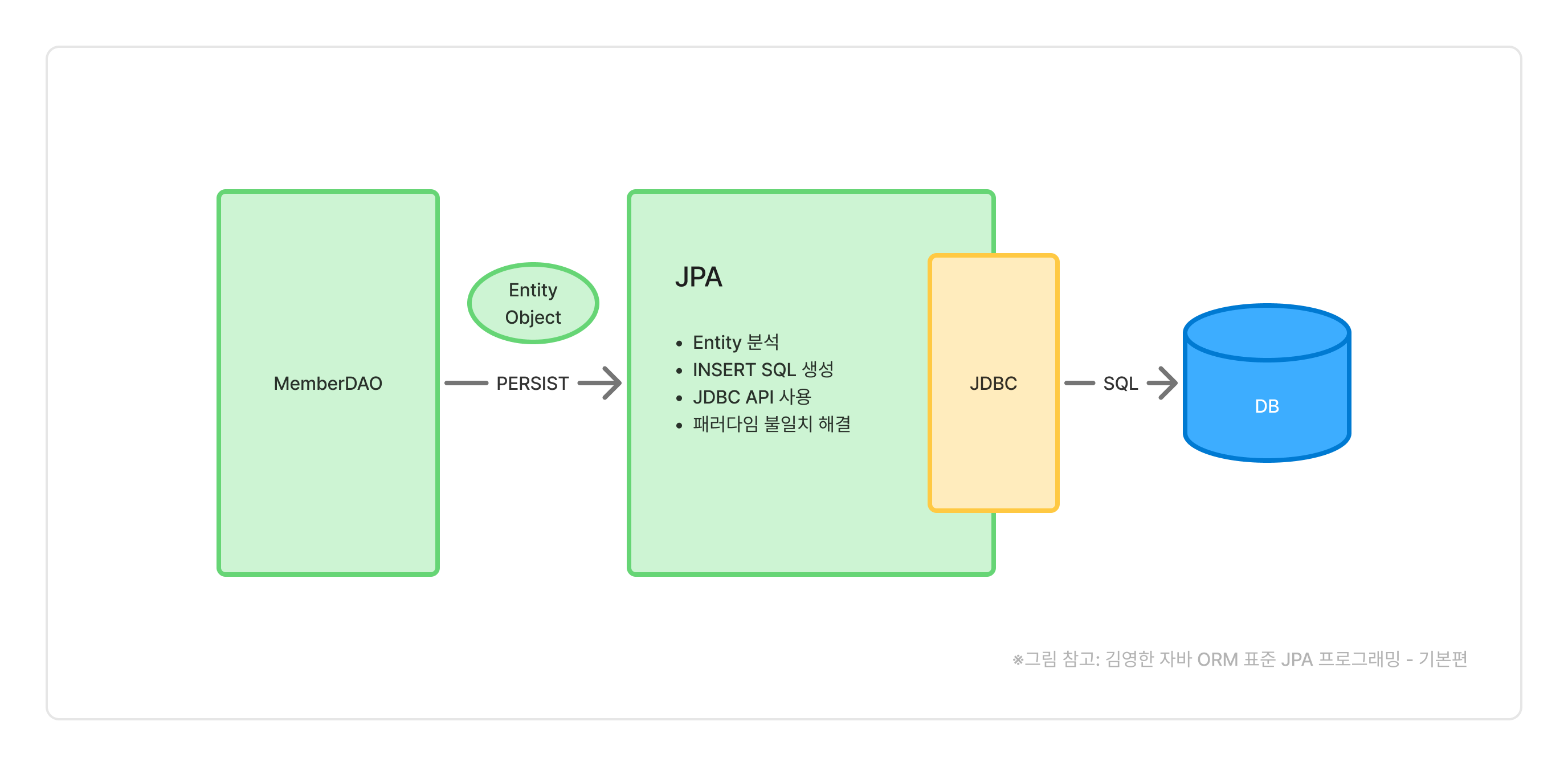
JPA를 통해 데이터를 데이터베이스에 INSERT하는 과정을 살펴보면 JDBC를 사용하는 것과 차이가 있습니다. 우선 DAO(Repository등)를 통해 INSERT할 객체를 JPA에 넘겨줍니다. 여기 PERSIST라고 적혀있는데 지금은 영구히 저장하기 위한 액션이라고 이해하시면 됩니다. 그럼 JPA가 객체를 분석하고, 필요한 SQL를 생성하고, JDBC API를 이용해 DB에 저장하는 모든 과정을 자동으로 처리해줍니다. 이 과정에 관계형 데이터베이스와 객체 사이 패러다임 불일치도 해결해줍니다.
