들어가며
블로그 작성이 굉장히 오랜만이네요ㅋㅋㅋ 한동안 취준하고, 코로나도 걸리고, 알바도 새로 구하고 정신이 없었습니다. 또, 뭔가 "더 좋은 블로그를 써야지" 하는 마음이 "대단한 걸 써야지"가 되고 "작정하고 써야지"가 되다보니 시작하기가 힘들어져 여기까지 왔습니다ㅎㅎ 아무튼 그래서 기록에 좀 더 편해져보려고 오늘 포스트는 정말 별거 아닌 간단한 메모 같은 포스트를 써보려고 합니다.
상황
게시판을 하나 만들어보고 있습니다. 개발 공부를 시작할 당시 인터넷이나 주변에서 게시판 같은 거 만들어서 포트폴리오로 할 생각하지 말라는 말을 너무 많이 듣다보니 자연스럽게 게시판을 만들어볼 생각 자체를 안 하게 됐었는데, 공부를 좀 하고 시간이 지나고 보니 '게시판이라도 제대로 만드려고 하면 신경쓸게 많지 않을까?' 하는 생각이 들었습니다.
그래서 한 번 제대로 동작하는, 프로덕션 수준의 게시판을 한 번 스스로 고민해서 만들어보고 싶어졌고, 그걸 하고 있습니다. 심심하면 구경해보셔도 좋습니다.
유저 로그인/가입 플로우를 만들던 중 이런 영상을 접하게 되었습니다.
https://www.youtube.com/watch?v=_l5Q5kKHtR8&t=3s
빅테크 기업들은 Username 중복 체크를 어떻게 밀리초 안에 해내는 지에 대한 영상인데, 인덱스 -> 캐시 -> 최종적으로 블룸 필터를 통해서 아주 빠른 속도를 낼 수 있다고 설명하는 영상입니다.