조회의 경우에도 find() 메서드를 이용하면 JPA가 적당한 SQL을 만들어 ResultSet으로 데이터를 받아오고, 그것을 다시 맞는 타입의 클래스(혹은 클래스 컬렉션)으로 변환하여 DAO에 반환해줍니다.
엔티티(Entity)
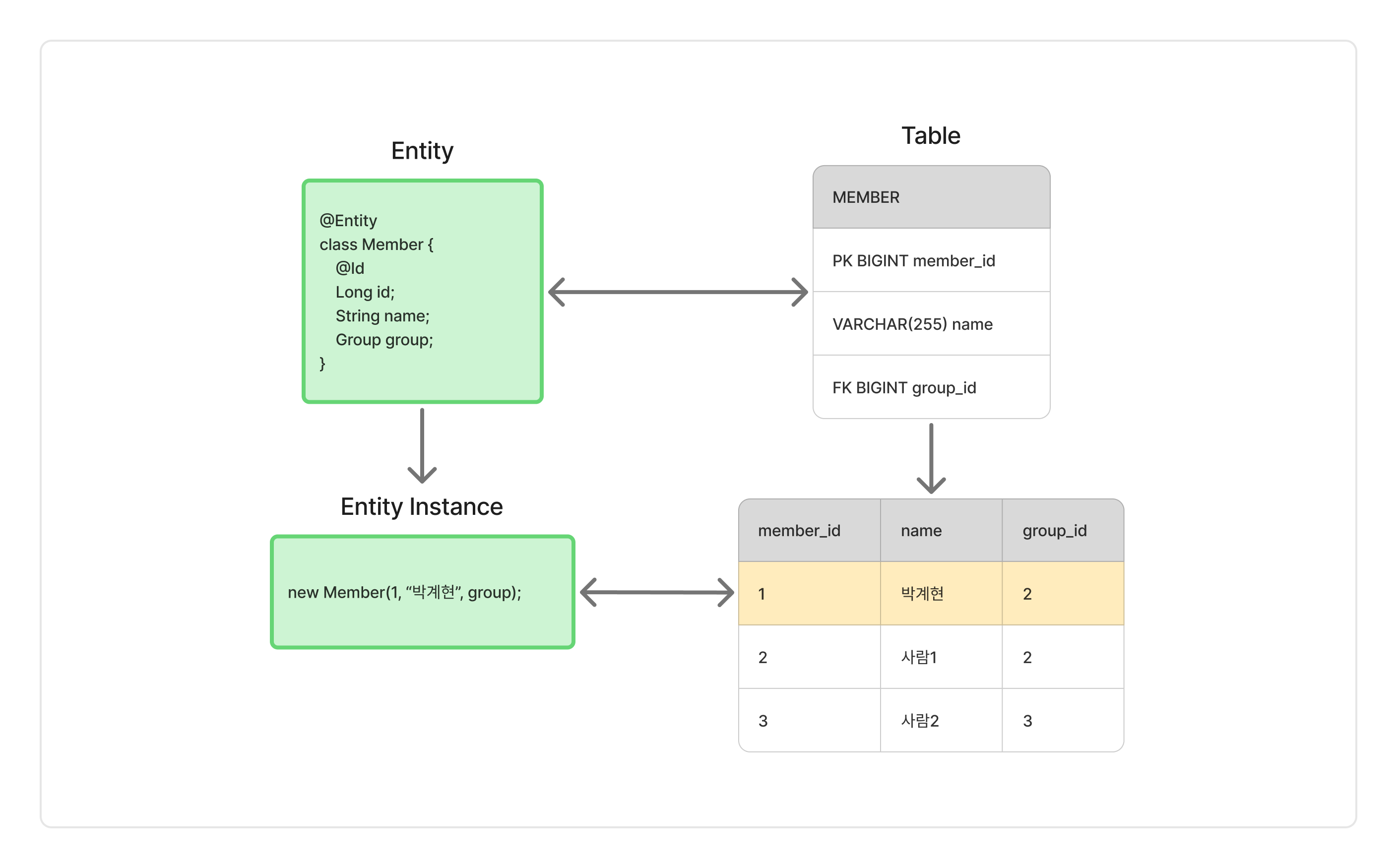
엔티티(Entity)라는 말이 등장했습니다. 엔티티는 자바에서의 클래스에 해당하며, 하나의 엔티티가 하나의 RDB 테이블을 표현합니다. 또한 각 엔티티 클래스의 인스턴스는 RDB 테이블에서 각 행을 의미합니다.
Hibernate
JPA는 말씀드렸다시피 API이기 때문에 이것에 대한 구현체가 필요합니다. 하이버네이트(Hibernate)는 JPA API의 오픈소스 구현체입니다. 사실, 하이버네이트가 먼저 나왔고, 그거 때문에 JPA 표준이 만들어졌지만, 아무튼 그렇습니다.
간단히 역사를 소개드리면, 예전에 JavaEE(현재 JakartaEE)에 EJB(Enterprise JavaBeans)가 있었고, 그 안에 Entity Bean(엔티티 빈)이 ORM 기술로 있었는데, 이게 매우 불편하고 성능도 안 나왔다고 합니다. 그러다 2001년에 Gavin King이 엔티티빈의 불편함을 해소한 오픈소스 Hibernate를 공개했고, 이것이 커뮤니티에 의해 자바의 비공식적인 표준으로 자리잡았습니다.
Java EE 진영에서도 공식 ORM 표준이 필요하다는 인식이 생겼고, Hibernate의 많은 부분을 차용해 설계하였습니다. 그렇게 JPA가 Java EE 5에서 처음 정의되었고, Hibernate는 JPA 구현체 중 하나가 되었습니다.
아무튼 지금은 ORM을 위한 JPA라는 인터페이스가 있고, 이를 구현한 Hibernate, EclipseLink, DataNucleus 등이 있는데, Hibernate가 가장 인기가 많다고 합니다.
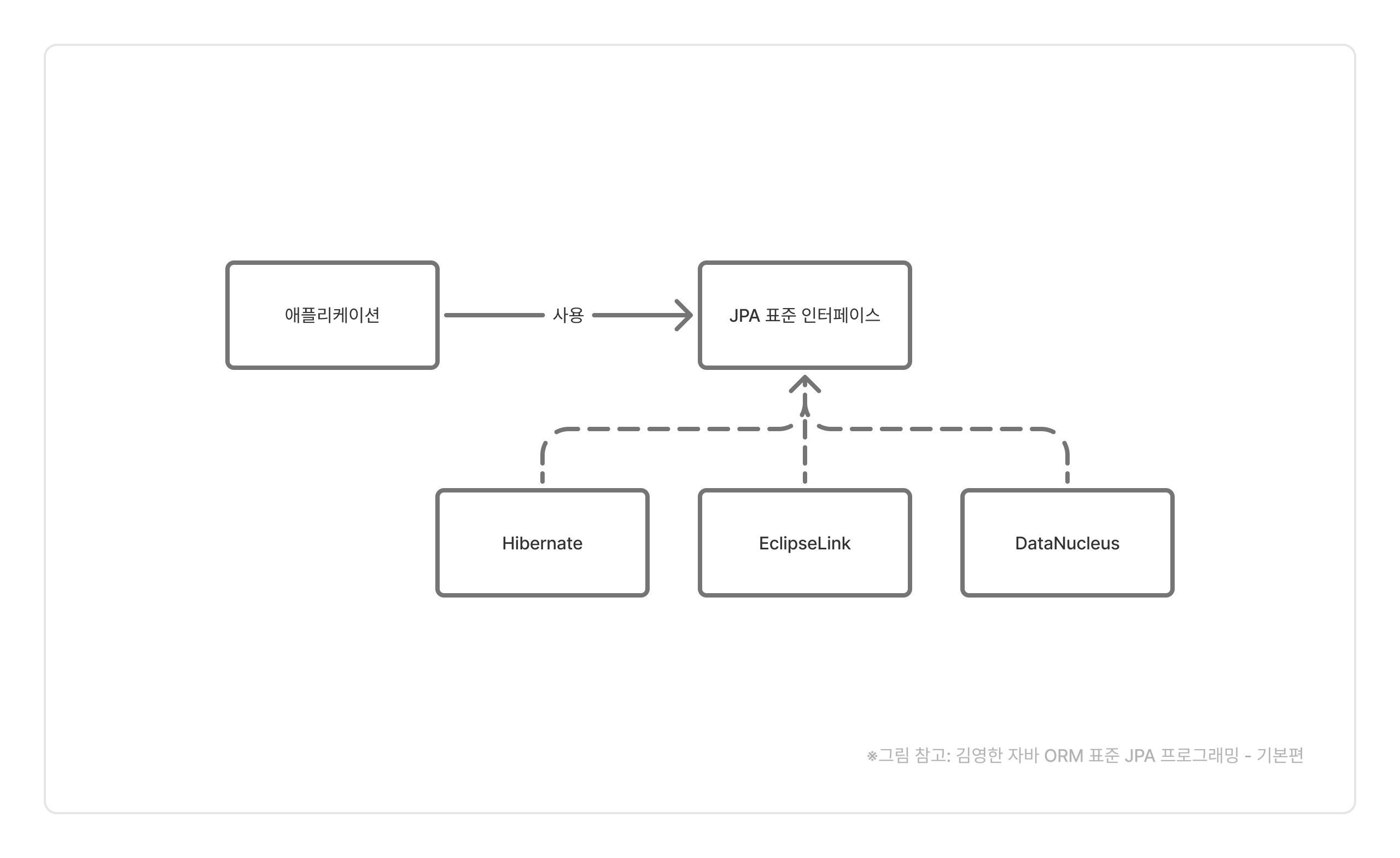
JPA 사용시 장점
JPA를 사용했을 때의 장점을 다시 한 번 정리하면 다음과 같습니다.
- SQL 중심적인 개발에서 객체 중심으로 개발할 수 있습니다. 객체지향적인 방식으로 데이터베이스를 다룰 수 있어, 도메인 중심 설계가 가능해집니다.
- SQL을 직접 다루거나 매핑하지 않는 덕분에 생산성이 늘어납니다.
- SQL을 직접 다루거나 매핑하지 않는 덕분에 유지보수성이 좋아집니다.
- 패러다임 불일치가 해소됩니다. -> 대신 동작 방식을 잘 알아야합니다.
- 잘 사용하면 성능에서 이점을 얻을 수 있습니다.
- 데이터 접근을 추상화합니다.
- 표준 인터페이스라 벤더와 독립적으로 개발할 수 있습니다.
- 표준 인터페이스(와!)입니다.
🤔 JPA는 Leaky Abstraction인가?