이 영상을 보고 비슷하게 블룸필터로 최적화 적용을 한 번 해봐야겠다 하고 우선 대용량 데이터에서 유저네임 체크에 병목이 생기는지 테스트 해보았습니다.
테스트 결과
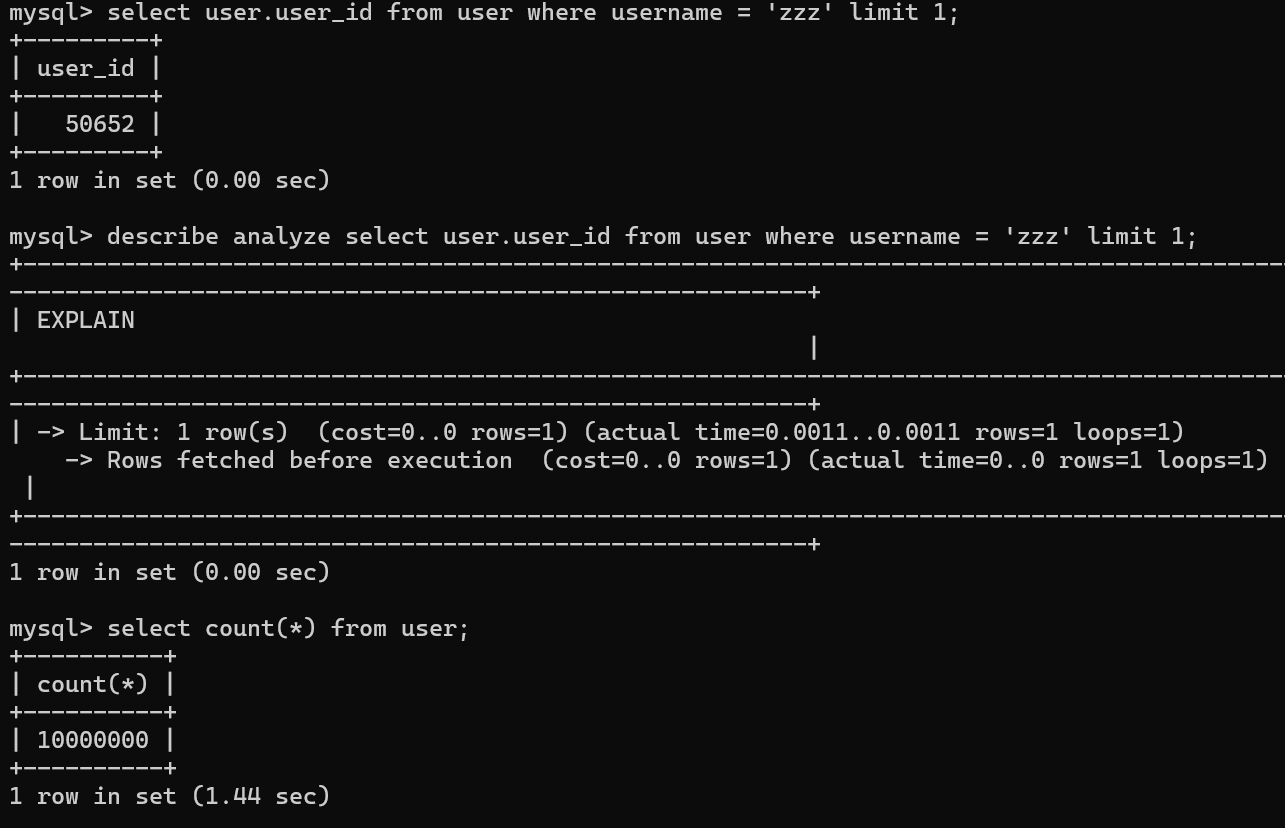
결론부터 말씀드리면, Username에 대한 유니크 인덱스만으로 속도가 너무 잘 나옵니다.
처음에는 1백만 건, 그 다음 2백만, 1천만, 1억 건의 유저 데이터를 넣고 테스트 해봤는데 다 거의 비슷한 속도가 나왔습니다. "블룸 필터로 1억 건 데이터에서 200ms 안에 유저네임 중복 체크하기" 라는 제목으로 글을 쓰고 싶었는데, 아직 별 거 안 했는데 20ms가 나와버렸습니다;; (아아, 이것이 인덱스의 힘인가)
뭔가 어거지로 데이터를 10억, 100억 넣어서 최적화하기에는 의미가 없는 것 같아서 그러지 않기로 결정하고 다른 기능 구현으로 현재는 넘어갔습니다.
배운 것
대신 배운 것도 있는데 간단하게 남겨봅니다.
테스트 데이터는 유저네임 규칙에 따라
a ~ z,0~9,_를 사전순으로 조합하여 임의의 이름을 만들어내도록 자바로 메서드를 작성하여 실행했습니다.JDBC의
addBatch()와executeBatch()로 1000건 씩 Bulk Insert를 진행했습니다.