JPA가 위와 같은 장점을 충분히 발휘하기 위해서는 내부 구현에 대한 충분한 이해가 필요합니다. 때문에 세부 구현이 추상화 바깥에 영향을 준다해서 "leaky abstraction(누수된 추상화)"이다/아니다하는 말들이 있습니다. 그러나 어떤 기술이든 어느 시점에는 추상화의 누수는 피할 수 없다고도 이야기 합니다. 자바의 가비지 컬렉터, TCP 프로토콜 등도 마찬가지라고 합니다. 아무튼 추상화를 믿고 동작 방식에 대한 공부 없이 기술을 사용하는 것은 어쩔 수 없는 위험을 동반하나 봅니다.
"All non-trivial abstractions, to some degree, are leaky."
"모든 non-trivial한 추상화는 어느 정도 새게 마련이다."
— Joel Spolsky (2002) 출처
JPA를 활용한 코드
이제 기존 예제에서 JPA를 사용하는 코드로 바꿔보겠습니다. 스프링 부트가 아닌 일반 Gradle 프로젝트에서 JPA를 사용하기 위해서는 설정이 필요합니다. 위에도 적혀있지만 다시 한 번 살펴보겠습니다.
<persistence xmlns="https://jakarta.ee/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://jakarta.ee/xml/ns/persistence https://jakarta.ee/xml/ns/persistence/persistence_3_0.xsd"
version="3.0">
<persistence-unit name="hello">
<class>org.example.domain.Member</class>
<properties>
<!-- H2 in-memory database -->
<property name="jakarta.persistence.jdbc.driver" value="org.h2.Driver"/>
<property name="jakarta.persistence.jdbc.url" value="jdbc:h2:tcp://localhost/~/test"/>
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/>
<!-- Credentials -->
<property name="jakarta.persistence.jdbc.user" value="sa"/>
<property name="jakarta.persistence.jdbc.password" value=""/>
<!-- display SQL in console -->
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="hibernate.highlight_sql" value="true"/>
<!-- JPA Options -->
<property name="hibernate.hbm2ddl.auto" value="create" />
</properties>
</persistence-unit>
</persistence>가능한 한 공식 문서의 형태를 그대로 가져오려고 했습니다.
<class>org.example.domain.Member</class>: 사용할 엔티티를 등록한 것입니다. Maven 혹은 스프링부트에서는 각 엔티티를 수동으로 등록할 필요 없습니다.<!-- H2 in-memory database -->: 아래 부분은 JPA가 사용하는 JDBC 연결 정보입니다. 본인이 사용하는 데이터베이스 설정에 맞게 수정하면 됩니다.<!-- Credentials -->: 마찬가지로 JDBC가 연결할 데이터베이스의 인증 정보 부분입니다.<!-- display SQL in console -->: Hibernate가 만드는 SQL(+JPQL)을 보여줍니다.<property name="hibernate.hbm2ddl.auto" value="create" />: 프로그램이 실행할 때 JPA가 엔티티의 생김새에 따라 데이터베이스에 필요한 자동으로 DDL을 날려 테이블을 생성하는 기능에 대한 설정입니다.create로 되어 있는 경우 매번 같은 이름의 테이블을 삭제하고 새로운 테이블을 생성합니다.
Member (Entity)
@Entity // 추가
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
public class Member {
@Id @GeneratedValue // 추가
private Long id;
private String name;
}엔티티는 @Entity 어노테이션을 붙여줘야 합니다. 또한 엔티티는 반드시 기본 키에 매핑되는 필드에 @Id 어노테이션을 붙여줘야 합니다. 그리고 내부적 기능을 위해 기본 생성자(@NoArgsConstructor)가 반드시 있어야 합니다.