MySQL 대용량 테스트 데이터 삽입에서 시간을 줄여주는 것: 유니크 인덱스 삭제하고 삽입
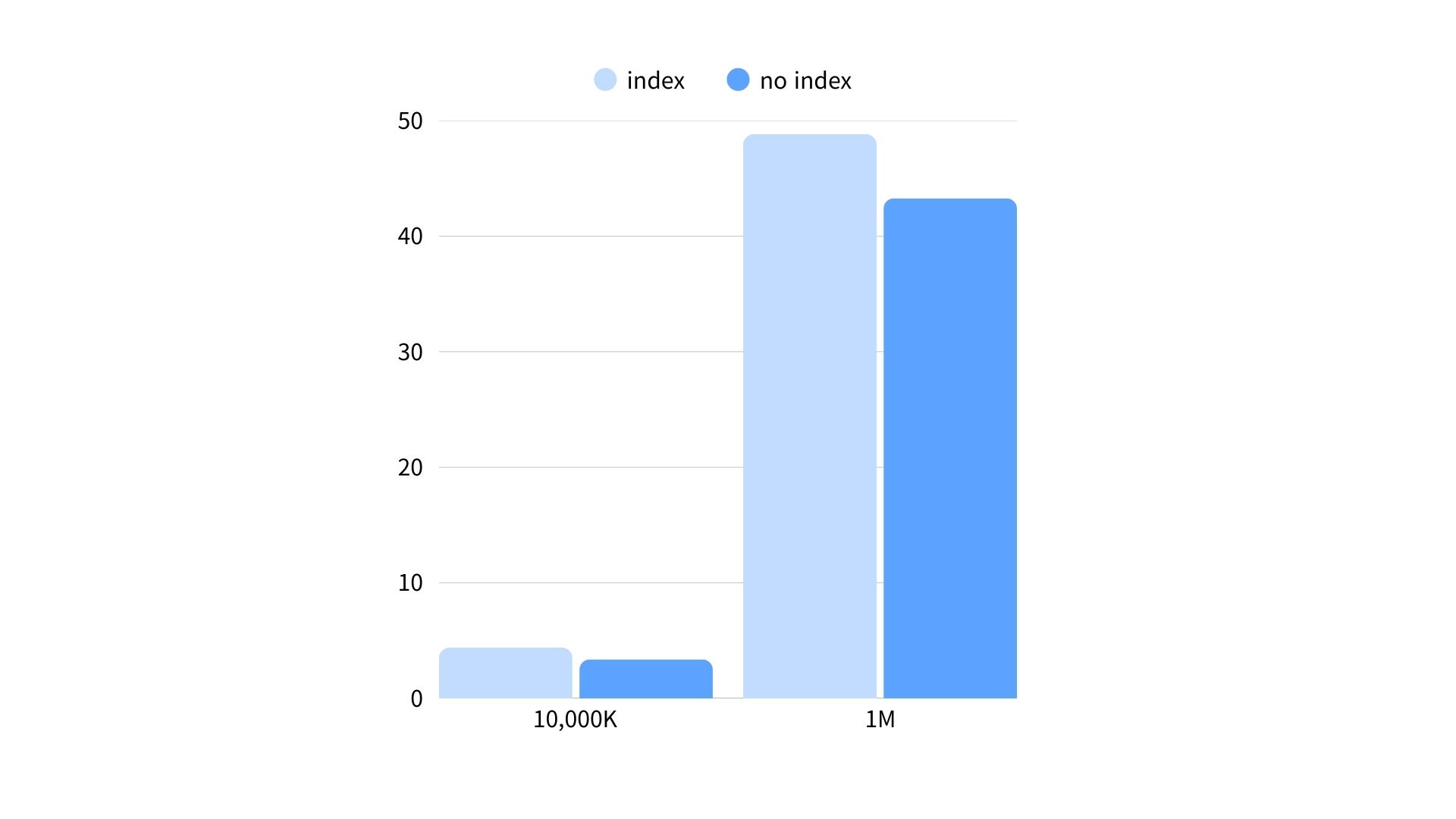
당연한 소리지만 유니크 인덱스가 있으면 삽입 속도가 느려집니다. 유니크 인덱스는 인덱스 생성 비용 이외에도, 값이 존재하는지 유니크 제약 조건을 위한 검사가 한 번 필요하기 때문입니다. 그런데 '대충 느려진다'만 알고 있었지 '얼마나 느려지는지'는 몰랐기 때문에 기록을 해보자면, 다음은 username 칼럼에 대한 유니크 인덱스가 있을 때와 없을 때 데이터 삽입에 걸린 시간 차이입니다.
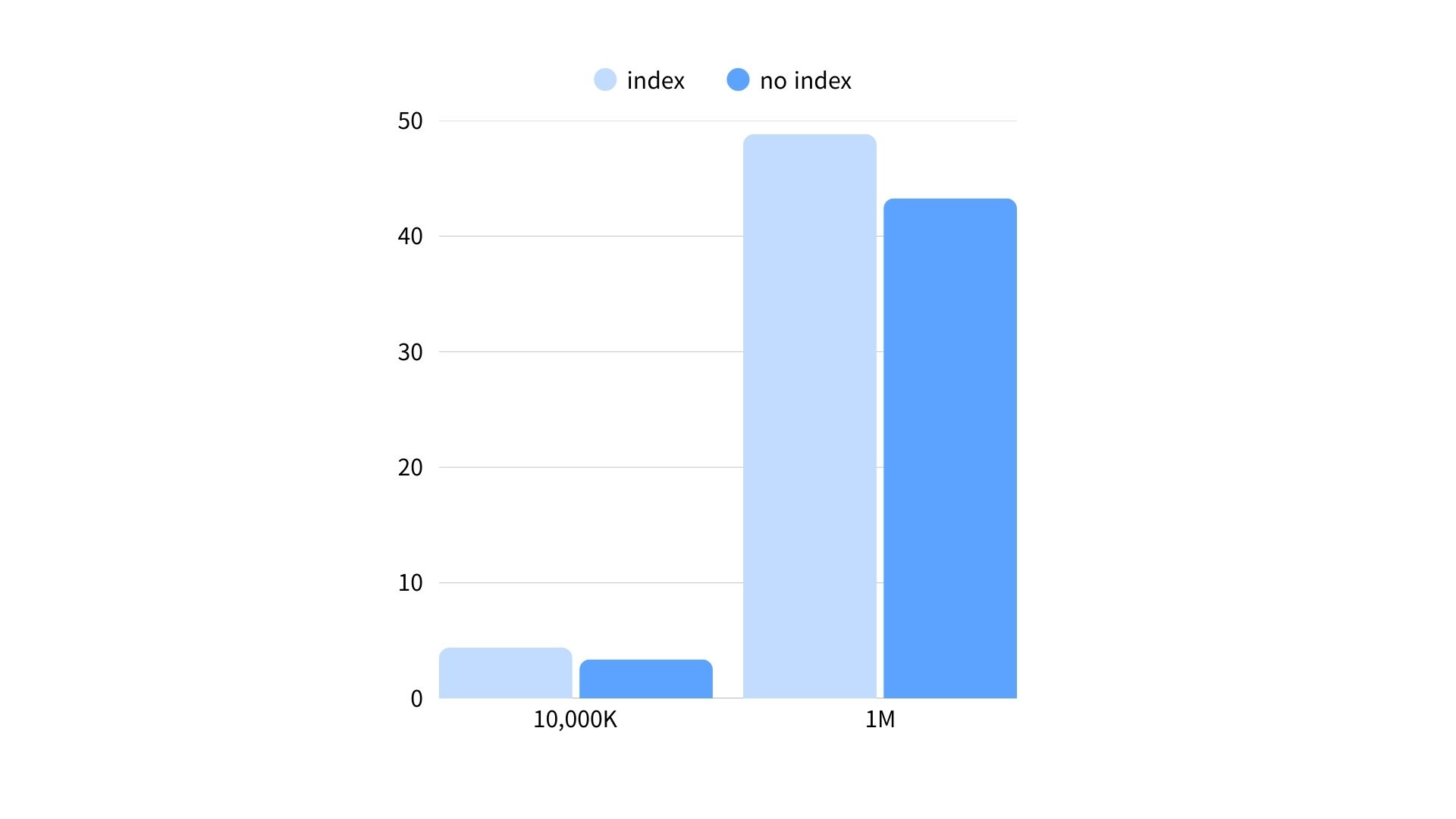
1000만 건 삽입
username인덱스가 있을 때:- 삽입: 4m 24s
username인덱스가 없을 때:- 삽입: 3m 23s
- 인덱스 생성: 20s
- 총: 3m 43s
1억 건 삽입
username인덱스가 있을 때:- 삽입: 48m 49s
username인덱스가 없을 때:- 삽입: 38m 51s
- 인덱스 생성: 3m 56s
- 총: 43m 17s
일반적인 OLTP(On-Line Transaction Processing) 웹 애플리케이션에서 이 정도로 대규모 삽입이 일어나는 경우는 드물지만, 백업된 데이터 복구 등을 해야하는 경우를 생각하면 꽤 큰 차이(약 10%~15%)가 있다고 볼 수 있겠습니다.