MemberJpaRepository
public class MemberJpaRepository implements MemberRepository {
private final EntityManagerFactory emf;
public MemberJpaRepository() {
this.emf = Persistence.createEntityManagerFactory("hello");
}
@Override
public void save(Member member) {
EntityManager em = emf.createEntityManager();
try {
em.getTransaction().begin();
em.persist(member);
em.getTransaction().commit();
} catch (Exception e) {
em.getTransaction().rollback();
throw e;
} finally {
em.close();
}
}
@Override
public List<Member> findAll() {
EntityManager em = emf.createEntityManager();
try {
return em.createQuery("SELECT m FROM Member m", Member.class)
.getResultList();
} finally {
em.close();
}
}
}JPA는 EntityManager 라는 클래스를 통해 원하는 엔티티 객체를 JPA에 저장하라고 넘깁니다. save() 내부에 em.persist(member)가 그 역할을 합니다. 데이터를 INSERT하는데 SQL을 사용하지 않는 것을 볼 수 있습니다.
근데 findAll()은 SQL 있는데요! SQL 안 쓴다메요!!
SQL이 아닙니다. 자세히 보시면, SQL과는 좀 다르게 Member 객체를 직접 언급하는 것을 볼 수 있습니다. 이것은 JPQL입니다. JPA에서 쿼리문을 객체지향적으로 다루기 위해 만들어졌습니다. 데이터베이스 구조가 바뀌더라도 조회 대상이 Member 객체라는 사실은 달라지지 않기 때문에, JPQL을 수정할 필요는 없습니다. 이것이 SQL을 직접 사용하는 것과의 큰 차이점 입니다.
또한 JPQL을 실행해 불러온 데이터를 따로 클래스로 매핑하지 않고 바로 List<Member>로 받는 것을 볼 수 있습니다. 그러한 과정을 모두 JPA가 해결해주기 때문입니다.
위처럼 순수 Java SE 환경에서는 EntityManagerFactory를 직접 생성해야 하지만, Spring Boot에서는 관련 빈들을 자동 구성해주기 때문에, EntityManager를 필요할 때 주입받아 사용할 수 있습니다.
Main
public class Main {
public static void main(String[] args) {
MemberRepository memberRepository = new MemberJpaRepository(); // MemberJpaRepository로 변경
memberRepository.save(new Member(null, "박계현"));
List<Member> result = memberRepository.findAll();
for (Member member : result) {
System.out.println(member.getName());
}
}
}인터페이스를 사용하기 때문에 메인 코드는 큰 차이가 없습니다.
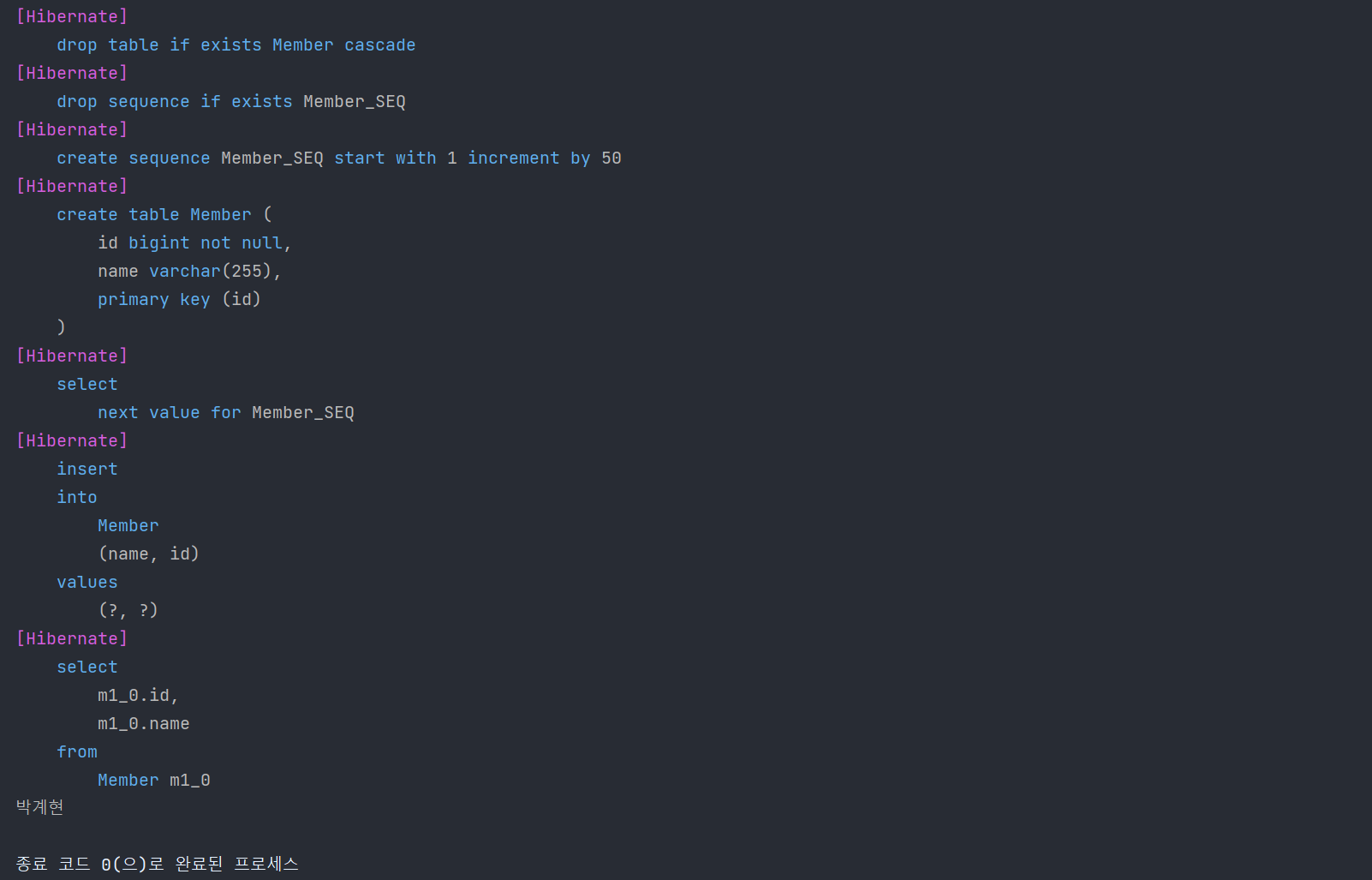
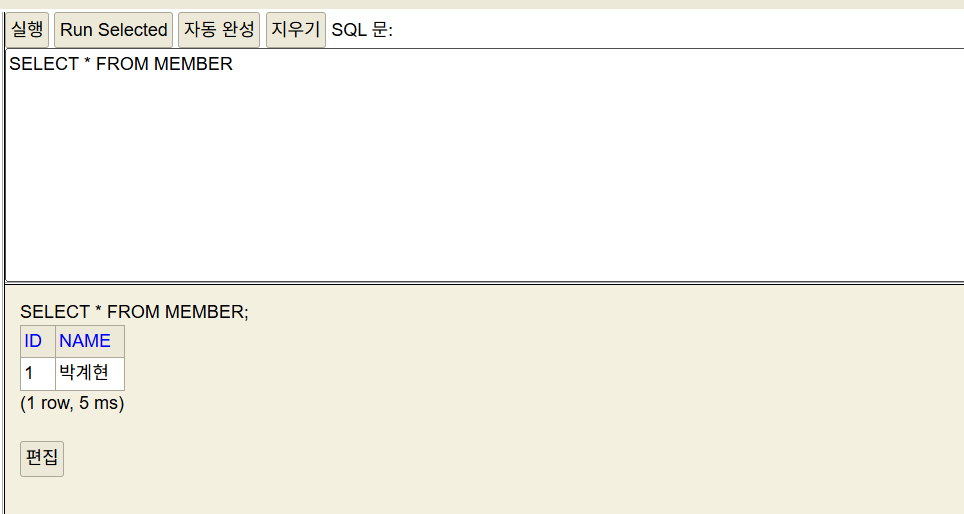
내부 쿼리를 볼 수 있도록 설정해두었기 때문에 콘솔에 찍히는 것을 확인할 수 있습니다. 정상적으로 JPA를 통해 데이터를 저장하고 불러온 것을 확인할 수 있습니다.