Mimesis 라이브러리를 활용한 Python 스크립트로 데이터 삽입
가짜 테스트 데이터를 생성해주는 Mimesis라는 Python 라이브러리를 이용해 대용량 데이터를 csv 파일로 만들어서 INSERT 하는 스크립트도 GPT 도움을 받아 짜보았습니다.
import argparse
import csv
import time
import json
import os
import pymysql
import random
import string
from datetime import datetime
from mimesis import Person
from mimesis.locales import Locale
OAUTH_PROVIDERS = ["GOOGLE", "KAKAO", "NAVER"]
def load_config():
with open("config.json") as f:
return json.load(f)
def random_oauth_id(length=16):
return ''.join(random.choices(string.ascii_letters + string.digits, k=length))
def generate_csv(csv_path, total_count, chunk):
person = Person(Locale.EN)
start = time.time()
with open(csv_path, "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow([
"created_at", "last_modified_at",
"created_by", "email",
"last_modified_by",
"oauth_id", "oauth_provider",
"username"
])
for offset in range(0, total_count, chunk):
rows = []
for i in range(offset, min(offset + chunk, total_count)):
now = datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f")
username = f"{person.username()}{i}"
email = f"{username}@example.com"
oauth_provider = random.choice(OAUTH_PROVIDERS)
oauth_id = random_oauth_id()
rows.append([
now, now,
"test", email,
"test",
oauth_id,
oauth_provider,
username
])
with open(csv_path, "a", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerows(rows)
# 진행률 출력
progress = offset + len(rows)
percent = (progress / total_count) * 100
elapsed = time.time() - start
print(f"[CSV] {progress}/{total_count} ({percent:.2f}%) | Elapsed: {elapsed:.2f}s")
total_elapsed = time.time() - start
print(f"[CSV] Generation completed in {total_elapsed:.2f} seconds.")
def load_into_mysql(config, csv_path):
db = config["db"]
csv_abs_path = os.path.abspath(csv_path).replace("\\", "/")
conn = pymysql.connect(
host=db["host"],
port=db["port"],
user=db["user"],
password=db["password"],
database=db["database"],
local_infile=True
)
cursor = conn.cursor()
query = f"""
LOAD DATA LOCAL INFILE '{csv_abs_path}'
INTO TABLE {db['table']}
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
IGNORE 1 LINES
(created_at, last_modified_at, created_by, email, last_modified_by, oauth_id, oauth_provider, username)
"""
print("Loading into MySQL...")
start = time.time()
cursor.execute(query)
conn.commit()
elapsed = time.time() - start
print(f"MySQL LOAD completed in {elapsed:.2f} seconds.")
cursor.close()
conn.close()
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--count", type=int, help="Number of rows to generate")
args = parser.parse_args()
config = load_config()
total = args.count or config.get("schema", {}).get("count", 100000)
chunk = config.get("schema", {}).get("chunk", 50000)
csv_path = "users.csv"
print(f"Generating {total} User rows...")
generate_csv(csv_path, total, chunk)
print("CSV generation done.")
load_into_mysql(config, csv_path)
print("All done.")
if __name__ == "__main__":
main()그런데 문제는 너무 느립니다...! 일단 이렇게 해서 생성된 csv 파일이 User 데이터가 1천만 건이면 1.3GB 입니다. 데이터를 생성하는데 130초 걸리고, 삽입은 하다가 자꾸 뻗어버려서 포기했습니다(삽입을 시작하고 끝이 안 나서 측정에 실패했습니다). 삽입 중 진행 상황을 알 수 없는 것도 불편했습니다.
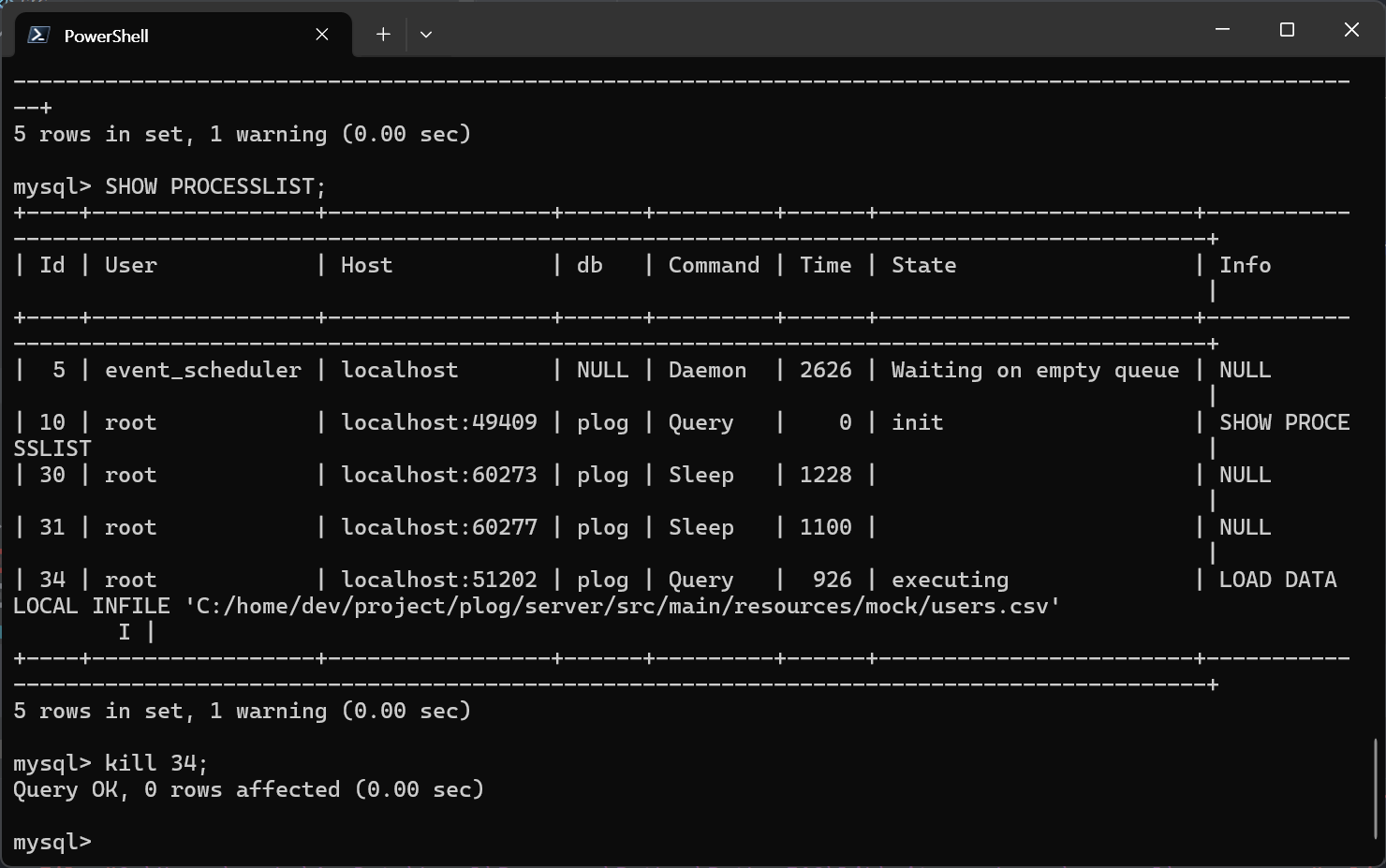
덕분에 MySQL 프로세스가 응답이 없을 때 강제로 종료하는 법을 배웠습니다.