(추가) 스프링 부트에서의 구현
Spring Boot 사용
우리가 만든 MemberRepository의 구현체를 스프링에서 만들면 아래와 같이 만들 수 있습니다.
@Repository
public class MemberJpaRepository implements MemberRepository {
@PersistenceContext // 또는 @Autowired도 가능
private EntityManager em;
@Override
@Transactional
public void save(Member member) {
em.persist(member);
}
@Override
public List<Member> findAll() {
return em.createQuery("SELECT m FROM Member m", Member.class)
.getResultList();
}
}스프링에서는 트랜잭션 처리를 @Transactional을 통해 AOP로 처리했기 때문에 코드가 더욱 간결해집니다. JpaTransactionManager를 통해 트랜잭션 별 EntityManager가 자동으로 관리되기 때문에 직접 EntityManager를 생성하고 리소스를 닫는 코드가 생략됩니다.
나아가 스프링 부트는 EntityManagerFactory의 생성과 설정을 자동으로 해줍니다.
Spring Data JPA 사용
근데 여기서 끝이 아닙니다(뭐라고..!). Spring Data JPA까지 사용하면 더 간단하게 할 수 있습니다. Spring Data JPA를 사용하는 경우에는 MemberRespository가 JpaRepository를 상속받도록 수정해줘야 합니다.
public interface MemberRepository extends JpaRepository<Member, Long> {
}근데 이게 끝입니다! 엥? 구현체는 어딨죠? 구현체는 Spring Data JPA가 알아서 만들어줍니다. 서비스 코드 내에서 MemberRepository를 주입받으면, 기본적으로 제공되는 메서드들을 코드 구현없이 사용할 수 있습니다.
Spring Data JPA 사용 예시
@Service
public class MemberService {
private final MemberRepository memberRepository;
public MemberService(MemberRepository memberRepository) {
this.memberRepository = memberRepository;
}
public void saveMember(String username) {
Member member = new Member();
member.setUsername(username);
memberRepository.save(member);
}
public List<Member> getAllMembers() {
return memberRepository.findAll();
}
}여기서의 save()와 findAll()은 JpaRepository에 이미 정의되어 있는 것이며, 구현 또한 저는 한 글자도 적은 적이 없습니다. 그럼에도 Member는 잘 저장되고 조회도 됩니다. 저 두 메서드 외에도 주로 사용되는 메서드들이 제공되며, 필요한 경우에 원하는 메서드를 추가할 수 있습니다.
마치며
사실 한 글에서 영속성 컨텍스트까지 다뤄보려고 했지만 내용이 너무 많아져서 이만 줄이기로 했습니다ㅎㅎ. 영속성 컨텍스트와 연관관계 매핑에 대한 내용은 이후에 써보려고 합니다.
참고 자료
- https://docs.jboss.org/hibernate/orm/6.6/introduction/html_single/Hibernate_Introduction.html#hello-hibernate
- https://jakarta.ee/specifications/persistence/
- https://jakarta.ee/learn/docs/jakartaee-tutorial/current/persist/persistence-intro/persistence-intro.html
- https://en.wikipedia.org/wiki/Leaky_abstraction
- https://ko.wikipedia.org/wiki/%EA%B0%9D%EC%B2%B4_%EA%B4%80%EA%B3%84_%EB%A7%A4%ED%95%91
- 김영한 자바 ORM 표준 JPA 프로그래밍 - 기본편

JPA는 내부적으로 JDBC API를 사용해서 데이터베이스와 통신하기 때문에 자바 애플리케이션과 JDBC 사이 들어온 하나의 추상 레이어로 생각하면 된다. 명심하겠습니다 :)