SHOW PROCESSLIST;
KILL {프로세스 ID};적은 수의 데이터를 생성하는 데에는 꽤 편리하지만(Mimesis 라이브러리가 제공하는 다양한 Fake 데이터 타입들을 활용할 수 있습니다), 대용량 데이터 삽입에는 무리가 있었습니다.
추가로 LOAD DATA를 통해 데이터를 입력하는 중에 중간에 취소하거나 프로세스를 KILL하더라도, InnoDB는 이미 삽입된 데이터를 전체 롤백 하게 됩니다. 이 롤백 과정에서 해당 트랜잭션이 잡고 있는 row-level, index, 그리고 테이블에 대한 intention lock이 유지되기 때문에, 작업이 완료될 때까지 사실상 테이블에 접근할 수 없습니다. 고로 프로세스를 중간에 KILL하거나 하는 상황은 되도록 만들지 않는 것이 좋겠습니다.
아래는 innoDB 트랜잭션 상태를 확인하는 방법입니다.
SELECT * FROM information_schema.innodb_trx;+--------+--------------+---------------------+-----------------------+------------------+------------+---------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------------+-------------------+-------------------+------------------+-----------------------+-----------------+-------------------+-------------------------+---------------------+-------------------+------------------------+----------------------------+---------------------------+---------------------------+------------------+----------------------------+---------------------+
| trx_id | trx_state | trx_started | trx_requested_lock_id | trx_wait_started | trx_weight | trx_mysql_thread_id | trx_query | trx_operation_state | trx_tables_in_use | trx_tables_locked | trx_lock_structs | trx_lock_memory_bytes | trx_rows_locked | trx_rows_modified | trx_concurrency_tickets | trx_isolation_level | trx_unique_checks | trx_foreign_key_checks | trx_last_foreign_key_error | trx_adaptive_hash_latched | trx_adaptive_hash_timeout | trx_is_read_only | trx_autocommit_non_locking | trx_schedule_weight |
+--------+--------------+---------------------+-----------------------+------------------+------------+---------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------------+-------------------+-------------------+------------------+-----------------------+-----------------+-------------------+-------------------------+---------------------+-------------------+------------------------+----------------------------+---------------------------+---------------------------+------------------+----------------------------+---------------------+
| 579697 | ROLLING BACK | 2025-12-01 21:30:54 | NULL | NULL | 3642417 | 34 | LOAD DATA LOCAL INFILE 'C:/home/dev/project/plog/server/src/main/resources/mock/users.csv'
INTO TABLE user
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
IGNORE 1 LINES
(created_at, last_modified_at, created_by, email, last_modified_by, oauth_id, oauth_provider, username) | rollback of SQL statement | 1 | 1 | 30116 | 8691832 | 954428 | 3612301 | 0 | REPEATABLE READ | 1 | 1 | NULL | 0 | 0 | 0 | 0 | NULL |
+--------+--------------+---------------------+-----------------------+------------------+------------+---------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------------+-------------------+-------------------+------------------+-----------------------+-----------------+-------------------+-------------------------+---------------------+-------------------+------------------------+----------------------------+---------------------------+---------------------------+------------------+----------------------------+---------------------+
1 row in set (0.01 sec)마치며
아무튼 없는 문제를 있겠지 생각하고 진행했다면 큰일날 뻔 했습니다ㅎㅎ. 망치를 들고 못을 찾는 위험이라고나 할까요? 직접 실험해보고 데이터를 확인하는 습관을 계속 길러나가면 도움이 될 것 같습니다. 이런저런 테스트를 해보는 중에도 꽤 많은 걸 배울 수 있으니까요. 혹, 의문점이나 오류가 있다면 남겨주시면 감사하겠습니다.
